編者按:我們如何才能更好地控制大模型的輸出?
本文將介紹幾個關鍵參數,幫助讀者更好地理解和運用 temperature、top-p、top-k、frequency penalty 和 presence penalty 等常見參數,以優化語言模型的生成效果。
文章詳細解釋了這些參數的作用機制以及如何在質量與多樣性之間進行權衡。提高 temperature 可以增加多樣性但會降低質量。top-p 和 top-k 可以在不損失多樣性的前提下提高質量。frequency penalty 和 presence penalty 可以增加回復的詞匯多樣性和話題多樣性。
最后,文章提供了參數配置的具體建議和技巧,供讀者參考使用。選擇合適的參數能顯著提高語言模型的表現,更是進行 prompt engineering 的重要一環。
以下是譯文,enjoy!
作者 | Samuel Montgomery
編譯 | 岳揚
🚢🚢🚢歡迎小伙伴們加入AI技術軟件及技術交流群,追蹤前沿熱點,共探技術難題~
當我們通過 Playground 或 API 使用語言模型時,可能會被要求選擇一些推理參數。但是對大多數人來說,這些參數的含義(以及使用它們的正確方法)可能不為大多數人所熟悉。

典型模型推理界面參數選擇的截圖。圖片由作者提供
本文將介紹如何使用這些參數來控制大模型的幻覺(hallucinations),為模型的輸出注入創造力,并進行其他細粒度的調整,主要目的是為了優化模型的輸出。就像提示工程(prompt engineering)一樣,對推理參數進行調優可以使模型發揮出最佳效果。
通過學習本文,我相信各位讀者能夠充分理解這五個關鍵的推理參數——temperature、top-p、top-k、frequency penalty 和 presence penalty。還可以明白這些參數對生成內容的質量和多樣性產生的影響。
所以,泡好咖啡了嗎?現在開始吧!
目錄
01 背景信息 Background
02 質量、多樣性和Temperature
03 Top-k和Top-p
04 頻率懲罰和存在懲罰 Frequency and Presence Penalties
05 參數調整備忘單
06 總結
01 背景信息 Background
在選擇推理參數之前,我們需要了解一些背景信息。讓我們來談談這些模型是如何選擇要生成哪些單詞的。
要閱讀一份文檔,語言模型會將其分解為一系列的tokens。token只是模型能夠輕松理解的一小段文本:可以是一個單詞(word)、一個音節(syllable)或一個字符(character)。例如,“Megaputer Intelligence Inc.” 可以被分解為五個token:[“Mega”, “puter”, “Intelligence”, “Inc”, “.”]。
我們熟悉的大多數語言模型都是通過重復生成token序列(sequence)中的下一個token來運作的。每次模型想要生成另一個token時,會重新閱讀整個token序列并預測接下來應該出現的token。 這種策略被稱為自回歸生成(autoregressive generation)。
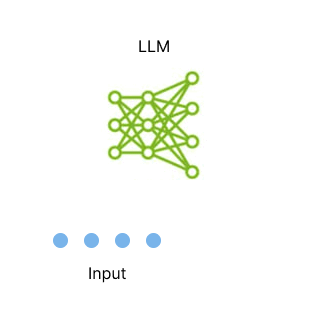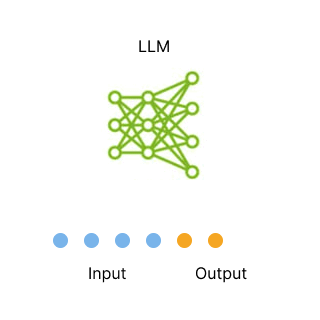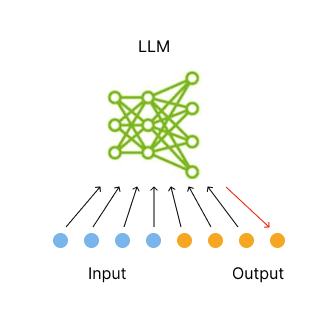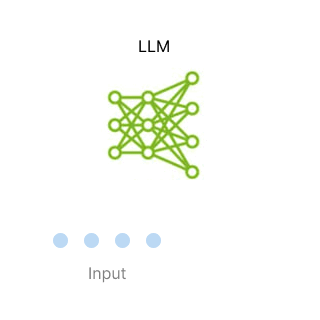
token的自回歸生成。
GIF由Echo Lu[1]制作,其中包含了 Annie Surla[2]的一張圖片(來自 NVIDIA[3],經過修改)。
本次修改已獲得版權所有者的許可。
