2019獨角獸企業重金招聘Python工程師標準>>> 
一、編譯環境描述
-
OpenStack創建五個虛擬機,其中1個主節點(hostname為bigdatamaster),4個從節點(hostname分別為,bigdataslave1、bigdataslave2、bigdataslave3、bigdataslave4)
-
OS:CentOS 7.2_1511
-
JDK:Oracle JDK 1.8_191
-
Maven:3.5.2
-
Hadoop:Apache Hadoop 2.7.2
-
Hive:0.13.1
-
Scala:2.11.8
-
Spark:2.3.2
-
CarbonData:1.5.0
二、編譯過程
1.選擇源碼
在CarbonData的歸檔地址(http://archive.apache.org/dist/carbondata/1.5.0/或者https://dist.apache.org/repos/dist/release/carbondata/)下載源碼:
[root@bigdatamaster Desktop]# wget https://dist.apache.org/repos/dist/release/carbondata/1.5.0/apache-carbondata-1.5.0-source-release.zip
...
[root@bigdatamaster Desktop]# ls
apache-carbondata-1.5.0-source-release.zip
[root@bigdatamaster Desktop]# unzip apache-carbondata-1.5.0-source-release.zip
[root@bigdatamaster Desktop]# ls
apache-carbondata-1.5.0-source-release.zip carbondata-parent-1.5.0
[root@bigdatamaster carbondata-parent-1.5.0]# ls
assembly build conf datamap dev examples hadoop LICENSE NOTICE processing store tools
bin common core DEPENDENCIES docs format integration licenses-binary pom.xml README.md streaming注:如果底層的hadoop系統版本為2.7.2,scala版本為2.11.8,spark版本為2.2.1,則不需要通過源碼編譯。由于本文所處的底層系統hadoop版本為2.7.1,scala版本為,spark版本為2.3.2,因此需要下載源碼重新編譯。
2.編譯源碼
[root@bigdatamaster carbondata-parent-1.5.0]# mvn -DskipTests -Pspark-2.3 -Dspark.version=2.3.2 -Dhadoop.version=2.7.1 clean package...
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Apache CarbonData :: Parent ........................ SUCCESS [ 8.404 s]
[INFO] Apache CarbonData :: Common ........................ SUCCESS [ 15.636 s]
[INFO] Apache CarbonData :: Core .......................... SUCCESS [01:00 min]
[INFO] Apache CarbonData :: Processing .................... SUCCESS [ 27.459 s]
[INFO] Apache CarbonData :: Hadoop ........................ SUCCESS [ 13.402 s]
[INFO] Apache CarbonData :: Streaming ..................... SUCCESS [03:11 min]
[INFO] Apache CarbonData :: Store SDK ..................... SUCCESS [ 37.462 s]
[INFO] Apache CarbonData :: Spark Datasource .............. SUCCESS [01:31 min]
[INFO] Apache CarbonData :: Spark Common .................. SUCCESS [01:32 min]
[INFO] Apache CarbonData :: Search ........................ SUCCESS [ 34.174 s]
[INFO] Apache CarbonData :: Lucene Index DataMap .......... SUCCESS [01:35 min]
[INFO] Apache CarbonData :: Bloom Index DataMap ........... SUCCESS [ 13.619 s]
[INFO] Apache CarbonData :: Spark2 ........................ SUCCESS [02:35 min]
[INFO] Apache CarbonData :: Spark Common Test ............. SUCCESS [01:09 min]
[INFO] Apache CarbonData :: DataMap Examples .............. SUCCESS [ 3.621 s]
