超參數優化在大多數機器學習流水線中已成為必不可少的一步,而貝葉斯優化則是最為廣為人知的一種“學習”超參數優化方法。
超參數優化的任務旨在幫助選擇學習算法中成本(或目標)函數的一組最佳參數。這些參數可以是數據驅動的(例如,各種訓練數據組合)或模型驅動的(例如神經網絡中的層數、學習率、優化器、批處理大小等)。在具有深度架構的最先進復雜機器學習模型中,由于參數的組合數以及這些參數之間的相互作用,超參數優化并不是一個簡單的計算任務。
在本文中,我們將討論貝葉斯優化作為一種具有記憶并從每次參數調整中學習的超參數優化方法。然后,我們將從頭開始構建一個貝葉斯優化器,而不使用任何特定的庫。
1. 為什么使用貝葉斯優化
傳統的超參數優化方法,如網格搜索(grid search)和隨機搜索(random search),需要多次計算給定模型的成本函數,以找到超參數的最優組合。由于許多現代機器學習架構包含大量超參數(例如深度神經網絡),計算成本函數變得計算昂貴,降低了傳統方法(如網格搜索)的吸引力。在這種情況下,貝葉斯優化已成為常見的超參數優化方法之一,因為它能夠在迭代次數明顯較少的情況下找到優化的解決方案,相較于傳統方法如網格搜索和隨機搜索,這得益于從每次迭代中學習。
2. 貝葉斯優化的工作原理
貝葉斯優化在概念上可能看起來復雜,但一旦實現,它會變得更簡單。在這一部分中,我將提供貝葉斯優化工作原理的概念性概述,然后我們將實施它以更好地理解。
貝葉斯優化利用貝葉斯技術對目標函數設置先驗,然后添加一些新信息以得到后驗函數。
先驗表示在新信息可用之前我們所知道的內容,后驗表示在給定新信息后我們對目標函數的了解。
更具體地說,收集搜索空間的樣本(在這個上下文中是一組超參數),然后為給定樣本計算目標函數(即訓練和評估模型)。由于目標函數不容易獲得,使用“替代函數”作為目標函數的貝葉斯近似。
然后,使用前一個樣本的信息更新替代函數,從先驗到后驗。
后驗表示在那個時間點上我們對目標函數的最佳了解,并用于指導“獲取函數”。獲取函數(例如期望改進)優化搜索空間內位置的條件概率,以獲取更有可能優化原始成本函數的新樣本。
繼續使用期望改進的例子,獲取函數計算超參數網格中每個點的期望改進,并返回具有最大值的點。然后,新收集的樣本將通過成本函數運行,后驗將被更新,這個過程重復,直到達到目標函數的可接受的優化點、產生足夠好的結果,或者資源耗盡。
3. 實現
本節將專注于貝葉斯優化的逐步實現,共有七個步驟。首先,我將列出這些步驟,然后提供詳細的解釋,以及實現代碼塊。
-
導入庫
-
定義目標(或成本)函數
-
定義參數邊界
-
定義獲取函數
-
初始化樣本和替代函數
-
運行貝葉斯優化循環
-
返回結果
技術交流&材料獲取
技術要學會分享、交流,不建議閉門造車。一個人可以走的很快、一堆人可以走的更遠。
資料干貨、資料分享、數據、技術交流提升,均可加交流群獲取,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友。
方式①、添加微信號:dkl88194,備注:來自CSDN + 資料
方式②、微信搜索公眾號:Python學習與數據挖掘,后臺回復: 資料
1、數據分析實戰寶典

2、100個超強算法模型
我們打造了《100個超強算法模型》,特點:從0到1輕松學習,原理、代碼、案例應有盡有,所有的算法模型都是按照這樣的節奏進行表述,所以是一套完完整整的案例庫。
很多初學者是有這么一個痛點,就是案例,案例的完整性直接影響同學的興致。因此,我整理了 100個最常見的算法模型,在你的學習路上助推一把!

