1.研究背景與意義
項目參考AAAI Association for the Advancement of Artificial Intelligence
研究背景與意義
辣椒是一種重要的經濟作物,被廣泛種植和消費。然而,辣椒的產量預測一直是農業生產中的重要問題。準確地預測辣椒的產量可以幫助農民合理安排種植計劃、優化農業資源配置、提高農業生產效益,從而推動農業可持續發展。
傳統的辣椒產量預測方法主要依賴于人工經驗和統計模型,這些方法往往受限于數據采集的不完整性和主觀性,預測精度較低。隨著互聯網和深度學習技術的快速發展,基于Web和深度學習的辣椒檢測產量預測系統成為可能。
首先,基于Web的辣椒檢測產量預測系統可以通過互聯網收集大量的辣椒生長環境數據和農業管理數據。這些數據包括土壤濕度、溫度、光照強度、氣象條件等,以及農民的種植管理記錄。通過分析這些數據,可以建立辣椒生長環境與產量之間的關系模型,從而實現對辣椒產量的準確預測。
其次,深度學習技術在圖像識別和模式識別方面取得了巨大的突破。辣椒的生長過程中,葉片顏色、形狀、大小等特征會發生變化,這些特征與辣椒的產量密切相關。基于深度學習的圖像識別算法可以從辣椒生長過程中獲取的圖像中提取這些特征,并通過訓練模型實現對辣椒產量的預測。
基于Web和深度學習的辣椒檢測產量預測系統具有以下幾個重要意義:
-
提高辣椒產量預測的準確性:傳統的預測方法受限于數據采集和模型建立的局限性,預測精度較低。基于Web和深度學習的系統可以充分利用大量的數據和強大的模式識別能力,提高辣椒產量預測的準確性。
-
優化農業資源配置:準確地預測辣椒的產量可以幫助農民合理安排種植計劃,避免資源的浪費和過度投入。農民可以根據預測結果調整施肥、澆水、病蟲害防治等農業管理措施,提高農業生產效益。
-
推動農業可持續發展:辣椒產量的準確預測可以幫助農民提前做好市場調研和銷售計劃,避免產量過剩或供不應求的情況發生。合理的產量預測可以平衡供需關系,穩定市場價格,促進農業可持續發展。
-
拓展農業科技應用:基于Web和深度學習的辣椒檢測產量預測系統是農業科技與互聯網、人工智能的結合,為農業科技應用拓展了新的領域。該系統的研究和應用可以為其他作物的產量預測提供借鑒和參考,推動農業科技的創新和發展。
綜上所述,基于Web和深度學習的辣椒檢測產量預測系統具有重要的研究背景和意義。通過充分利用互聯網和深度學習技術,該系統可以提高辣椒產量預測的準確性,優化農業資源配置,推動農業可持續發展,拓展農業科技應用。這對于提高農業生產效益、保障糧食安全、促進農村經濟發展具有重要的實際意義。
2.圖片演示



3.視頻演示
基于Web和深度學習的辣椒檢測產量預測系統_嗶哩嗶哩_bilibili
4.數據集的采集&標注和整理
圖片的收集
首先,我們需要收集所需的圖片。這可以通過不同的方式來實現,例如使用現有的公開數據集LJDatasets。
labelImg是一個圖形化的圖像注釋工具,支持VOC和YOLO格式。以下是使用labelImg將圖片標注為VOC格式的步驟:
(1)下載并安裝labelImg。
(2)打開labelImg并選擇“Open Dir”來選擇你的圖片目錄。
(3)為你的目標對象設置標簽名稱。
(4)在圖片上繪制矩形框,選擇對應的標簽。
(5)保存標注信息,這將在圖片目錄下生成一個與圖片同名的XML文件。
(6)重復此過程,直到所有的圖片都標注完畢。
由于YOLO使用的是txt格式的標注,我們需要將VOC格式轉換為YOLO格式。可以使用各種轉換工具或腳本來實現。

下面是一個簡單的方法是使用Python腳本,該腳本讀取XML文件,然后將其轉換為YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-import xml.etree.ElementTree as ET
import osclasses = [] # 初始化為空列表CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:classes.append(cls) # 如果類別不存在,添加到classes列表中cls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')xml_path = os.path.join(CURRENT_DIR, './label_xml/')# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:label_name = img_xml.split('.')[0]print(label_name)convert_annotation(label_name)print("Classes:") # 打印最終的classes列表
print(classes) # 打印最終的classes列表整理數據文件夾結構
我們需要將數據集整理為以下結構:
-----data|-----train| |-----images| |-----labels||-----valid| |-----images| |-----labels||-----test|-----images|-----labels確保以下幾點:
所有的訓練圖片都位于data/train/images目錄下,相應的標注文件位于data/train/labels目錄下。
所有的驗證圖片都位于data/valid/images目錄下,相應的標注文件位于data/valid/labels目錄下。
所有的測試圖片都位于data/test/images目錄下,相應的標注文件位于data/test/labels目錄下。
這樣的結構使得數據的管理和模型的訓練、驗證和測試變得非常方便。
模型訓練
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代碼講解
5.1 export.py
