雪花算法原理(設計原理、優缺點、如何改造它、以及應用)
- 雪花算法源碼
- 為什么雪花算法是 64 位?
- 為什么時間戳是41位?占雪花算法的 43-47 bit 位
- 為什么工作臺最大只支持設置 31 ?
- 工作臺設置成了 63 會導致什么后果?
- 同機器位只支持最大 5 bit位
- 同理數據累加位只支持最大 12 bit位
- 雪花算法優點
- 雪花算法缺點
- 雪花算法改造
- 小咸魚的技術窩
雪花算法源碼
雪花算法是一個開源的分布式生成唯一自增 Id 的這么一個工具類。主要的源碼如下
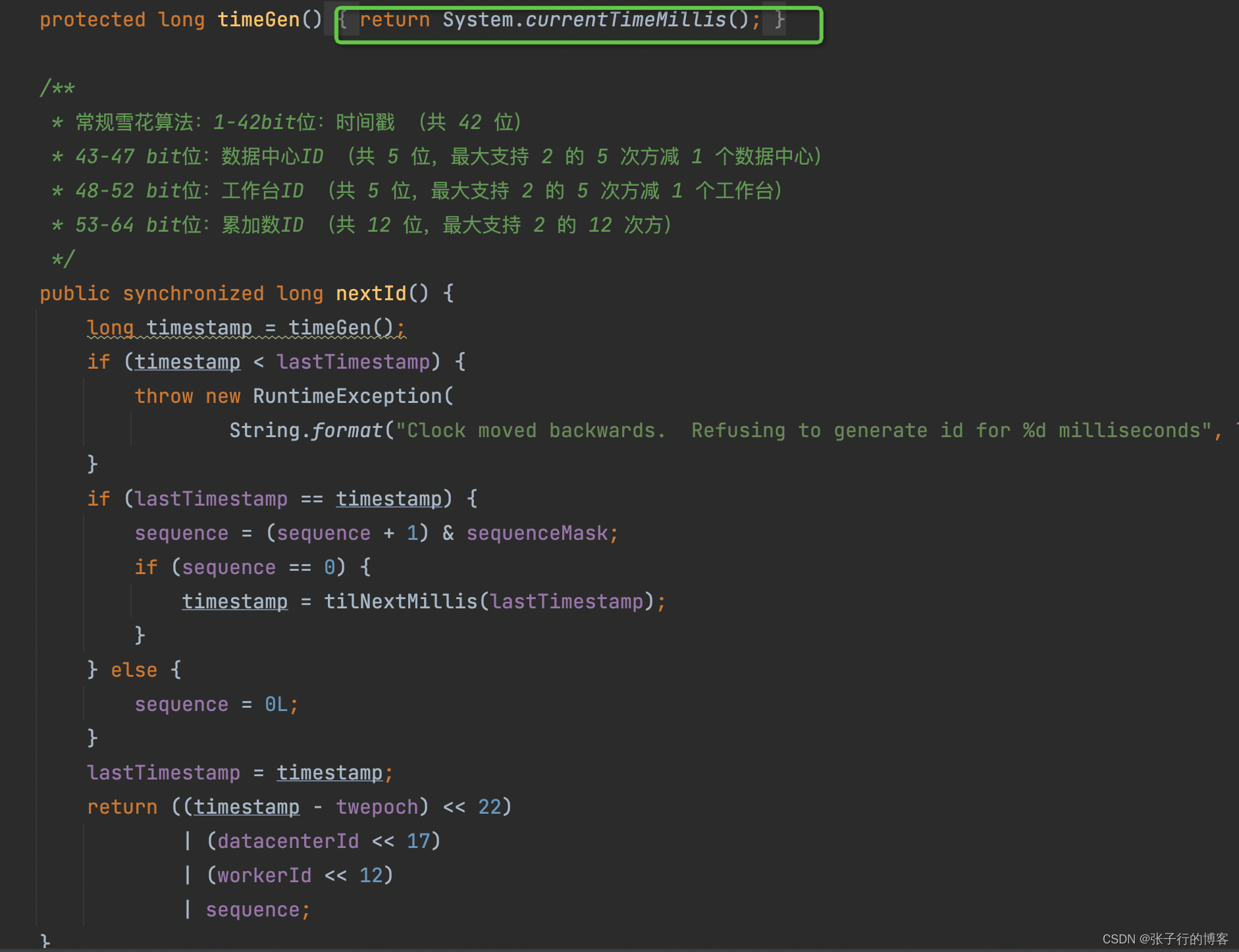
/*** 常規雪花算法:1-42bit位:時間戳 (共 42 位)* 43-47 bit位:數據中心ID (共 5 位,最大支持 2 的 5 次方減 1 個數據中心)* 48-52 bit位:工作臺ID (共 5 位,最大支持 2 的 5 次方減 1 個工作臺)* 53-64 bit位:累加數ID (共 12 位,最大支持 2 的 12 次方)*/
public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - twepoch) << 22)| (datacenterId << 17)| (workerId << 12)| sequence;
}
都知道雪花算法結構如下,不知道讀者有沒有想過 為什么雪花算法是 64 位的?為什么工作機器最大為 5 位?,反正我第一次接觸雪花算法的時候,就想過這些問題。
- 1-42bit位:時間戳 (共 42 位)
- 43-47 bit位:數據中心ID (共 5 位,最大支持 2 的 5 次方減 1 個數據中心)
- 48-52 bit位:工作臺ID (共 5 位,最大支持 2 的 5 次方減 1 個工作臺)
- 53-64 bit位:累加數ID (共 12 位,最大支持 2 的 12 次方)