這解釋了為什么ChatGPT會逐個地輸出單詞:它在生成內容時就以逐詞輸出的方式。
如果要選擇序列中的下一個token,語言模型首先要為其詞匯表中的每個token分配一個可能性分數(likelihood score)。經過模型的評估,如果某個token能夠讓文本得到合理的延續,就能夠獲得較高的可能性分數。如果某個token無法自然延續文本內容,就將獲得較低的可能性分數。
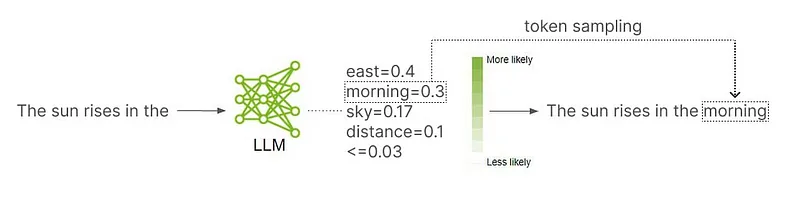
語言模型分配可能性分數,以預測序列中的下一個token。
原始圖片由 NVIDIA[3] 的 Annie Surla[2] 創建,經過版權所有者 Echo Lu[1] 的許可進行修改。
在分配完可能性分數(likelihood score)之后,就會使用一種將可能性分數考慮在內的token抽樣選擇方案(token sampling scheme)來選擇token。token抽樣選擇方案包含一定的隨機性,這樣語言模型就不會每次都以相同的方式回答相同的問題。這種隨機性可以成為聊天機器人或其他應用程序中的一個不錯的特性。
簡而言之:語言模型將文本分解為token,預測序列中的下一個token,并引入一些隨機性。根據需要重復這個過程,來輸出內容。
02 質量、多樣性和Temperature
但是,為什么我們會想要選擇第二好的token、第三好的token,或者除了最好的token以外的其他token呢?難道我們不希望每次都選擇最好的token(及具有最高可能性分數的token)嗎?通常情況下,我們確實會這樣進行。但是,如果我們每次都選擇生成最好的回復,那么我們每次都將得到相同的回復。如果我們想要得到多種多樣的回復,我們可能不得不放棄一些回復內容的質量來獲得回復的多樣性。這種為了多樣性而犧牲質量的做法被稱為質量與多樣性的權衡(quality-diversity tradeoff)。
在這種情況下,temperature這個參數可以告訴機器如何在質量和多樣性之間進行權衡。較低的 temperature 意味著更高的質量,而較高的 temperature 意味著更高的多樣性。當 temperature 設置為零時,模型總是會選擇具有最高可能性分數的token,從而導致模型生成的回復缺乏多樣性,但卻能確保總是選擇模型評估出的最高質量的token來生成回復。
很多時候,我們都希望將 temperature 設置為零。原則上,對于只需要向模型傳遞一次的任何提示語,都應該將 temperature 設置為零,因為這樣最有可能得到一個高質量的回復。在我進行的數據分析工作中,對于實體提取(entity extraction)、事實提取(fact extraction)、情感分析(sentiment analysis)和大多數其他標準任務都設置temperature 為零。
在較高的 temperature 下,通常會看到更多的垃圾內容和幻覺內容,連貫性較差,生成的回復質量可能會降低,但同時也會看到更多具有創造性和多樣性的回復。我們建議僅在需要獲得多個不同答案的情況下,才使用非零的 temperature。
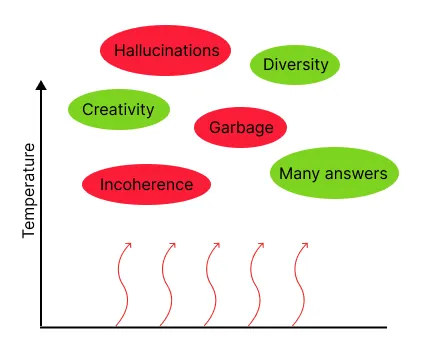
較高的 temperature 帶來了回答的多樣性和創造性,但也會增加垃圾內容、不連貫和幻覺。
圖片由Echo Lu[1]創建。
為什么我們會希望對同一個提示語(prompt)獲得兩個不同的回答呢?在某些情況下,對同一個提示語生成多個回復并僅保留最佳回復可能是比較好的。例如,有一種技術可以讓我們對一個提示語生成多個回復,并只保留最好的回復,這通常會比在 temperature 為零時的單個查詢產生更好的結果。另一個使用場景是生成人工合成的數據:我們會希望有許多不同的合成數據點(synthetic data points),而不僅是只有一個非常好的數據點(data point)。可能會在以后的文章中討論這種情況(以及其他情況),但更常見的情況是,我們只希望每個提示語有一個回復。當你不確定應該如何選擇 temperature 時,選擇 temperature 為零通常是一個安全的選擇。
