NoCode-bench:評估LLM無代碼功能添加能力的新基準
論文:NoCode-bench: A Benchmark for Evaluating Natural Language-Driven Feature Addition
研究背景:當AI嘗試給軟件"加新功能",我們需要一張靠譜的"考卷"
想象一下,你想給常用的軟件加個小功能——比如讓聊天工具支持郵件訂閱,或者讓表格軟件導出新格式。如果不用寫代碼,只需用自然語言描述這個需求,AI就能自動完成代碼修改,那該多方便?這就是"自然語言驅動的無代碼開發"的愿景:讓普通人也能通過說話或寫字來定制軟件,不用再跟復雜的代碼打交道。
但這里有個大問題:我們怎么知道AI能不能做好這件事?現有的評估工具大多盯著"修bug"或"解決問題",比如給AI一個"軟件崩潰了"的描述,看它能不能修好。但"加新功能"和"修bug"完全不是一回事——前者需要理解現有軟件的結構,還要在不破壞原有功能的前提下新增代碼,難度大得多。而且,現有基準里只有極少數任務是關于加功能的(比如SWE-bench里僅7.3%)。
就像老師想測試學生的"作文創新能力",但手里只有"改錯題"的試卷,顯然測不出真實水平。于是,研究者們決定打造一張專門的"考卷"——這就是NoCode-bench的由來。
主要作者及單位信息
該論文由來自浙江大學、香港科技大學、斯圖加特大學的研究者合作完成,核心團隊包括Le Deng、Zhonghao Jiang、Jialun Cao、Michael Pradel和Zhongxin Liu(通訊作者),其中多數作者來自浙江大學區塊鏈與數據安全國家重點實驗室。
創新點:這張"考卷"和以前的有什么不一樣?
-
聚焦"無代碼功能添加"這一空白領域:不同于現有基準(如SWE-bench)主要關注bug修復,NoCode-bench專門針對"用自然語言描述新功能,讓AI生成代碼變更"的場景,填補了該領域評估工具的空白。
-
從"發布說明"出發,保證任務真實性:以前的基準常從"問題描述"或"代碼提交記錄"里挖任務,容易混入模糊或錯誤的案例。而NoCode-bench從軟件的"發布說明"入手——這是開發者自己寫的"更新日志",明確標注了"新增功能",相當于直接從老師手里拿了"官方題庫",任務真實性大大提高。
-
有"精簡版考卷"方便快速評估:完整版包含634個任務,對資源有限的研究者不太友好。于是團隊人工篩選出114個高質量任務(NoCode-bench Verified),就像"模擬卷",既能保證評估效果,又能節省時間。
研究方法:這張"考卷"是怎么出的?
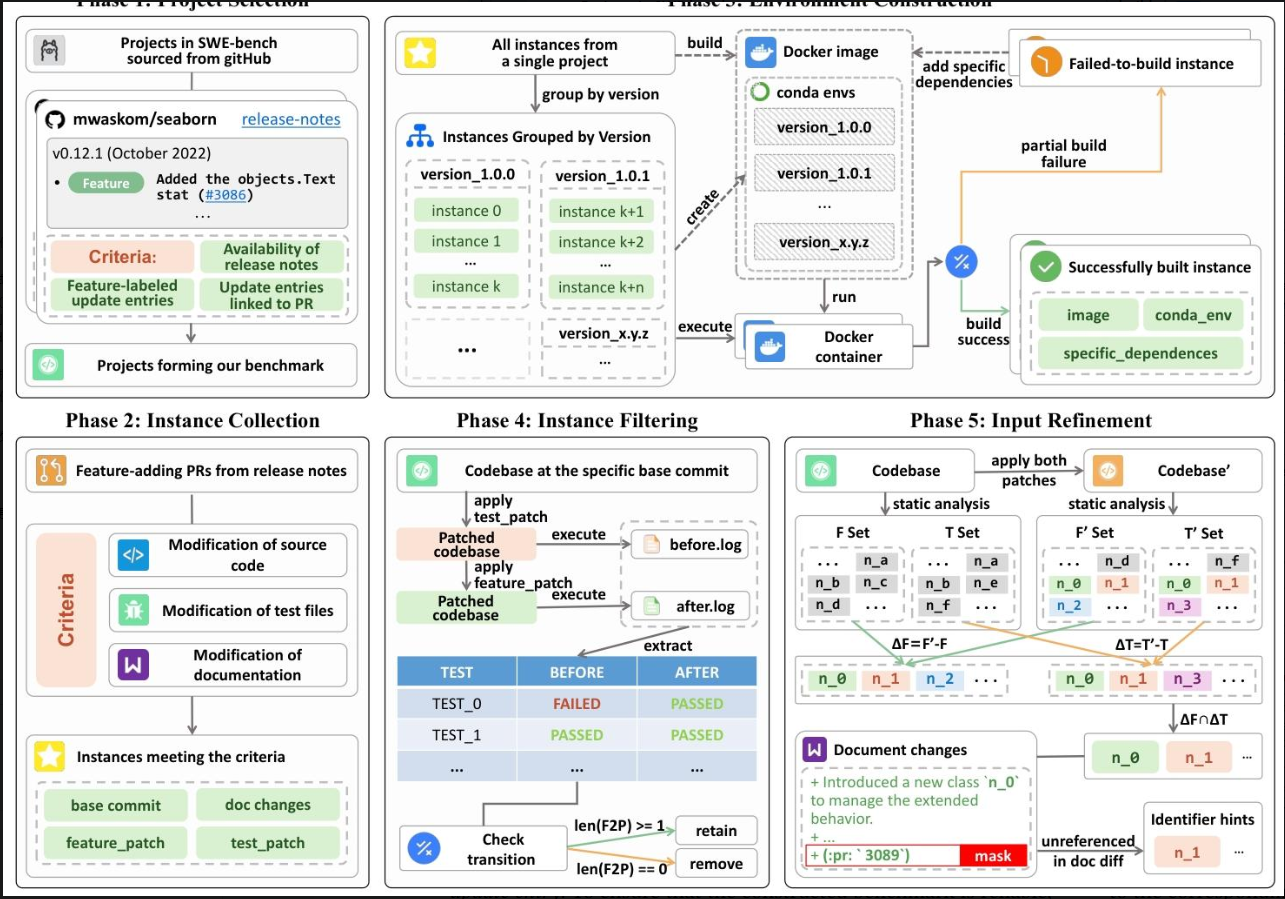
NoCode-bench的構建分5個步驟,就像出卷老師從選題到定稿的全過程:
-
選"教材"(項目選擇):從SWE-bench的12個開源項目里,挑出10個符合條件的——必須有清晰的發布說明,且明確標注了"新增功能",還能關聯到具體的代碼修改記錄(PR)。比如flask因為沒有標注"功能"就被排除了。
-
找"題目素材"(實例收集):從選定的項目里爬取所有和"新增功能"相關的代碼修改記錄(PR),并篩選出同時改了源代碼、測試文件和文檔的PR——畢竟加功能不僅要寫代碼,還要更新說明書和測試用例。
-
搭"考場環境"(環境構建):為每個項目準備可復現的運行環境,用Docker鏡像和Anaconda管理依賴,避免因為"環境不對"導致AI做對了也被判錯。
-
篩"有效題目"(實例過濾):通過測試用例驗證每個任務——新增功能后,必須有一些測試從"失敗"變成"成功"(證明功能生效了),否則就剔除。最終留下634個有效任務。
-