def export_formats():# YOLOv5 export formatsx = [['PyTorch', '-', '.pt', True, True],['TorchScript', 'torchscript', '.torchscript', True, True],['ONNX', 'onnx', '.onnx', True, True],['OpenVINO', 'openvino', '_openvino_model', True, False],['TensorRT', 'engine', '.engine', False, True],['CoreML', 'coreml', '.mlmodel', True, False],['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],['TensorFlow GraphDef', 'pb', '.pb', True, True],['TensorFlow Lite', 'tflite', '.tflite', True, False],['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],['TensorFlow.js', 'tfjs', '_web_model', False, False],['PaddlePaddle', 'paddle', '_paddle_model', True, True],]return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])def try_export(inner_func):# YOLOv5 export decorator, i..e @try_exportinner_args = get_default_args(inner_func)def outer_func(*args, **kwargs):prefix = inner_args['prefix']try:with Profile() as dt:f, model = inner_func(*args, **kwargs)LOGGER.info(f'{prefix} export success ? {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')return f, modelexcept Exception as e:LOGGER.info(f'{prefix} export failure ? {dt.t:.1f}s: {e}')return None, Nonereturn outer_func@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):# YOLOv5 TorchScript model exportLOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')f = file.with_suffix('.torchscript')ts = torch.jit.trace(model, im, strict=False)d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.htmloptimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)else:ts.save(str(f), _extra_files=extra_files)return f, None@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):# YOLOv5 ONNX exportcheck_requirements('onnx>=1.12.0')import onnxLOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')f = file.with_suffix('.onnx')output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']if dynamic:dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)if isinstance(model, SegmentationModel):dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)elif isinstance(model, DetectionModel):dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)torch.onnx.export(model.cpu() if dynamic else model, # --dynamic only compatible with cpuim.cpu() if dynamic else im,f,verbose=False,opset_version=opset,do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=Falseinput_names=['images'],output_names=output_names,dynamic_axes=dynamic or None)# Checksmodel_onnx = onnx.load(f) # load onnx modelonnx.checker.check_model(model_onnx) # check onnx model# Metadatad = {'stride': int(max(model.stride)), 