為什么雪花算法是 64 位?
因為雪花算法返回的是一個 long 類型的值,換算成二進制就是最大 64 位!
為什么時間戳是41位?占雪花算法的 43-47 bit 位
隨便一個時間戳轉換成二進制就是 41 位
log.info("時間戳:{} 位", Long.toBinaryString(System.currentTimeMillis()).length());

且雪花算法中的時間戳左移了 22 位,加上時間戳本身的 41 位,加起來就有 63 位了,加上第一位的符號位,就是 64 位,正好等于 long 類型的 64 位。完美利用 long 類型。
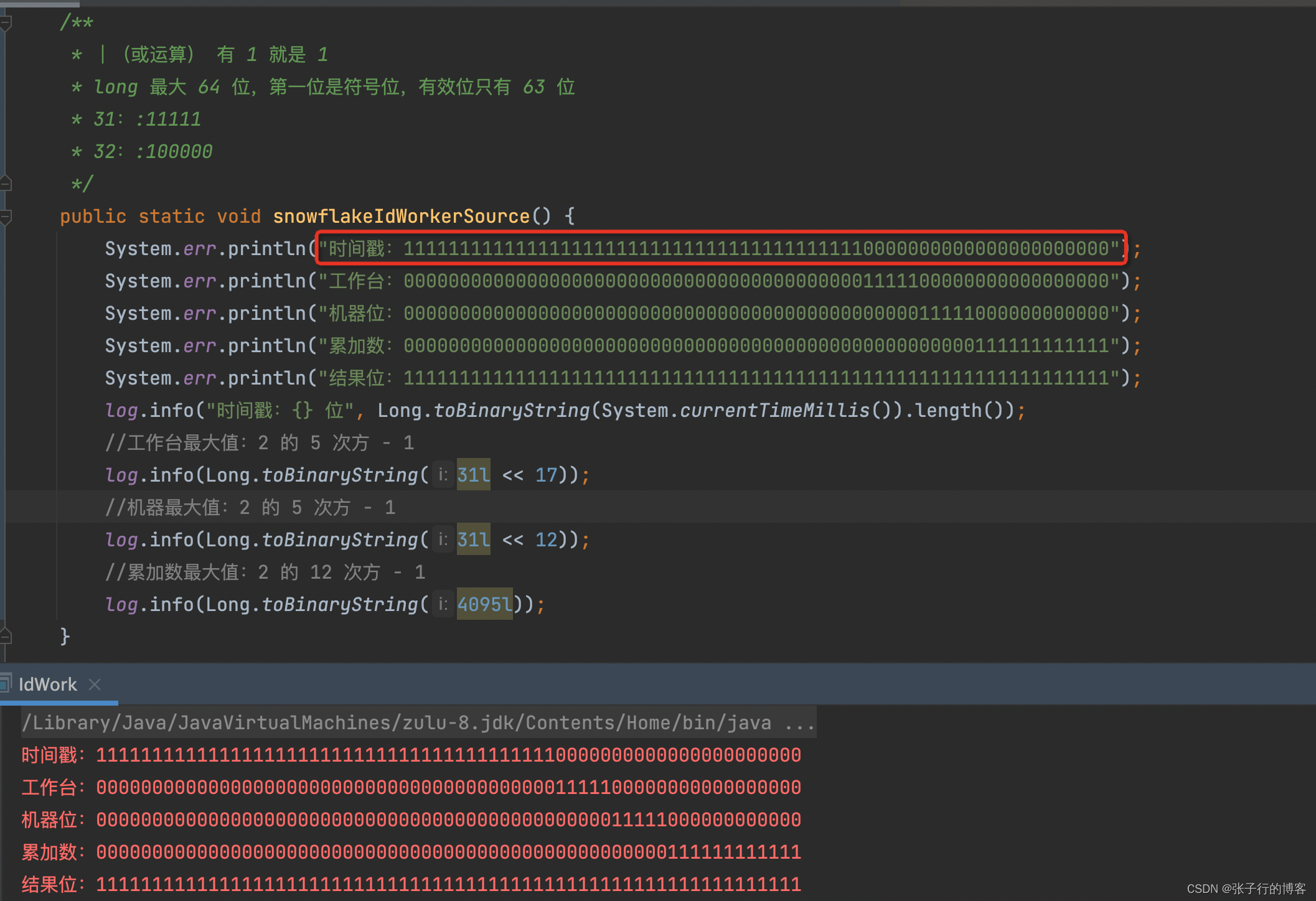
為什么工作臺最大只支持設置 31 ?
時間戳達到了最大值,41 位時間戳 bit 位全是 1,留了后 22 位全是 0,由于或運算,運算位有 1 就是 1,所以說這個 22 位算是留給累加數、工作臺、數據中心的有效左移位,超過這個有效左移位,就會出現生成重復 id 的情況出現。
111111111111111111111111111111111111111110000000000000000000000
工作臺達到最大值 31(31換二進制為11111),左移22位后,會得到如下一個二進制數(位數不足63位,前面用0補齊)
000000000000000000000000000000000000000001111100000000000000000
最終得到的運算結果就是這個
111111111111111111111111111111111111111111111100000000000000000