需要注意的是,雖然理論上 temperature 為零應該每次產生相同的答案,但在實踐中可能并非如此! 這是因為模型運行在 GPU 上,可能容易出現微小的計算錯誤,例如四舍五入產生的誤差。即使在 temperature 為零的情況下,這些誤差會在計算中引入低水平的隨機性。由于更改文本中的一個token可能會大大改變文本的含義,一個微小的錯誤可能會導致文本后序的token選擇發生級聯變化,從而導致幾乎完全不同的輸出結果。但請放心,這通常對質量的影響微乎其微。我們提到這一點,只是以免讓你在 temperature 為零時輸出結果出現一些隨機性而感到驚訝。
有很多方法可以讓模型在質量和多樣性之間進行權衡,而不是僅受 temperature 的影響。在下一節中,我們將討論對 temperature 選擇技術的一些修改。但是,如果您對將 temperature 設置為 0 很滿意,可以暫時跳過這部分內容。在 temperature 為零時這些參數不會影響模型的回復,您可以放心地設置。
簡而言之:增加 temperature 可以增加模型輸出的隨機性,從而提高了回復的多樣性,但降低了質量。
03 Top-k和Top-p
一種常見的調整token選擇公式的方法稱為 top-k sampling 。top-k sampling 與普通的 temperature sampling 非常相似,只是排除了可能性最低的token:只考慮“前k個”最佳選擇,這也是該方法的名稱來源。這種方法的優點是防止我們選擇到真正糟糕的token。
例如,假設我們要補全 “The sun rises in the…(太陽升起在…)” 這個句子。那么,在沒有 top-k sampling 的情況下,模型會將詞匯表中的每個token都視為可以放置在序列之后的可能結果。然后,就會有一定的概率寫出一些荒謬的內容,比如“The sun rises in the refrigerator.(太陽升起在冰箱里)”。通過進行 top-k sampling ,模型會篩選這些真正糟糕的選擇,只考慮前k個最佳token。通過截斷大部分糟糕的token,我們會失去一些內容多樣性,但是內容的質量會大幅提高。
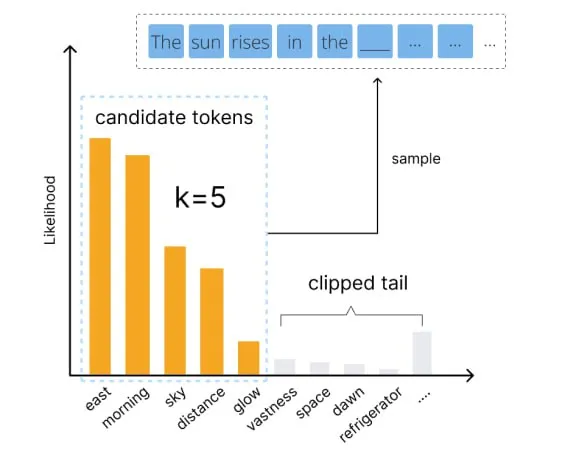
Top-k sampling 只保留 k 個最佳候選token,而丟棄其他token,從而提高內容質量。圖片由 Echo Lu 提供[1]。
top-p sampling是一種既能保證輸出內容多樣性,又能在保持內容質量的成本上比單純使用 temperature 更加低的方法。由于這種技術非常有效,因此激發了許多方法變體的出現。
有一種常見的 top-k sampling 變體被稱為 top-p sampling ,也被稱為 nucleus sampling 。top-p sampling 與 top-k sampling 非常相似,只是它使用可能性分數(likelihood scores)而不是token排名(token ranks)來決定應保留哪些token。更具體地說,它只考慮那些可能性分數超過閾值p的排名靠前的token,而將其余的token丟棄。
