一、 ORM
在 MVC 或者說 MTV 設計模式中,模型(M)代表對數據庫的操作。那么如何操作數據庫呢?
我們可以在 Python 代碼中嵌入 SQL 語句。
但是問題又來了,Python 怎么連接數據庫呢?可以使用類似 pymysql 這一類的第三方模塊(針對不同的數據庫,有不同的模塊)。
如果你有很多的數據庫操作,并且你的 Python 程序員不是專業的 DBA,寫的 SQL 語句很爛,甚至經常寫錯,怎么辦?
聰明的人想出了一個辦法:用 Python 語法來寫,然后使用一個中間工具將 Python代碼翻譯成原生的 SQL 語句。這個中間工具就是所謂的 ORM(對象關系映射)!
ORM(object—relationship--mapping)將一個 Python 的對象映射為數據庫中的一張關系表。它將 SQL 封裝起來,程序員不再需要關心數據庫的具體操作,只需要專注于自己本身代碼和業務邏輯的實現。
于是,整體的實現過程就是:Python 代碼,通過 ORM 轉換成 SQL 語句,再通過pymysql 去實際操作數據庫。

最典型的 python ORM 就是 SQLAlchemy 了,如果你的 Web 框架自身不帶 ORM 系統,那么你可以安裝使用它。
Django 自帶 ORM 系統,不需要額外安裝別的 ORM。當然,也可以安裝并使用其它的 ORM,比如 SQLAlchemy,但是不建議這么做,因為 Django 系統龐大,集成完善,模型層與視圖層、模板層結合得比較緊密,使用自帶的 ORM 更方便更可靠,并且Django 自帶的 ORM 功能也非常強大,也不難學。
Django 的 ORM 系統體現在框架內就是模型層。想要理解模型層的概念,關鍵在于理解用 Python 代碼的方式來定義數據庫表的做法!一個 Python 的類,就是一個模型,代表數據庫中的一張數據表!Django 奉行 Python 優先的原則,一切基于 Python代碼的交
流,完全封裝 SQL 內部細節。
Django 默認支持的數據庫類型(查看預先定義好的 engine):
?
可以配置不在默認支持類型中的其他類型的數據庫,比如 sqlserver,需要下載相對應的包來支持。
在 Django 中配置使用 MySQL 數據庫:
1. 修改項目的 settings.py 文件,將 default 數據庫改為 mysql,具體參數如下:

2. 修改項目的__init__.py 文件,添加如下代碼:
import pymysqlpymysql.install_as_MySQLdb()
二、模型和字段
一個模型(model)就是一個單獨的、確定的數據的信息源,包含了數據的字段和操作方法。通常,每個模型映射為一張數據庫中的表。
基本的原則如下:
1.每個模型在 Django 中的存在形式為一個 Python 類
2.每個模型都是 django.db.models.Model 的子類
3.模型的每個字段(屬性)代表數據表的某一列
4.Django 將自動為你生成數據庫訪問 API
5.Django 會為表增加自動增長的主鍵列,每個模型只能有一個主鍵列。如果自定義主鍵列,則 Django 不會再生成默認的主鍵列
6.表名由 Django 自動生成,默認格式為“項目名稱_小寫模型類名”,也可以自己通過 Meta 來自定義
例如:
定義模型類 Person:

相當于下面的 SQL 語句:
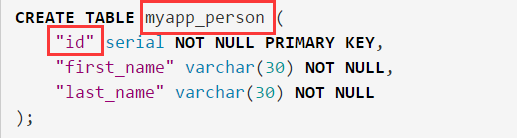
創建了模型之后,在使用它之前,你需要先在 settings 文件中的INSTALLED_APPS 處,注冊 models.py 文件所在的 myapp。當你每次對模型進行增、刪、修改時,請務必執行命令 python manage.py?migrate,讓操作實際應用到數據庫上。這里可以選擇在執行 migrate 之前,先執行 python manage.py makemigrations 讓修改動作保存到記錄文件中。
2.1 模型字段 fields
字段是模型中最重要的內容之一,也是唯一必須的部分。字段在 Python 中表現為一個類屬性,體現了數據表中的一個列。

字段命名約束:
Django 不允許下面兩種字段名:
1.與 Python 關鍵字沖突。這會導致語法錯誤。
2.字段名中不能有兩個以上下劃線在一起,因為兩個下劃線是 Django 的查詢語法。
由于你可以自定義表名、列名,上面的規則可能被繞開,但是請養成良好的習慣,一定不要那么起名。
2.2 常用字段類型
字段類型的作用:
1.決定數據庫中對應列的數據類型(例如:INTEGER, VARCHAR, TEXT)
2.? HTML 中對應的表單標簽的類型,例如<input type=“text” />
3.在 admin 后臺和自動生成的表單中最小的數據驗證需求
Django 內置了許多字段類型,它們都位于 django.db.models 中,例如models.CharField。這些類型基本滿足需求,如果還不夠,你也可以自定義字段。
下表列出了所有 Django 內置的字段類型,但不包括關系字段類型(字段名采用駝峰命名法)
| 類型? | 說明 |
| AutoField? | 一個自動增加的整數類型字段。通常你不需要自己編寫它,Django 會自動幫你添加字段:id =models.AutoField(primary_key=True),這是一個自增字段,從 1 開始計數。 如果你非要自己設置主鍵,那么請務必將字段設置為 primary_key=True。Django 在一個模型中只允許有一個自增字段,并且該字段必須為主鍵! |
| BigAutoField? | (1.10 新增)64 位整數類型自增字段,數字范圍更大,從 1 到 9223372036854775807 |
| BigIntegerField | 64 位整數字段(看清楚,非自增),類似 IntegerField ,-9223372036854775808 到9223372036854775807。在 Django 的模板表單里體現為一個 textinput 標簽 |
| BinaryField? | 二進制數據類型。使用受限,少用。 |
| BooleanField? | 布爾值類型。默認值是 None。在 HTML 表單中體現為 CheckboxInput 標簽。如果要接收 null 值,請使用 NullBooleanField。 |
| CharField | 字符串類型。必須接收一個 max_length 參數,表示字符串長度不能超過該值。默認的表單標簽是input text。最常用的 filed,沒有之一! |
| CommaSeparatedIntegerField | 逗號分隔的整數類型。必須接收一個 max_length 參數。常用于表示較大的金額數目,例如1,000,000 元。 |
| DateField? | class DateField(auto_now=False, auto_now_add=False, **options)日期類型。一個Python 中的 datetime.date 的實例。在 HTML 中表現為 TextInput 標簽。 在 admin 后臺中,Django 會幫你自動添加一個 JS 的日歷表和一個“Today”快捷方式,以及附加的日期合法性驗證。兩個重要參數:(參數互斥,不能共存) auto_now: 每當對象被保存時將字段設為當前日期,常用于保存最后修改時間。auto_now_add:每當對象被創建時,設為當前日期,常用于保存創建日期(注意,它是不可修改的)。 例子:pub_time = models.DateField(auto_now_add=True),自動添加發布時間。 |
| DateTimeField? | 日期時間類型。Python 的 datetime.datetime 的實例。與 DateField 相比就是多了小時、分和秒的顯示,其它功能、參數、用法、默認值等等都一樣。 |
| DecimalField? | 固定精度的十進制小數。相當于 Python 的 Decimal 實例,必須提供兩個指定的參數!參數max_digits:最大的位數,必須大于或等于小數點位數 。 decimal_places:小數點位數,精度。當 localize=False 時,它在 HTML 表現為 NumberInput 標簽,否則是 text 類型。例子:儲存最大不超過 999, 帶有 2 位小數位精度的數, 定義如下:models.DecimalField(...,max_digits=5, decimal_places=2)。 |
| DurationField? | 持續時間類型。存儲一定期間的時間長度。類似 Python 中的 timedelta。在不同的數據庫實現中有不同的表示方法。常用于進行時間之間的加減運算。 |
