kafka介紹
Kafka是最初由Linkedin公司開發,是一個分布式、支持分區的(partition)、多副本的 (replica),基于zookeeper協調的分布式消息系統,它的最大的特性就是可以實時的處理大量數據以滿足各種需求場景:比如基于hadoop的批處理系統、低延遲的實時系統、 Storm/Spark流式處理引擎,web/nginx日志、訪問日志,消息服務等等,用scala語言編寫,Linkedin于2010年貢獻給了Apache基金會并成為頂級開源項目。
1.使用場景
-
日志收集:可以用Kafka收集各種服務的log,通過kafka以統?接口服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等。
-
消息系統:解耦和生產者和消費者、緩存消息等。
-
用戶活動跟蹤:Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、 搜索、點擊等活動,這些活動信息被各個服務器發布到kafka的topic中,然后訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、數據倉庫中做離線分析和挖掘。
-
運營指標:Kafka也經常用來記錄運營監控數據。包括收集各種分布式應用的數據,生產各種操作的集中反饋,比如報警和報告。
2.kafka基本概念

整個流程應該是:producer通過網絡發送消息到Kafka集群,然后consumer 來進行消費,如下圖:
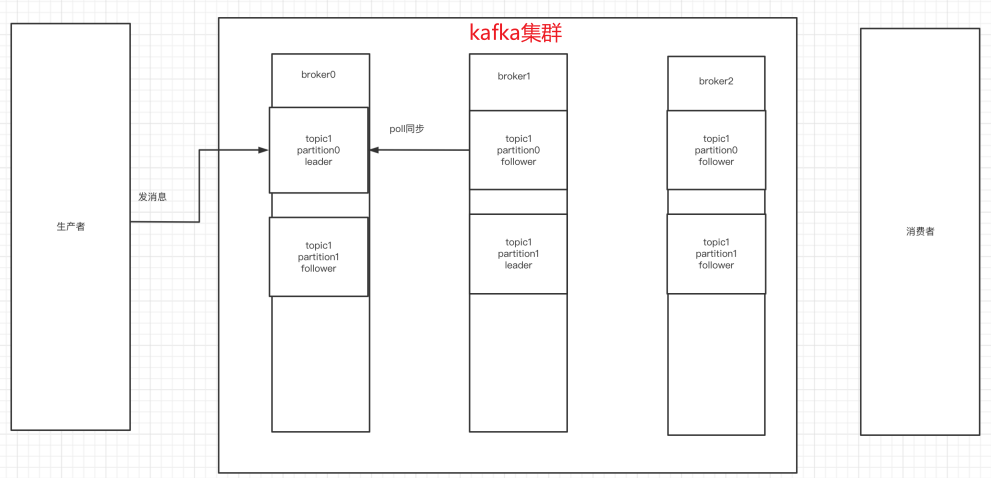
服務端(brokers)和客戶端(producer、consumer)之間通信通過TCP協議來完成。
kafka基本使用
1.安裝&關閉
以下所有操作全部基于kafka_2.13-3.0.1.tgz (3.0.1版本) 這個版本
配置文件server.properties(主要修改以下配置)
#broker.id屬性在kafka集群中必須要是唯?
