1.數據預處理
所謂數據預處理,就是指在正式做題之前對數據進行的一些處理。在有些情 況下,出題方提供的數據或者網上查找的數據并不能直接使用,比如缺少數據甚 至是異常數據,如果直接忽略缺失值,或者沒發現異常數據,都會嚴重地影響結 果的正確性。此外,帶單位的數據也需要通過無量綱處理以減少單位對計算的影響。因此正確的數據預處理是前期值得關注的任務。
2.缺失數據
(1)均值填充法
如果缺失值是數值型的,就根據該屬性在其他所有對象取值的平均值來填充該缺失的屬性值,比如年齡、距離等屬性。
如果缺失值是非數值型的,就根據統計學中的眾數原理,用該屬性在其他所 有對象的取值次數最多的值(即出現頻率最高的值)來補齊該缺失的屬性值。比如
性別、類別等屬性。
(2)就近補齊法
對于一個包含缺失值的對象,就近補齊法在完整數據中找到一個與它最相似 的對象, 然后用這個相似對象的值來進行填充。不同的問題可能會選用不同的標
準來對相似進行判定。該方法的難度在于如何定義相似標準,主觀因素較多。
(3)聚類填充法
聚類是按照某個特定標準(如距離、密度等)把一個數據集分割成不同的類或 簇,同一類的數據盡可能聚集到一起,不同類數據盡量分離,使得同一個簇內的 數據對象的相似性盡可能大,同時不在同一個簇中的數據對象的差異性也盡可能 地大。把數據分好類后可以在每個類別中處理缺失值,最經典的聚類算法是K-? 近鄰算法 (KNN) , 建議同學們在使用時根據數據屬性合理選擇距離和K(類別)
個數。
(4)回歸方程法
用不含缺失值的數據集建立回歸方程,把缺失值的點代入回歸方程即可預測 缺失值,在具體使用時應該注意要留出一部分數據驗證你的回歸方程的準確性
(建議測試數據比例20%)。
3.異常值處理
異常值是指樣本中的個別值,其數值明顯異于其他觀測值,異常值也叫離群 點。在比賽中,出題方可能會故意提供異常數據,考察參賽選手的數據分析和處理能力。
(1)檢測方法
√? 基于實際問題
在一些實際問題中, 一方面可以用物理模型剔除一些異常值,比如用圓周運 動的臨界條件篩選速度異常值;另一方面,可以根據生活常識剔除異常值,比如車速有上限。
√? 基于統計學原理
若數據服從正態分布,根據正態分布的定義可知,在默認情況下我們可以認 定,距離超過平均值3δ的樣本是不存在的。因此,當樣本距離平均值大于3δ,
認為該樣本為異常值。