[INFO] Apache CarbonData :: Assembly ...................... SUCCESS [ 15.694 s]
[INFO] Apache CarbonData :: CLI ........................... SUCCESS [ 24.015 s]
[INFO] Apache CarbonData :: Hive .......................... SUCCESS [ 32.317 s]
[INFO] Apache CarbonData :: presto ........................ SUCCESS [01:06 min]
[INFO] Apache CarbonData :: Spark2 Examples ............... SUCCESS [ 52.898 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 18:22 min
[INFO] Finished at: 2019-04-20T21:36:16+08:00
[INFO] Final Memory: 201M/1411M
[INFO] ------------------------------------------------------------------------...查看pom.xml文件發現scala編譯的版本默認就是2.11.8,因此在此處編譯時不需要再添加“-Pscala-2.1 -Dscala.version=2.11.8”指定scala版本
編譯好后,可以在assembly目錄的target目錄下發現指定hadoop版本和spark版本編譯好的carbon文件,如下圖所示:
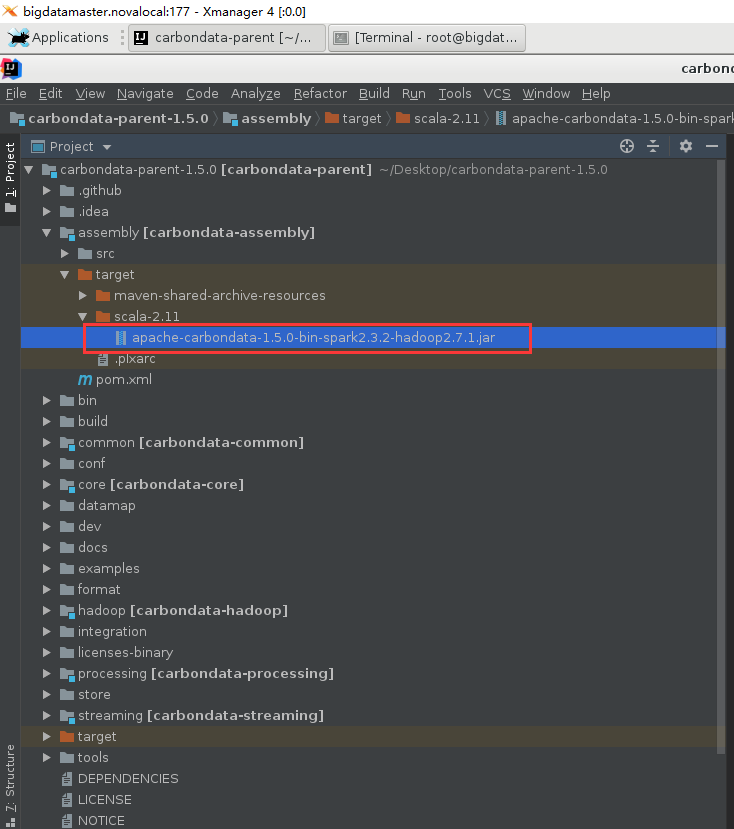
三、安裝過程
1.按照官方文檔https://carbondata.apache.org/quick-start-guide.html的步驟,在Spark集群下安裝和配置CarbonData(文檔:Installing and Configuring CarbonData on Standalone Spark Cluster這一部分)
前提條件:
-
Hadoop的HDFS和YARN均正常運行(已安裝Hadoop-2.7.1集群并正常運行)
-
Spark正常運行(已安裝Spark-2.3.2集群并正常運行)
-
CarbonData用戶必須有HDFS的訪問權限(root賬戶運行)
1)在spark安裝目錄下創建carbonlib目錄:
[root@bigdatamaster ~]# cd $SPARK_HOME
[root@bigdatamaster spark-2.3.2]# ls
bin data jars LICENSE NOTICE R RELEASE sparkdata
conf examples kubernetes licenses python README.md sbin yarn
[root@bigdatamaster spark-2.3.2]# mkdir carbonlib
[root@bigdatamaster spark-2.3.2]# ls
bin conf examples kubernetes licenses python README.md sbin yarn
carbonlib data jars LICENSE NOTICE R RELEASE sparkdata2)將步驟2中編譯好的apache-carbondata-1.5.0-bin-spark2.3.2-hadoop2.7.1.jar拷貝至carbonlib目錄下
[root@bigdatamaster spark-2.3.2]# cp ~/Desktop/carbondata-parent-1.5.0/assembly/target/scala-2.11/apache-carbondata-1.5.0-bin-spark2.3.2-hadoop2.7.1.jar ./carbonlib/
[root@bigdatamaster spark-2.3.2]# ls carbonlib/
apache-carbondata-1.5.0-bin-spark2.3.2-hadoop2.7.1.jar3)編輯spark安裝目錄下conf目錄下的spark-env.sh文件,將carbonlib添加至spark環境變量中
[root@bigdatamaster spark-2.3.2]# vim conf/spark-env.sh
(在文件末尾添加如下一行)
export SPARK_CLASSPATH=$SPARK_CLASSPATH:${SPARK_HOME}/carbonlib/*4)將carbon.properties.template文件拷貝至spark安裝目錄的conf目錄下,并命名為carbon.properties
[root@bigdatamaster carbondata-parent-1.5.0]# ls
assembly common datamap docs hadoop licenses-binary processing streaming
bin conf DEPENDENCIES examples integration NOTICE README.md target
build core dev format LICENSE pom.xml store tools
[root@bigdatamaster carbondata-parent-1.5.0]# ls conf/
carbon.properties.template dataload.properties.template[root@bigdatamaster carbondata-parent-1.5.0]# cp conf/carbon.properties.template $SPARK_HOME/conf/carbon.properties