broker.id=0
listeners=PLAINTEXT://xx.xx.xx.xx(服務器內網IP地址):9092
advertised.listeners=PLAINTEXT://xx.xx.xx.xx(服務器對外IP地址):9092
#kafka的消息存儲?件
log.dir=/usr/local/kafka/data/kafka-logs
#kafka連接zookeeper的地址
zookeeper.connect=192.168.65.60:2181
啟動
./kafka-server-start.sh -daemon ../config/server.properties
驗證
# 查看端口是否占用
netstat -ntlp
或者
進入到zk內查看是否有kafka的節點:/brokers/ids/0
./zkCli.sh

關閉kafka
./kafka-server-stop.sh stop ../config/server.properties
2.創建topic
執行以下命令創建名為“test”的topic,這個topic只有?個partition,并且備份因子也設置為 1
./kafka-topics.sh --bootstrap-server kafkahost:9092 --create --topic test --partitions 1 --replication-factor 1-- 新版本的kafka,已經不需要依賴zookeeper來創建topic,新版的kafka創建topic指令如下:
./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --create --topic test --partitions 1 --replication-factor 1
3.查看kafka中所有的主題
./kafka-topics.sh --bootstrap-server kafkahost:9092 --list./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --list
4.發送消息
kafka自帶了?個producer命令客戶端,可以從本地文件中讀取內容或者以命令行中直接輸入內容,并將這些內容以消息的形式發送到kafka集群中。在默認情況下,每?個行會被當做成?個獨立的消息。使用kafka的發送消息的客戶端,指定發送到的kafka服務器地址和topic
把消息發送給broker中的某個topic,打開?個kafka發送消息的客戶端,然后開始用客戶端向kafka服務器發送消息
./kafka-console-producer.sh --bootstrap-server 124.222.253.33:9092 --topic test
5.消費消息
消費消息兩種方式:
對于consumer,kafka同樣也攜帶了?個命令行客戶端,會將獲取到內容在命令中進行輸出,默認是消費最新的消息。 使用kafka的消費者消息的客戶端,從指定kafka服務器的指定 topic中消費消息
-
從當前主題中的最后?條消息的offset(偏移量位置)+1開始消費
