序
本篇由來,在COC上我當面感謝了組委會和姜寧老師,隨即被姜寧老師催稿,本來當天晚上寫了一個流水賬,感覺甚為不妥。于是決定慢慢寫,緩緩道來。要同時兼顧Show me the code,Show me the vide。希望能形成一個從不同側面觀測我自己Community Over Code 2025參會心的,收獲的內容集合。
感覺這個系列正慢慢變成一場開發過程的圖文慢直播,肯能有助于大家一步一步的從零開始構建自己的Agent。
我定了一個番茄鐘,每天寫稿大概1~2個鐘,寫到哪兒算哪兒。
今天也對內容進行了調整把前略改成附錄了,頗有一種寫論文的感覺。
BTW,知乎我一般隔一天發。插曲可以TL;DR。
詞匯表
異人智能,我從KK和建忠老師的直播,個人筆記,了解到的詞匯,我很喜歡。大家請自行替換為大模型,Agent就好了。
許可證更新
GPT-OSS模型采用了Apache 2.0開源許可證,允許自由使用、修改和商業化,與Qwen3等模型類似。通過明確區分兩類模型(開放權重 vs. 完全開源),GPT-OSS選擇以Apache 2.0許可證提供高自由度,但未公開訓練細節。這一方案平衡了商業靈活性與技術透明度。用戶可自由將模型用于商業產品或蒸餾優化,無需法律限制,但需注意其技術黑箱性。Apache 2.0協議確保了低門檻的應用普及。
OpenAI發布了名為“GPT-OSS”的模型,并明確將其定義為開放權重模型(僅提供模型權重和推理代碼,不含訓練代碼或數據集)。
GPT-OSS的其他趣聞
訓練概覽
GPT-OSS模型是先進的AI模型,專注于STEM(科學、技術、工程、數學)、編程和通用知識。訓練使用了210萬H100 GPU小時的計算資源,其中GPT-OSS-20B模型的計算量約為其他模型的十分之一。
目前缺乏關于訓練數據集規模和具體算法的詳細信息,尤其是與其他模型(如DeepSeek V3和Qwen3)的比較數據不足。
通過監督微調和高計算強化學習階段優化模型,使其在英語文本任務中表現優異。盡管計算資源龐大,但GPT-OSS-20B的效率顯著更高。
GPT與DeepSeek模型的訓練差異
GPT模型的訓練時長估算同時包含監督學習(用于指令跟隨)和強化學習(用于推理),而DeepSeek V3僅為基礎預訓練模型,其后續的DeepSeek R1是單獨訓練的。