[root@bigdatamaster carbondata-parent-1.5.0]# ls $SPARK_HOME/conf
carbon.properties metrics.properties.template spark-env.sh
docker.properties.template slaves spark-env.sh.template
fairscheduler.xml.template slaves.template
log4j.properties.template spark-defaults.conf.template5)配置carbon.properties
[root@bigdatamaster spark-2.3.2]# vim conf/carbon.properties
(添加如下幾行)
carbon.storelocation=hdfs://bigdatamaster:9000/carbon/Store
carbon.ddl.base.hdfs.url=hdfs://bigdatamaster:9000/carbon/Data
carbon.badRecords.location=hdfs://bigdatamaster:9000/carbon/BadRecords
carbon.lock.type=HDFSLOCK四個配置的含義請見官網https://carbondata.apache.org/configuration-parameters.html
6)配置spark安裝目錄下conf目錄下的spark-default.conf文件
[root@bigdatamaster spark-2.3.2]# cd conf/
[root@bigdatamaster conf]# ls
carbon.properties metrics.properties.template spark-env.sh
docker.properties.template slaves spark-env.sh.template
fairscheduler.xml.template slaves.template
log4j.properties.template spark-defaults.conf.template
[root@bigdatamaster conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@bigdatamaster conf]# ls
carbon.properties metrics.properties.template spark-defaults.conf.template
docker.properties.template slaves spark-env.sh
fairscheduler.xml.template slaves.template spark-env.sh.template
log4j.properties.template spark-defaults.conf[root@bigdatamaster conf]# vim spark-defaults.conf
(添加如下2行)
spark.executor.extraJavaOptions -Dcarbon.properties.filepath=/root/data/spark-2.3.2/conf/carbon.properties
spark.driver.extraJavaOptions -Dcarbon.properties.filepath=/root/data/spark-2.3.2/conf/carbon.properties7)將hive-site.xml添加至spark安裝目錄的conf目錄下
[root@bigdatamaster spark-2.3.2]# cp ~/data/hive-0.13.1/conf/hive-site.xml conf/注:此步驟不做,則在下面測試創建表時會報如下錯誤
scala> carbon.sql("CREATE TABLE IF NOT EXISTS test_table(id string, name string, city string, age Int) STORED BY 'carbondata'")
2019-04-21 14:10:47 WARN ObjectStore:6666 - Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
2019-04-21 14:10:47 WARN ObjectStore:568 - Failed to get database default, returning NoSuchObjectException
2019-04-21 14:10:50 WARN ObjectStore:568 - Failed to get database global_temp, returning NoSuchObjectException
2019-04-21 14:10:52 AUDIT CarbonCreateTableCommand:207 - [bigdatamaster][root][Thread-1]Creating Table with Database name [default] and Table name [test_table]
2019-04-21 14:10:53 WARN HiveExternalCatalog:66 - Couldn't find corresponding Hive SerDe for data source provider org.apache.spark.sql.CarbonSource. Persisting data source table `default`.`test_table` into Hive metastore in Spark SQL specific format, which is NOT compatible with Hive.