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --topic test -
從當前主題中的第?條消息開始消費
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --from-beginning --topic test
6.消息的細節
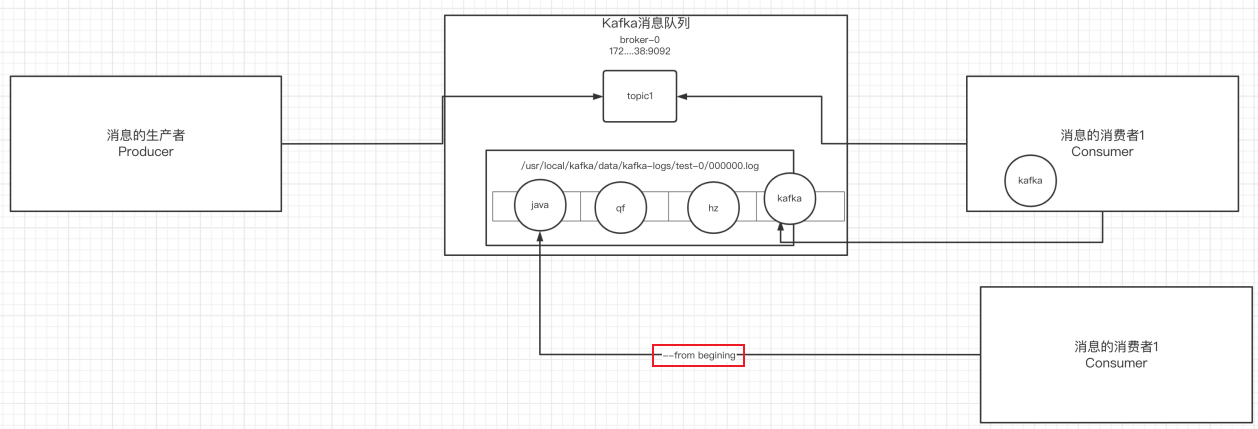
- 生產者將消息發送給broker,broker會將消息保存在本地的日志文件中
/usr/local/kafka/data/kafka-logs/主題-分區/00000000.log
- 消息的保存是有序的,通過offset偏移量來描述消息的有序性
- 消費者消費消息時可以通過offset來描述當前要消費的那條消息的位置
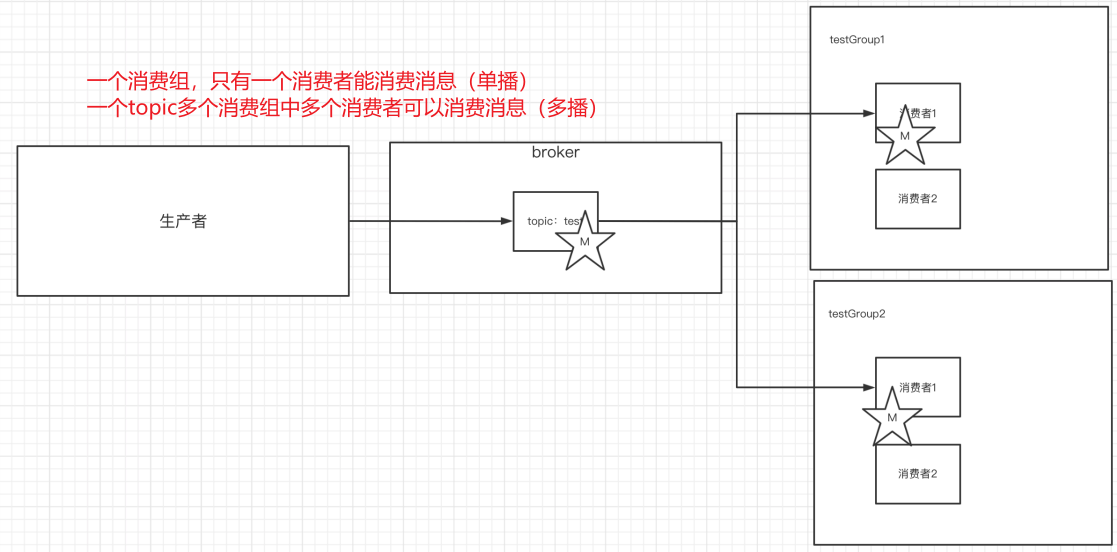
7.單播&多播消息
單播還是多播消息取決于topic有多少消費組
1)單播
如果多個消費者在同?個消費組,那么只有?個消費者可以收到訂閱的topic中的消息。(同?個消費組中只能有?個消費者收到訂閱topic中的消息。)
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --consumer-property group.id=testGroup --topic test
2)多播
不同的消費組訂閱同?個topic,那么不同的消費組中只有?個消費者能收到消息。實際上也是多個消費組中的多個消費者收到了同?個消息。
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --consumer-property group.id=testGroup2 --topic test
3)區別
8.查看消費組詳細信息
# 查看當前主題下有哪些消費組
./kafka-consumer-groups.sh --bootstrap-server 124.222.253.33:9092 --list# 查看消費組中的具體信息:?如當前偏移量、最后?條消息的偏移量、堆積的消息數量
./kafka-consumer-groups.sh --bootstrap-server 124.222.253.33:9092 --describe --group testGroup

- Currennt-offset:當前消費組的已消費偏移量(最后被消費的消息的偏移量)
- Log-end-offset:主題對應分區消息的結束偏移量(HW) 【消息總量,最后一條消息偏移量】
- Lag:當前消費組未消費的消息數(積壓消息量)
Kafka中主題和分區的概念
1.主題
主題-topic在kafka中是?個邏輯的概念,kafka通過topic將消息進?分類。不同的topic會被訂閱該topic的消費者消費。
但是有?個問題,如果說這個topic中的消息非常非常多,多到需要幾T來存,因為消息是會被保存到log日志文件中的。為了解決單個文件過大的問題,kafka提出了Partition分區的概念。