'names': model.names}for k, v in d.items():meta = model_onnx.metadata_props.add()meta.key, meta.value = k, str(v)onnx.save(model_onnx, f)# Simplifyif simplify:try:cuda = torch.cuda.is_available()check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))import onnxsimLOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')model_simp, check = onnxsim.simplify(f, check=True)assert check, 'assert check failed'onnx.save(model_simp, f)except Exception as e:LOGGER.info(f'{prefix} simplifier failure {e}')return f, None
export.py是一個用于將YOLOv5 PyTorch模型導出為其他格式的程序文件。它支持導出的格式包括PyTorch、TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle。通過運行export.py文件,可以根據命令行參數指定要導出的格式,以及模型權重文件的路徑。導出的模型文件將保存在指定的輸出路徑中。
export.py文件中定義了一些輔助函數,如export_torchscript和export_onnx,用于實際執行導出操作。這些函數使用PyTorch和ONNX庫來導出模型,并將導出的模型保存為相應的文件格式。
export.py文件還包含一些用于解析命令行參數、檢查環境要求和打印日志的輔助函數。這些函數確保導出過程順利進行,并提供必要的信息和反饋。
使用export.py文件時,可以通過命令行參數指定要導出的模型權重文件和要導出的格式。導出的模型文件將保存在當前目錄或指定的輸出目錄中。導出過程中會打印出導出的進度和結果。
此外,export.py文件還提供了一個示例用法和一些與TensorFlow.js相關的說明。示例用法演示了如何使用導出的模型進行推理。與TensorFlow.js相關的說明介紹了如何在TensorFlow.js中使用導出的模型。
總之,export.py文件是一個用于將YOLOv5 PyTorch模型導出為其他格式的工具文件,提供了豐富的導出選項和靈活的使用方式。
5.2 web.py
import cv2
import torch
import torch.backends.cudnn as cudnn
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.general import (non_max_suppression, scale_coords)
from utils.torch_utils import select_device, time_sync
import numpy as npclass ObjectDetector:def __init__(self, weights='./best.pt', data='./data/coco128.yaml', device='', half=False, dnn=False):self.device = select_device(device)self.model = self.load_model(weights, data, half, dnn)self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.namesdef load_model(self, weights, data, half, dnn):device = select_device(self.device)model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.enginehalf &= (pt or jit or onnx or engine) and device.type != 'cpu'if pt or jit:model.model.half() if half else model.model.float()return modeldef detect_objects(self, img, imgsz=(640, 640), conf_thres=0.25, iou_thres=0.05, max_det=1000, classes=None, agnostic_nms=False, augment=False, half=False):cal_detect = []im = letterbox(img, imgsz, self.model.stride, self.model.pt)[0]im = im.transpose((2, 0, 1))[::-1]im = np.ascontiguousarray(im)im = torch.from_numpy(im).to(self.device)im = im.half() if half else im.float()im /= 255if len(im.shape) == 3:im = im[None]pred = self.model(im, augment=augment)pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)for i, det in enumerate(pred):if len(det):det[:, :4] = scale_coords(im.shape[2:], det[:, :4], img.shape).round()for *xyxy, conf, cls in reversed(det):c = int(cls)label = f'{self.names[c]}'cal_detect.append([label, xyxy, float(conf)])return cal_detect......
