C++繼承
繼承的概念
繼承(inheritance)機制是面向對象程序設計使代碼可以復用的重要的手段,它允許程序員在保持原有類特性的基礎上進行擴展,增加功能,這樣產生新的類,稱為派生類。
繼承呈現了面向對象程序設計的層次結構,體現了由簡單到復雜的認知過程。以前我們接觸的復用都是函數復用,而繼承便是類設計層次的復用。
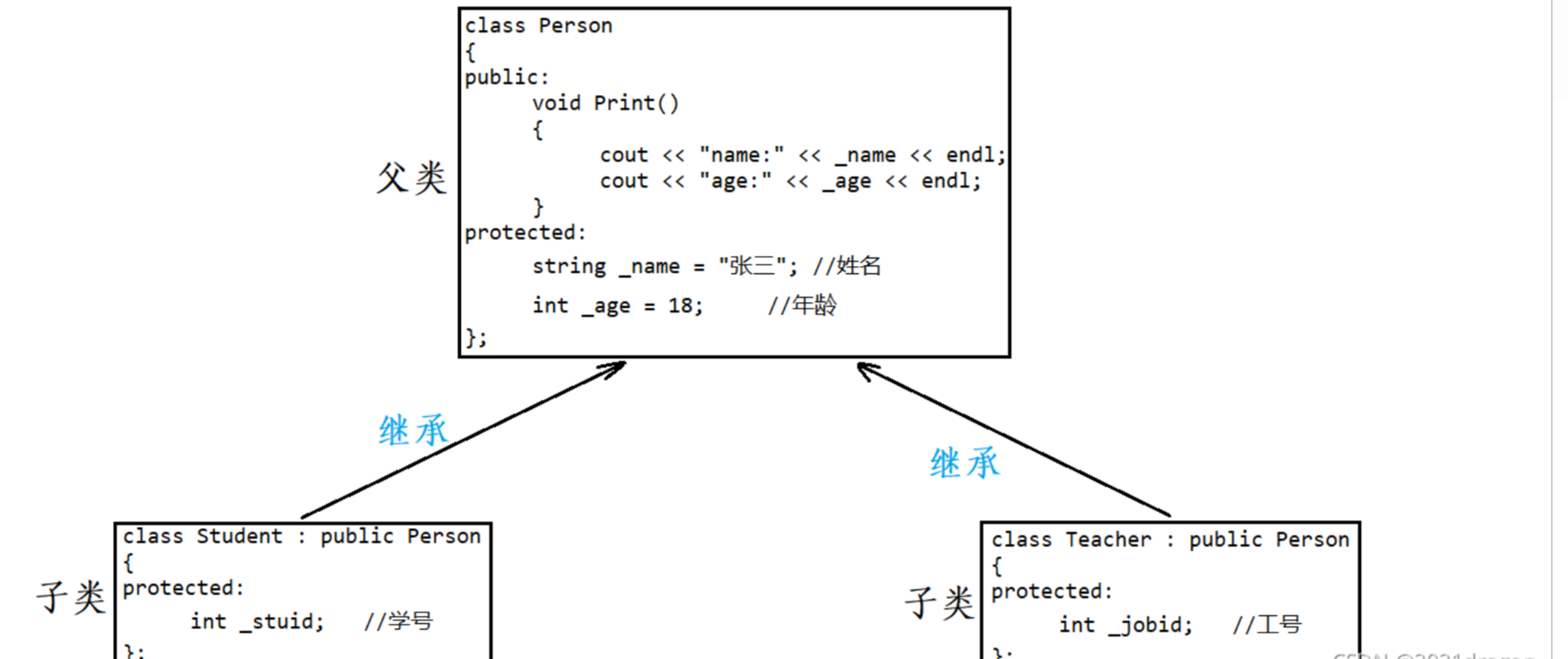
繼承的定義格式如下:

默認繼承方式
在使用繼承的時候也可以不指定繼承方式,使用關鍵字class時默認的繼承方式是private,使用struct時默認的繼承方式是public。
基類和派生類對象賦值轉換
派生類對象可以賦值給基類的對象、基類的指針以及基類的引用,因為在這個過程中,會發生基類和派生類對象之間的賦值轉換。
注意:?基類對象不能賦值給派生類對象,基類的指針可以通過強制類型轉換賦值給派生類的指針,但是此時基類的指針必須是指向派生類的對象才是安全的。
繼承中的作用域
在繼承體系中的基類和派生類都有獨立的作用域。若子類和父類中有同名成員,子類成員將屏蔽父類對同名成員的直接訪問,這種情況叫隱藏,也叫重定義。
需要注意的是,如果是成員函數的隱藏,只需要函數名相同就構成隱藏。
例如,對于以下代碼,調用成員函數fun時將直接調用子類當中的fun,若想調用父類當中的fun,則需使用作用域限定符指定類域。
#include <iostream>
#include <string>
using namespace std;
//父類
class Person
{
public:void fun(int x){cout << x << endl;}
};
//子類
class Student : public Person
{
public:void fun(double x){cout << x << endl;}
};
int main()