讓我們深入研究!
Step 1 — 導入庫
我們首先導入一些必要的庫,如下所示:
-
numpy用于數值計算,是數據科學中常見的庫之一 -
scipy.stats是一個用于統計函數的庫 -
load_iris是scikit-learn中加載鳶尾花數據集的函數 -
GaussianProcessRegressor是scikit-learn中實現高斯過程回歸模型的類 -
Matern是scikit-learn中實現Matern核函數的類,用于高斯過程
import numpy as np
import scipy.stats as sps
from sklearn.datasets import load_iris
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import Matern
導入了這些庫之后,讓我們繼續定義目標函數。
Step 2: 定義目標函數
目標函數接受一組超參數 C 和 gamma 作為輸入,并返回在鳶尾花數據集上使用 RBF 核的支持向量分類器的負準確性。其中,C 是正則化參數,gamma 是 RBF、poly 和 sigmoid 核的核系數。核系數的詳細信息對我們的流程并不關鍵,可以在這里找到。然后,我們使用 load_iris 加載鳶尾花數據集,并將數據分為訓練集和測試集。數據準備好后,訓練支持向量分類器,并返回在測試集上的負準確性。
def objective(params):C, gamma = paramsX, y = load_iris(return_X_y=True)np.random.seed(0)indices = np.random.permutation(len(X))X_train = X[indices[:100]]y_train = y[indices[:100]]X_test = X[indices[100:]]y_test = y[indices[100:]]from sklearn.svm import SVCclf = SVC(C=C, gamma=gamma)clf.fit(X_train, y_train)return -clf.score(X_test, y_test)
Step 3: 定義參數邊界
在這一步,我們定義超參數搜索空間的邊界。我們創建一個形狀為 (2, 2) 的 NumPy 數組 bounds,其中每行對應一個超參數,每列對應該超參數的下界和上界。在我們的例子中,第一個超參數是 C,第二個是 gamma,兩者都用于訓練支持向量分類器。
設置邊界的目的是限制超參數搜索空間,避免測試不太可能是最優的值,并將優化焦點放在超參數空間的最有希望的區域。我們對這個練習隨機定義了邊界,但在超參數范圍已知的任務中,這變得很重要。
bounds = np.array([[1e-3, 1e3], [1e-5, 1e-1]])
Step 4: 定義獲取函數
這一步定義了我們之前討論過的獲取函數,并確定在搜索空間中要評估的下一個點。在這個具體的例子中,獲取函數是期望改進(Expected Improvement, EI)函數。它測量目標函數在當前最佳觀測值的基礎上的期望改進,考慮到當前替代模型(高斯過程)。獲取函數的定義如下:
-
高斯過程使用
gp.predict()在點x處預測均值和標準差。 -
函數找到迄今為止觀察到的最佳目標函數值(
f_best)。 -
計算對
f_best的改進為improvement = f_best — mu。 -
如果
sigma為正,則計算標準得分Z = improvement/sigma;如果sigma為0,則將Z設置為0。 -
使用標準正態分布的累積分布函數(
sps.norm.cdf)和概率密度函數(sps.norm.pdf)計算在點x處的期望改進(ei)。 -
返回期望改進。
def acquisition(x):mu, sigma = gp.predict(x.reshape(1, -1), return_std=True)f_best = np.min(y_samples)improvement = f_best - muwith np.errstate(divide='warn'):Z = improvement / sigma if sigma > 0 else 0ei = improvement * sps.norm.cdf(Z) + sigma * sps.norm.pdf(Z)ei[sigma == 0.0] == 0.0return ei