這個程序文件是一個使用Remi庫創建的GUI應用程序。它包含了一個名為MyApp的類,該類繼承自Remi的App類。該應用程序的主要功能是顯示一個界面,其中包含一個圖像、一個計數器、一個文本輸入框、一個標簽和一個滑塊。用戶可以通過點擊圖像、選擇文件、滑動滑塊等操作與應用程序進行交互。應用程序還包含一些其他功能,如定時器、文件上傳和下載等。此外,該應用程序還包含一個名為run的函數,用于運行目標檢測模型并返回檢測結果。
5.3 init.py
以下是封裝為類后的代碼:
import paddleocr
from .paddleocr import *class PaddleOCR:def __init__(self):self.__version__ = paddleocr.VERSIONself.__all__ = ['PaddleOCR', 'PPStructure', 'draw_ocr', 'draw_structure_result', 'save_structure_res','download_with_progressbar']
這個程序文件是一個Python模塊的初始化文件,文件名為__init__.py。該文件包含了一些版權信息和許可證,以及導入了paddleocr模塊和一些函數和類。導入的函數和類包括PaddleOCR、PPStructure、draw_ocr、draw_structure_result、save_structure_res和download_with_progressbar。此外,該文件還定義了兩個變量__version__和__all__,其中__version__存儲了paddleocr的版本號,__all__列出了該模塊對外暴露的函數和類的名稱。
5.4 models\common.py
import math
import torch
import torch.nn as nnclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class DWConv(Conv):# Depth-wise convolutiondef __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activationsuper().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)class DWConvTranspose2d(nn.ConvTranspose2d):# Depth-wise transpose convolutiondef __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_outsuper().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))class TransformerLayer(nn.Module):# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)def __init__(self, c, num_heads):super().__init__()self.q = nn.Linear(c, c, bias=False)self.k = nn.Linear(c, c, bias=False)self.v = nn.Linear(c, c, bias=False)self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)self.fc1 = nn.Linear(c, c, bias=False)self.fc2 = nn.Linear(c, c, bias=False)def forward(self, x):x = self.ma(self.q(x), self.k(x), self.v(x))[0] + xx = self.fc2(self.fc1(x)) + xreturn xclass TransformerBlock(nn.Module):# Vision Transformer https://arxiv.org/abs/2010.11929def __init__(self, c1, c2, num_heads, num_layers):super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)self.linear = nn.Linear(c2, c2) # learnable position embeddingself.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))self.c2 = c2def forward(self, x):if self.conv is not None:x = self.conv(x)b, _, w,
這個程序文件是YOLOv5的一個模塊,主要包含了一些常用的模塊和函數。文件中定義了一些卷積層、池化層、殘差塊等常用的神經網絡模塊,以及一些輔助函數和工具函數。這些模塊和函數可以用于構建YOLOv5模型的各個組件,如backbone、neck和head等。
5.5 models\experimental.py