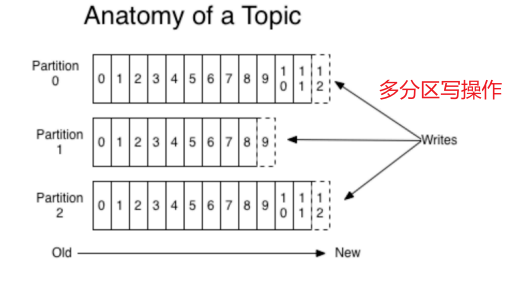
2.分區
1)分區的概念
通過partition將?個topic中的消息分區來存儲。
這樣的好處有多個:
- 分區存儲,可以解決統?存儲文件過大的問題
- 提高了讀寫的吞吐量:讀和寫可以同時在多個分區中進行
2)創建多分區的主題
./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --create --topic test1 --partitions 2 --replication-factor 1
3.kafka中消息日志文件中保存的內容
-
00000.log: 這個文件中保存的就是消息
-
__consumer_offsets-49:
kafka內部自己創建了__consumer_offsets主題包含了50個分區。這個主題用來存放消費者消費某個主題的偏移量。因為每個消費者都會自己維護著消費的主題的偏移量,也就是說每個消費者會把消費的主題的偏移量自主上報給kafka中的默認主題:consumer_offsets。因此kafka為了提升這個主題的并發性,默認設置了50個分區(可以通過offsets.topic.num.partitions設置)。
- 提交到哪個分區:通過hash函數:hash(consumerGroupId) % __consumer_offsets 主題的分區數
- 提交到該主題中的內容是:key是consumerGroupId+topic+分區號,value就是當前offset的值
-
文件中保存的消息,默認保存7天。七天到后消息會被刪除,最后就保留最新的那條數據。
Kafka集群操作
1.搭建kafka集群(三個broker)
- 創建三個server.properties文件
# 0 1 2
broker.id=2
# 9092 9093 9094
listeners=PLAINTEXT://xx.xx.xx.xx(服務器內網IP地址):9094
advertised.listeners=PLAINTEXT://xx.xx.xx.xx(服務器對外IP地址):9094
# kafka-logs kafka-logs-1 kafka-logs-2
log.dir=/usr/local/data/kafka-logs-2
- 通過命令來啟動三臺broker
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties
- 校驗是否啟動成功
進入到zk中查看/brokers/ids中過是否有三個znode(0,1,2)
2.副本的概念
在創建主題時,除了指明了主題的分區數以外,還指明了副本數 replication-factor參數
如下主題,創建了兩分區、三副本(副本對應集群中broker數量)
./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --create --topic my-replicated-topic --partitions 2 --replication-factor 3