工作臺設置成了 63 會導致什么后果?
63對應的二進制是 6個1(111111),參與的運算結果和工作臺設置成31得到的結果一樣,就有產生的重復 id 的風險了。因此這也是工作臺最大只支持 5 bit 位的原因

同機器位只支持最大 5 bit位
在時間戳、工作臺按最大值運算后,留給數據中心的有效運算位只有 17 位了,然后數據中心又左移了12 位,留給數據中心的參與運算的bit就只有5位了(17-12=5)。同理如果數據中心設置成63,也會有生成重復id的風險出現

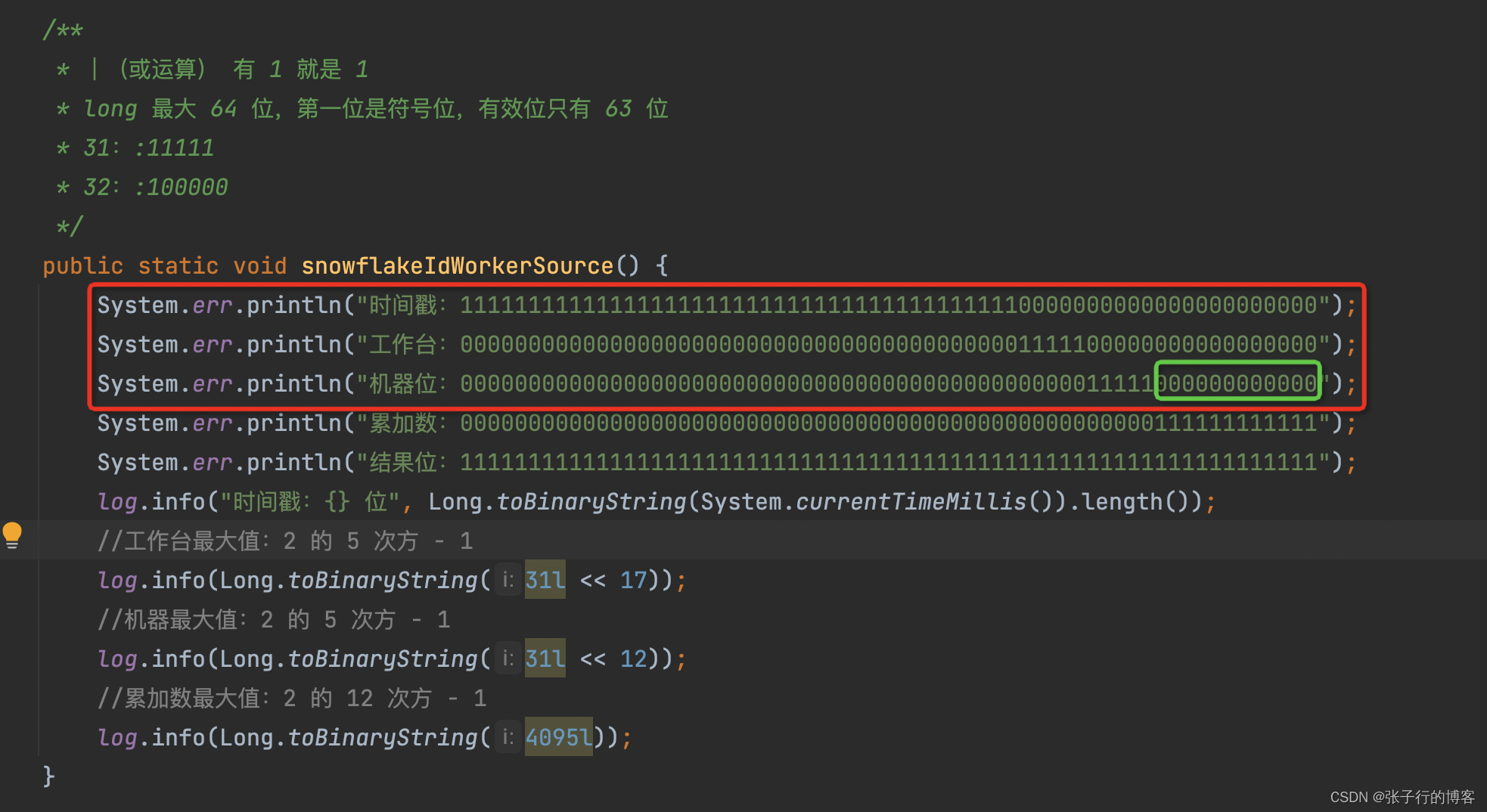
同理數據累加位只支持最大 12 bit位
在時間戳、機器位、工作臺按最大值左移后,留給累加數的有效位只有12bit位了(63-41-5-5=12),看我下圖圈綠的地方這個就是有效bit位。
雪花算法優點
按照官方來說就是:
不需要搭建服務集群,代碼邏輯非常簡單,同一毫秒內,訂單ID的序列號自增。同步鎖只作用于本機,機器之間互不影響,每毫秒可以生成4百萬個訂單ID
對比Mysql自增主鍵:
一般雪花算法用于生成訂單ID,相比于 Mysql 自增主鍵來說,Mysql 自增ID是不是很容易看出你的銷量,做個差值計算就好了
對比UUID
UUID是無序的,訂單ID都加索引,在你插入數據的時候,維護B+樹很好性能,需要頻繁的調整葉子結點的數據,還會導致頁分裂。簡而言之就是性能不高,而雪花算法性能高低延遲
雪花算法缺點
由于時間戳占生成id的41 bit位,且這個時間戳是根據服務器時間生成的,一旦服務器時間回撥了一下,你就嗝屁了,可能會生成重復的 id
雪花算法改造
基于基因法改造案例如下,詳情點擊跳轉 一文搞懂分庫分表算法,通俗易懂(基因法、一致性 hash、時間維度)
//41 bit 位時間戳,5 bit 位數據中心,5 bit 機器位,5 bit累加位,7 bit 用戶基因位long orderId = ((timestamp - twepoch) << 22)| (datacenterId << 17)| (workerId << 12)| (sequence << 7)| uid;
小咸魚的技術窩
關注不迷路,分享更多技術干貨B站、CSDN、微信公眾號都是(小咸魚的技術窩),更多詳情在主頁
















——第4期)



解決方法)