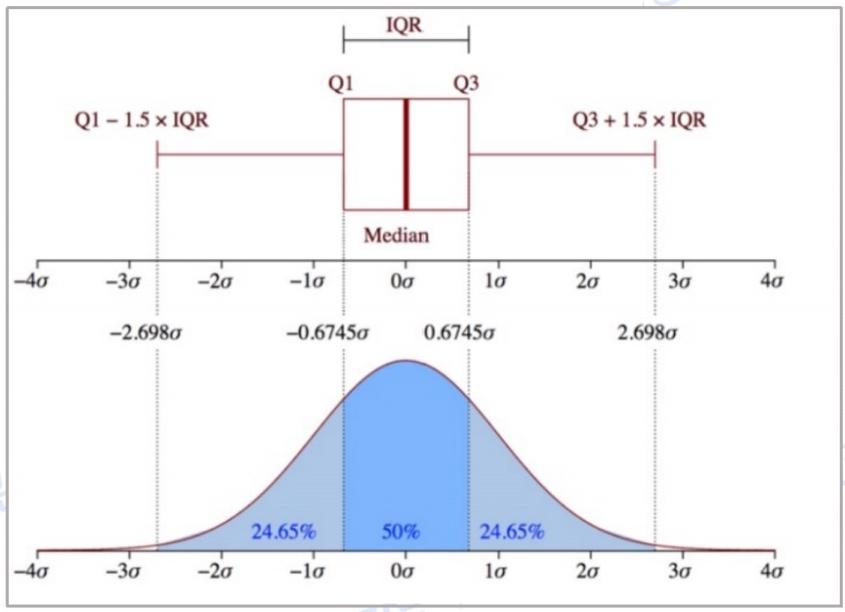
√? 箱線圖法
分位數:把數據分布劃成4個相等的部分,每個部分表示數據分布的四分之 一,稱為四分位數,100-分位數通常稱為百分位數,即劃為100個大小相等的部
分。中位數、四分位數和百分位數是使用最廣泛的分位數。
四分位極差:第1個和第3個四分位數之間的距離稱為四分位數極差,定義
為 :
IQR=Q?-Q?
五數概括由中位數(圖片圖片)、四分位數圖片圖片,最大值和最小值組成。
異常值識別的通常規則:挑選落在第3個四分位數之上或第1個四分位數之 下至少1.5×IQR的值。箱線圖的斷點一般在四分位數上,盒的長度是四分位數 極差IQR,?? 中位數用盒內的線標記,盒外的兩條線(胡須)延申到最小和最大觀 測值。僅當最大和最小觀測值超過四分位數不到1.5×IQR 時,胡須擴展,否則 胡須再出現在四分位數的1.5×IQR之內的最極端觀測值處終止,剩下的情況個
別列出。
該方法的優點在于既能對數據進行統計學描述,了解數據的整體特征,又能
可視化展示結果,簡潔清晰。
(2)處理方法
a). 為了避免異常值影響結果的正確性,直接刪除。
b).?在總體樣本量較少的情況下,不能簡單地刪除異常值,因為樣本量也很
影響結果,因此可以將異常值視為缺失值,使用缺失值處理方法來處理異常值。
4.無量綱化處理
無量綱化,也稱為數據的規范化,是指不同指標之間由于存在量綱不同致其
不具可比性,故首先需將指標進行無量綱化,消除量綱影響后再進行接下來的分
析。
常見的無量綱化處理方法主要有標準化(各指標均值為0,標準差為1)、 均值化(各指標數據構成協方差矩陣)和歸一化(將一列數據“拍扁”到某個固
定區間(常為[0,1]),和最大/小值有關),如歸一化公式:

5.數據量問題
數據樣本量不夠或者查不到數據,可以在一定約束條件下用隨機數生成,模 型適用即可。但切記要對模型做靈敏性分析和誤差分析,來證明隨機生成的數據
對模型的影響非常小。
數據不夠確實令人做題時無從下手,但物極必反,數據太多也不是什么好事, 如果某個賽題提供了很多數據,需要對多維數據做降維處理,減少數據冗余,常
見的方法有主成分分析法 (PCA) 、 線性判別分析等。
6.預測模型
預測模型要根據題目所給數據樣本量的大小,選擇合適的方法:
(1)灰色預測模型(樣本量<15)
數據樣本點個數少, 一般建議為6-15個,或者數據呈現指數或曲線的形式。
(2)微分方程預測(樣本量<100)
無法直接找到原始數據之間的關系,但可以建立微分方程,利用推導出的公
式預測數據。
(3)回歸預測(100<樣本量<1000)
回歸預測就是把預測的相關性原則作為基礎,把影響預測目標的各因素找出 來,然后找出這些因素和預測目標之間的函數關系的近似表達,并且用數學的方 法找出來。依據相關關系中自變量的個數不同分類,可分為一元回歸分析預測法
和多元回歸分析預測法。
7.插值與擬合
擬合與插值在數學建模競賽中非常常見,但有以下幾點需要留意:
(1)擬合與插值區別: 插值是離散函數逼近的重要方法,利用它可通過函 數在有限個點處的取值狀況,估算出函數在其他點處的近似值;擬合是指將平面
上的一系列點與光滑曲線連接起來。
(2)靈活掌握不同插值方法的適用條件:拉格朗日插值(?一?維)、分段線
性插值(多條件)、三次樣條插值(空間中的點)。
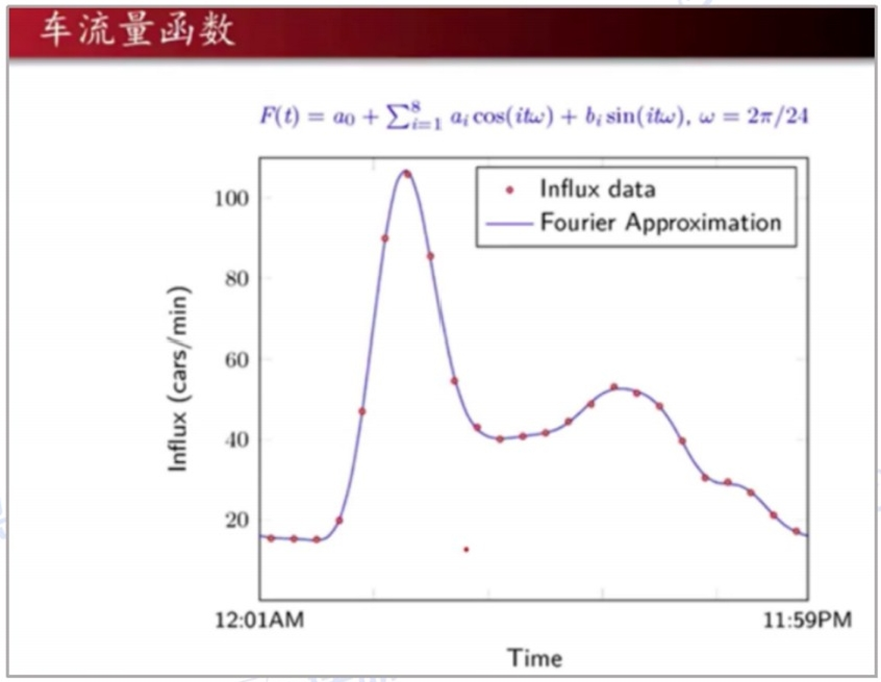
(3)靈活選擇擬合函數: 比如一道經典的數模國賽車流量預測問題,對于 車流量,每個點代表每一小時的平均值,而且車流量可以看作是以天為周期的周
期函數,再聯系不規則的函數曲線,可以考慮用傅里葉級數擬合。
(1)Excel:?????? 越簡單,越強大。你可能忽略了這個最常見的軟件,但在數據處理方面,它毫不遜色專業軟件,在數據可視化方面也方便操作。
(2)SPSS:?? 用于統計分析,圍繞統計學知識的一些基本應用,包括描述統 計,方差分析,因子分析,主成分分析,基本的回歸,分布的檢驗等等,我們前邊提到的箱線圖就可以用 SPSS一 鍵生成!
(3)Python:??????? 熟練掌握Numpy,Pandas,Matplotlib????? 庫 ,python??? 的強大無需多言,綜合且高效!
(4)Tableau:??????? 主要用于數據可視化展示,操作簡單,可以直接用鼠標來選 擇行、列標簽來生成各種不同的圖形圖表,而且Tableau?? 的設計、色彩及操作界
面簡單清新,做出來的圖更美觀。
(5)數據查找網站:
聯合國數據中心:https://www.un.org/zh/databases/
聯合國糧食及農業組織: FAOSTAT
谷歌學術: 思謀學術_谷歌學術搜索和文獻資源
美國運輸統計局: Bureau of Transportation Statistics
美國勞工統計局: https://stats.bls.gov/
美國農業部: USDA
美國人口統計局: http://www.census.gov/
美?????????? 國??????????? 普?????????? 查?????????? 局
http://2010.census.gov/2010census/language/chinese-simplified.php
中國國家統計局: http://www.stats.gov.cn/tjsj/
世界衛生組織: www.who.int/data/gh?? o

美國商務部經濟分析局: www.bea.gov/data
?Free GIS Data:freegisdata.rtwilson.com


?歡迎點擊下方名片加入通過下方名片加入美賽備戰 交流群
或者關注GZH :建模忠哥 ,建模期間提供免費的chatgpt3.5? ? ??


二十一 人臉識別)

)

)

)

![[隴劍杯 2021]日志分析](http://pic.xiahunao.cn/[隴劍杯 2021]日志分析)

 基于SSM 的商城購物系統(完整源代碼以及開發文檔))
)

:27、移除元素)



