二分查找法:在我的理解中這個查找方法為什么會叫二分呢,我認為是將要查詢的一個列表分成了兩份,然后在利用某個值來進行比較,在一個不斷循環的過程中來找出我們要找的某一個值。
廢話不多說,先上代碼:
1 def twofenfind(lst, target): 2 left = 0 3 right = len(lst) - 1 4 5 while target in lst: 6 mid = (left + right) // 2 7 if target > lst[mid]: 8 left = mid + 1 9 10 elif target < lst[mid]: 11 right = mid - 1 12 13 else: 14 return mid 15 return None 16 17 18 19 print(twofenfind([1, 2, 3 ,4, 7], 3))
# 代碼有些地方可能會有歧義,但這也僅僅只是我個人的一些理解(如有錯誤還請指正)。
二分查找發是一個效率很高的查找法,但是被查找的數據必須是有序的。
首先,將待查找target值與有序列表lst[0]到lst[n - 1]的中間位置——記為mid上的結點的關鍵字進行比較,如果相等就完成查找;否則,若lst[mid]>target,則說明待查找的數只可能在列表左邊
lst[0]-lst[mid - 1]中,只需要在左邊的列表中進行查找;若lst[mid] > x,則在右邊的列表lst[mid + 1] 到 lst[n - 1]中繼續進行查找,這樣經過一次,關鍵字的比較就縮小了一半的查找區間。
然后繼續按照上面的方法進行查找,然后知道找到關鍵字為target的元素或者當前查找區間為空(即表明查找失敗)為止。
?
下面測試一下,以查找target:13為例:?
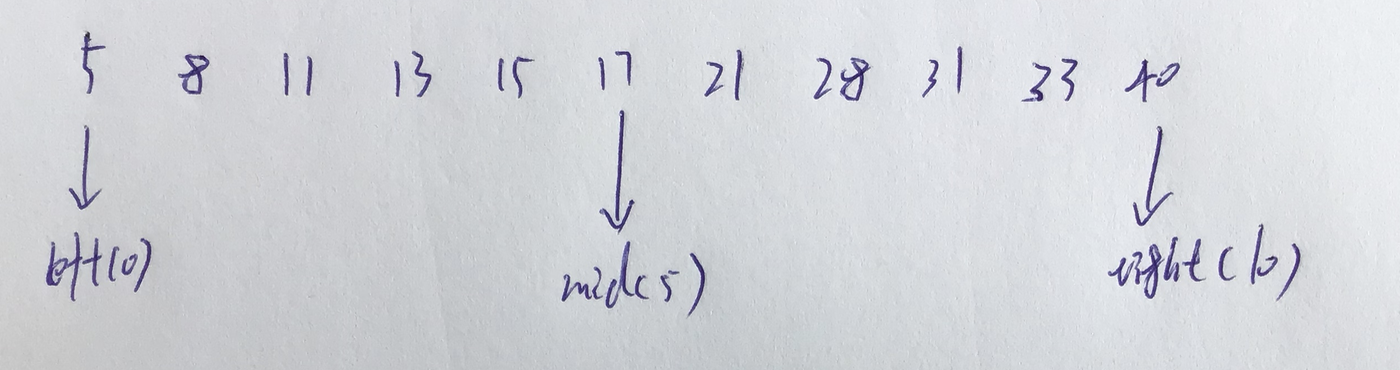
當中取mid的關鍵字和target進行比較,很顯然13 < 17,所以要查找的13應該是在前半部分的,所以下次查找的區間應該是在[0,5],即left的值不變仍然為0,right的值變為mid - 1 = 5,所以
mid = len(right + left) // 2 = 2(這里要進行整除)
?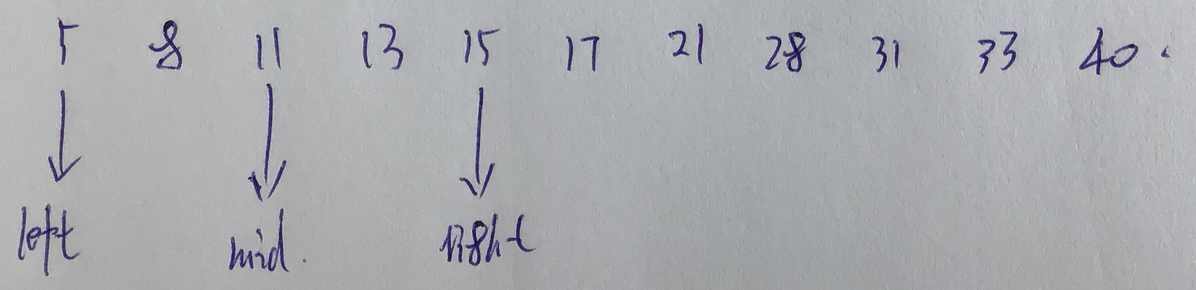
取11和13進行比較,顯然13 > 11, 所以要查找的值應該是在11后面的,所以left就變為了mid + 1 ,right的值仍然不變,取得最終的值mid = 3
取mid指示的位置的關鍵字13和target進行比較,結果相等,就說明查找成功了,所以target在列表中的位置即為mid所指示的位置。(我是按照索引來查找的)
?












索引的本質)
![bzoj4245: [ONTAK2015]OR-XOR](http://pic.xiahunao.cn/bzoj4245: [ONTAK2015]OR-XOR)