{Student s;s.fun(3.14); //直接調用子類當中的成員函數funs.Person::fun(20); //指定調用父類當中的成員函數funreturn 0;
}
繼承與靜態成員
若基類當中定義了一個static靜態成員變量,則在整個繼承體系里面只有一個該靜態成員。無論派生出多少個子類,都只有一個static成員實例。
菱形繼承
菱形繼承:菱形繼承是多繼承的一種特殊情況。
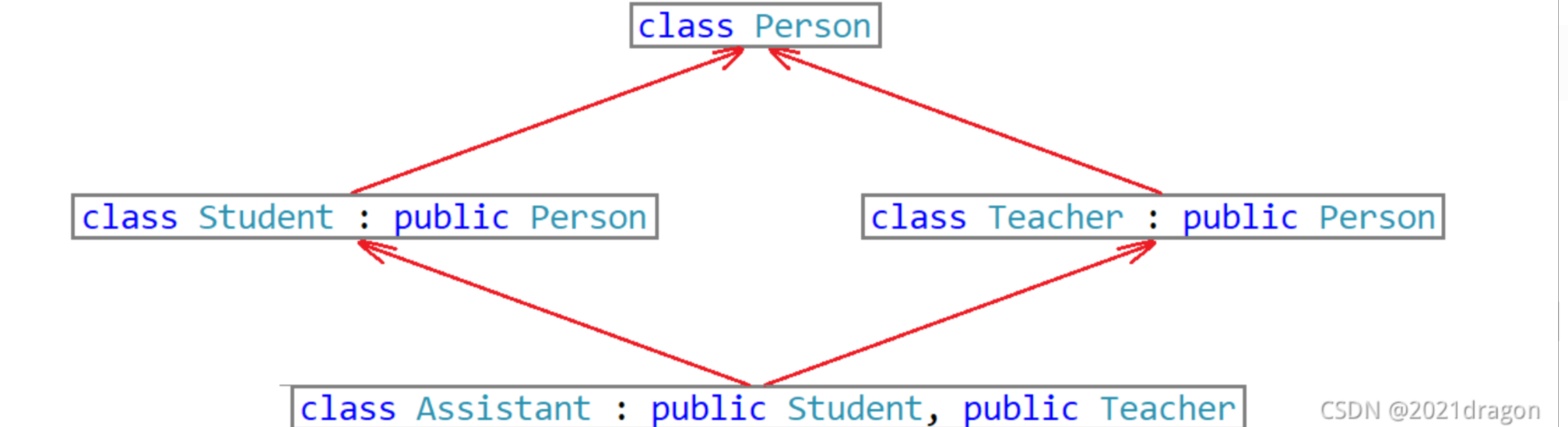
從菱形繼承的模型構造就可以看出,菱形繼承的繼承方式存在數據冗余和二義性的問題。
菱形虛擬繼承
為了解決菱形繼承的二義性和數據冗余問題,出現了虛擬繼承。如前面說到的菱形繼承關系,在Student和Teacher繼承Person是使用虛擬繼承,即可解決問題。
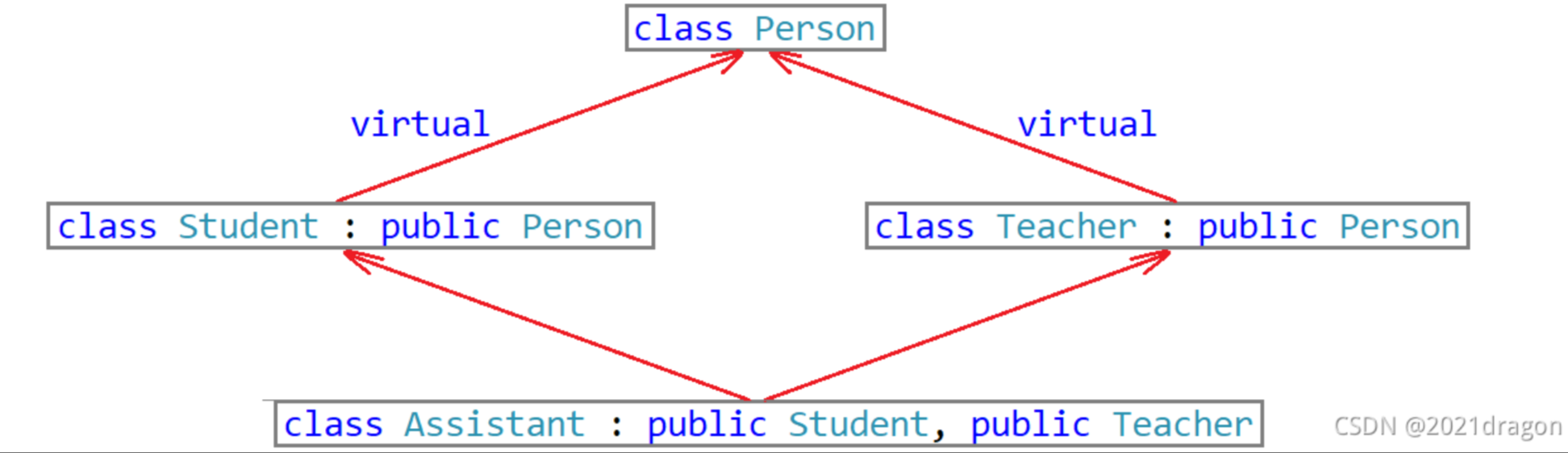
原理:
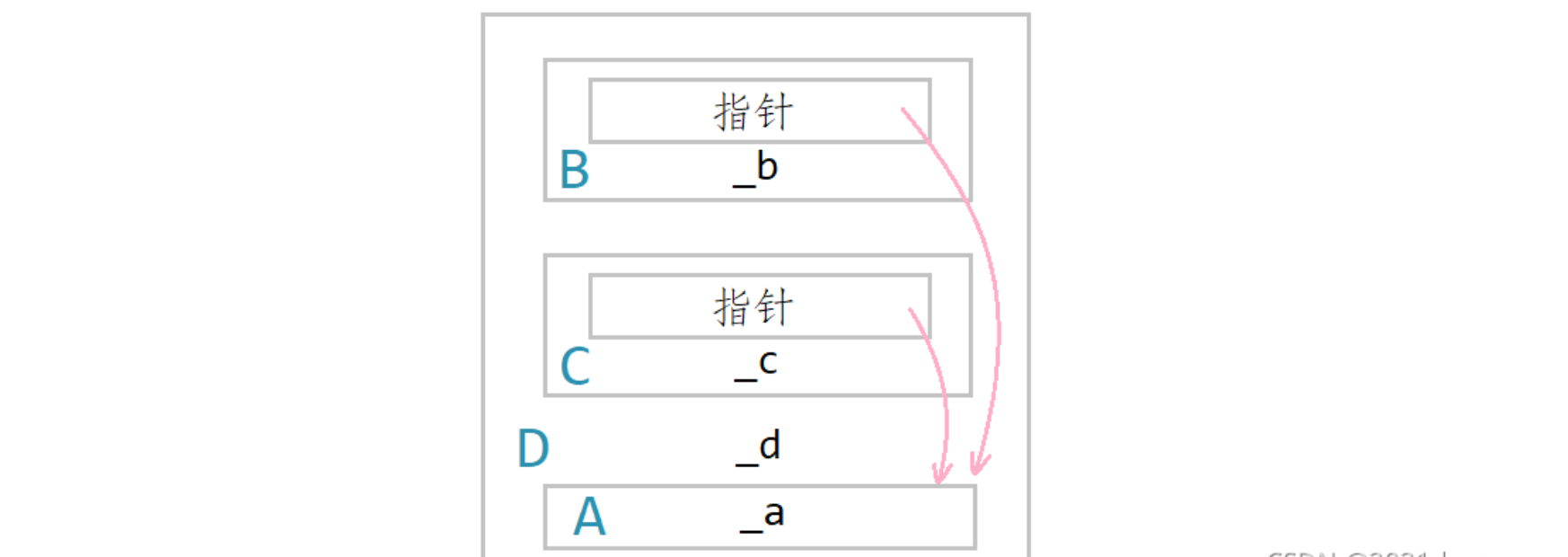
繼承和組合
繼承是一種is-a的關系,也就是說每個派生類對象都是一個基類對象;而組合是一種has-a的關系,若是B組合了A,那么每個B對象中都有一個A對象。
若是兩個類之間既可以看作is-a的關系,又可以看作has-a的關系,則優先使用組合。
繼承允許你根據基類的實現來定義派生類的實現,這種通過生成派生類的復用通常被稱為白箱復用。術語“白箱”是相對可視性而言:在繼承方式中,基類的內部細節對于派生類可見,繼承一定程度破壞了基類的封裝,基類的改變對派生類有很大的影響,派生類和基類間的依賴性關系很強,耦合度高。
C+多態
多態的概念
多態就是函數調用的多種形態,使用多態能夠使得不同的對象去完成同一件事時,產生不同的動作和結果。
例如,在現實生活當中,普通人買票是全價,學生買票是半價,而軍人允許優先買票。不同身份的人去買票,所產生的行為是不同的,這就是所謂的多態。
多態的定義及實現
多態的構成條件