優化"題目描述"(輸入 refinement):有些任務的文檔里沒提新增的類或函數名,但測試用例里有,這種情況會導致AI寫對了也通不過測試。于是研究者補充了這些"隱藏信息",還刪掉了文檔里的PR編號(避免AI"作弊")。
而評估實驗則像"模擬考試":選了6個最先進的LLM(比如GPT-4o、Claude-4-Sonnet),用兩種主流框架(Agentless和OpenHands)讓它們完成任務,再通過"成功率""文件匹配率"等指標打分。
主要貢獻:這張"考卷"到底有什么用?
-
填補了領域空白:首次提出專門評估"無代碼功能添加"的基準,讓研究者有了統一的工具來比較不同AI的能力。
-
揭示了LLM的真實水平:測試發現,最好的AI(Claude-4-Sonnet)在簡單任務集里成功率僅15.79%,復雜任務集里更低。這說明現在的AI離"無代碼開發"還差得遠。
-
指出了AI的三大短板:
- 不會跨文件修改:多文件任務的成功率不到3%;
- 看不懂軟件結構:經常改壞原有功能;
- 不會用工具:調用編輯工具時格式總出錯,導致任務失敗。
這些發現就像給AI開發者遞了一張"改進清單",明確了未來需要突破的方向。
解決的主要問題及成果
- 解決了"無代碼功能添加"缺乏專門評估工具的問題,提出了NoCode-bench基準;
- 構建了包含634個任務的數據集及114個人工驗證的子集,支持多樣化評估;
- 評估了主流LLM的表現,發現其在跨文件編輯、代碼結構理解和工具調用上的短板,為后續研究提供了依據。
一段話總結:
NoCode-bench是一個用于評估大型語言模型(LLMs)在自然語言驅動的無代碼功能添加任務上表現的基準測試集,包含來自10個項目的634個任務,涉及約114k代碼變更,每個任務均配對用戶文檔變更與對應的代碼實現,并通過開發者編寫的測試用例驗證。其構建通過五階段流程(項目選擇、實例收集、環境構建、實例過濾、輸入優化)完成,以發布說明為起點確保任務真實性,并包含一個經人工驗證的子集NoCode-bench Verified(114個任務)以支持輕量評估。評估結果顯示,最先進的LLMs在NoCode-bench Verified上的最佳成功率僅為15.79%,在NoCode-bench Full上更低,主要因缺乏跨文件編輯能力、對代碼庫結構理解不足及工具調用能力欠缺導致。
思維導圖:

詳細總結:
1. 背景與目的
- 無代碼開發旨在讓用戶通過自然語言指定軟件功能,無需直接編輯代碼,LLMs在此領域有潛力,但需高質量基準測試評估其能力。
- 現有基準(如SWE-bench)多關注bug修復或問題解決,較少針對無代碼場景,且功能添加任務占比低(如SWE-bench僅7.3%),因此構建NoCode-bench以填補空白。
2. NoCode-bench構建(五階段流程)
- 項目選擇:從SWE-bench的12個項目中篩選出10個,要求有發布說明、特征標注的更新條目及關聯的GitHub PR。
- 實例收集:爬取符合條件的特征添加PR,篩選出同時修改源代碼、測試文件和文檔的PR,截止2024年8月,獲1571個候選實例。
- 環境構建:為每個項目構建基礎Docker鏡像,用Anaconda管理版本隔離,解決依賴問題確保環境可復現。
- 實例過濾:保留有F2P測試(從失敗到成功的測試用例)的實例,最終獲634個任務。
- 輸入優化:補充測試中引用但文檔未提及的實體名稱,屏蔽PR編號等避免數據泄露。
3. NoCode-bench Verified
- 構建:從候選中隨機抽樣238個任務,由5名資深開發者按任務清晰度和評估準確性標注,最終保留114個高質量任務。
- 作用:支持資源有限情況下的輕量、可靠評估,與NoCode-bench Full(634個任務)互補。
4. 實驗設置
- 研究問題(RQs):
- RQ1:與SWE-bench的特征差異