Step 5: 初始化樣本和替代函數
在開始貝葉斯優化循環之前,我們需要使用一些初始樣本初始化高斯過程替代模型。如前所述,替代函數用于有效地逼近未知的目標函數以進行優化。高斯過程是一個概率模型,定義了對函數的先驗。隨著獲取新數據,它允許使用貝葉斯推理來更新模型。具體而言,x_samples 是從由 bounds 數組定義的搜索空間中隨機抽樣的初始點。y_samples 是這些初始點對應的目標函數評估。這些樣本用于訓練高斯過程,并改進其替代建模。
Step 6: 運行貝葉斯優化循環
我們終于來到了貝葉斯優化循環。在這一步中,貝葉斯優化循環將運行指定次數(n_iter)。在每次迭代中,使用現有樣本(即 x_samples 和 y_samples)更新高斯過程模型,使用 gp.fit() 方法。然后,通過在參數空間生成的大量隨機點(即 x_random_points)優化獲取函數,選擇下一個由目標函數評估的樣本。在這些點上評估獲取函數,并選擇獲取函數值最大的點作為下一個樣本(即 x_next)。在此點記錄獲取函數值作為 best_acq_value。最后,在選擇的點上評估目標函數,并通過更新 x_samples 和 y_samples 將結果值添加到現有樣本中。這個過程重復進行指定次數的迭代(即 n_iter),并打印每次迭代的結果。
# 運行 n_iter 次的貝葉斯優化循環
n_iter = 10
for i in range(n_iter):# 使用現有樣本更新高斯過程gp.fit(x_samples, y_samples)# 通過優化獲取函數找到下一個樣本x_next = Nonebest_acq_value = -np.inf# 從參數空間中抽樣大量隨機點n_random_points = 10000x_random_points = np.random.uniform(bounds[:, 0], bounds[:, 1], size=(n_random_points, bounds.shape[0]))# 在每個點上評估獲取函數并找到最大值acq_values = np.array([acquisition(x) for x in x_random_points])max_acq_index = np.argmax(acq_values)max_acq_value = acq_values[max_acq_index]if max_acq_value > best_acq_value:best_acq_value = max_acq_valuex_next = x_random_points[max_acq_index]print(f"Iteration {i+1}: next sample is {x_next}, acquisition value is {best_acq_value}")# 在下一個樣本上評估目標函數并將其添加到現有樣本中y_next = objective(x_next)x_samples = np.vstack((x_samples, x_next))y_samples = np.append(y_samples, y_next)
Step 7: 打印結果
最后,我們打印在貝葉斯優化循環中找到的最佳參數和最佳準確性。最佳參數是與目標函數最小值相對應的參數,這就是為什么使用 np.argmin 來找到 y_samples 最小值的索引。
# Print final results
best_index = np.argmin(y_samples)
best_x = x_samples[best_index]
best_y = y_samples[best_index] print(f"Best parameters: C={best_x[0]}, gamma={best_x[1]}")
print(f"Best accuracy: {best_y}")
以下是運行此過程的最終結果:
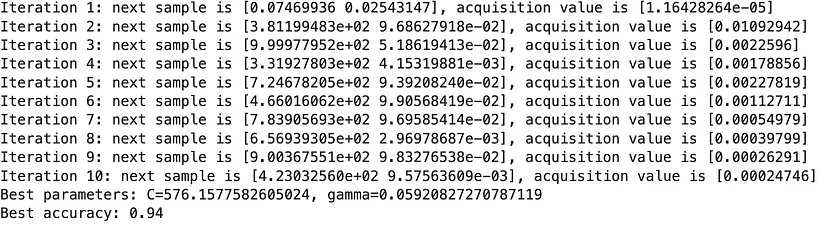
4. 結論
在本文中,我們介紹了機器學習流水線中的超參數優化,并深入探討了超參數優化的世界,詳細討論了貝葉斯優化以及為什么它可能是一種相對于基本優化器(如網格搜索和隨機搜索)更有效的微調策略。然后,我們逐步從頭開始構建了一個用于分類的貝葉斯優化器,以更好地理解這個過程。


:Tair安裝部署)


X的區別是?)

)







)


二十一 人臉識別)