| EmailField | 郵箱類型,默認 max_length 最大長度 254 位。使用這個字段的好處是,可以使用 DJango 內置的EmailValidator 進行郵箱地址合法性驗證。 |
| FileField? | class FileField(upload_to=None, max_length=100, **options)上傳文件類型 |
| FilePathField | 文件路徑類型 |
| FloatField?? | 浮點數類型,參考整數類型 |
| ImageField | 圖像類型 |
| IntegerField? | 整數類型,最常用的字段之一。取值范圍-2147483648 到 2147483647。在 HTML 中表現為NumberInput 標簽。 |
| GenericIPAddressField | class GenericIPAddressField(protocol='both', unpack_ipv4=False,**options)[source],IPV4 或者 IPV6 地址,字符串形式, 例如 192.0.2.30 或者 2a02:42fe::4 在HTML 中表現為 TextInput 標簽。參數 protocol 默認值為‘both’,可選‘IPv4’或者‘IPv6’,表示你的 IP 地址類型。 |
| NullBooleanField | 類似布爾字段,只不過額外允許 NULL 作為選項之一。 |
| PositiveIntegerField | 正整數字段,包含 0,最大 2147483647。 |
| PositiveSmallIntegerField | 較小的正整數字段,從 0 到 32767。 |
| SlugField | slug 是一個新聞行業的術語。一個 slug 就是一個某種東西的簡短標簽,包含字母、數字、下劃線或者連接線,通常用于 URLs 中。可以設置 max_length 參數,默認為 50。 |
| SmallIntegerField? | 小整數,包含-32768 到 32767。 |
| TextField? | 大量文本內容,在 HTML 中表現為 Textarea 標簽,最常用的字段類型之一!如果你為它設置一個max_length 參數,那么在前端頁面中會受到輸入字符數量限制, 然而在模型和數據庫層面卻不受影響。只有 CharField 才能同時作用于兩者。 |
| TimeField | 時間字段,Python 中 datetime.time 的實例。接收同 DateField 一樣的參數,只作用于小時、分和秒。 |
| URLField? | 一個用于保存 URL 地址的字符串類型,默認最大長度 200。 |
| UUIDField | 用于保存通用唯一識別碼(Universally Unique Identifier)的字段。使用 Python 的 UUID 類。 |
?其中,
1. FileField:
class FileField(upload_to=None, max_length=100, **options)[source]
上傳文件字段(不能設置為主鍵)。默認情況下,該字段在 HTML 中表現為一個ClearableFileInput 標簽。在數據庫內,我們實際保存的是一個字符串類型,默認最大長度 100,可以通過 max_length 參數自定義。真實的文件是保存在服務器的文件系統內的。
重要參數 upload_to 用于設置上傳地址的目錄和文件名。如下例所示:
class MyModel(models.Model):# 文件被傳至`MEDIA_ROOT/uploads`目錄,MEDIA_ROOT 由你在 settings 文件中設置 upload = models.FileField(upload_to='uploads/')
2. ImageField
class ImageField(upload_to=None, height_field=None, width_field=None,max_length=100, **options)[source]
用于保存圖像文件的字段。其基本用法和特性與 FileField 一樣,只不過多了兩個屬性height 和 width。默認情況下,該字段在 HTML 中表現為一個 ClearableFileInput 標簽。
在數據庫內,我們實際保存的是一個字符串類型,默認最大長度 100,可以通過max_length 參數自定義。真實的圖片是保存在服務器的文件系統內的。
height_field 參數:保存有圖片高度信息的模型字段名。 width_field 參數:保存有圖片寬度信息的模型字段名。
使用 Django 的 ImageField 需要提前安裝 pillow 模塊。
使用 FileField 或者 ImageField 字段的步驟:
1. 在 settings 文件中,配置 MEDIA_ROOT,作為你上傳文件在服務器中的基本路徑(為了性能考慮,這些文件不會被儲存在數據庫中)。再配置個 MEDIA_URL,作為公用 URL,指向上傳文件的基本路徑。
2. 添加 FileField 或者 ImageField 字段到你的模型中,定義好 upload_to 參數,文件最終會放在 MEDIA_ROOT 目錄的“upload_to”子目錄中。
3. 真正被保存在數據庫中的,只是指向你上傳文件路徑的字符串而已。可以通過 url屬性,在 Django 的模板中方便的訪問這些文件。例如,假設你有一個 ImageField字段,名叫 mug_shot,那么在 Django 模板的 HTML 文件中,可以使用{{ object.mug_shot.url }}來獲取該文件。其中的 object 用你具體的對象名稱代替。
4. 可以通過 name 和 size 屬性,獲取文件的名稱和大小信息。
安全建議
無論你如何保存上傳的文件,一定要注意他們的內容和格式,避免安全漏洞!務必對所有的上傳文件進行安全檢查,確保它們不出問題!
2.3 關系類型字段
除了前面說過的普通類型字段,Django 還定義了一組關系類型字段,用來表示模型與模型之間的關系。
主要包括:
1.多對一:ForeignKey
2.多對多:ManyToManyField
3.一對一:OneToOneField
1)、多對一(ForeignKey)
多對一的關系,通常被稱為外鍵。
外鍵要定義在‘多’的一方!
from django.db import models class Car(models.Model):manufacturer = models.ForeignKey('Manufacturer', ) class Manufacturer(models.Model):pass
上面的例子中,每輛車都會有一個生產工廠,一個工廠可以生產 N 輛車,于是用一個外鍵字段 manufacturer 表示,并放在 Car 模型中。注意,此 manufacturer 非彼Manufacturer 模型類,它是一個字段的名稱。
如果要關聯的對象在另外一個 app 中,可以顯式的指出。下例假設 Manufacturer 模型存在于 production 這個 app 中,則 Car 模型的定義如下:
class Car(models.Model):manufacturer = models.ForeignKey('production.Manufacturer', # 關鍵在這里!! )
如果要創建一個遞歸的外鍵,也就是自己關聯自己的的外鍵,使用下面的方法:
models.ForeignKey('self', on_delete=models.CASCADE)
核心在于‘self’這個引用。什么時候需要自己引用自己的外鍵呢?典型的例子就是評論系統!
在實際的數據庫后臺,Django 會為每一個外鍵添加_id 后綴,并以此創建數據表里的一列。在上面的工廠與車的例子中,Car 模型對應的數據表中,會有一列叫做manufacturer_id。但實際上,在 Django 代碼中你不需要使用這個列名,一般我們都直接使用字段名 manufacturer。
參數說明:
外鍵還有一些重要的參數,說明如下:
on_delete
當一個被外鍵關聯的對象被刪除時,Django 將模仿 on_delete 參數定義的 SQL 約束執行相應操作。
該參數可選的值都內置在 django.db.models 中,包括:
1.CASCADE:模擬 SQL 語言中的 ON DELETE CASCADE 約束,將定義有外鍵的模型對象同時刪除!(該操作為當前 Django 版本的默認操作!)
