2019獨角獸企業重金招聘Python工程師標準>>> 
問題:SQL查詢慢怎么辦?
優化手段,加索引。
索引是幫助MYSQL高效的獲取數據的排好序的數據結構。
問題:索引結構為什么使用Btree而不使用二叉樹,紅黑樹或者HASH結構?
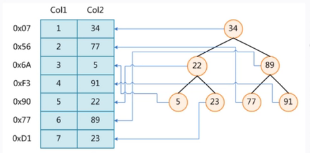
 二叉樹的特性,右邊子節點的值大于父節點,且左邊子節點的值小于父節點
二叉樹的特性,右邊子節點的值大于父節點,且左邊子節點的值小于父節點
二叉樹:使用二叉樹來做索引的數據結構,當索引值遞增的時候,二叉樹也會不斷地增加右子節點 ,那么在查找索引的時候,所做的IO操作,等同于沒有索引逐行查找數據的IO操作。
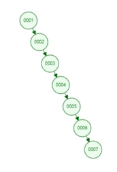
紅黑樹:平衡二叉樹。隨著數據量增大,樹的高度也會變高。2的N次方=數量量(假設100萬),那么N至少也是50,那么樹的高度也是50,如果數據在子葉節點上,那么至少要經過50次的IO操作,才能找到數據。
HASH:散列表結構,key不適合排序,而且數據是散列的分布的,不利于IO讀寫。
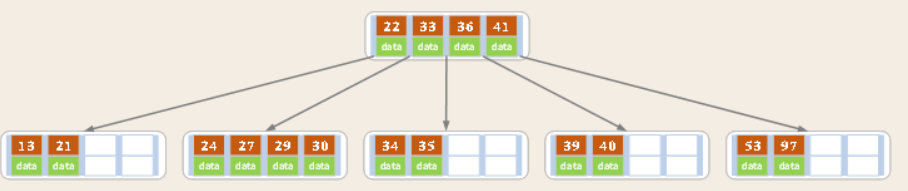
BTree:一個節點上,橫向擴展。即一個節點上,可以存儲多個元素(Degree),且每個元素,都可以有子節點,叫做多叉樹。
- 度(Degree)-節點的數據存儲個數
- 葉節點具有相同深度
- 葉節點的指針為空
- 節點中的數據KEY從左至右遞增排列
????以5階B樹舉例
B+Tree(Btree變種)
- 非葉子節點不存儲data,只存儲key,可以增大度(Degree)-節點的數據存儲個數
- 葉子節點不存儲指針
- 葉子節點增加了順序訪問指針,提高區間訪問的性能
以5階B+樹舉例
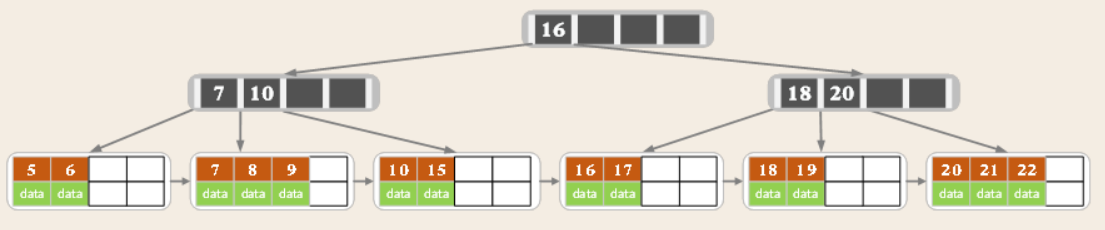
問題:Btree和B+Tree的區別?
- Btree每個節點,都包含了key和data,而B+tree只有葉子節點保存了key和data,其他節點,只保存了key,方便增大度的個數
- B+tree的葉子節點之間, 增加了指針,提高了查詢區間的性能,不需要像Btree一樣每次都從根節點開始查找
- Btree中,父節點和葉子節點,關鍵字的字段值不會冗余,而B+tree會冗余的存儲關鍵的索引值,即父節點和葉子結點都存在相同的關鍵值
MyISAM索引實現(非聚集)
MyISAM索引文件和數據文件是分離的。它是針對建表的,而不是針對數據庫的,既同一個數據庫可以多種類型的表,myISAM和innoDB。
在mysql的文件件中,會發現一個表有三個文件:
- test_table_myisam.frm?// 存儲表的結構,表的定義
- test_table_myisam.MYD // 存儲表的數據
- test_table_myisam.MYI?// 存儲表的索引文件
myisam存儲引擎是非聚集索引,所以在MYI的文件中,以B+tree的數據結構存儲了表的索引信息,而索引內容中的data,是指向數據的在MYD文件中的地址。
在myisam存儲引擎中,主鍵索引使用了B+tree,而輔助索引,非主鍵索引,也同樣根據字段的值,使用了B+tree結構來存儲。
innoDB索引實現(聚集)
- 表數據文件本身就是按B+Tree組織的一個索引結構文件
? ? 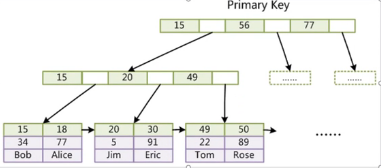
- 聚集索引 定義:葉節點包含了完整的數據記錄
- 為什么innoDB表必須有主鍵,并且推薦使用整形的自增主鍵?
