意義
客觀世界的場景含有豐富多彩的信息,但是由于受到硬件設備的成像條件和成像方式的限制,難以獲得原始場景中的所有信息。而且,硬件設備分辨率的限制會不可避免地使圖像丟失某些高頻細節信息。在當今信息迅猛發展的時代,在衛星遙感、醫學影像、多媒體視頻等領域中對圖像質量的要求越來越高,人們不斷尋求更高質量和更高分辨率的圖像,來滿足日益增長的需求。
空間分辨率的大小是衡量圖像質量的一個重要指標,也是將圖像應用到實際生活中重要的參數之一。分辨率越高的圖像含有的細節信息越多,圖像清晰度越高,在實際應用中對各種目標的識別和判斷也更加準確。
但是通過提高硬件性能從而提高圖像的分辨率的成本高昂。因此,為了滿足對圖像分辨率的需求,又不增加硬件成本的前提下,依靠軟件方法的圖像超分辨率重建應運而生。
超分辨率圖像重建是指從一系列有噪聲、模糊及欠采樣的低分辨率圖像序列中恢復出一幅高分辨率圖像的過程。可以針對現有成像系統普遍存在分辨率低的缺陷,運用某些算法,提高所獲得低分辨率圖像的質量。因此,超分辨率重建算法的研究具有廣闊的發展空間。
方法的具體細節
評價指標
峰值信噪比
峰值信噪比(Peak Signal-to-Noise Ratio), 是信號的最大功率和信號噪聲功率之比,來測量被壓縮的重構圖像的質量,通常以分貝來表示。PSNR指標值越高,說明圖像質量越好。
SSIM計算公式如下:
MSE表示兩個圖像之間對應像素之間差值平方的均值。
表示圖像中像素的最大值。對于8bit圖像,一般取255。
?表示圖像X在 ij 處的像素值
?表示圖像Y在 ij 處的像素值
結構相似性評價
結構相似性評價(Structural Similarity Index), 是衡量兩幅圖像相似度的指標,取值范圍為0到1。SSIM指標值越大,說明圖像失真程度越小,圖像質量越好。
SSIM計算公式如下:
?這兩種方式,一般情況下能較為準確地評價重建效果。但是畢竟人眼的感受是復雜豐富的,所以有時也會出現一定的偏差。
EDSR