這種差異可能影響模型性能對比的公平性,因為GPT的訓練涵蓋更全面的優化階段,而DeepSeek V3的基礎模型未整合后續微調步驟。
DeepSeek選擇分階段訓練(先預訓練V3,再單獨訓練R1),而非像GPT一樣整合多階段訓練。這一方式可能提升模塊化靈活性,但需額外協調不同階段的優化目標。
分階段訓練允許更專注的模型優化(如V3專注通用能力,R1強化特定任務),同時降低單次訓練的算力壓力。但需權衡整體效率與最終性能的統一性。
GPT-OSS模型的推理能力控制
GPT-OSS模型是具備推理能力的AI模型,其特點是用戶可以通過調整推理時的參數(如“推理力度:低/中/高”)直接控制模型的響應長度和準確性。
傳統AI模型的推理能力通常是固定的,用戶無法靈活調整其輸出深度或細節程度,這限制了不同場景下的適用性。
通過引入“推理力度”指令,用戶可根據需求選擇低、中、高三種模式:
- 低力度:生成簡潔響應,適合快速問答。
- 中力度:平衡響應長度與準確性,適用于常規任務。
- 高力度:輸出更詳細的分析,適合復雜問題。
這一設計提升了模型的靈活性,讓用戶能按需優化效率(低力度節省時間)或精度(高力度增強可靠性),從而適應多樣化應用場景。
GPT-OSS的響應長度與質量研究
OpenAI發布了GPT開源模型的性能分析,重點研究了模型在不同推理努力(reasoning effort)下的響應長度與輸出質量的關系,相關數據標注于模型卡片中。
模型的響應長度和質量可能受推理計算量影響,若未優化這一關系,可能導致效率低下(如生成長文本但質量不穩定)或資源浪費(如過度計算短響應)。
通過調整模型的推理努力參數(如計算步數或注意力機制),實驗顯示:
- 結果:適當提升推理努力可平衡響應長度與質量,避免冗余或低效輸出。
- 益處:用戶能更高效地獲得符合需求的回答,同時節省計算資源。
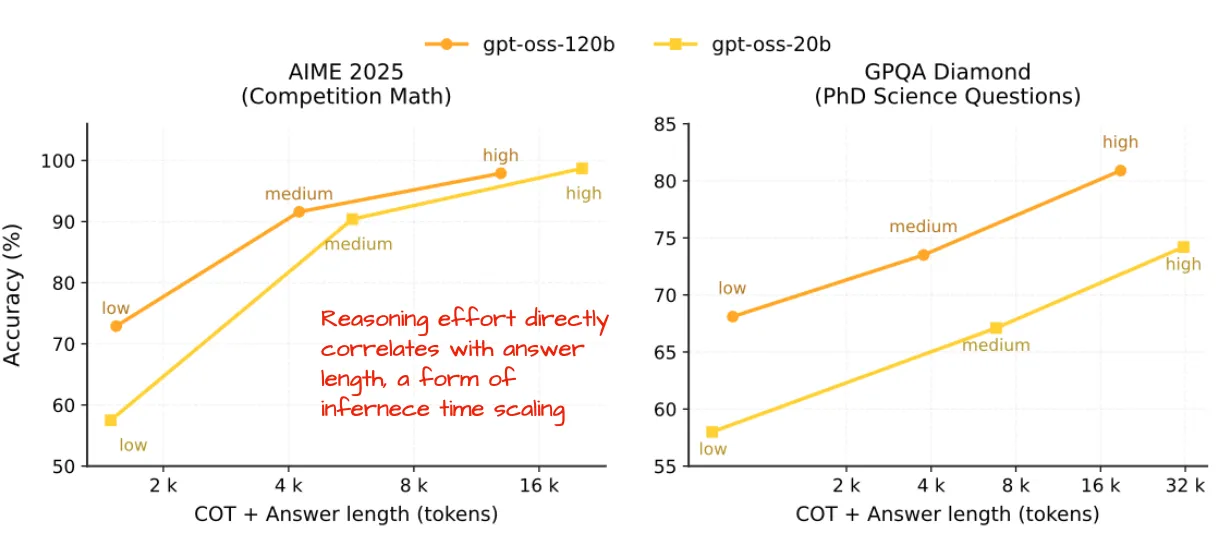
簡單任務(如回答基礎問題或修正小錯誤)若采用復雜推理,會浪費資源并導致冗長響應。通過動態調整推理層級,系統可跳過不必要的深度分析。
OpenAI未像Qwen3或OLMo那樣在強化學習訓練前公開基礎模型,而Qwen3團隊近期放棄了混合推理模式,改為單獨訓練不同功能的模型(如Instruct/Thinking/Coder)。