- RQ2:LLMs在Verified子集的表現
- RQ3:LLMs在Full子集的表現
- RQ4:LLMs失敗的原因
- 模型與框架:6個LLMs(3個開源:Qwen3-235B等;3個閉源:GPT-4o等),采用Agentless和OpenHands框架。
- 評估指標:成功率(Success%)、應用率(Applied%)、文件匹配率(File%)、回歸測試通過率(RT%)等。
5. 實驗結果
| 維度 | NoCode-bench vs SWE-bench |
|---|---|
| 輸入復雜度 | 文檔變更平均長度約為SWE-bench問題描述的2倍(739.06 vs 480.37 tokens) |
| 定位難度 | 平均修改文件2.65個(SWE-bench 1.66個),13.56%實例需新增/刪除文件(SWE-bench 1.70%) |
| 編輯難度 | 平均代碼變更179.12行(SWE-bench 37.71行),20%實例變更超200行 |
- RQ2(Verified子集):Claude-4-Sonnet表現最佳,成功率15.79%;Agentless框架應用率(98%)高于OpenHands(59%)。
- RQ3(Full子集):平均成功率5.68%,低于Verified子集,因任務更復雜且含噪聲。
- RQ4(失敗原因):
- 跨文件編輯能力不足:多文件任務成功率僅2.03%(Full子集)。
- 代碼庫結構理解不足:修改破壞現有功能(如DeepSeek-v3的錯誤修改)。
- 工具調用能力欠缺:Gemini-2.5-Pro因格式錯誤成功率為0。
6. 結論
NoCode-bench為無代碼功能添加任務提供了挑戰性基準,現有LLMs表現不佳,需在跨文件編輯、代碼庫理解和工具調用方面改進。
關鍵問題:
-
NoCode-bench與現有軟件工程基準(如SWE-bench)的核心區別是什么?
答:NoCode-bench聚焦無代碼功能添加場景,以文檔變更為輸入,而SWE-bench等多關注傳統問題解決,以 issue 描述為輸入;NoCode-bench任務涉及更多跨文件編輯(平均2.65個文件 vs SWE-bench 1.66個)、更長代碼變更(平均179行 vs SWE-bench 37行),且包含更高比例的文件增刪(13.56% vs 1.70%),難度更高。 -
LLMs在NoCode-bench上的評估表現如何?主要發現是什么?
答:最先進的LLMs表現較差,在Verified子集上最佳成功率為15.79%(Claude-4-Sonnet),在Full子集上平均成功率僅5.68%;Agentless框架整體表現優于OpenHands;模型在單文件任務上的成功率(如Claude-4-Sonnet達24.59%)顯著高于多文件任務(僅3.77%),表明跨文件編輯是主要瓶頸。 -
導致LLMs在NoCode-bench任務中失敗的關鍵原因有哪些?
答:主要有三點:一是缺乏跨文件編輯能力,多文件任務成功率極低;二是對代碼庫結構理解不足,修改易破壞現有功能(如DeepSeek-v3的錯誤實現);三是工具調用能力欠缺,模型難以生成符合格式的工具指令(如Gemini-2.5-Pro因格式錯誤成功率為0)。
總結:一張難住了當前AI的"考卷"
NoCode-bench是首個聚焦"自然語言驅動無代碼功能添加"的基準,包含634個真實任務(及114個精選任務),通過嚴謹的五階段流程構建而成。實驗顯示,即使是最先進的LLM,在這張"考卷"上的表現也很糟糕,主要因為跨文件編輯、軟件結構理解和工具調用能力不足。
這不僅是對當前AI的"壓力測試",更為未來的研究指明了方向——要實現"無代碼開發",AI還有很長的路要走。



