與 top-k sampling 相比,top-p sampling 的優勢在有許多較差或平庸的序列后續詞時就會顯現出來。 例如,假設下一個token只有幾個比較好的選擇,卻有幾十個只是隱約挨邊的選擇。如果我們使用 k=25 的 top-k sampling(譯者注:k代表的是保留的token數量) ,我們將考慮許多較差的token選擇。相比之下,如果我們使用 top-p sampling 來過濾掉概率分布中最底層的 10%(譯者注:將token的可能性概率從大到小排序,只保留從概率最大開始、累積概率之和達到90%為止的tokens),那么我們可能只需要考慮那些分數較高的token,同時過濾掉其他的token。
在實際應用中,與 top-k sampling 相比,top-p sampling 往往能夠獲得更好的效果。 它能夠更加適應輸入的上下文,并提供更靈活的篩選。因此,總的來說,top-p和top-k sampling 都可以在非零的 temperature 下使用,以較低的質量成本獲取輸出內容的多樣性,但 top-p sampling 通常效果更好。
小貼士: 對于這兩種設置(top-p和top-k sampling),數值越低表示過濾得越多。當設置值為零時,它們將過濾掉除排名靠前的token之外的所有token,這與將 temperature 設置為零具有相同的效果。因此,請在使用這些參數時注意,將這些參數設置得過低可能會減少模型輸出內容的多樣性。
簡而言之:top-k和top-p在幾乎不損失輸出內容多樣性的情況下提高了輸出內容的質量。它們通過在隨機抽樣前去除最差的token選擇來實現這一目的。
04 頻率懲罰和存在懲罰
Frequency and Presence Penalties
最后,讓我們來討論本文中的最后兩個參數:頻率懲罰和存在懲罰(frequency and presence penalties)。令人驚訝的是,這些參數是另一種讓模型在質量和多樣性之間進行權衡的方法。然而,temperature 參數通過在token選擇(token sampling)過程中添加隨機性來實現輸出內容的多樣性,而頻率懲罰和存在懲罰則通過對已在文本中出現的token施加懲罰以增加輸出內容的多樣性。這使得對舊的和過度使用的token進行選擇變得不太可能,從而讓模型選擇更新穎的token。
頻率懲罰(frequency penalty)讓token每次在文本中出現都受到懲罰。這可以阻止重復使用相同的token/單詞/短語,同時也會使模型討論的主題更加多樣化,更頻繁地更換主題。另一方面,存在懲罰(presence penalty)是一種固定的懲罰,如果一個token已經在文本中出現過,就會受到懲罰。這會導致模型引入更多新的token/單詞/短語,從而使其討論的主題更加多樣化,話題變化更加頻繁,而不會明顯抑制常用詞的重復。
就像 temperature 一樣,頻率懲罰和存在懲罰(frequency and presence penalties)會引導我們遠離“最佳的”可能回復,朝著更有創意的方向前進。 然而,它們不像 temperature 那樣通過引入隨機性,而是通過精心計算的針對性懲罰,為模型生成內容增添多樣性在一些罕見的、需要非零 temperature 的任務中(需要對同一個提示語給出多個答案時),可能還需要考慮將小的頻率懲罰或存在懲罰加入其中,以提高創造性。但是,對于只有一個正確答案且您希望一次性找到合理回復的提示語,當您將所有這些參數設為零時,成功的幾率就會最高。
一般來說,如果只存在一個正確答案,并且您只想問一次時,就應該將頻率懲罰和存在懲罰的數值設為零。但如果存在多個正確答案(比如在文本摘要中),在這些參數上就可以進行靈活處理。如果您發現模型的輸出乏味、缺乏創意、內容重復或內容范圍有限,謹慎地應用頻率懲罰或存在懲罰可能是一種激發活力的好方法。但對于這些參數的最終建議與 temperature 的建議相同:在不確定的情況下,將它們設置為零是一個最安全的選擇!
