原文鏈接:https://arxiv.org/abs/2308.03755
1. 引言
完全稀疏檢測器在基于激光雷達的3D目標檢測中有較高的效率和有效性,特別是對于長距離場景而言。
但是,由于點云的稀疏性,完全稀疏檢測器面臨的一大困難是中心特征丟失(CFM),即因為點云往往分布在物體表面,物體的中心特征通常會缺失。FSD引入實例級表達,通過聚類獲取實例,并提取實例級特征進行邊界框預測,以避免使用物體中心特征。但由于實例級表達有較強的歸納偏好,其泛化性不足。例如,聚類時需要對各類預定義閾值,且難以找到最優值;在擁擠的場景中可能使得多個實例被識別為一個實體,導致漏檢。
本文提出FSDv2,丟棄了FSD中的實例級表達,以追求更高的泛化性。本文引入虛擬體素以替代FSD中的實例,這些虛擬體素通過體素化投票中心得到。為減輕投票質量低帶來的影響,虛擬體素被輸入輕量級的稀疏虛擬體素混合器(VVM)增強特征,聚合屬于同一物體不同虛擬體素的特征,得到覆蓋整個實例的特征。VVM模擬了FSD中的實例級特征提取,但不顯式地生成實例,以避免產生手工的歸納偏好。由于虛擬體素位于物體中心附近,可將虛擬體素作為“錨點”,從中預測邊界框;這可減輕正負樣本的不平衡性。
2. 相關工作
2.1 密集檢測器
密集檢測器(如VoxelNet和PointPillars)將點云轉化為密集的3D體素或2D BEV,并使用密集的3D卷積或2D卷積處理。
2.2 半密集檢測器
半密集檢測器(如SECOND和CenterPoint)將點云轉化為稀疏3D體素,使用稀疏3D卷積處理后得到2D密集BEV特征,輸入檢測頭進行檢測。其余方法使用Transformer結構增強稀疏主干。
2.3 完全稀疏檢測器
完全稀疏檢測器(如PointRCNN和VoteNet)基于點云進行檢測,無需將點云轉化為體素。FSD避免了點云處理中耗時的操作。
3. 準備知識
3.1 FSDv1的整體設計
FSDv1主要包含3部分:(1)點特征提取:使用稀疏體素特征提取器提取體素特征,然后使用基于MLP的頸部網絡將體素特征轉化為點特征。最后使用輕量級的逐點MLP進行逐點分類和中心投票。(2)聚類:將連接組件標簽(CCL)應用在投票的中心,以將點聚類為實例。(3)實例特征提取和邊界框預測:詳見下文。
3.2 稀疏實例識別
FSDv1實例特征提取的核心是稀疏實例識別(SIR)。
首先,初始的實例點特征輸入MLP,并通過最大池化得到實例特征,與實例各點的特征拼接,輸入到另一MLP壓縮通道維度。迭代執行上述步驟后,將最大池化的結果用于邊界框預測。該方法類似一系列PointNet層。
4. 方法
4.1 總體結構