多態是指不同繼承關系的類對象,去調用同一函數,產生了不同的行為。在繼承中要想構成多態需要滿足兩個條件:
- 必須通過基類的指針或者引用調用虛函數。
- 被調用的函數必須是虛函數,且派生類必須對基類的虛函數進行重寫。
虛函數重寫的兩個例外
協變(基類與派生類虛函數的返回值類型不同)
派生類重寫基類虛函數時,與基類虛函數返回值類型不同。即基類虛函數返回基類對象的指針或者引用,派生類虛函數返回派生類對象的指針或者引用,稱為協變。
析構函數的重寫(基類與派生類析構函數的名字不同)
如果基類的析構函數為虛函數,此時派生類析構函數只要定義,無論是否加virtual關鍵字,都與基類的析構函數構成重寫,雖然基類與派生類析構函數名字不同。
那父類和子類的析構函數構成重寫的意義何在呢?試想以下場景:分別new一個父類對象和子類對象,并均用父類指針指向它們,然后分別用delete調用析構函數并釋放對象空間。
int main()
{//分別new一個父類對象和子類對象,并均用父類指針指向它們Person* p1 = new Person;Person* p2 = new Student;//使用delete調用析構函數并釋放對象空間delete p1;delete p2;return 0;
}
C++11 override和final
從上面可以看出,C++對函數重寫的要求比較嚴格,有些情況下由于疏忽可能會導致函數名的字母次序寫反而無法構成重寫,而這種錯誤在編譯期間是不會報錯的,直到在程序運行時沒有得到預期結果再來進行調試會得不償失,因此,C++11提供了final和override兩個關鍵字,可以幫助用戶檢測是否重寫。
final:修飾虛函數,表示該虛函數不能再被重寫。
override:檢查派生類虛函數是否重寫了基類的某個虛函數,如果沒有重寫則編譯報錯。
抽象類
在虛函數的后面寫上=0,則這個函數為純虛函數。包含純虛函數的類叫做抽象類(也叫接口類),抽象類不能實例化出對象。