class Sum(nn.Module):def __init__(self, n, weight=False):super().__init__()self.weight = weightself.iter = range(n - 1)if weight:self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True)def forward(self, x):y = x[0]if self.weight:w = torch.sigmoid(self.w) * 2for i in self.iter:y = y + x[i + 1] * w[i]else:for i in self.iter:y = y + x[i + 1]return yclass MixConv2d(nn.Module):def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True):super().__init__()n = len(k)if equal_ch:i = torch.linspace(0, n - 1E-6, c2).floor()c_ = [(i == g).sum() for g in range(n)]else:b = [c2] + [0] * na = np.eye(n + 1, n, k=-1)a -= np.roll(a, 1, axis=1)a *= np.array(k) ** 2a[0] = 1c_ = np.linalg.lstsq(a, b, rcond=None)[0].round()self.m = nn.ModuleList([nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU()def forward(self, x):return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))class Ensemble(nn.ModuleList):def __init__(self):super().__init__()def forward(self, x, augment=False, profile=False, visualize=False):y = [module(x, augment, profile, visualize)[0] for module in self]y = torch.cat(y, 1)return y, Nonedef attempt_load(weights, device=None, inplace=True, fuse=True):from models.yolo import Detect, Modelmodel = Ensemble()for w in weights if isinstance(weights, list) else [weights]:ckpt = torch.load(attempt_download(w), map_location='cpu')ckpt = (ckpt.get('ema') or ckpt['model']).to(device).float()if not hasattr(ckpt, 'stride'):ckpt.stride = torch.tensor([32.])if hasattr(ckpt, 'names') and isinstance(ckpt.names, (list, tuple)):ckpt.names = dict(enumerate(ckpt.names))model.append(ckpt.fuse().eval() if fuse and hasattr(ckpt, 'fuse') else ckpt.eval())for m in model.modules():t = type(m)if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model):m.inplace = inplaceif t is Detect and not isinstance(m.anchor_grid, list):delattr(m, 'anchor_grid')setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):m.recompute_scale_factor = Noneif len(model) == 1:return model[-1]print(f'Ensemble created with {weights}\n')for k in 'names', 'nc', 'yaml':setattr(model, k, getattr(model[0], k))model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].strideassert all(model[0].nc == m.nc for m in model), f'Models have different class counts: {[m.nc for m in model]}'return model
這個程序文件是YOLOv5的實驗模塊。文件中定義了幾個自定義的模塊和函數。
-
Sum類:實現了多個層的加權求和。可以選擇是否應用權重。
-
MixConv2d類:實現了混合的深度卷積。可以選擇是否使用相同的通道數。
-
Ensemble類:模型的集合,可以同時處理多個模型的輸出。
-
attempt_load函數:加載模型權重。可以加載單個模型或多個模型的集合。
該文件還導入了其他模塊和函數,如utils.downloads模塊和models.yolo模塊。
總體來說,這個程序文件實現了YOLOv5的一些實驗模塊和加載模型權重的功能。
5.6 models\tf.py
import tensorflow as tf