2.PROTECT:阻止上面的刪除操作,但是彈出 ProtectedError 異常
3.SET_NULL:將外鍵字段設為 null,只有當字段設置了 null=True 時,方可使用該值。
4.SET_DEFAULT:將外鍵字段設為默認值。只有當字段設置了 default 參數時,方可使用。
5.DO_NOTHING:什么也不做。
6.SET():設置為一個傳遞給 SET()的值或者一個回調函數的返回值。注意大小寫。
limit_choices_to
該參數用于限制外鍵所能關聯的對象,只能用于 Django 的 ModelForm(Django 的表單模塊)和 admin 后臺,對其它場合無限制功能。其值可以是一個字典、Q 對象或者一個返回字典或 Q 對象的函數調用。
related_name
用于關聯對象反向引用模型的名稱。以英雄和書的例子解釋,就是從書反向關聯到英雄的關系名稱。通常情況下,這個參數我們可以不設置,Django 會默認以模型的小寫作為反向關聯名。
related_query_name
反向關聯查詢名。用于從目標模型反向過濾模型對象的名稱。
to_field
默認情況下,外鍵都是關聯到被關聯對象的主鍵上(一般為 id)。如果指定這個參數,可以關聯到指定的字段上,但是該字段必須具有 unique=True 屬性,也就是具有唯一屬性。
db_constraint
默認情況下,這個參數被設為 True,表示遵循數據庫約束,這也是大多數情況下你的選擇。如果設為 False,那么將無法保證數據的完整性和合法性。
swappable
控制遷移框架的動作,如果當前外鍵指向一個可交換的模型。使用場景非常稀少,通常請將該參數保持默認的 True。
2)、多對多(ManyToManyField)
多對多關系在數據庫中也是非常常見的關系類型。比如一本書中可以有好幾個英雄,一個英雄也可以出現在幾本書中。多對多的字段可以定義在任何的一方,請盡量定義在符合人們思維習慣的一方,但不要同時都定義。
在數據庫后臺,Django 實際上會額外創建一張用于體現多對多關系的中間表。默認情況下,該表的名稱是“多對多字段名+關聯對象模型名+一個獨一無二的哈希碼”
重要參數:
through
(定義中間表)
如果你想自定義多對多關系的那張額外的關聯表,可以使用這個參數。參數的值為一個中間模型。
看下面的例子:
from django.db import models
class Person(models.Model):name = models.CharField(max_length=50)
class Group(models.Model):name = models.CharField(max_length=128)members = models.ManyToManyField(Person,through='Membership', ## 自定義中間表through_fields=('group', 'person'),)
class Membership(models.Model): # 這就是具體的中間表模型
group = models.ForeignKey(Group, on_delete=models.CASCADE)
person = models.ForeignKey(Person, on_delete=models.CASCADE)
inviter = models.ForeignKey(
Person,
on_delete=models.CASCADE,
related_name="membership_invites",
)
invite_reason = models.CharField(max_length=64)
上面的代碼中,通過 class Membership(models.Model)定義了一個新的模型,用來保存 Person 和 Group 模型的多對多關系,并且同時增加了‘邀請人’和‘邀請原因’的字段。
through_fields
接著上面的例子。Membership 模型中包含兩個關聯 Person 的外鍵,Django 無法確定到底使用哪個作為和 Group 關聯的對象。所以,在這個例子中,必須顯式的指定through_fields 參數,用于定義關系。
through_fields 參數接收一個二元元組('field1', 'field2'),field1 是指向定義有多對多關系的模型的外鍵字段的名稱,這里是 Membership 中的‘group’字段(注意大小寫),另外一個則是指向目標模型的外鍵字段的名稱,這里是 Membership 中的‘person’,而不是‘inviter’。
再通俗的說,就是 through_fields 參數指定從中間表模型 Membership 中選擇哪兩個字段,作為關系連接字段。
db_table
設置中間表的名稱。不指定的話,則使用默認值。
db_constraint
參考外鍵的相同參數。
swappable
參考外鍵的相同參數。
ManyToManyField 多對多字段不支持 Django 內置的 validators 驗證功能。
null 參數對 ManyToManyField 多對多字段無效!設置 null=True 毫無意義
3)、一對一(OneToOneField)
這種關系類型多數用于當一個模型需要從別的模型擴展而來的情況。比如,Django 自帶 auth 模塊的 User 用戶表,如果你想在自己的項目里創建用戶模型,又想方便的使用 Django 的認證功能,那么一個比較好的方案就是在你的用戶模型里,使用一對一關系,添加一個與 auth 模塊 User 模型的關聯字段。
看下面的例子:
from django.conf import settings from django.db import models # 兩個字段都使用一對一關聯到了 Django 內置的 auth 模塊中的 User 模型 class MySpecialUser(models.Model):user = models.OneToOneField(settings.AUTH_USER_MODEL,on_delete=models.CASCADE, ) supervisor = models.OneToOneField(settings.AUTH_USER_MODEL,on_delete=models.CASCADE,related_name='supervisor_of', )
這樣下來,你的 User 模型將擁有下面的屬性:
>>> user = User.objects.get(pk=1)
>>> hasattr(user, 'myspecialuser')
True
>>> hasattr(user, 'supervisor_of')
True
跨模塊的模型:
有時候,我們關聯的模型并不在當前模型的文件內,沒關系,就像我們導入第三方庫一樣的從別的模塊內導入進來就好,如下例所示:
from django.db import models from geography.models import ZipCode class Restaurant(models.Model):# ...zip_code = models.ForeignKey(ZipCode,on_delete=models.SET_NULL,blank=True,null=True,)
?2.4 字段的參數
?
所有的模型字段都可以接收一定數量的參數,比如 CharField 至少需要一個max_length 參數。下面的這些參數是所有字段都可以使用的,并且是可選的。
null
該值為 True 時,Django 在數據庫用 NULL 保存空值。默認值為 False。
blank
True 時,字段可以為空。默認 False。和 null 參數不同的是,null 是純數據庫層面的,而 blank 是驗證相關的,它與表單驗證是否允許輸入框內為空有關,與數據庫無關。
choices
用于頁面上的選擇框標簽,需要先提供一個二維的二元元組,第一個元素表示存在數據庫內真實的值,第二個表示頁面上顯示的具體內容。在瀏覽器頁面上將顯示第二個元素的值。
db_column
該參數用于定義當前字段在數據表內的列名。如果未指定,Django 將使用字段名作為列名。
db_index
該參數接收布爾值。如果為 True,數據庫將為該字段創建索引。
db_tablespace
用于字段索引的數據庫表空間的名字,前提是當前字段設置了索引。默認值為工程的DEFAULT_INDEX_TABLESPACE 設置。如果使用的數據庫不支持表空間,該參數會被忽略。
default
字段的默認值,可以是值或者一個可調用對象。如果是可調用對象,那么每次創建新對象時都會調用。設置的默認值不能是一個可變對象,比如列表、集合等等。lambda匿名函數也不可用于 default 的調用對象,因為匿名函數不能被 migrations 序列化。
editable
如果設為 False,那么當前字段將不會在 admin 后臺或者其它的 ModelForm 表單中顯示,同時還會被模型驗證功能跳過。參數默認值為 True。
error_messages
用于自定義錯誤信息。參數接收字典類型的值。字典的鍵可以是null、 blank、 invalid、 invalid_choice、 unique 和 unique_for_date 其中的一個。
help_text
額外顯示在表單部件上的幫助文本。使用時請注意轉義為純文本,防止腳本攻擊。
primary_key
如果你沒有給模型的任何字段設置這個參數為 True,Django 將自動創建一個AutoField 自增字段,名為‘id’,并設置為主鍵。也就是 id =models.AutoField(primary_key=True)。
如果你為某個字段設置了 primary_key=True,則當前字段變為主鍵,并關閉 Django自動生成 id 主鍵的功能。
primary_key=True 隱含 null=False 和 unique=True 的意思。一個模型中只能有一個主鍵字段!