#include <iostream>
using namespace std;
//抽象類(接口類)
class Car
{
public://純虛函數virtual void Drive() = 0;
};
int main()
{Car c; //抽象類不能實例化出對象,errorreturn 0;
}
接口繼承和實現繼承
實現繼承:?普通函數的繼承是一種實現繼承,派生類繼承了基類函數的實現,可以使用該函數。
接口繼承:?虛函數的繼承是一種接口繼承,派生類繼承的是基類虛函數的接口,目的是為了重寫,達成多態。
建議:?所以如果不實現多態,就不要把函數定義成虛函數。
多態的原理
下面Base類當中有三個成員函數,其中Func1和Func2是虛函數,Func3是普通成員函數,子類Derive當中僅對父類的Func1函數進行了重寫。
#include <iostream>
using namespace std;
//父類
class Base
{
public://虛函數virtual void Func1(){cout << "Base::Func1()" << endl;}//虛函數virtual void Func2(){cout << "Base::Func2()" << endl;}//普通成員函數void Func3(){cout << "Base::Func3()" << endl;}
private:int _b = 1;
};
//子類
class Derive : public Base
{
public://重寫虛函數Func1virtual void Func1(){cout << "Derive::Func1()" << endl;}
private:int _d = 2;
};
int main()
{Base b;Derive d;return 0;
}
對象模型分析如下:

Func2是虛函數,所以繼承下來后放進了子類的虛表,而Func3是普通成員函數,繼承下來后不會放進子類的虛表。此外,虛函數表本質是一個存虛函數指針的指針數組,一般情況下會在這個數組最后放一個nullptr。
總結一下,派生類的虛表生成步驟如下:
- 先將基類中的虛表內容拷貝一份到派生類的虛表。
- 如果派生類重寫了基類中的某個虛函數,則用派生類自己的虛函數地址覆蓋虛表中基類的虛函數地址。
- 派生類自己新增加的虛函數按其在派生類中的聲明次序增加到派生類虛表的最后。
為什么必須使用父類的指針或者引用去調用虛函數呢?為什么使用父類對象去調用虛函數達不到多態的效果呢?
Person* p1 = &Mike;
Person* p2 = &Johnson;
使用父類指針或者引用時,實際上是一種切片行為,切片時只會讓父類指針或者引用得到父類對象或子類對象中切出來的那一部分。
Person p1 = Mike;
Person p2 = Johnson;
使用父類對象時,切片得到部分成員變量后,會調用父類的拷貝構造函數(類型Person必定調用父類的拷貝構造函數)對那部分成員變量進行拷貝構造,而拷貝構造出來的父類對象p1和p2當中的虛表指針指向的都是父類對象的虛表。因為同類型的對象共享一張虛表,他們的虛表指針指向的虛表是一樣的。
動態綁定和靜態綁定
靜態綁定:?靜態綁定又稱為前期綁定(早綁定),在程序編譯期間確定了程序的行為,也成為靜態多態,比如:函數重載。
動態綁定:?動態綁定又稱為后期綁定(晚綁定),在程序運行期間,根據具體拿到的類型確定程序的具體行為,調用具體的函數,也稱為動態多態。
相比不構成多態時的代碼,構成多態時調用函數的那句代碼翻譯成匯編后就變成了八條匯編指令,主要原因就是我們需要在運行時,先到指定對象的虛表中找到要調用的虛函數,然后才能進行函數的調用。
bitset
?bitset(位圖)的介紹與使用
給40億個不重復的無符號整數,沒排過序。給一個無符號整數,如何快速判斷一個數是否在這40億個數中?