副本是為了為主題中的分區創建多個備份,多個副本在kafka集群的多個broker中,會有?個副本作為leader,其他是follower。
查看topic情況:
# 查看topic情況
./kafka-topics.sh --describe --bootstrap-server 124.222.253.33:9092 --topic my-replicated-topic

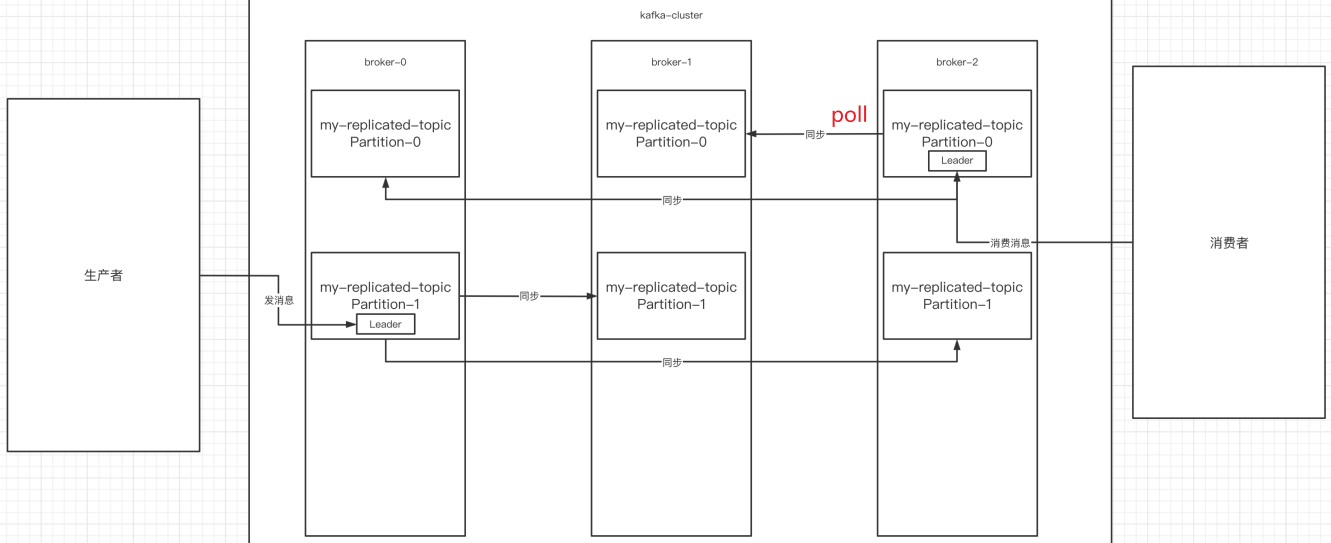
- leader:
kafka的寫和讀的操作,都發生在leader上。leader負責把數據同步給follower。當leader掛了,經過主從選舉,從多個follower中選舉產??個新的leader(follower通過poll的方式來同步數據)
- follower:
接收leader的同步的數據,leader掛了,參與leader選舉
- replicas:
當前副本存在的broker節點
- isr:
可以同步和已同步的broker節點會被存入到isr集合中。如果isr中的broker節點性能較差,會被踢出isr集合。
3.broker、主題、分區、副本
綜上broker、主題、分區、副本概念已全部展示:
集群中有多個broker,創建主題時可以指明主題有多個分區(把消息拆分到不同的分區中存儲),可以為分區創建多個副本,不同的副本存放在不同的broker?。
4.kafka集群消息的發送
./kafka-console-producer.sh --broker-list 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094 --topic my-replicated-topic
5.kafka集群消息的消費
1)普通消費
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094 --from-beginning --topic my-replicated-topic
2)指定消費組消費
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic
6.分區分消費組的集群消費中的細節
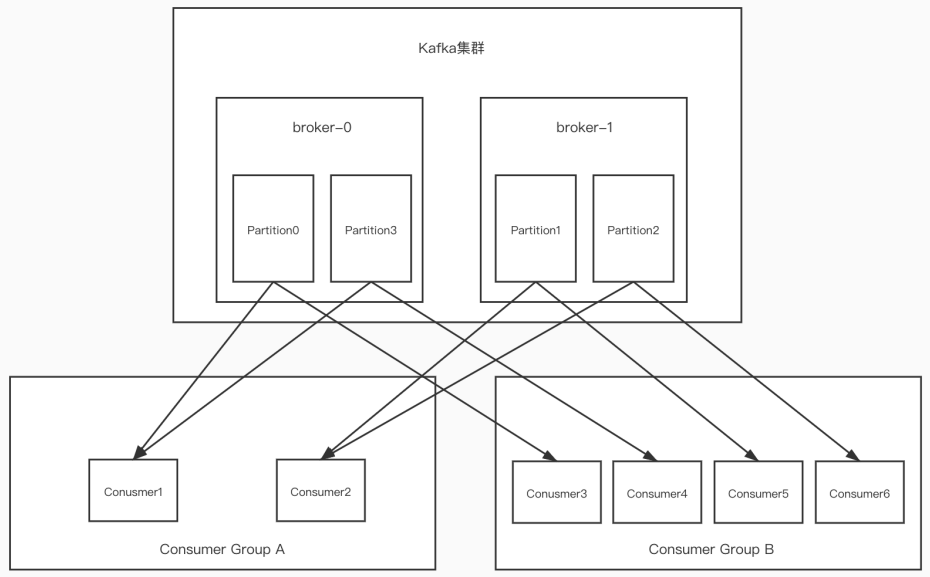
-
?個partition只能被?個消費組中的?個消費者消費,目的是為了保證消費的順序性,但是多個partion的多個消費者消費的總的順序性是得不到保證的,那怎么做到消費的總順序性呢?(Kafka只在
partition的范圍內保證消息消費的局部順序性,不能在同?個topic中的多個partition中保證總的消費順序性。 ?個消費者可以消費多個partition。) -
partition的數量決定了消費組中消費者的數量,
建議同?個消費組中消費者的數量不要超過partition的數量,否則多的消費者消費不到消息 -
如果消費者掛了,那么會觸發rebalance機制,會讓其他消費者來消費該分區


二叉樹part07)
)


)


)








實現整頁面截圖或生成PDF文件)
日志分析監控)