unique_for_date
日期唯一。可能不太好理解。舉個栗子,如果你有一個名叫 title 的字段,并設置了參數 unique_for_date="pub_date",那么 Django 將不允許有兩個模型對象具備同樣的title 和 pub_date。有點類似聯合約束。
unique_for_month
同上,只是月份唯一。
unique_for_year
同上,只是年份唯一。
verbose_name
為字段設置一個人類可讀,更加直觀的別名。
對于每一個字段類型,除了 ForeignKey、ManyToManyField 和 OneToOneField 這三個特殊的關系類型,其第一可選位置參數都是 verbose_name。如果沒指定這個參數,Django 會利用字段的屬性名自動創建它,并將下劃線轉換為空格。
下面這個例子的 verbose name 是"person’s first name":
first_name = models.CharField("person's first name", max_length=30)
下面這個例子的 verbose name 是"first name":
first_name = models.CharField(max_length=30)
對于外鍵、多對多和一對一字字段,由于第一個參數需要用來指定關聯的模型,因此必須用關鍵字參數 verbose_name 來明確指定。
validators
運行在該字段上的驗證器的列表。
三、 模型的元數據 Meta
模型的元數據,指的是“除了字段外的所有內容”,例如排序方式、數據庫表名、人類可讀的單數或者復數名等等。所有的這些都是非必須的,甚至元數據本身對模型也是非必須的。
想在模型中增加元數據,方法很簡單,在模型類中添加一個子類,名字是固定的 Meta,然后在這個 Meta 類下面增加各種元數據選項或者說設置項。參考下面的例子:
from django.db import models class Ox(models.Model):horn_length = models.IntegerField()class Meta: # 注意,是模型的子類,要縮進!ordering = ["horn_length"]
上面的例子中,我們為模型 Ox 增加了一個元數據‘ordering’,表示排序,下面我們會詳細介紹有哪些可用的元數據選項。
強調:每個模型都可以有自己的元數據類,每個元數據類也只對自己所在模型起作用。
元數據選項:
abstract
如果 abstract=True,那么模型會被認為是一個抽象模型。抽象模型本身不實際生成數據庫表,而是作為其它模型的父類,被繼承使用。
app_label
如果定義了模型的 app 沒有在 INSTALLED_APPS 中注冊,則必須通過此元選項聲明它屬于哪個 app,例如:app_label = 'myapp'
base_manager_name
自定義模型的_base_manager 管理器的名字。模型管理器是 Django 為模型提供的 API所在。
db_table
指定在數據庫中,當前模型生成的數據表的表名。比如:db_table = 'my_freinds'
友情建議:使用 MySQL 數據庫時,db_table 用小寫英文。
db_tablespace
自定義數據庫表空間的名字。默認值是工程的 DEFAULT_TABLESPACE 設置。
default_manager_name
自定義模型的_default_manager 管理器的名字。
default_related_name
默認情況下,從一個模型反向關聯設置有關系字段的源模型,我們使用<model_name>_set,也就是源模型的名字+下劃線+set。
get_latest_by
Django 管理器給我們提供有 latest()和 earliest()方法,分別表示獲取最近一個和最前一個數據對象。但是,如何來判斷最近一個和最前面一個呢?也就是根據什么來排序呢?
get_latest_by 元數據選項幫你解決這個問題,它可以指定一個類似 DateField、DateTimeField 或者 IntegerField 這種可以排序的字段,作為 latest()和 earliest()方法的排序依據,從而得出最近一個或最前面一個對象。例如:get_latest_by = "order_date"
managed
該元數據默認值為 True,表示 Django 將按照既定的規則,管理數據庫表的生命周期。如果設置為 False,將不會針對當前模型創建和刪除數據庫表。在某些場景下,這可能有用,但更多時候,你可以忘記該選項。
order_with_respect_to
其用途是根據指定的字段進行排序,通常用于關系字段。
ordering
用于指定該模型生成的所有對象的排序方式,接收一個字段名組成的元組或列表。默認按升序排列,如果在字段名前加上字符“-”則表示按降序排列,如果使用字符問號“?”表示隨機排列。請看下面的例子:
ordering = ['pub_date'] # 表示按'pub_date'字段進行升序排列
ordering = ['-pub_date'] # 表示按'pub_date'字段進行降序排列
ordering = ['-pub_date', 'author'] # 表示先按'pub_date'字段進行降序排列,
再按`author`字段進行升序排列。
permissions
該元數據用于當創建對象時增加額外的權限。它接收一個所有元素都是二元元組的列表或元組,每個元素都是(權限代碼, 直觀的權限名稱)的格式。比如下面的例子:permissions = (("can_deliver_pizzas", "可以送披薩"),)
default_permissions
Django 默認給所有的模型設置('add', 'change', 'delete')的權限,也就是增刪改。你可以自定義這個選項,比如設置為一個空列表,表示你不需要默認的權限,但是這一操作必須在執行 migrate 命令之前。
proxy
如果設置了 proxy = True,表示使用代理模式的模型繼承方式。
required_db_features
聲明模型依賴的數據庫功能。
required_db_vendor
聲明模型支持的數據庫。Django 默認支持 sqlite, postgresql, mysql, oracle。
indexes
Django1.11 新增的選項。
接收一個應用在當前模型上的索引列表。
unique_together
舉個例子,假設有一張用戶表,保存有用戶的姓名、出生日期、性別和籍貫等等信息。
要求是所有的用戶唯一不重復,可現在有好幾個叫“張偉”的,如何區別它們呢?(不要和我說主鍵唯一,這里討論的不是這個問題)
我們可以設置不能有兩個用戶在同一個地方同一時刻出生并且都叫“張偉”,使用這種聯合約束,保證數據庫能不能重復添加用戶。在 Django 的模型中,如何實現這種約束呢?