from tensorflow import kerasclass TFBN(keras.layers.Layer):# TensorFlow BatchNormalization wrapperdef __init__(self, w=None):super().__init__()self.bn = keras.layers.BatchNormalization(beta_initializer=keras.initializers.Constant(w.bias.numpy()),gamma_initializer=keras.initializers.Constant(w.weight.numpy()),moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),這是一個使用TensorFlow和Keras實現的YOLOv5模型的程序文件。它包含了一些自定義的層,如TFBN、TFPad、TFConv等,用于構建YOLOv5模型的各個組件。該文件還包含了TFDetect類,用于進行目標檢測。程序中還包含了一些用于訓練和推理的函數。
6.系統整體結構
整體功能和構架概述:
該項目是一個基于Web和深度學習的辣椒檢測產量預測系統。它使用YOLOv5模型進行目標檢測,并提供了一個Web界面供用戶進行交互。系統的主要功能包括上傳圖片、進行目標檢測、顯示檢測結果、計算產量預測等。
該項目的代碼結構如下:
- export.py:將YOLOv5模型導出為其他格式的工具文件。
- web.py:使用Remi庫創建的GUI應用程序,提供了一個圖形界面供用戶進行交互。
- init.py:模塊的初始化文件,定義了一些導入的模塊和函數。
- models目錄:包含了YOLOv5模型的相關代碼。
- utils目錄:包含了一些輔助函數和工具類,用于模型訓練、推理和日志記錄等。
下面是每個文件的功能概述:
| 文件路徑 | 功能 |
|---|---|
| export.py | 將YOLOv5模型導出為其他格式的工具文件 |
| web.py | 使用Remi庫創建的GUI應用程序,提供圖形界面供用戶進行交互 |
| init.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| models\common.py | 包含了一些常用的模塊和函數,用于構建YOLOv5模型的各個組件 |
| models\experimental.py | 包含了YOLOv5的實驗模塊和加載模型權重的功能 |
| models\tf.py | 使用TensorFlow和Keras實現的YOLOv5模型的程序文件 |
| models\yolo.py | 包含了YOLOv5模型的定義和相關函數 |
| models_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\activations.py | 包含了一些激活函數的定義和相關函數 |
| utils\augmentations.py | 包含了一些數據增強的函數和類 |
| utils\autoanchor.py | 包含了自動錨框生成的函數和類 |
| utils\autobatch.py | 包含了自動批次大小調整的函數和類 |
| utils\callbacks.py | 包含了一些回調函數的定義和相關函數 |
| utils\dataloaders.py | 包含了數據加載器的定義和相關函數 |
| utils\downloads.py | 包含了文件下載的函數和相關函數 |
| utils\general.py | 包含了一些通用的輔助函數和工具函數 |
| utils\loss.py | 包含了一些損失函數的定義和相關函數 |
| utils\metrics.py | 包含了一些評估指標的定義和相關函數 |
| utils\plots.py | 包含了一些繪圖函數的定義和相關函數 |
| utils\torch_utils.py | 包含了一些與PyTorch相關的輔助函數和工具函數 |
| utils\triton.py | 包含了與Triton Inference Server相關的輔助函數和工具函數 |
| utils_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\aws\resume.py | 包含了AWS上的模型恢復功能的函數和類 |
| utils\aws_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\flask_rest_api\example_request.py | 包含了Flask REST API的示例請求的函數和類 |
| utils\flask_rest_api\restapi.py | 包含了Flask REST API的定義和相關函數 |
| utils\loggers_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\loggers\clearml\clearml_utils.py | 包含了ClearML日志記錄工具的輔助函數和工具函數 |
| utils\loggers\clearml\hpo.py | 包含了ClearML的超參數優化功能的函數和類 |
| utils\loggers\clearml_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\loggers\comet\comet_utils.py | 包含了Comet日志記錄工具的輔助函數和工具函數 |
| utils\loggers\comet\hpo.py | 包含了Comet的超參數優化功能的函數和類 |