要判斷一個數是否在某一堆數中,我們可能會想到如下方法:
- 將這一堆數進行排序,然后通過二分查找的方法判斷該數是否在這一堆數中。
- 將這一堆數插入到unordered_set容器中,然后調用find函數判斷該數是否在這一堆數中。
位圖解決
實際在這個問題當中,我們只需要判斷一個數在或是不在,即只有兩種狀態,那么我們可以用一個比特位來表示數據是否存在,如果比特位為1則表示存在,比特位為0則表示不存在。
無符號整數總共有2的32次方個,因此記錄這些數字就需要2的32次方個比特位,也就是512M的內存空間,內存消耗大大減少。
#include <iostream>
#include <bitset>
using namespace std;int main()
{bitset<8> bs;bs.set(2); //設置第2位bs.set(4); //設置第4位cout << bs << endl; //00010100bs.flip(); //反轉所有位cout << bs << endl; //11101011cout << bs.count() << endl; //6cout << bs.test(3) << endl; //1bs.reset(0); //清空第0位cout << bs << endl; //11101010bs.flip(7); //反轉第7位cout << bs << endl; //01101010cout << bs.size() << endl; //8cout << bs.any() << endl; //1bs.reset(); //清空所有位cout << bs.none() << endl; //1bs.set(); //設置所有位cout << bs.all() << endl; //1return 0;
}
bitset類的模擬實現
在構造位圖時,我們需要根據所給位數N,創建一個N位的位圖,并且將該位圖中的所有位都初始化為0。
namespace xwy
{//模擬實現位圖template<size_t N>class bitset{public://構造函數bitset();//設置位void set(size_t pos);//清空位void reset(size_t pos);//反轉位void flip(size_t pos);//獲取位的狀態bool test(size_t pos);//獲取可以容納的位的個數size_t size();//獲取被設置位的個數size_t count();//判斷位圖中是否有位被設置bool any();//判斷位圖中是否全部位都沒有被設置bool none();//判斷位圖中是否全部位都被設置bool all();//打印函數void Print();private:vector<int> _bits; //位圖};
}
其構造函數與設置位函數:
//構造函數
bitset()
{_bits.resize(N / 32 + 1, 0);
}//設置位
void set(size_t pos)
{assert(pos < N);//算出pos映射的位在第i個整數的第j個位int i = pos / 32;int j = pos % 32;_bits[i] |= (1 << j); //將該位設置為1(不影響其他位)
}
布隆過濾器
在注冊賬號設置昵稱的時候,為了保證每個用戶昵稱的唯一性,系統必須檢測你輸入的昵稱是否被使用過,這本質就是一個key的模型,我們只需要判斷這個昵稱被用過,還是沒被用過。
- 方法一:用紅黑樹或哈希表將所有使用過的昵稱存儲起來,當需要判斷一個昵稱是否被用過時,直接判斷該昵稱是否在紅黑樹或哈希表中即可。但紅黑樹和哈希表最大的問題就是浪費空間,當昵稱數量非常多的時候內存當中根本無法存儲這些昵稱
- 方法二:用位圖將所有使用過的昵稱存儲起來,雖然位圖只能存儲整型數據,但我們可以通過一些哈希算法將字符串轉換成整型,比如BKDR哈希算法。當需要判斷一個昵稱是否被用過時,直接判斷位圖中該昵稱對應的比特位是否被設置即可。
位圖雖然能夠大大節省內存空間,但由于字符串的組合形式太多了,一個字符的取值有256種,而一個數字的取值只有10種,因此無論通過何種哈希算法將字符串轉換成整型都不可避免會存在哈希沖突。
布隆過濾器的實現
首先,布隆過濾器可以實現為一個模板類,因為插入布隆過濾器的元素不僅僅是字符串,也可以是其他類型的數據,只有調用者能夠提供對應的哈希函數將該類型的數據轉換成整型即可,但一般情況下布隆過濾器都是用來處理字符串的,所以這里可以將模板參數K的缺省類型設置為string。布隆過濾器中的成員一般也就是一個位圖,我們可以在布隆過濾器這里設置一個非類型模板參數N,用于讓調用者指定位圖的長度
//布隆過濾器
template<size_t N, class K = string, class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
public://...