使用 unique_together,也就是聯合唯一!比如:unique_together = (('name', 'birth_day', 'address'),)
這樣,哪怕有兩個在同一天出生的張偉,但他們的籍貫不同,也就是兩個不同的用戶。
一旦三者都相同,則會被 Django 拒絕創建。這一元數據經常被用在 admin 后臺,并且強制應用于數據庫層面。
unique_together 接收一個二維的元組((xx,xx,xx,...),(),(),()...),每一個元素都是一個元組,表示一組聯合唯一約束,可以同時設置多組約束。為了方便,對于只有一組約束的情況下,可以簡單地使用一維元素,例如:
unique_together = ('name', 'birth_day', 'address')
聯合唯一無法作用于普通的多對多字段。
verbose_name
用于設置模型對象的直觀、人類可讀的名稱。可以用中文。例如:
verbose_name = "story"
verbose_name = "披薩"
如果你不指定它,那么 Django 會使用小寫的模型名作為默認值。
verbose_name_plural
英語有單數和復數形式。這個就是模型對象的復數名,比如“apples”。因為我們中
文通常不區分單復數,所以保持和 verbose_name 一致也可以。
verbose_name_plural = "stories"
verbose_name_plural = "披薩"
如果不指定該選項,那么默認的復數名字是 verbose_name 加上‘s’
label
前面介紹的元數據都是可修改和設置的,但還有兩個只讀的元數據,label 就是其中之一。
label 等同于 app_label.object_name。例如 booktest.BookInfo,polls 是應用名,Question 是模型名。
label_lower
同上,不過是小寫的模型名。
四、 模型對象查詢操作
查詢操作是 Django 的 ORM 框架中最重要的內容之一。我們建立模型、保存數據為的就是在需要的時候可以查詢得到數據。Django 自動為所有的模型提供了一套完善、方便、高效的 API,一些重要的,我們要背下來,一些不常用的,要有印象,使用的時候可以快速查找參考手冊。
4.1、創建對象
假設模型位于 mysite/booktest/models.py 文件中,那么創建對象的方式如下:
>>> from booktest.models import BookInfo
>>> b = BookInfo(btitle='笑傲江湖',
bpub_date=datetime(year=1968,month=1,day=1))
>>> b.save()
在后臺,這會運行一條 SQL 的 INSERT 語句。如果你不顯式地調用 save()方法,Django 不會立刻將該操作反映到數據庫中。save()方法沒有返回值,它可以接受一些額外的參數。
如果想要一行代碼完成上面的操作,請使用 creat()方法,它可以省略 save 的步驟:
b = Blog.objects.create(btitle='笑傲江湖',
bpub_date=datetime(year=1968,month=1,day=1))
4.2、保存對象
使用 save()方法,保存對數據庫內已有對象的修改。例如如果已經存在 b5 對象在數據庫內:
>>> b5.name = 'New name'
>>> b5.save()
在后臺,這會運行一條 SQL 的 UPDATE 語句。如果你不顯式地調用 save()方法,Django 不會立刻將該操作反映到數據庫中。
4.3、檢索對象
想要從數據庫內檢索對象,你需要基于模型類,通過管理器(Manager)構造一個查詢結果集(QuerySet)。
每個 QuerySet 代表一些數據庫對象的集合。它可以包含零個、一個或多個過濾器(filters)。Filters 縮小查詢結果的范圍。在 SQL 語法中,一個 QuerySet 相當于一個SELECT 語句,而 filter 則相當于 WHERE 或者 LIMIT 一類的子句。
通過模型的 Manager 獲得 QuerySet,每個模型至少具有一個 Manager,默認情況下,它被稱作 objects,可以通過模型類直接調用它,但不能通過模型類的實例調用它。
4.3.1. 檢索所有對象
使用 all()方法,可以獲取某張表的所有記錄。
>>> all_books = BookInfo.objects.all()
4.3.2. 過濾對象
有兩個方法可以用來過濾 QuerySet 的結果,分別是:
1.filter(**kwargs):返回一個根據指定參數查詢出來的 QuerySet
2.exclude(**kwargs):返回除了根據指定參數查詢出來結果的 QuerySet
其中,**kwargs 參數的格式必須是 Django 設置的一些字段格式。例如:
BookInfo.objects.filter(pub_date__year=2006)
鏈式過濾
filter 和 exclude 的結果依然是個 QuerySet,因此它可以繼續被 filter 和 exclude,這就形成了鏈式過濾:
>>> BookInfo.objects.filter(
... btitle__startswith='笑'
... ).exclude(
... bpub_date__gte=datetime.date.today()
... ).filter(
... bpub_date__gte=datetime(2005, 1, 30)
... )
被過濾的 QuerySets 都是唯一的
每一次過濾,你都會獲得一個全新的 QuerySet,它和之前的 QuerySet 沒有任何關系,可以完全獨立的被保存,使用和重用。例如:
>>> q1 = BookInfo.objects.filter(btitle__startswith="笑")
>>> q2 = q1.exclude(bpub_date__gte=datetime.date.today())
>>> q3 = q1.filter(bpub_date__gte=datetime.date.today())
例子中的 q2 和 q3 雖然由 q1 得來,是 q1 的子集,但是都是獨立自主存在的。同樣 q1也不會受到 q2 和 q3 的影響。
QuerySets 都是懶惰的
一個創建 QuerySets 的動作不會立刻導致任何的數據庫行為。你可以不斷地進行 filter動作一整天,Django 不會運行任何實際的數據庫查詢動作,直到 QuerySets 被提交(evaluated)。
簡而言之就是,只有碰到某些特定的操作,Django 才會將所有的操作體現到數據庫內,否則它們只是保存在內存和 Django 的層面中。這是一種提高數據庫查詢效率,減少操作次數的優化設計。看下面的例子:
>>> q = BookInfo.objects.filter(btitle__startswith="笑")
>>> q = q.filter(bpub_date__lte=datetime.date.today())
>>> print(q)
上面的例子,看起來執行了 2 次數據庫訪問,實際上只是在 print 語句時才執行 1 次訪問。通常情況,QuerySets 的檢索不會立刻執行實際的數據庫查詢操作,直到出現類似print 的請求,也就是所謂的 evaluated。
返回新 QuerySets 的 API
| 方法名? | 解釋 |
| filter() | 過濾查詢對象。 |
| exclude() | 排除滿足條件的對象 |
| annotate() | 使用聚合函數 |
| order_by() | 對查詢集進行排序 |
| reverse() | 反向排序 |
| distinct() | 對查詢集去重 |
| values() | 返回包含對象具體值的字典的 QuerySet |
| values_list() | 與 values()類似,只是返回的是元組而不是字典。 |
| dates() | 根據日期獲取查詢集 |
| datetimes() | 根據時間獲取查詢集 |
| none() | 創建空的查詢集 |
| all() | 獲取所有的對象 |
| union() | 并集 |
| intersection() | 交集 |
| difference() | 差集 |
| select_related() | 附帶查詢關聯對象 |
| prefetch_related() | 預先查詢 |
| extra() | 附加 SQL 查詢 |
| defer() | 不加載指定字段 |
| only() | 只加載指定的字段 |
| using() | 選擇數據庫 |
| select_for_update() | 鎖住選擇的對象,直到事務結束。 |
| raw() | 接收一個原始的 SQL 查詢 |
?
可以使用下列方法對 QuerySet 提交查詢操作:
? 1.迭代:QuerySet 是可迭代的,在首次迭代查詢集時執行實際的數據庫查詢。
? 2.切片:如果使用切片的”step“參數,Django 將執行數據庫查詢并返回一個列表。
? 3. len():當你對 QuerySet 調用 len()時, 將提交數據庫操作。
? 4.list():對 QuerySet 調用 list()將強制提交操作 book_list =
list(BookInfo.objects.all())
? 5.bool()
4.3.3. 檢索單一對象
filter 方法始終返回的是 QuerySets,那怕只有一個對象符合過濾條件,返回的也是包含一個對象的 QuerySets,這是一個集合類型對象,你可以簡單的理解為 Python 列表,可迭代可循環可索引。
如果你確定你的檢索只會獲得一個對象,那么你可以使用 Manager 的 get()方法來直接返回這個對象。
>>> one_book = BookInfo.objects.get(pk=1)
在 get 方法中你可以使用任何 filter 方法中的查詢參數,用法也是一模一樣。
注意:如果在查詢時沒有匹配到對象,那么 get()方法將拋出 DoesNotExist 異常。
這個異常是模型類的一個屬性,在上面的例子中,如果不存在主鍵為 1 的 Entry 對象,那么 Django 將拋出 Entry.DoesNotExist 異常。
類似地,在使用 get()方法查詢時,如果結果超過 1 個,則會拋出MultipleObjectsReturned 異常,這個異常也是模型類的一個屬性。
所以:get()方法要慎用!