| utils\loggers\comet_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\loggers\wandb\log_dataset.py | 包含了WandB日志記錄工具的數據集記錄功能的函數和類 |
| utils\loggers\wandb\sweep.py | 包含了WandB的超參數優化功能的函數和類 |
| utils\loggers\wandb\wandb_utils.py | 包含了WandB日志記錄工具的輔助函數和工具函數 |
| utils\loggers\wandb_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
| utils\segment\augmentations.py | 包含了圖像分割任務的數據增強函數和類 |
| utils\segment\dataloaders.py | 包含了圖像分割任務的數據加載器的定義和相關函數 |
| utils\segment\general.py | 包含了圖像分割任務的一些通用輔助函數和工具函數 |
| utils\segment\loss.py | 包含了圖像分割任務的損失函數的定義和相關函數 |
| utils\segment\metrics.py | 包含了圖像分割任務的評估指標的定義和相關函數 |
| utils\segment\plots.py | 包含了圖像分割任務的繪圖函數的定義和相關函數 |
| utils\segment_init_.py | 模塊的初始化文件,定義了一些導入的模塊和函數 |
7.YOLOv5模型
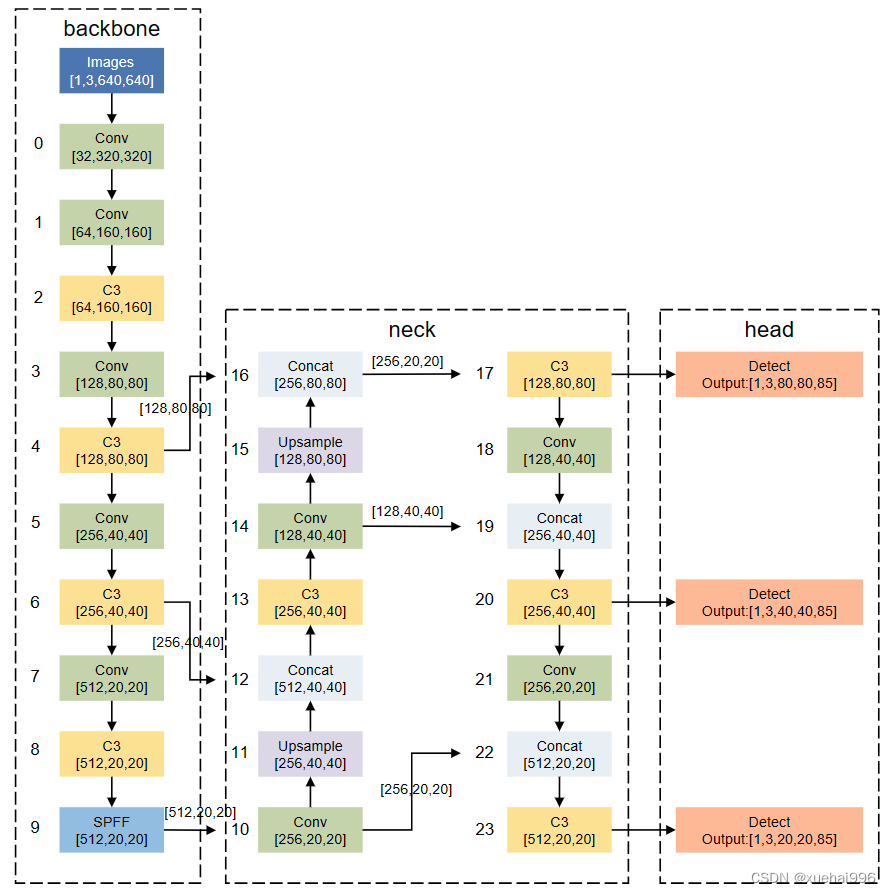
YOLO[15]系列網絡模型是最為經典的one-stage算法,在目標檢測的網絡里面,它是在工業領域使用最多的網絡模型。YOLOv5網絡模型在繼承了原有YOLO網絡模型優點的基礎上,具有更優的檢測精度和更快的推理速度。模型的整體結構如圖1所示。YOLOv5網絡結構由輸入端(Input)、Backbone、Neck、Head 組件組成。各部分完成的主要功能,所述如下:
(1)Input: YOLOv5采用了YOLOv4中的 Mosaic數據增強方法來豐富數據集,降低硬件需求,從而減少了GPU的使用。此外,自適應錨框計算功能被嵌入到整個訓練代碼中,可以根據需要自行調節開關,同時也實現了自適應圖片縮放,這有助于提高目標檢測的推理速度。
(2) Backbone: Focus模塊將輸入的圖片數據分成四份,每一份數據相當于進行了2倍下采樣,然后將這四份數據進行拼接,得到一個尺寸縮小一半的新特征圖。最后,通過卷積操作將信息進行融合,并改變特征圖的通道數。這種方法的優點是能夠最大程度地減少信息損失和計算量,同時增加了難樣本和數據的多樣性。
(3)Neck:在 YOLOv5網絡模型中,頸部網絡主要負責對主干網絡提取的特征進行增強處理,以提高后續預測的精度。原始的FPN結構采用自頂向下的特征融合方式來處理目標檢測領域中的多尺度變化問題,已經在許多模型中得到了廣泛應用。但是,如果僅使用FPN結構來融合上下文信息,則無法實現上層信息與底層信息的交流。因此,在FPN 的基礎上,YOLOv5網絡還加入了PAN結構,引入了一條自下而上的信息流,充分實現了網絡上下信息流的融合,從而提高了網絡的檢測能力。
(4)Head: YOLOv5采用損失函數CIOU-Loss,可以將一些遮擋重疊的目標準確識別出來。
8.訓練結果分析
本實驗訓練過程在Ubuntul8.0、CUDA11.0環境下進行,GPU配置:NVIDIA GeForce RTX 4090,24GB顯存,調用GPU進行訓練。所有實驗訓練參數設置:輸入圖片大小為640×640
優化器采用帶動量的SGD優化器,初始學習率設置為0.001、批大小為16,共訓練200輪。檢測結果如圖所示:

由測試結果可知,經過改進的網絡識別準確度獲得較大提高,從圖(a)和圖(b)兩張圖片中可以看出,改進后的CM-YOLO 網絡的Map比原始YOLOv5s網絡有所提升,如在有葉子遮擋的情況下,原始YOLOv5s網絡識別目標框的Map為0.52,如圖(a)所示,CM-YOLO模型的Map為0.82,如圖(b)所示。因此CM-YOLO 網絡目標識別框的位置更加精準。
通過實驗結果比較原始YOLOv5s模型與CM-YOLO模型對于辣椒果實目標檢測識別的效果,從準確率Precision,平均精度(mAP),召回率Recall對算法進行比較,比較結果如表所示,具體地。
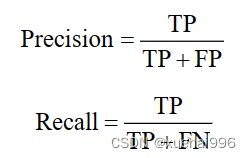
TP表示實際為正樣本且被分類器正確預測為正樣本的樣本數量,FP表示實際為負樣本但被分類器錯誤地預測為正樣本的樣本數量,FN表示實際為正樣本但被分類器錯誤地預測為負樣本的樣本數量。Precision表示分類器正確預測為正樣本的樣本數量占分類器預測為正樣本的所有樣本數量的比例,Recall表示分類器正確預測為正樣本的樣本數量占所有實際為正樣本的樣本數量的比例。

由表1可以看出,基于CM-YOLO的辣椒檢測平均精度和召回率更高,能夠較好地完成辣椒檢測任務。圖是原始YOLOv5模型與CM-YOLO模型特征可視化對比,由圖可以看出,CM-YOLO模型提取的辣椒線條更加明顯。

9.系統整合
下圖完整源碼&數據集&環境部署視頻教程&自定義UI界面

參考博客《基于Web和深度學習的辣椒檢測產量預測系統》
10.參考文獻
[1] 朱智惟, 單建華, 余賢海, 等. 基于 YOLOv5s 的番茄采摘機器人目標檢測技術[J]. 傳感器與微統, 2023, 42(6):
129-132. https://doi.org/10.13873/J.1000-9787(2023)06-0129-04
[2] 趙敬, 王全有, 褚幼暉, 等. 農業采摘機器人發展分析及前景展望[J]. 農機使用與維修, 2023(6): 63-70.