2019-04-21 14:10:54 AUDIT CarbonCreateTableCommand:207 - [bigdatamaster][root][Thread-1]Table created with Database name [default] and Table name [test_table]
res0: org.apache.spark.sql.DataFrame = []8)在Spark其他節點上重復步驟1)~步驟6)
此處我直接通過scp命令傳輸。步驟1)~步驟6)涉及spark安裝目錄下的以下目錄和文件:
-
carbonlib($SPARK_HOME/carbonlib)
-
spark-env.sh($SPARK_HOME/conf/spark-env.sh)
-
spark-defaults.conf($SPARK_HOME/conf/spark-defaults.conf)
-
carbon.properties($SPARK_HOME/conf/carbon.properties)
直接將一個目錄和三個配置文件通過scp遠程傳輸至spark集群其他節點相應位置即可:
[root@bigdatamaster spark-2.3.2]# scp -r carbonlib root@bigdataslave1:~/data/spark-2.3.2/
[root@bigdatamaster spark-2.3.2]# scp -r carbonlib root@bigdataslave2:~/data/spark-2.3.2/
[root@bigdatamaster spark-2.3.2]# scp -r carbonlib root@bigdataslave3:~/data/spark-2.3.2/
[root@bigdatamaster spark-2.3.2]# scp -r carbonlib root@bigdataslave4:~/data/spark-2.3.2/[root@bigdatamaster spark-2.3.2]# scp conf/spark-env.sh root@bigdataslave1:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/spark-env.sh root@bigdataslave2:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/spark-env.sh root@bigdataslave3:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/spark-env.sh root@bigdataslave4:~/data/spark-2.3.2/conf/[root@bigdatamaster spark-2.3.2]# scp conf/spark-defaults.conf root@bigdataslave1:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/spark-defaults.conf root@bigdataslave2:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/spark-defaults.conf root@bigdataslave3:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/spark-defaults.conf root@bigdataslave4:~/data/spark-2.3.2/conf/[root@bigdatamaster spark-2.3.2]# scp conf/carbon.properties root@bigdataslave1:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/carbon.properties root@bigdataslave2:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/carbon.properties root@bigdataslave3:~/data/spark-2.3.2/conf/
[root@bigdatamaster spark-2.3.2]# scp conf/carbon.properties root@bigdataslave4:~/data/spark-2.3.2/conf/?
四、測試
1)創建測試數據,并上傳至HDFS(注:下面測試數據集測試步驟選自文獻9,在此感謝作者)
[root@bigdatamaster Desktop]# vim carbonTestData.csv
(添加如下4行)
id,name,city,age
1,david,shenzhen,31
2,eason,shenzhen,27
3,jarry,wuhan,35[root@bigdatamaster Desktop]# hadoop dfs -put carbonTestData.csv /
[root@bigdatamaster Desktop]# hadoop dfs -ls /
Found 6 items
-rw-r--r-- 2 root supergroup 78 2019-04-21 14:06 /carbonTestData.csv
drwxr-xr-x - root supergroup 0 2019-04-04 14:55 /hadoopdata
drwxr-xr-x - root supergroup 0 2019-03-06 16:16 /hbase
drwxr-xr-x - root supergroup 0 2019-03-06 16:04 /root
drwxrwxr-x - root supergroup 0 2019-03-06 17:01 /tmp
drwxr-xr-x - root supergroup 0 2019-03-06 16:27 /user2)在bigdatamaster的terminal輸入以下目錄啟動spark?shell
spark-shell \
--master spark://bigdatamaster:7077 \
--jars /root/data/spark-2.3.2/carbonlib/apache-carbondata-1.5.0-bin-spark2.3.2-hadoop2.7.1.jar \
--total-executor-cores 2 \
--executor-memory 2G?
[root@bigdatamaster ~]# spark-shell \
> --master spark://bigdatamaster:7077 \
> --jars /root/data/spark-2.3.2/carbonlib/apache-carbondata-1.5.0-bin-spark2.3.2-hadoop2.7.1.jar \
> --total-executor-cores 2 \
> --executor-memory 2G
2019-04-21 14:08:56 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://bigdatamaster:4040
Spark context available as 'sc' (master = spark://bigdatamaster:7077, app id = app-20190421140908-0002).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.3.2/_/Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSessionscala> import org.apache.spark.sql.CarbonSession._
import org.apache.spark.sql.CarbonSession._scala> val carbon = SparkSession.builder().config(sc.getConf).getOrCreateCarbonSession("hdfs://bigdatamaster:9000/carbon/Store")2019-04-21 14:10:07 WARN SparkContext:66 - Using an existing SparkContext; some configuration may not take effect.