如下圖所示,首先使用稀疏體素特征提取器作為主干,并使用MLP用于逐點分類和中心投票(與FSDv1相同)。FSDv2使用虛擬體素化替代聚類,并使用虛擬體素混合器混合不同虛擬體素的特征,用于預測邊界框。
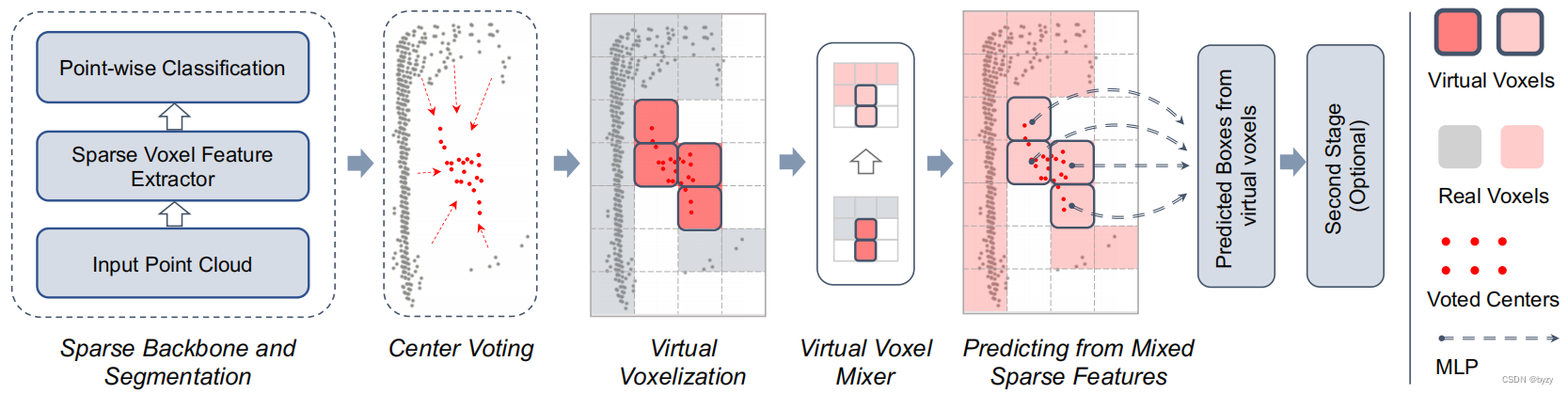
4.2 虛擬體素化
4.2.1 虛擬體素
使用投票中心創建虛擬體素。具體來說,對于每個前景點,預測偏移量得到投票中心。然后將各投票中心與原始點云的并集體素化。虛擬體素即至少包含一個投票中心的體素,而僅含真實點的體素則稱為真實體素。
雖然投票中心可能有很多,但虛擬體素一般較少,因為投票中心往往彼此接近,且體素大小會設置得比通常更大(主干已經捕捉了細粒度特征,此處無需高分辨率)。
4.2.2 虛擬體素特征編碼
引入虛擬體素編碼器,類似FSDv1中的SIR結構,區別在于FSDv1提取實例特征而本文提取體素特征。首先為投票中心生成特征,此處將生成投票中心的點的(經過主干編碼后的)特征作為投票中心特征,并將預測偏移量作為額外特征以與真實點區分。對于真實點則設置虛擬偏移量0。然后使用SIR結構聚合虛擬體素內真實點和虛擬點的特征。
4.3 虛擬體素混合器
虛擬體素混合器(VVM)用于混合虛擬體素特征、真實體素特征和主干輸出的多尺度特征。
4.3.1 混合虛擬體素特征的動機
當中心投票效果不佳時,一個物體的中心附近可能會有多個虛擬體素,但這些體素沒有交互。
4.3.2 混合虛擬體素與真實體素的動機
由于虛擬體素來自預測的前景點,當預測不準時會有前景信息損失。
4.3.3 混合多尺度特征
多尺度特征包含主干輸出的多尺度真實體素特征和4.1節中得到的虛擬/真實體素特征。由于特征是稀疏而不規則的,多尺度特征融合不能像圖像一樣進行通道維度的拼接。
設(相對于虛擬體素特征的)步長 s s s下的稀疏特征為 F s ∈ R N s × C s F_s\in\mathbb{R}^{N_s\times C_s} Fs?∈RNs?×Cs?,其中 N s N_s Ns?為體素數, C s C_s Cs?為通道數。體素的坐標為 I s ∈ R N s × 3 I_s\in\mathbb{R}^{N_s\times 3} Is?∈RNs?×3,轉化到 s ~ \tilde{s} s~步長下的坐標為 I s s ~ I_s^{\tilde{s}} Iss~?。虛擬體素化得到的特征為 F 1 F_1 F1?。首先將 I s I_s Is?轉化為 I s 1 I_s^1 Is1?:
I s 1 = I s × s + ? s / 2 ? I_s^1=I_s\times s+\lfloor{s/2}\rfloor Is1?=Is?×s+?s/2?