https://doi.org/10.14031/j.cnki.njwx.2023.06.019
[3] 高帥, 劉永華, 高菊玲, 等. 基于 YOLOv3 算法與 3D 視覺的農業采摘機器人目標識別與定位研究[J]. 中國農機
化學報, 2022, 43(12): 178-183. https://doi.org/10.13733/j.jcam.issn.2095-5553.2022.12.026
[4] 李亞濤. 茶葉采摘機器人的視覺檢測與定位技術研究[D]: [博士學位論文]. 杭州: 浙江理工大學, 2022.
https://doi.org/10.27786/d.cnki.gzjlg.2022.000006
[5] 魏天宇, 柳天虹, 張善文, 等. 基于改進 YOLOv5s 的辣椒采摘機器人識別定位方法[J]. 揚州大學學報(自然科學
版), 2023, 26(1): 61-69. https://doi.org/10.19411/j.1007-824x.2023.01.010
[6] 劉麗娟, 竇佩佩, 王慧. 自然環境下重疊與遮擋蘋果圖像識別方法研究[J]. 中國農機化學報, 2021, 42(6):
174-181. https://doi.org/10.13733/j.jcam.issn.2095-5553.2021.06.27
[7] Whittaker, D.E., Miles, G.R., Mitchell, O.D. and Gaultney, L. (1987) Fruit Location in a Partially Occluded Image.
Transactions of the ASAE, 30, 591-596. https://doi.org/10.13031/2013.30444
[8] Gongal, A., et al. (2016) Apple Crop-Load Estimation with Over-the-Row Machine Vision System. Computers and
Electronics in Agriculture, 120, 26-35. https://doi.org/10.1016/j.compag.2015.10.022
[9] 李杰. 結合改進注意力機制的 YOLO 目標檢測算法[J]. 計算機時代, 2023(7): 108-113.
https://doi.org/10.16644/j.cnki.cn33-1094/tp.2023.07.025
[10] Liu, W., et al. (2016) SSD: Single Shot MultiBox Detector. In: Leibe, B., Matas, J., Sebe, N. and Welling, M., Eds.,
Computer Vision—ECCV, Springer International Publishing, Berlin, 21-37.
[11] Mehta, S.S., Ton, C., Asundi, S. and Burks, T.F. (2017) Multiple Camera Fruit Localization Using a Particle Filter.
Computers and Electronics in Agriculture, 142, 139-154. https://doi.org/10.1016/j.compag.2017.08.007
[12] Nyarko, E.K., Vidovi?, I., Rado?aj, K. and Cupec, R. (2018) A Nearest Neighbor Approach for Fruit Recognition in

)






![[筆記]ARMv7/ARMv8 交叉編譯器下載](http://pic.xiahunao.cn/[筆記]ARMv7/ARMv8 交叉編譯器下載)








![[Kadane算法,前綴和思想]元素和最大的子矩陣](http://pic.xiahunao.cn/[Kadane算法,前綴和思想]元素和最大的子矩陣)