- 為什么非主鍵索引結構葉子節點存儲的是主鍵值?(一致性和節省存儲空間)
在mysql的文件件中,會發現一個表有兩個文件:
- test_table_myisam.frm? // 存儲表的結構,表的定義
- test_table_myisam.ibd? // 存儲表的索引+數據
在innoDB存儲引擎中,輔助索引、非主鍵索引都不是聚集索引。
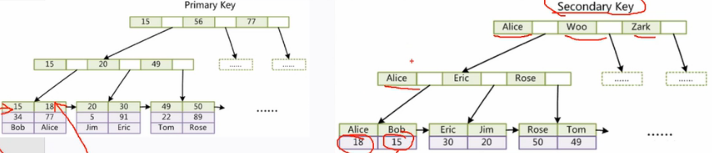
問題:為什么B+tree比Btree快?
樹的高度h,影響了查找效率,因為從根節點開始,每次查找下一個節點,都可能需要一次IO讀寫。所以增加非葉子節點的度,可以有效提高查詢效率。而CPU從磁盤上讀取數據到內存中,最小單元是頁,一頁讀取的最小數據是4KB,而CPU一次IO,讀取的數據是一頁的整數倍,且最大值也有限制。而mysql在底層,設置的大小是16KB。所以B+TREE要把數據放在葉子節點,所以非葉子幾點,就可以增加更多的節點數。而Btree節點和數據是保存在一起的,所以非葉節點的節點數,要比B+tree少,樹的高度就比B+tree高。
問題:為什么MYSQL頁文件默認的配置是16KB?
我們假設一行的數據是1K,那我們一頁的數據,就能存儲16行數據,也就是一個葉節點可以存儲16條記錄;再來看非葉節點,假設ID是bigint類型,那么長度為8B,指針大小在InnoDB源碼中為64(6B),一共就是14B,那么一頁里面就可以存儲16K/14=1170個(主鍵+指針)
那么一顆高度為2的B+樹能存儲的數據為:1170*16=18720條,一顆高度為3的B+樹可以存儲1170*1170*16=21902400(千萬條)
原因就是16KB就足夠應對千萬條表記錄了。
問題:為什么innoDB表必須有主鍵,并且推薦使用整形的自增主鍵?
? ? ? ? ?使用innoBD存儲引擎時,要建立主鍵索引,如果我們沒有主動創建索引,那么innoDB會自動幫我們建立主鍵索引。innoDB會在我們創建的表里找一列唯一的,可以代表主鍵的字段來創建主鍵索引,如果沒有這樣的字段,innoDB會默認加一列字段,來創建主鍵索引。有點類似oracle中的rowId。為什么要推薦整形而且自增的字段當做主鍵?為什么建議使用整形類型,因為如果使用uuid作為主鍵索引,uuid類型比整數類型大,為了方便IO操作一次讀取4個頁的數據(mysql默認16KB,一頁是4KB),意味索引的非葉子節點上的關鍵字要比使用整數類型的關鍵字數量小,那么B+tree的高度就可能增加,那么讀取葉子節點上的數據的IO操作次數就增加了。那么查找的效率就低了。為什么要自增,因為當新紀錄插入時,主鍵自增的話,在B+tree中插入節點比較方便,而使用uuid為主鍵,新紀錄的uuid不一定比前面的uuid大,可能會將新紀錄插在靠前面的葉子節點中,葉子節點滿了,會取中間的關鍵字向上存放到父節點中,可能會造成樹的分裂,微觀上性能就比自增的差。
![bzoj4245: [ONTAK2015]OR-XOR](http://pic.xiahunao.cn/bzoj4245: [ONTAK2015]OR-XOR)










)



![[Usaco2010 Mar]gather 奶牛大集會](http://pic.xiahunao.cn/[Usaco2010 Mar]gather 奶牛大集會)