不返回 QuerySets 的 API
| 方法名 | 解釋 |
| get() | 獲取單個對象 |
| create() | 創建對象,無需 save() |
| get_or_create() | 查詢對象,如果沒有找到就新建對象 |
| update_or_create() | 更新對象,如果沒有找到就創建對象 |
| bulk_create() | 批量創建對象 |
| count() | 統計對象的個數 |
| in_bulk() | 根據主鍵值的列表,批量返回對象 |
| iterator() | 獲取包含對象的迭代器 |
| latest() | 獲取最近的對象 |
| earliest() | 獲取最早的對象 |
| first() | 獲取第一個對象 |
| last() | 獲取最后一個對象 |
| aggregate() | 聚合操作 |
| exists() | 判斷 queryset 中是否有對象 |
| update() | 批量更新對象 |
| delete() | 批量刪除對象 |
| as_manager() | 獲取管理器 |
?
聚合操作
使用 aggregate()函數返回聚合函數的值。
聚合函數包括:Avg,Count,Max,Min,Sum
用法:
from django.db.models import Max
maxDate = list.aggregate(Max(‘bpub_date’))
4.3.4. QuerySet 中使用限制
使用類似 Python 對列表進行切片的方法可以對 QuerySet 進行范圍取值。它相當于SQL 語句中的 LIMIT 和 OFFSET 子句。參考下面的例子:
>>> BookInfo.objects.all()[:5] # 返回前 5 個對象
>>> BookInfo.objects.all()[5:10] # 返回第 6 個到第 10 個對象
注意:不支持負索引!例如 Entry.objects.all()[-1]是不允許的
通常情況,切片操作會返回一個新的 QuerySet,并且不會被立刻執行。但是有一個例外,那就是指定步長的時候,查詢操作會立刻在數據庫內執行,如下:
>>> BookInfo.objects.all()[:10:2]
4. 3.5. 字段查詢
字段查詢其實就是 filter()、exclude()和 get()等方法的關鍵字參數。 其基本格式是:
field__lookuptype=value,注意其中是雙下劃線。 例如:
>>> BookInfo.objects.filter(bpub_date__lte='2006-01-01')
# 相當于:
SELECT * FROM booktest_bookinfo WHERE bpub_date <= '2006-01-01';
其中的字段必須是模型中定義的字段之一。但是有一個例外,那就是 ForeignKey 字段,你可以為其添加一個“_id”后綴(單下劃線)。例如:
>>> HeroInfo.objects.filter(book_id=4)
如果你傳遞了一個非法的鍵值,查詢函數會拋出 TypeError 異常。
Django 的數據庫 API 支持 20 多種查詢類型,下面介紹一些常用的:
exact:
默認類型。如果你不提供查詢類型,或者關鍵字參數不包含一個雙下劃線,那么查詢類型就是這個默認的 exact。
>>> Entry.objects.get(headline__exact="Cat bites dog")
# 相當于
# SELECT ... WHERE headline = 'Cat bites dog';
iexact:
不區分大小寫。
>>> Blog.objects.get(name__iexact="beatles blog")
# 匹配"Beatles Blog", "beatles blog",甚至"BeAtlES blOG".
contains:
表示包含的意思!大小寫敏感!
Entry.objects.get(headline__contains='Lennon')
# 相當于
# SELECT ... WHERE headline LIKE '%Lennon%';
# 匹配'Today Lennon honored',但不匹配'today lennon honored'
icontains:
contains 的大小寫不敏感模式。
startswith 和 endswith
以什么開頭和以什么結尾。大小寫敏感!
istartswith 和 iendswith
是不區分大小寫的模式。
下表列出了所有的字段查詢參數:
| 字段名? | 說明 |
| exact | 精確匹配 |
| iexact | 不區分大小寫的精確匹配 |
| contains | 包含匹配 |
| icontains | 不區分大小寫的包含匹配 |
| in | 在..之內的匹配 |
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
| startswith | 從開頭匹配 |
| istartswith | 不區分大小寫從開頭匹配 |
| endswith | 從結尾處匹配 |
| iendswith | 不區分大小寫從結尾處匹配 |
| range | 范圍匹配 |
| date | 日期匹配 |
| year | 年份 |
| month | 月份 |
| day | 日期 |
| week | 第幾周 |
| week_day | 周幾 |
| time | 時間 |
| hour | 小時 |
| minute | 分鐘 |
| second | 秒 |
| isnull | 判斷是否為空 |
| search | 1.10 中被廢棄 |
| regex | 區分大小寫的正則匹配 |
| iregex | 不區分大小寫的正則匹配 |
?
4.3.6. 跨越關系查詢
Django 提供了強大并且直觀的方式解決跨越關聯的查詢,它在后臺自動執行包含JOIN 的 SQL 語句。要跨越某個關聯,只需使用關聯的模型字段名稱,并使用雙下劃線分隔,直至你想要的字段(可以鏈式跨越,無限跨度)。例如:
# 返回所有 BookInfo 的 btitle 為'笑傲江湖'的 HeroInfo 對象
# 一定要注意,返回的是 HeroInfo 對象,而不是 BookInfo 對象。
# objects 前面用的是哪個 class,返回的就是哪個 class 的對象。
>>> HeroInfo.objects.filter(book__btitle)='笑傲江湖’)
反之亦然,如果要引用一個反向關聯,只需要使用模型的小寫名!
# 獲取所有的 BookInfo 對象,前提是它所關聯的 HeroInfo 的 hcomment 包含'八'
>>>BookInfo.objects.filter(heroinfo__hcomment__contains='八')
4.3.7. 使用 F 表達式引用模型的字段
到目前為止的例子中,我們都是將模型字段與常量進行比較。但是,如果你想將模型的一個字段與同一個模型的另外一個字段進行比較該怎么辦?
使用 Django 提供的 F 表達式!
例如,為了查找 comments 數目多于 read 數目的 BookInfo,可以構造一個 F()對象來引用 read 數目,并在查詢中使用該 F()對象:
>>> from django.db.models import F
>>> BookInfo.objects.filter(ncomments__gt=F('nread'))
Django 支持對 F()對象進行加、減、乘、除、取模以及冪運算等算術操作。兩個操作數可以是常數和其它 F()對象。例如查找 comment 數目比 read 兩倍還要多的
BookInfo,我們可以這么寫:
>>> Entry.objects.filter(ncomments__gt=F('nread') * 2)
主鍵的快捷查詢方式:pk
pk 就是 primary key 的縮寫。通常情況下,一個模型的主鍵為“id”,所以下面三個語句的效果一樣:
>>> BookInfo.objects.get(id__exact=14)
>>> BookInfo.objects.get(id=14)
>>> BookInfo.objects.get(pk=14)
可以聯合其他類型的參數:
>>> BookInfo.objects.filter(pk__in=[1,4,7])
>>> BookInfo.objects.filter(pk__gt=14)
4.3.8. 在 LIKE 語句中轉義百分符號和下劃線
在原生 SQL 語句中%符號有特殊的作用。Django 幫你自動轉義了百分符號和下劃線,你可以和普通字符一樣使用它們,如下所示:
>>> BookInfo.objects.filter(btitle__contains='%')
# 它和下面的一樣
# SELECT ... WHERE btitle LIKE '%\%%';
4.3.9. 緩存與查詢集
每個 QuerySet 都包含一個緩存,用于減少對數據庫的實際操作。
對于新創建的 QuerySet,它的緩存是空的。當 QuerySet 第一次被提交后,數據庫執行實際的查詢操作,Django 會把查詢的結果保存在 QuerySet 的緩存內,隨后的對于該 QuerySet 的提交將重用這個緩存的數據。
要想高效的利用查詢結果,降低數據庫負載,你必須善于利用緩存。看下面的例子,這會造成 2 次實際的數據庫操作,加倍數據庫的負載,同時由于時間差的問題,可能在兩次操作之間數據被刪除或修改或添加,導致臟數據的問題:
>>> print([b.btitle for b in BookInfo.objects.all()])
>>> print([b.bpub_date for b in BookInfo.objects.all()])
為了避免上面的問題,好的使用方式如下,這只產生一次實際的查詢操作,并且保持了數據的一致性:
>>> queryset = BookInfo.objects.all()
>>> print([b.btitle for b in queryset]) # 提交查詢
>>> print([b.bpub_date for b in queryset]) # 重用查詢緩存
何時不會被緩存
有一些操作不會緩存 QuerySet,例如切片和索引。這就導致這些操作沒有緩存可用,每次都會執行實際的數據庫查詢操作。例如:
>>> queryset = BookInfo.objects.all()
>>> print(queryset[5]) # 查詢數據庫
>>> print(queryset[5]) # 再次查詢數據庫
但是,如果已經遍歷過整個 QuerySet,那么就相當于緩存過,后續的操作則會使用緩存,例如:
>>> queryset = BookInfo.objects.all()
>>> [entry for entry in queryset] # 查詢數據庫
>>> print(queryset[5]) # 使用緩存
>>> print(queryset[5]) # 使用緩存
4.3.10 使用 Q 對象進行復雜查詢
普通 filter 函數里的條件都是“and”邏輯,如果你想實現“or”邏輯怎么辦?用 Q 查詢!