OpenAI的選擇可能更偏向工業和生產需求,而非研究用途;Qwen3的混合模式雖靈活(通過標簽切換推理行為),但性能低于獨立模型。
OpenAI推出MXFP4優化技術,提升大模型運行效率
OpenAI發布了采用MXFP4量化方案的gpt-oss模型,該技術專門針對混合專家(MoE)模型中的專家模塊進行優化。傳統量化技術主要用于移動端或嵌入式AI,但大模型(如120B參數規模)需要更高計算資源,通常依賴多GPU設備,導致成本高且部署復雜。MXFP4量化技術使大模型能在單塊高端GPU(如80GB顯存的H100或AMD MI300X)上運行。
優勢:
- 降低成本:無需多GPU設備,單卡即可部署,節省算力租賃費用。
- 簡化部署:避免跨GPU通信開銷,提升運行效率。
- 兼容性廣:支持最新硬件(如AMD MI300X),擴展應用場景。
舊顯卡無法支持MXFP4格式,導致模型運行效率低下,顯存需求激增,限制了普通用戶的使用。
4. 硬件升級:采用RTX 50系列及以上顯卡,啟用MXFP4優化,顯著降低顯存占用(20B模型僅需16GB)。
5. 兼容性取舍:舊硬件仍可運行,但需承受更高顯存消耗(如20B模型達48GB)。
評分與表現
目前,開源大模型(如Qwen3-Instruct)在LM Arena排行榜上表現領先,但新模型(如gpt-oss)尚未被納入評測。新模型因發布時間較短,缺乏獨立基準測試數據,導致公眾無法全面了解其實際性能。通過LM Arena等公開平臺持續追蹤模型表現,例如Qwen3-Instruct憑借用戶投票暫居榜首。
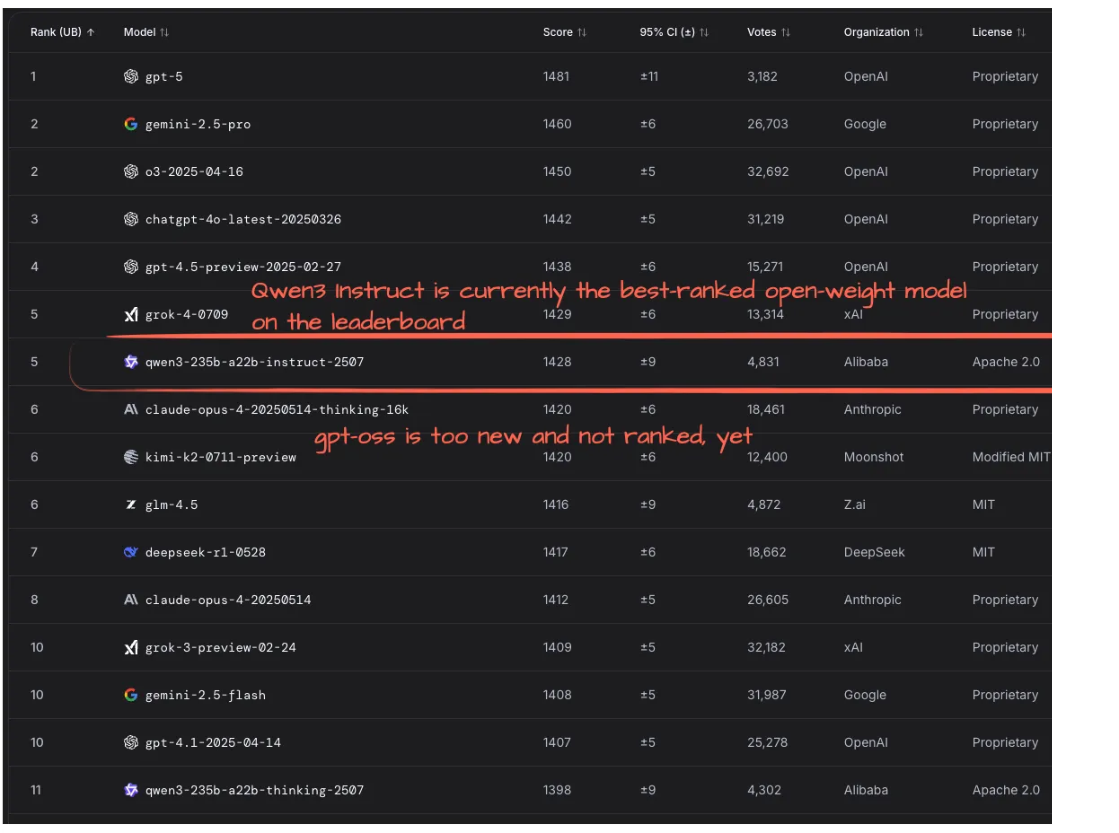
OpenAI發布了GPT-OSS模型的基準測試圖表(圖23),同時公開了未使用工具的GPT-OSS-120B數據(來自官方模型卡論文),而Qwen3的數據則來自其官方倉庫。這類基準測試旨在量化大語言模型的性能,但不同模型的測試數據和評估標準可能存在差異,導致直接比較的難度。
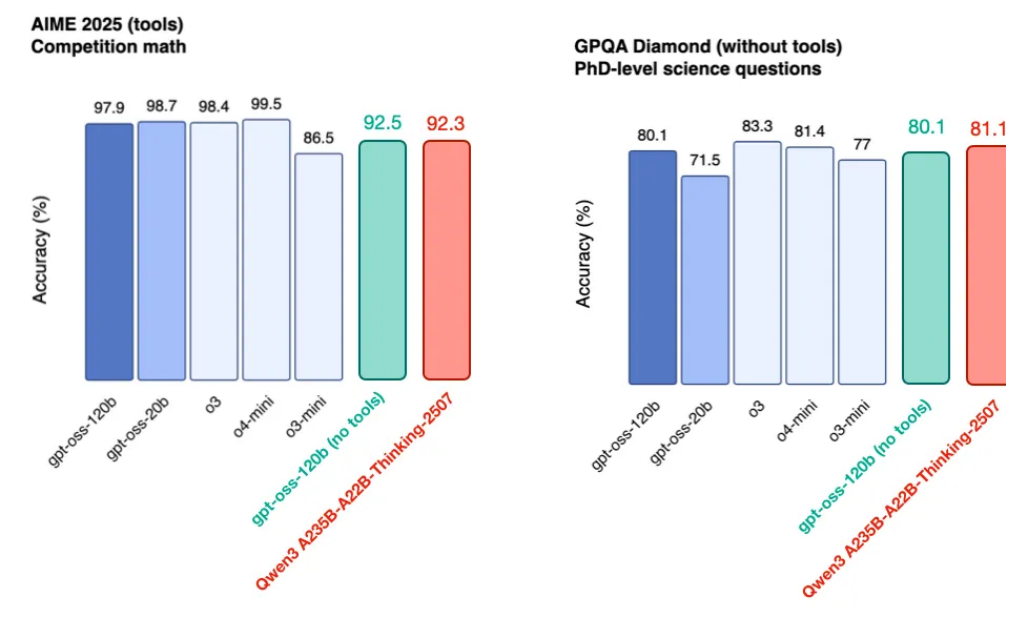
開源大模型GPT-OSS-120B的性能與挑戰