private:bitset<N> _bs;
};
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件的交集?給出近似算法。
題目要求給出近視算法,也就是允許存在一些誤判,那么我們就可以用布隆過濾器。
- 先讀取其中一個文件當中的query,將其全部映射到一個布隆過濾器當中。
- 然后讀取另一個文件當中的query,依次判斷每個query是否在布隆過濾器當中,如果在則是交集,不在則不是交集。
如何擴展BloomFilte使得它支持刪除元素的操作。
布隆過濾器一般不支持刪除操作,原因如下:
- 因為布隆過濾器判斷一個元素存在時可能存在誤判,因此無法保證要刪除的元素確實在布隆過濾器當中,此時將位圖中對應的比特位清0會影響其他元素。
- 此外,就算要刪除的元素確實在布隆過濾器當中,也可能該元素映射的多個比特位當中有些比特位是與其他元素共用的,此時將這些比特位清0也會影響其他元素。
如果要讓布隆過濾器支持刪除,就必須要做到以下兩點:
- 保證要刪除的元素在布隆過濾器當中,比如在刪除一個用戶的信息前,先遍歷數據庫確認該用戶確實存在。
- 保證刪除后不會影響到其他元素,比如可以為位圖中的每一個比特位設置一個對應的計數值,當插入元素映射到該比特位時將該比特位的計數值++,當刪除元素時將該元素對應比特位的計數值–即可。
哈希切分
利用哈希函數,讓相同query進入到同一個小文件中。Ai= hash(query)%200.map<string,,int>可以統計 每個string出現的次數。
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件的交集?給出精確算法。
還是剛才那道題目,但現在要求給出精確算法,那么就不能使用布隆過濾器了,此時需要用到哈希切分。
- 首先需要估算一下這里一個文件的大小,便于確定將一個文件切分為多少個小文件。
- 假設平均每個query為20字節,那么100億個query就是200G,由于我們只有1G內存,這里可以考慮將一個文件切分成400個小文件。
- 這里我們將這兩個文件分別叫做A文件和B文件,此時我們將A文件切分成了A0~A399共400個小文件,將B文件切分成了B0~B399共400個小文件。
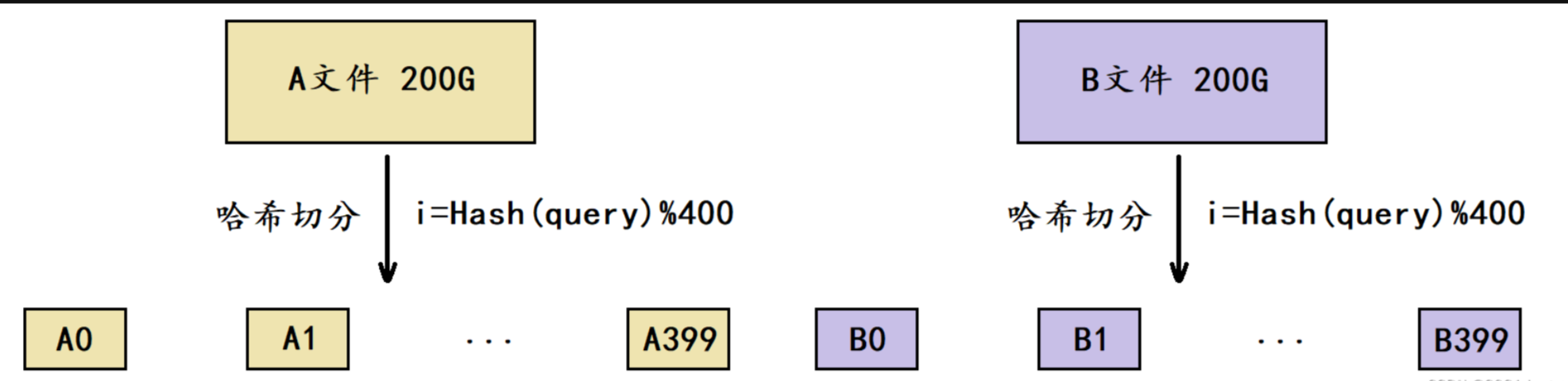
由于切分A文件和B文件時采用的是同一個哈希函數,因此A文件與B文件中相同的query計算出的 i ii 值都是相同的,最終就會分別進入到Ai和Bi文件中,這也是哈希切分的意義。
那各個小文件之間又應該如何找交集呢?