Q 來自 django.db.models.Q,用于封裝關鍵字參數的集合,可以作為關鍵字參數用于filter、exclude 和 get 等函數。 例如:
from django.db.models import Q
Q(btitle__startswith='笑')
可以使用“&”或者“|”或“~”來組合 Q 對象,分別表示與或非邏輯。它將返回一個新的 Q 對象。
Q(btitle__startswith='笑')|Q(btitle__startswith='神')
# 這相當于:
WHERE btitle LIKE '笑%' OR btitle LIKE '神%'
你也可以這么使用,默認情況下,以逗號分隔的都表示 AND 關系:
BookInfo.objects.get(Q(btitle__startswith='笑'),Q(bpub_date=date(2005, 5, 2)) | Q(bpub_date=date(2005, 5, 6)) )
當關鍵字參數和 Q 對象組合使用時,Q 對象必須放在前面,如下例子:
BookInfo.objects.get(Q(bpub_date=date(2005, 5, 2)) | Q(bpub_date=date(2005, 5,6)),btitle__startswith='a',)
如果關鍵字參數放在 Q 對象的前面,則會報錯。
4.4 比較對象
要比較兩個模型實例,只需要使用 python 提供的雙等號比較符就可以了。在后臺,其實比較的是兩個實例的主鍵的值。下面兩種方法是等同的:
>>> some_entry == other_entry
>>> some_entry.id == other_entry.id
4.5、刪除對象
刪除對象使用的是對象的 delete()方法。該方法將返回被刪除對象的總數量和一個字典,字典包含了每種被刪除對象的類型和該類型的數量。如下所示:
>>> e.delete()
(1, {'weblog.Entry': 1})
也可以批量刪除。每個 QuerySet 都有一個 delete()方法,它能刪除該 QuerySet 的所有成員。例如:
>>> BookInfo.objects.filter(bpub_date__year=2005).delete()
(5, {booktest.BookInfo': 5})
當 Django 刪除一個對象時,它默認使用 SQL 的 ON DELETE CASCADE 約束,也就是說,任何有外鍵指向要刪除對象的對象將一起被刪除。例如:
b = BookInfo.objects.get(pk=1)
# 下面的動作將刪除該條 BookInfo 和所有的它關聯的 HeroInfo 對象
b.delete()
這種級聯的行為可以通過的 ForeignKey 的 on_delete 參數自定義。
注意,delete()是唯一沒有在管理器上暴露出來的方法。這是刻意設計的一個安全機制,用來防止你意外地請求類似 Entry.objects.delete()的動作,而不慎刪除了所有的條目。如果你確實想刪除所有的對象,你必須明確地請求一個完全的查詢集,像下面這樣:
BookInfo.objects.all().delete()
4.6、批量更新對象
使用 update()方法可以批量為 QuerySet 中所有的對象進行更新操作。
BookInfo.objects.filter(bpub_date__year=1959).update(bcomments=100)
只可以對普通字段和 ForeignKey 字段使用這個方法。若要更新一個普通字段,只需提供一個新的常數值。若要更新 ForeignKey 字段,需設置新值為你想指向的新模型實例。
例如:
>>> b = BookInfo.objects.get(pk=1)
# 修改所有的 HeroInfo,讓他們都屬于 b
>>> HeroInfo.objects.all().update(book=b)
update 方法會被立刻執行,并返回操作匹配到的行的數目(有可能不等于要更新的行的數量,因為有些行可能已經有這個新值了)。唯一的約束是:只能訪問一張數據庫表。
update 方法可以配合 F 表達式。這對于批量更新同一模型中某個字段特別有用。
>>> BookInfo.objects.all().update(ncomments=F('ncomments') + 1)
4.7、關系的對象
利用本節一開始的模型,一個 HeroInfo 對象 h 可以通過 book 屬性 h.book 獲取關聯的BookInfo 對象。反過來,BookInfo 對象 b 可以通過 heroinfo_set 屬性b.heroinfo_set.all()訪問與它關聯的所有 HeroInfo 對象。
4.7.1. 一對多(外鍵)
正向查詢:
直接通過圓點加屬性,訪問外鍵對象:
>>> h = HeroInfo.objects.get(id=2)
>>> h.book # 返回關聯的 BookInfo 對象
要注意的是,對外鍵的修改,必須調用 save 方法進行保存,例如:
>>> h = HeroInfo.objects.get(id=2)
>>> h.book = some_book
>>> h.save()
在第一次對一個外鍵關系進行正向訪問的時候,關系對象會被緩存。隨后對同樣外鍵關系對象的訪問會使用這個緩存,例如:
>>> h = HeroInfo.objects.get(id=2)
>>> print(h.book) # 訪問數據庫,獲取實際數據
>>> print(h.book) # 不會訪問數據庫,直接使用緩存的版本
反向查詢:
如果一個模型有 ForeignKey,那么該 ForeignKey 所指向的外鍵模型的實例可以通過一個管理器進行反向查詢,返回源模型的所有實例。默認情況下,這個管理器的名字為FOO_set,其中 FOO 是源模型的小寫名稱。該管理器返回的查詢集可以用前面提到的方式進行過濾和操作。
>>> b = BookInfo.objects.get(id=1)
>>> b.heroinfo_set.all()
4.7.2. 多對多
多對多關系的兩端都會自動獲得訪問另一端的 API。這些 API 的工作方式與前面提到的“反向”一對多關系的用法一樣。
唯一的區別在于屬性的名稱:定義 ManyToManyField 的模型使用該字段的屬性名稱,而“反向”模型使用源模型的小寫名稱加上'_set' (和一對多關系一樣)。
4.7.3. 一對一
一對一非常類似多對一關系,可以簡單的通過模型的屬性訪問關聯的模型。
class HeroDetail(models.Model):heroinfo = models.OneToOneField(HeroInfo,on_delete=models.CASCADE)details = models.TextField()hd = HeroInfoDetail.objects.get(id=2)
hd.heroinfo
4.7.4. 通過關聯對象進行查詢
涉及關聯對象的查詢與正常值的字段查詢遵循同樣的規則。當你指定查詢需要匹配的值時,你可以使用一個對象實例或者對象的主鍵值。
例如,如果你有一個 id=5 的 BookInfo 對象 b,下面的三個查詢將是完全一樣的:
HeroInfo.objects.filter(book=b) # 使用對象實例
HeroInfo.objects.filter(book =b.id) # 使用實例的 id
HeroInfo.objects.filter(book =5) # 直接使用 id
五、 模型的繼承
很多時候,我們都不是從‘一窮二白’開始編寫模型的,有時候可以從第三方庫中繼承,有時候可以從以前的代碼中繼承,甚至現寫一個模型用于被其它模型繼承。
類同于 Python 的類繼承,Django 也有完善的繼承機制。
首先,Django 中所有的模型都必須繼承 django.db.models.Model 模型,不管是直接繼承也好,還是間接繼承也罷。
其次,模型還可以繼承自其他自定義的父模型。你唯一需要決定的是,父模型是否是一個獨立自主的,同樣在數據庫中創建數據表的模型,還是一個只用來保存子模型共有內容,并不實際創建數據表的抽象模型。
Django 有三種繼承的方式:
1.抽象基類:被用來繼承的模型被稱為 Abstract base classes,將子類共同的數據抽離出來,供子類繼承重用,它不會創建實際的數據表;