按下式得到聚合的稀疏特征和體素坐標:
F a g g = Concat ( Linear ( F 1 ) , Linear ( F 2 ) , ? , Linear ( F L ) ) I a g g = Concat ( I 1 , I 2 1 , ? , I L 1 ) F_{agg}=\text{Concat}(\text{Linear}(F_1),\text{Linear}(F_2),\cdots,\text{Linear}(F_L))\\ I_{agg}=\text{Concat}(I_1,I_2^1,\cdots,I_L^1) Fagg?=Concat(Linear(F1?),Linear(F2?),?,Linear(FL?))Iagg?=Concat(I1?,I21?,?,IL1?)
其中線性層用于將特征轉換為相同的通道數。
注意 I a g g I_{agg} Iagg?可能包含重復元素,因為不同尺寸的體素可能有相同的坐標。本文使用動態池化操作DP來去除重復坐標,將重復坐標對應的特征求取均值,得到單一特征。
4.3.4 VVM的模型結構
使用SparseUNet處理上述聚合結果。
4.4 討論:聚類v.s.虛擬體素
當中心投票一致時,所有投票中心位于同一虛擬體素內,假設聚類是完美的,則本文的虛擬體素化方法與FSDv1的實例表達類似。
但當中心投票不一致時,會導致多個虛擬體素,每個體素編碼了物體的部分形狀。虛擬體素混合器使得虛擬體素之間可以交互,以編碼完整幾何信息。此時也與FSDv1的實例表達類似。
總的來說,本文的方法可以避免SIR中的手工參數設計,使得模型更簡單通用。
4.5 虛擬體素分配
4.5.1 潛在的設計選擇
傳統的分配方法對于虛擬體素而言是次優的。因為:
- 虛擬體素不總是填充物體中心,特別是對于遠處或大型物體。因此,基于中心的分配方法是不可行的。
- 基于錨框的方法需要逐類的超參數(如錨框大小),這和本文提高泛化性的設計思路沖突。
- 最近體素分配方法(將離中心最近的體素分配給對應的物體)會導致模糊性且阻礙優化。因為多個虛擬體素可能位于同一物體中心附近,但只有一個能作為匹配結果。
4.5.2 本文的方法:邊界框內體素分配
本文將邊界框內的所有虛擬體素作為正樣本。
- 由于虛擬體素數遠少于真實體素數,不會導致不同物體的正樣本數不平衡。且能提高點很少的物體的召回率。
- 由于虛擬體素分布于物體中心附近,考慮所有虛擬體素不會導致回歸目標有較大方差。
- 由于真實的邊界框標注不會重疊,且點云的稀疏性保證邊界框內不包含背景噪聲,使得這種分配方法可靠。這解釋了為什么基于圖像的2D檢測需要更加復雜的策略。
4.5.3 虛擬體素位置定義
直接的方法是將體素的幾何中心作為虛擬體素的位置,但會導致不精確性和模糊性,因為體素的大小可能會超過一些小物體的大小。
本文考慮體素內點的分布,將體素的位置定義為所含點的加權中心:
x ˉ = ∑ i = 0 N ? 1 I ( x i ) x i ∑ i = 0 N ? 1 I ( x i ) \bar{x}=\frac{\sum_{i=0}^{N-1}I(x_i)x_i}{\sum_{i=0}^{N-1}I(x_i)} xˉ=∑i=0N?1?I(xi?)∑i=0N?1?I(xi?)xi??
其中
I ( x ) = { 1 , 若 x ∈ F α , 若 x ? F I(x)=\left\{\begin{matrix}1,& 若x\in \mathbb{F}\\\alpha,&若x\notin \mathbb{F}\end{matrix}\right. I(x)={1,α,?若x∈F若x∈/F?