SRResNet在SR的工作中引入了殘差塊,取得了更深層的網絡,而EDSR是對SRResNet的一種提升,其最有意義的模型性能提升是去除掉了SRResNet多余的模塊(BN層)
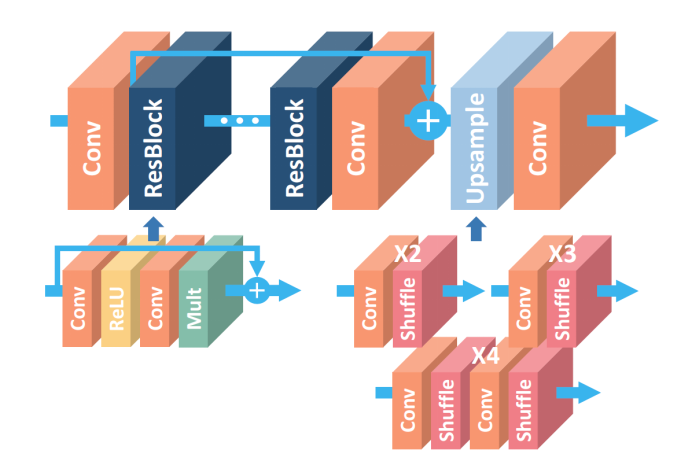
EDSR把批規范化處理(batch normalization, BN)操作給去掉了。
論文中說,原始的ResNet最一開始是被提出來解決高層的計算機視覺問題,比如分類和檢測,直接把ResNet的結構應用到像超分辨率這樣的低層計算機視覺問題,顯然不是最優的。由于批規范化層消耗了與它前面的卷積層相同大小的內存,在去掉這一步操作后,相同的計算資源下,EDSR就可以堆疊更多的網絡層或者使每層提取更多的特征,從而得到更好的性能表現。EDSR用L1損失函數來優化網絡模型。
1.解壓數據集
因為訓練時間可能不是很長,所以這里用了BSD100,可以自行更換為DIV2K或者coco
# !unzip -o /home/aistudio/data/data121380/DIV2K_train_HR.zip -d train# !unzip -o /home/aistudio/data/data121283/Set5.zip -d test?2.定義dataset
import os
from paddle.io import Dataset
from paddle.vision import transforms
from PIL import Image
import random
import paddle
import PIL
import numbers
import numpy as np
from PIL import Image
from paddle.vision.transforms import BaseTransform
from paddle.vision.transforms import functional as F
import matplotlib.pyplot as pltclass SRDataset(Dataset):def __init__(self, data_path, crop_size, scaling_factor):""":參數 data_path: 圖片文件夾路徑:參數 crop_size: 高分辨率圖像裁剪尺寸 (實際訓練時不會用原圖進行放大,而是截取原圖的一個子塊進行放大):參數 scaling_factor: 放大比例"""self.data_path=data_pathself.crop_size = int(crop_size)self.scaling_factor = int(scaling_factor)self.images_path=[]# 如果是訓練,則所有圖像必須保持固定的分辨率以此保證能夠整除放大比例# 如果是測試,則不需要對圖像的長寬作限定# 讀取圖像路徑for name in os.listdir(self.data_path):self.images_path.append(os.path.join(self.data_path,name))# 數據處理方式self.pre_trans=transforms.Compose([# transforms.CenterCrop(self.crop_size),transforms.RandomCrop(self.crop_size),transforms.RandomHorizontalFlip(0.5),transforms.RandomVerticalFlip(0.5),# transforms.ColorJitter(brightness=0.3, contrast=0.3, hue=0.3),])self.input_transform = transforms.Compose([transforms.Resize(self.crop_size//self.scaling_factor),transforms.ToTensor(),transforms.Normalize(mean=[0.5],std=[0.5]),])self.target_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5],std=[0.5]),])def __getitem__(self, i):# 讀取圖像img = Image.open(self.images_path[i], mode='r')img = img.convert('RGB')img=self.pre_trans(img)lr_img = self.input_transform(img)hr_img = self.target_transform(img.copy())return lr_img, hr_imgdef __len__(self):return len(self.images_path)
測試dataset
# 單元測試train_path='train/DIV2K_train_HR'
test_path='test'
ds=SRDataset(train_path,96,2)
l,h=ds[1]# print(type(l))
print(l.shape)
print(h.shape)l=np.array(l)
h=np.array(h)
print(type(l))
l=l.transpose(2,1,0)
h=h.transpose(2,1,0)
print(l.shape)
print(h.shape)plt.subplot(1, 2, 1)
plt.imshow(((l+1)/2))
plt.title('l')
plt.subplot(1, 2, 2)
plt.imshow(((h+1)/2))
plt.title('h')
plt.show()
定義網絡結構
較rsresnet少了歸一化層,以及更深的殘差塊
from paddle.nn import Layer
from paddle import nn
import mathn_feat = 256
kernel_size = 3# 殘差塊 尺寸不變
class _Res_Block(nn.Layer):def __init__(self):super(_Res_Block, self).__init__()self.res_conv = nn.Conv2D(n_feat, n_feat, kernel_size, padding=1)self.relu = nn.ReLU()def forward(self, x):y = self.relu(self.res_conv(x))y = self.res_conv(y)y *= 0.1# 殘差加入y = paddle.add(y, x)return yclass EDSR(nn.Layer):def __init__(self):super(EDSR, self).__init__()in_ch = 3num_blocks = 32self.conv1 = nn.Conv2D(in_ch, n_feat, kernel_size, padding=1)# 擴大self.conv_up = nn.Conv2D(n_feat, n_feat * 4, kernel_size, padding=1)self.conv_out = nn.Conv2D(n_feat, in_ch, kernel_size, padding=1)self.body = self.make_layer(_Res_Block, num_blocks)# 上采樣self.upsample = nn.Sequential(self.conv_up, nn.PixelShuffle(2))# 32個殘差塊def make_layer(self, block, layers):res_block = []for _ in range(layers):res_block.append(block())return nn.Sequential(*res_block)def forward(self, x):out = self.conv1(x)out = self.body(out)out = self.upsample(out)out = self.conv_out(out)return out看paddle能不能用gpu