- 經過切分后理論上每個小文件的平均大小是512M,因此我們可以將其中一個小文件加載到內存,并放到一個set容器中,再遍歷另一個小文件當中的query,依次判斷每個query是否在set容器中,如果在則是交集,不在則不是交集。
- 當哈希切分并不是平均切分,有可能切出來的小文件中有一些小文件的大小仍然大于1G,此時如果與之對應的另一個小文件可以加載到內存,則可以選擇將另一個小文件中的query加載到內存,因為我們只需要將兩個小文件中的一個加載到內存中就行了。
- 但如果兩個小文件的大小都大于1G,那我們可以考慮將這兩個小文件再進行一次切分,將其切成更小的文件,方法與之前切分A文件和B文件的方法類似。
請設計一個類,只能創建一個對象(單例模式)
單例模式有兩種實現方式,分別是餓漢模式和懶漢模式:
餓漢模式
單例模式的餓漢實現方式如下:
- 將構造函數設置為私有,并將拷貝構造函數和賦值運算符重載函數設置為私有或刪除,防止外部創建或拷貝對象。
- 提供一個指向單例對象的static指針(可以為對象,但是單例模式一般返回指針對象),并在程序入口之前完成單例對象的初始化。
- 提供一個全局訪問點獲取單例對象。
class Singleton
{
public://3、提供一個全局訪問點獲取單例對象static Singleton* GetInstance(){return _inst;}
private://1、將構造函數設置為私有,并防拷貝Singleton(){}Singleton(const Singleton&) = delete;Singleton& operator=(const Singleton&) = delete;//2、提供一個指向單例對象的static指針static Singleton* _inst;
};//在程序入口之前完成單例對象的初始化
Singleton* Singleton::_inst = new Singleton;
懶漢模式
單例模式的懶漢實現方式如下:
- 將構造函數設置為私有,并將拷貝構造函數和賦值運算符重載函數設置為私有或刪除,防止外部創建或拷貝對象。
- 提供一個指向單例對象的static指針,并在程序入口之前先將其初始化為空。
- 提供一個全局訪問點獲取單例對象。
class Singleton
{
public://3、提供一個全局訪問點獲取單例對象static Singleton* GetInstance(){//雙檢查if (_inst == nullptr){_mtx.lock();if (_inst == nullptr){_inst = new Singleton;}_mtx.unlock();}return _inst;}
private://1、將構造函數設置為私有,并防拷貝Singleton(){}Singleton(const Singleton&) = delete;Singleton& operator=(const Singleton&) = delete;//2、提供一個指向單例對象的static指針static Singleton* _inst;static mutex _mtx; //互斥鎖
};//在程序入口之前先將static指針初始化為空
Singleton* Singleton::_inst = nullptr;
mutex Singleton::_mtx; //初始化互斥鎖
懶漢模式還有一種比較經典的實現方式:
- 將構造函數設置為私有,并將拷貝構造函數和賦值運算符重載函數設置為私有或刪除,防止外部創建或拷貝對象。
- 提供一個全局訪問點獲取單例對象。
class Singleton
{
public://2、提供一個全局訪問點獲取單例對象static Singleton* GetInstance(){static Singleton inst;return &inst;}
private://1、將構造函數設置為私有,并防拷貝Singleton(){}Singleton(const Singleton&) = delete;Singleton& operator=(const Singleton&) = delete;
};

)


)













函數)