其中 F \mathbb{F} F為前景點(包含原始點和投票中心)集合, α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1]。
4.6 虛擬體素頭
VVM輸出的虛擬體素特征會輸入一組MLP預測最終邊界框。本文類似CenterPoint進行類別分組。分類分支使用Focal損失,回歸分支使用L1損失,回歸對象包含虛擬體素幾何中心到物體邊界框質心的偏移量、尺寸的對數以及朝向角的正余弦。
5. 實驗
5.3 主要結果
在WOD數據集和Argoverse數據集上,本文的方法能達到SotA;在nuScenes數據集上,本文的方法能與SotA性能相當。
5.4 聚類v.s.虛擬體素
5.4.1 統計數據
- 對于大型物體,通常對應多個虛擬體素,且虛擬體素的數量大于聚類簇的數量,這表明VVM的必要性。
- 對小型物體,虛擬體素和簇的數量都很少,此時二者功能相當。
- 大型車輛的真實體素比簇和虛擬體素的數量多很多,這表明使用真實體素進行預測會導致不同大小物體的不平衡,而使用較少的虛擬體素預測能減輕這一問題。
5.4.2 擁擠場景的性能
若一個物體和與其最近的同類物體的距離小于2m,則定義該物體處于擁擠場景。性能分解表明,相比于FSDv1,FSDv2在擁擠場景物體上的性能提升比常規場景更大。
5.4.3 消除歸納偏好的有效性
實驗表明,FSDv1隨訓練輪數的增加,性能逐漸飽和;而FSDv2的性能持續上升。
5.5 主要消融研究
5.5.1 基準方案設置
- 不生成投票中心,但保留投票損失作為額外監督。
- 僅對真實點使用體素化和體素編碼,沒有虛擬體素。
- 真實體素不通過混合器,直接輸入檢測頭預測結果。
- 由于虛擬體素分配策略對小物體檢測有重要影響,保留之。
實驗表明,逐步增加本文提出的模塊能在各數據集上一致提高性能。且混合器和虛擬體素對相對大型的物體有性能提升。
5.6 每個組件的性能分析
5.6.1 虛擬體素的有效性
為理解虛擬體素機制的作用,本文設計退化策略,即為預測的中心投票偏移量乘上一個縮放因數 s ∈ [ 0 , 1 ] s\in[0,1] s∈[0,1],當 s = 1 s=1 s=1時為FSDv2的正常情況; s = 0 s=0 s=0時虛擬體素完全退化。實驗表明:
- 大型物體在大縮放因數下的性能較好。因為大型物體的中心包含空體素的可能性更高。
- 縮放因數對小型物體的影響很小。因為此時的偏移量很小,不同縮放因數下的虛擬體素位置接近。
- 對于barrier類別,大縮放因數能極大地提升性能。這是因為通常它們相鄰放置,小縮放因數會導致從兩個相鄰實例的邊界預測,導致模糊性。
5.6.2 虛擬體素編碼器(VVE)的作用
將投票中心的特征置零后進行編碼(這樣,虛擬體素的特征僅來自真實點)。實驗表明,上述改動會導致性能下降,且VVE對小物體的性能提升更明顯。
5.6.3 虛擬體素混合器的輸入
考慮三種組合:(1)僅輸入虛擬體素;(2)輸入虛擬體素和真實體素;(3)輸入虛擬體素和多尺度體素。實驗表明引入真實體素能極大提高性能,多尺度體素能在多數類別上進一步提高性能。
5.6.4 虛擬體素分配的作用
實驗表明:
- 略微增大小物體的GT框能幫助分配更多標簽,但過分增大會因為噪聲或邊界框重疊而降低性能。
- 使用虛擬體素質心比幾何中心對小物體更有利,進一步使用加權質心能進一步提高性能。
使用最近虛擬體素分配方法會導致性能嚴重下降,但增加分配的虛擬體素數量能減小性能下降。考慮最近的10個虛擬體素時性能達到飽和。
5.6.5 虛擬體素大小
實驗表明,性能對虛擬體素的大小不敏感,且更大的體素能有略高的性能,這是因為此時大型物體的虛擬體素更少,不同大小物體的樣本不平衡性被減輕。
5.7 運行時間評估
實驗表明,FSDv2比FSDv1有更高的性能和效率。其中FSDv2的虛擬體素化與體素編碼比FSDv1的聚類有更快的速度,但混合器考慮了真實體素,比FSDv1的SIR更慢。





![[筆記]ARMv7/ARMv8 交叉編譯器下載](http://pic.xiahunao.cn/[筆記]ARMv7/ARMv8 交叉編譯器下載)








![[Kadane算法,前綴和思想]元素和最大的子矩陣](http://pic.xiahunao.cn/[Kadane算法,前綴和思想]元素和最大的子矩陣)