import paddle
print(paddle.device.get_device())paddle.device.set_device('gpu:0')訓練,一般4個小時就可以達到一個不錯的效果,set5中psnr可以達到27左右,當然這時間還是太少了
import os
from math import log10
from paddle.io import DataLoader
import paddle.fluid as fluid
import warnings
from paddle.static import InputSpecif __name__ == '__main__':warnings.filterwarnings("ignore", category=Warning) # 過濾報警信息train_path='train/DIV2K_train_HR'test_path='test'crop_size = 96 # 高分辨率圖像裁剪尺寸scaling_factor = 2 # 放大比例# 學習參數checkpoint = './work/edsr_paddle' # 預訓練模型路徑,如果不存在則為Nonebatch_size = 30 # 批大小start_epoch = 0 # 輪數起始位置epochs = 10000 # 迭代輪數workers = 4 # 工作線程數lr = 1e-4 # 學習率# 先前的psnrpre_psnr=32.35try:model = paddle.jit.load(checkpoint)print('加載先前模型成功')except:print('未加載原有模型訓練')model = EDSR()# 初始化優化器scheduler = paddle.optimizer.lr.StepDecay(learning_rate=lr, step_size=1, gamma=0.99, verbose=True)optimizer = paddle.optimizer.Adam(learning_rate=scheduler,parameters=model.parameters())criterion = nn.MSELoss()train_dataset = SRDataset(train_path, crop_size, scaling_factor)test_dataset = SRDataset(test_path, crop_size, scaling_factor)train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=workers,)test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False,num_workers=workers,)for epoch in range(start_epoch, epochs+1):model.train() # 訓練模式:允許使用批樣本歸一化train_loss=0n_iter_train = len(train_loader)train_psnr=0# 按批處理for i, (lr_imgs, hr_imgs) in enumerate(train_loader):lr_imgs = lr_imgshr_imgs = hr_imgssr_imgs = model(lr_imgs)loss = criterion(sr_imgs, hr_imgs) optimizer.clear_grad()loss.backward()optimizer.step()train_loss+=loss.item()psnr = 10 * log10(1 / loss.item())train_psnr+=psnrepoch_loss_train=train_loss / n_iter_traintrain_psnr=train_psnr/n_iter_trainprint(f"Epoch {epoch}. Training loss: {epoch_loss_train} Train psnr {train_psnr}DB")model.eval() # 測試模式test_loss=0all_psnr = 0n_iter_test = len(test_loader)with paddle.no_grad():for i, (lr_imgs, hr_imgs) in enumerate(test_loader):lr_imgs = lr_imgshr_imgs = hr_imgssr_imgs = model(lr_imgs)loss = criterion(sr_imgs, hr_imgs)psnr = 10 * log10(1 / loss.item())all_psnr+=psnrtest_loss+=loss.item()epoch_loss_test=test_loss/n_iter_testepoch_psnr=all_psnr / n_iter_testprint(f"Epoch {epoch}. Testing loss: {epoch_loss_test} Test psnr{epoch_psnr} dB")if epoch_psnr>pre_psnr:paddle.jit.save(model, checkpoint,input_spec=[InputSpec(shape=[1,3,48,48], dtype='float32')])pre_psnr=epoch_psnrprint('模型更新成功')scheduler.step()測試,需要自己上傳一張低分辨率的圖片
import paddle
from paddle.vision import transforms
import PIL.Image as Image
import numpy as npimgO=Image.open('img_003_SRF_2_LR.png',mode="r") #選擇自己圖片的路徑
img=transforms.ToTensor()(imgO).unsqueeze(0)#導入模型
net=paddle.jit.load("./work/edsr_paddle")source = net(img)[0, :, :, :]
source = source.cpu().detach().numpy() # 轉為numpy
source = source.transpose((1, 2, 0)) # 切換形狀
source = np.clip(source, 0, 1) # 修正圖片
img = Image.fromarray(np.uint8(source * 255))plt.figure(figsize=(9,9))
plt.subplot(1, 2, 1)
plt.imshow(imgO)
plt.title('input')
plt.subplot(1, 2, 2)
plt.imshow(img)
plt.title('output')
plt.show()img.save('./sr.png')EDSR_X2效果
雙線性插值放大效果

?EDSR_X2放大效果

?雙線性插值放大效果

EDSR_X2放大效果

原文:?EDSR圖像超分重構




)
)


超級全)


:人工智能的歷史以及再探矩陣)



)
freeRTOS移植STMF103)