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The enable unsafe sort value "null" is invalid. Using the default value "true
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The enable off heap sort value "null" is invalid. Using the default value "true
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The custom block distribution value "null" is invalid. Using the default value "false
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The enable vector reader value "null" is invalid. Using the default value "true
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The carbon task distribution value "null" is invalid. Using the default value "block
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The enable auto handoff value "null" is invalid. Using the default value "true
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The specified value for property carbon.sort.storage.inmemory.size.inmbis invalid.
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The specified value for property 512is invalid.
2019-04-21 14:10:07 WARN CarbonProperties:168 - main The specified value for property carbon.sort.storage.inmemory.size.inmbis invalid. Taking the default value.512
carbon: org.apache.spark.sql.SparkSession = org.apache.spark.sql.CarbonSession@53e166ad(構建表模式)
scala> carbon.sql("CREATE TABLE IF NOT EXISTS test_table(id string, name string, city string, age Int) STORED BY 'carbondata'")2019-04-21 14:12:34 AUDIT CarbonCreateTableCommand:207 - [bigdatamaster][root][Thread-1]Creating Table with Database name [default] and Table name [test_table]
res1: org.apache.spark.sql.DataFrame = [](上傳數據)
scala> carbon.sql("LOAD DATA INPATH 'hdfs://bigdatamaster:9000/carbonTestData.csv' INTO TABLE test_table")2019-04-21 14:21:12 WARN DeleteLoadFolders:168 - main Files are not found in segment hdfs://bigdatamaster:9000/carbon/Store/default/test_table/Fact/Part0/Segment_0 it seems, files are already being deleted
2019-04-21 14:21:12 AUDIT CarbonDataRDDFactory$:207 - [bigdatamaster][root][Thread-1]Data load request has been received for table default.test_table
2019-04-21 14:21:18 AUDIT CarbonDataRDDFactory$:207 - [bigdatamaster][root][Thread-1]Data load is successful for default.test_table
2019-04-21 14:21:18 AUDIT MergeIndexEventListener:207 - [bigdatamaster][root][Thread-1]Load post status event-listener called for merge index
res4: org.apache.spark.sql.DataFrame = [](查看表數據)
scala> carbon.sql("SELECT * FROM test_table").show()
+---+-----+--------+---+
| id| name| city|age|
+---+-----+--------+---+
| 1|david|shenzhen| 31|
| 2|eason|shenzhen| 27|
| 3|jarry| wuhan| 35|
+---+-----+--------+---+scala> carbon.sql("SELECT city, avg(age), sum(age) FROM test_table GROUP BY city").show()
+--------+--------+--------+
| city|avg(age)|sum(age)|
+--------+--------+--------+
| wuhan| 35.0| 35|
|shenzhen| 29.0| 58|
+--------+--------+--------+?
五、參考文獻
-
CarbonData使用示例(Java):https://blog.csdn.net/u013181284/article/details/77574094
-
CarbonData編譯、安裝和集成Spark 2.2:https://blog.csdn.net/wuzhilon88/article/details/78864735
-
Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入門:https://blog.csdn.net/coridc/article/details/61915801
-
Apache CarbonData :一種為更加快速數據分析而生的新Hadoop文件版式:https://blog.csdn.net/u011239443/article/details/52015680
-
【思維導圖】Parquet Orc CarbonData 三種列式存儲格式對比:https://blog.csdn.net/lxhandlbb/article/details/80754252
-
carbondata 安裝文檔:https://blog.csdn.net/u013181284/article/details/73331170
-
Apache CarbonData學習資料匯總:https://blog.csdn.net/xubo245/article/details/84336960
-
Apache CarbonData中文文檔:https://www.iteblog.com/archives/tag/carbondata/
-
Apache CarbonData 1.0.0 編譯部署 on Mac OS:https://ask.hellobi.com/blog/marsj/6164
?
六、附錄
貼幾張mvn編譯源碼過程中的圖片,真養眼。。
?



)













索引的本質)
![bzoj4245: [ONTAK2015]OR-XOR](http://pic.xiahunao.cn/bzoj4245: [ONTAK2015]OR-XOR)