需要注意的是,盡管 temperature 和頻率懲罰/存在懲罰都能增加模型回復內容的多樣性,但它們所增加的多樣性并不相同。頻率懲罰/存在懲罰增加了單個回復內的多樣性,這意味著一個回復會包含比沒有這些懲罰時更多不同的詞語、短語、主題和話題。但當你兩次輸入相同的提示語時,并不意味著會更可能得到兩個不同的答案。這與 temperature 不同, temperature 增加了不同查詢下回復的差異性:在較高的 temperature 下,當多次輸入相同的提示語給模型時,會得到更多不同的回復。
我喜歡將這種區別稱為回復內多樣性(within-response diversity)與回復間多樣性(between-response diversity)。temperature 參數同時增加了回復內和回復間的多樣性,而頻率懲罰/存在懲罰只增加了回復內的多樣性。因此,當我們需要增加回復內容的多樣性時,參數的選擇應取決于我們需要增加哪種多樣性。
簡而言之:頻率懲罰和存在懲罰增加了模型所討論主題的多樣性,并使模型能夠更頻繁地更換話題。頻率懲罰還可以通過減少詞語和短語的重復來增加詞語選擇的多樣性。
05 參數調整備忘單
本節旨在為選擇模型推理參數提供一份實用指南。首先,該節會提供一些明確的規則,決定將哪些值設為零。然后,會提供了一些tips,幫助讀者找到當參數應當為非零時的正確值。
強烈建議您在選擇推理參數時使用這張備忘單。現在就將此頁面保存為書簽,或者收藏本文章~ 以免丟失!
將參數設為零的規則:
temperature:
- 對于每個提示語只需要單個答案:零。
- 對于每個提示語需要多個答案:非零。
頻率懲罰和存在懲罰:
- 當問題僅存在一個正確答案時:零。
- 當問題存在多個正確答案時:可自由選擇。
Top-p/Top-k:
- 在 temperature 為零的情況下:輸出不受影響。
- 在 temperature 不為零的情況下:非零。
如果您使用的語言模型具有此處未列出的其他參數,將其保留為默認值始終是可以的。
當參數非0時,參數調整的技巧:
先列出那些應該設置為非零值的參數,然后去 playground 嘗試一些用于測試的提示語,看看哪些效果好。但是,如果上述規則說要將參數值保持為零,則應當將其保持為零!
調整temperature/top-p/top-k的技巧:
- 為了使模型輸入內容擁有更多的多樣性或隨機性,應當增加temperature。
- 在 temperature 非零的情況下,從 0.95 左右的 top-p(或 250 左右的 top-k )開始,根據需要降低 temperature。
Troubleshooting:
- 如果有太多無意義的內容、垃圾內容或產生幻覺,應當降低 temperature 和 降低top-p/top-k。
- 如果 temperature 很高而模型輸出內容的多樣性卻很低,應當增加top-p/top-k。
Tip:雖然有些模型能夠讓我們同時調整 top-p 和 top-k ,但我更傾向于只調整其中一個參數。top-k 更容易使用和理解,但 top-p 通常更有效。
調整頻率懲罰和存在懲罰的技巧:
- 為了獲得更多樣化的主題,應當增加存在懲罰值。
- 為了獲得更多樣化且更少重復內容的模型輸出,應當增加頻率懲罰。
Troubleshooting:
- 如果模型輸出的內容看起來零散并且話題變化太快,應當降低存在懲罰。
- 如果有太多新奇和不尋常的詞語,或者存在懲罰設置為零但仍然存在很多話題變化,應當降低頻率懲罰。
簡而言之:可以將本節作為調整語言模型參數的備忘單。您肯定會忘記這些規則,所以立即將此頁面加為瀏覽器書簽或加入社區收藏夾,以便以后作為參考。
06 總結
盡管定義token選擇策略(token sampling strategy)的方式多種多樣,但本文討論的參數——temperature、top-k、top-p、頻率懲罰和存在懲罰——是最為常用的。這些參數在諸如 Claude、Llama 和 GPT 系列等模型中被廣泛采用。在本文中,已經說明了,這些參數實際上都是為了幫助我們在模型輸出的質量和多樣性之間取得平衡。
在結束之前,還有一個推理參數需要提及:最大token長度(maximum token length)。最大token長度即為模型停止輸出回復的截止點,即使模型的回復尚未完成。在經歷了前文對其他參數進行復雜的討論后,我希望對這個參數的介紹不言自明。🙂
簡而言之:如果對參數的設置有疑問,將temperature、頻率懲罰和存在懲罰這些參數的數值設為零。若不起作用,請參考上述速查表。
END
參考資料
[1]https://www.linkedin.com/in/echoxlu/
[2]https://developer.nvidia.com/blog/author/anniesurla/
[3]https://developer.nvidia.com/blog/how-to-get-better-outputs-from-your-large-language-model/
本文經原作者授權,由Baihai IDP編譯。如需轉載譯文,請聯系獲取授權。
原文鏈接:
https://towardsdatascience.com/mastering-language-models-32e1d891511a
)














)
)