GPT-OSS-120B是一款開源大語言模型,體積僅為同行模型(如Qwen3 A235B-A22B-Thinking-2507)的一半,但能在單GPU上運行。測試顯示其性能接近甚至部分超越同類模型,尤其在數學、謎題和代碼等推理任務上表現突出。該模型存在較高的“幻覺”傾向(即生成不準確信息),可能因其訓練過度側重推理任務,導致通用知識遺忘。此外,開源大模型的工具集成技術仍處于早期階段,限制了實際應用場景。
模型發展應更注重推理能力而非記憶
隨著人工智能模型的成熟,未來可能更依賴外部資源(如搜索引擎)來回答事實性或知識性問題。當前模型過度依賴記憶而非推理能力,可能導致效率不足或靈活性受限,類似于人類教育中死記硬背的局限性。
解決方案與效果:
- 方案:優先提升模型的推理能力,而非單純記憶事實。
- 結果:模型能更高效地動態獲取信息,減少對靜態知識庫的依賴。
- 益處:
- 更貼近人類學習模式(注重解決問題而非記憶)。
- 增強應對復雜問題的靈活性,適應實時信息變化。
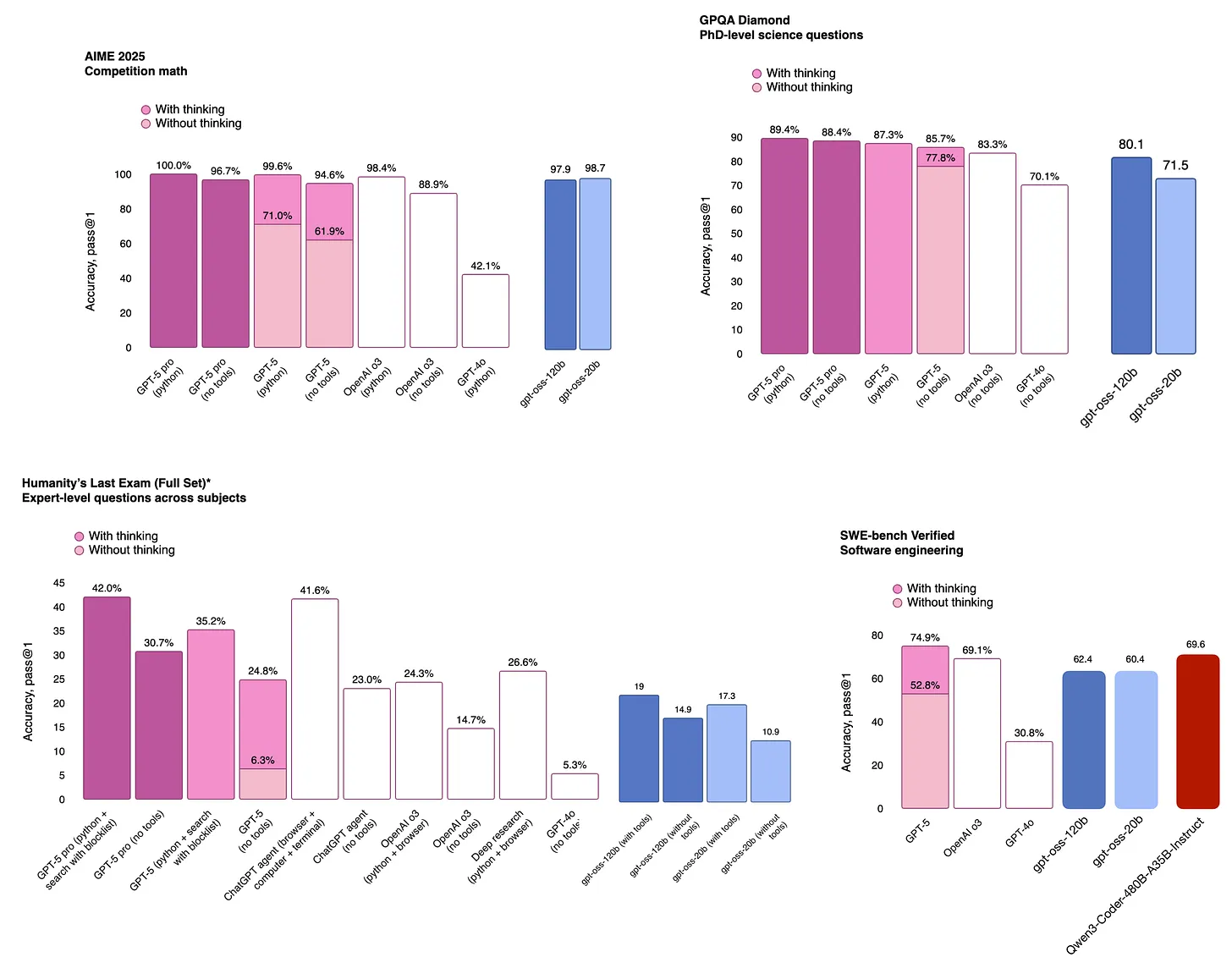
OpenAI發布GPT-5與開源模型表現對比
OpenAI近期發布了備受期待的GPT-5模型,緊隨其開源項目gpt-oss之后。值得注意的是,開源模型的基準性能表現(如圖24所示)與OpenAI的最新產品GPT-5相比,差距令人意外地小。這一現象引發疑問:為何開源模型的性能能夠接近商業旗艦產品?這可能反映了技術開源的潛力,或商業產品與開源項目在優化目標上的差異。OpenAI通過同時推進開源(gpt-oss)和商業產品(GPT-5)的策略,既促進了技術共享,又保持了競爭力。結果顯示,開源模型在基準測試中表現優異,甚至逼近GPT-5的水平。這一進展為開發者社區提供了高性能的開源工具,降低了技術門檻;同時,商業產品的持續迭代推動行業創新。用戶既能享受開源模型的低成本優勢,也能選擇更成熟的商業解決方案。
GPT-5與開源模型的性能對比分析
OpenAI發布了GPT-5的官方性能數據,同時開源模型gpt-oss和Qwen3-Coder也公布了基準測試結果。這些數據來自各方的官方公告和技術文檔。隨著大語言模型的快速發展,公眾需要清晰了解不同模型的性能差異,尤其是閉源商業模型(如GPT-5)與開源替代方案(如gpt-oss、Qwen3)的對比。通過整理官方發布的基準測試圖表(如GPT-5公告、gpt-oss模型卡、Qwen3-Coder倉庫數據),研究者可以橫向比較各模型的性能表現。
附錄
思考
Agent是作者個人或者團體的一些強烈的哲學表達
最近看到的提示詞相關內容匯總
基于數據驅動來寫提示詞(一)
Strands Agent實戰
Strands Agent 前文
Community Over Code 2025獲得的花絮(Strands Agent踩坑記錄,被AWS的speaker催更
)
基于Strands Agent開發輔助閱讀Agent
Agent從零開發
沒用langchain什么的腳手架,從DeepSeek官網的首次調用 API 開始,一步一步,面向DeepSeek開始對話的開發實戰記錄。
沒有Vibe Coding IDE, 學生可以從這個過程看底層一步一步怎么做的,為什么這么做。
如果想學習古法編程的朋友,可以一步一步從零自學。
理解原理,如果后續langchain全面收費的話,大家可以知道什么部分為什么這么設計,方便遷移。
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(一)
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(二)
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(三)
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(插曲篇)
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(五)
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(六)
是Conference還是Hackathon?Community Over Code 2025上踐行自己的哲學感悟(七)
![6-7 TIM編碼器接口 [江科協STM32]](http://pic.xiahunao.cn/6-7 TIM編碼器接口 [江科協STM32])


)



 Python + 地球信息科學與技術 = 經典案例分析)