2.多表繼承:Multi-table inheritance,每一個模型都有自己的數據庫表;
3.代理模型:如果你只想修改模型的 Python 層面的行為,并不想改動模型的字段,可以使用代理模型。
同 Python 的繼承一樣,Django 也是可以同時繼承兩個以上父類的。
5.1、 抽象基類:
只需要在模型的 Meta 類里添加 abstract=True 元數據項,就可以將一個模型轉換為抽象基類。Django 不會為這種類創建實際的數據庫表,它們也沒有管理器,不能被實例化也無法直接保存,它們就是用來被繼承的。抽象基類完全就是用來保存子模型們共有的內容部分,達到重用的目的。當它們被繼承時,它們的字段會全部復制到子模型中。看下面的例子:
from django.db import models class CommonInfo(models.Model):name = models.CharField(max_length=100)age = models.PositiveIntegerField()class Meta:abstract = True class Student(CommonInfo):home_group = models.CharField(max_length=5)
Student 模型將擁有 name,age,home_group 三個字段,并且 CommonInfo 模型不
能當做一個正常的模型使用。
如果子類沒有聲明自己的 Meta 類,那么它將繼承抽象基類的 Meta 類。
這里有幾點要特別說明:
1.抽象基類中有的元數據,子模型沒有的話,直接繼承;
2.抽象基類中有的元數據,子模型也有的話,直接覆蓋;
3.子模型可以額外添加元數據;
4.抽象基類中的 abstract=True 這個元數據不會被繼承。也就是說如果想讓一個抽象基類的子模型,同樣成為一個抽象基類,那你必須顯式的在該子模型的 Meta 中同樣聲明一個 abstract = True;
5.有一些元數據對抽象基類無效,比如 db_table,首先是抽象基類本身不會創建數據表,其次它的所有子類也不會按照這個元數據來設置表名。
5.2、 多表繼承
這種繼承方式下,父類和子類都是獨立自主、功能完整、可正常使用的模型,都有自己的數據庫表,內部隱含了一個一對一的關系。例如:
from django.db import models class Place(models.Model):name = models.CharField(max_length=50)address = models.CharField(max_length=80) class Restaurant(Place):serves_hot_dogs = models.BooleanField(default=False)serves_pizza = models.BooleanField(default=False)
Restaurant 將包含 Place 的所有字段,并且各有各的數據庫表和字段,比如:
>>> Place.objects.filter(name="Bob's Cafe")
>>> Restaurant.objects.filter(name="Bob's Cafe")
如果一個 Place 對象同時也是一個 Restaurant 對象,你可以使用小寫的子類名,在父類中訪問它,例如:
>>> p = Place.objects.get(id=12)
# 如果 p 也是一個 Restaurant 對象,那么下面的調用可以獲得該 Restaurant 對象。
>>> p.restaurant
<Restaurant: ...>
但是,如果這個 Place 是個純粹的 Place 對象,并不是一個 Restaurant 對象,那么上面的調用方式會彈出 Restaurant.DoesNotExist 異常。
Meta 和多表繼承
在多表繼承的情況下,由于父類和子類都在數據庫內有物理存在的表,父類的 Meta 類會對子類造成不確定的影響,因此,Django 在這種情況下關閉了子類繼承父類的Meta 功能。這一點和抽象基類的繼承方式有所不同。但是,還有兩個 Meta 元數據特殊一點,那就是 ordering 和 get_latest_by,這兩個參數是會被繼承的。因此,如果在多表繼承中,你不想讓你的子類繼承父類的上面兩種參數,就必須在子類中顯示的指出或重寫。如下:
class ChildModel(ParentModel):# ...class Meta:# 移除父類對子類的排序影響ordering = []
5.3、 代理模型
使用多表繼承時,父類的每個子類都會創建一張新數據表,通常情況下,這是我們想要的操作,因為子類需要一個空間來存儲不包含在父類中的數據。但有時,你可能只想更改模型在 Python 層面的行為,比如添加一個新方法。
代理模型就是為此而生的。你可以創建、刪除、更新代理模型的實例,并且所有的數據都可以像使用原始模型(非代理類模型)一樣被保存。不同之處在于你可以在代理模型中改變默認的排序方式,而不會對原始模型產生影響。
聲明一個代理模型只需要將 Meta 中 proxy 的值設為 True。
例如你想給 Person 模型添加一個方法。你可以這樣做:
from django.db import models class Person(models.Model):first_name = models.CharField(max_length=30)last_name = models.CharField(max_length=30) class MyPerson(Person):class Meta:proxy = Truedef do_something(self):# ...pass
MyPerson 類將操作和 Person 類同一張數據庫表。并且任何新的 Person 實例都可以通過 MyPerson 類進行訪問,反之亦然。
>>> p = Person.objects.create(first_name="foobar")
>>> MyPerson.objects.get(first_name="foobar")
<MyPerson: foobar>
一些約束:
1.代理模型必須繼承自一個非抽象的基類,并且不能同時繼承多個非抽象基類;
2.代理模型可以同時繼承任意多個抽象基類,前提是這些抽象基類沒有定義任何模型字段。
3.代理模型可以同時繼承多個別的代理模型,前提是這些代理模型繼承同一個非抽象基類。(早期 Django 版本不支持這一條)
5.4、 多重繼承
注意,多重繼承和多表繼承是兩碼事,兩個概念。
Django 的模型體系支持多重繼承,就像 Python 一樣。如果多個父類都含有 Meta 類,則只有第一個父類的會被使用,剩下的會忽略掉。
一般情況,能不要多重繼承就不要,盡量讓繼承關系簡單和直接,避免不必要的混亂和復雜。
請注意,繼承同時含有相同 id 主鍵字段的類將拋出異常。為了解決這個問題,你可以在基類模型中顯式的使用 AutoField 字段。
警告
在 Python 語言層面,子類可以擁有和父類相同的屬性名,這樣會造成覆蓋現象。但是對于 Django,如果繼承的是一個非抽象基類,那么子類與父類之間不可以有相同的字段名!
比如下面是不行的
class A(models.Model):name = models.CharField(max_length=30) class B(A):name = models.CharField(max_length=30)
如果你執行 python manage.py makemigrations 會彈出下面的錯誤:
django.core.exceptions.FieldError: Local field 'name' in class 'B' clashes with field of?the same name from base class 'A'.
但是!如果父類是個抽象基類就沒有問題了(1.10 版新增特性),如下:
class A(models.Model):name = models.CharField(max_length=30)class Meta:abstract = True class B(A):name = models.CharField(max_length=30)
?


)
















》...)