data_loader是一個通用的術語,用于表示數據加載器或數據批次生成器。它是在機器學習和深度學習中常用的一個概念。
一、data loader
數據加載器(data loader)是一個用于加載和處理數據集的工具,它可以將數據集劃分為小批次(batches)并提供給模型進行訓練或推斷。數據加載器的主要目的是幫助有效地處理大規模數據集,并提供可迭代的接口,以便在每個批次中獲取數據。
在訓練模型時,通常需要將數據集分成多個批次進行訓練。這樣做的好處包括:
- 內存效率:將整個數據集一次性加載到內存中可能導致內存不足的問題,而使用數據加載器可以逐批次地加載數據,減少內存消耗。
- 訓練效率:使用批次訓練可以利用并行計算的優勢,加快模型訓練的速度。
- 模型收斂性:批次訓練可以提供更多的樣本多樣性,幫助模型更好地收斂。
數據加載器通常會接收以下參數:
- 數據集:要加載和處理的數據集。
- 批次大小(batch size):每個批次中包含的樣本數量。
- 隨機化(shuffle):是否在每個時期(epoch)開始時對數據進行隨機化,以提高模型的泛化能力。
數據加載器可以是自定義的實現,也可以是使用機器學習框架(如TensorFlow、PyTorch等)提供的內置函數或類來實現。它們通常會提供一個迭代器或生成器接口,使用戶可以通過迭代獲取每個批次的數據。
需要根據具體的機器學習框架和任務來選擇和使用適當的數據加載器。常見的數據加載器包括torch.utils.data.DataLoader(PyTorch)、tf.data.Dataset(TensorFlow)等。這些加載器提供了更多功能,如數據預處理、并行加載、數據增強等,以滿足不同的數據處理需求。
二、data_loader返回的每個batch的數據大小是怎么計算得到的?
data_loader返回的每個批次(batch)的數據大小是根據數據集的總樣本數量和批次大小來計算得到的。
通常情況下,數據集的總樣本數量可以通過查看數據集的長度或大小來獲取。例如,對于一個包含1000個樣本的數據集,總樣本數量為1000。
批次大小是指在每個批次中包含的樣本數量。它可以由用戶指定,通常是根據內存限制、模型訓練的效果和計算資源等因素來確定。常見的批次大小可以是32、64、128等。
計算每個批次的數據大小時,可以使用以下公式:
數據大小 = min(批次大小, 總樣本數量 - 當前批次索引 * 批次大小)其中,當前批次索引從0開始。這個公式的作用是確保在最后一個批次中,即使樣本數量不足一個完整的批次大小,也可以返回剩余的樣本。
以下是一個簡單的示例代碼,演示如何計算每個批次的數據大小:
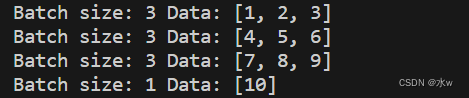
import mathdef data_loader(dataset, batch_size):total_samples = len(dataset)num_batches = math.ceil(total_samples / batch_size)for i in range(num_batches):start_index = i * batch_sizeend_index = min((i + 1) * batch_size, total_samples)data_batch = dataset[start_index:end_index]yield data_batch# 示例數據集
dataset = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
batch_size = 3# 使用data_loader函數加載數據集
loader = data_loader(dataset, batch_size)# 遍歷每個批次的數據
for batch in loader:print("Batch size:", len(batch), "Data:", batch)在上面的示例中,我們定義了一個data_loader函數,它接收數據集和批次大小作為輸入,并使用生成器(generator)來逐個返回每個批次的數據。然后,我們使用示例數據集和批次大小調用data_loader函數,并遍歷每個批次的數據。在輸出中,我們可以看到每個批次的數據大小和對應的數據。
請注意,以上示例中的數據集是一個簡單的列表,實際應用中的數據集可能是一個文件、數據庫或其他數據源,需要根據具體情況進行適當的處理和加載。
工程中提示詞的開發優化基礎概念學習總結)
)









 函數 ))







