目錄
一. 前言
二. final 的基礎使用
2.1. 修飾類
2.2. 修飾方法
2.2.1.?private 方法是隱式的 final
2.2.2.?final 方法可以被重載
2.3. 修飾參數
2.4. 修飾變量
2.4.1. static final
2.4.2. blank final
2.4.3.?所有?final 修飾的字段都是編譯期常量嗎?
三.?final 域重排序規則
3.1.?final 域為基本類型
3.1.1.?寫 final 域重排序規則
3.1.2.?讀 final 域重排序規則
3.2.?final 域為引用類型
3.2.1.?對 final 修飾的對象的成員域寫操作
3.2.2.?對 final 修飾的對象的成員域讀操作
3.3.?final 重排序的總結
四. final 再深入理解
4.1.?final 的實現原理
4.2.?為什么 final 引用不能從構造函數中“溢出”
4.3.?使用 final 的限制條件和局限性
一. 前言
? ? 在Java中,final 表示“最終的、不可改變的、完結的”,它也是一種修飾符,可以修飾變量、方法和類。final 修飾變量、方法和類時的意義是不同的,但本質是一樣的,都表示不可改變,類似 C#里的 sealed 關鍵字。final 修飾的變量叫做最終變量,也就是常量,修飾的方法叫做最終方法,修飾的類叫做最終類。
二. final 的基礎使用
2.1. 修飾類
? ? 當某個類的整體定義為 final 時,就表明了你不打算繼承該類,而且也不允許別人這么做。即這個類是不能有子類的。
注意:final 類中的所有方法都隱式為 final,因為無法覆蓋他們,所以在 final 類中給任何方法添加final 關鍵字是沒有任何意義的。
這里順道說說 final 類型的類如何拓展?比如 String 是 final 類型,我們想寫個 MyString 復用所有String 中方法,同時增加一個新的 toMyString() 的方法,應該如何做?
設計模式中最重要的兩種關系,一種是繼承/實現;另外一種是組合關系。所以當遇到不能用繼承的(final修飾的類),應該考慮用組合,如下代碼大概寫個組合實現的意思:
/**
* 流華追夢
*/
class MyString {private String innerString;// ...init & other methods// 支持老的方法public int length() {return innerString.length(); // 通過innerString調用老的方法}// 添加新方法public String toMyString() {// ...}
}2.2. 修飾方法
? ? 被 final 修飾的方法稱為常量方法,該方法可以被重載,也可以被子類繼承,但卻不能被重寫。當一個方法的功能已經可以滿足當前要求,不需要進行擴展,我們就不用任何子類來重寫該方法,防止該方法的內容被修改。比如 Object 類中,就有一個 final 修飾的 getClass() 方法,Object 的任何子類都不能重寫這個方法。
2.2.1.?private 方法是隱式的 final
類中所有 private 方法都隱式地指定為 final,由于無法取用 private 方法,所以也就不能覆蓋它。可以對 private 方法增添 final 關鍵字,但這樣做并沒有什么好處。看下下面的例子:
public class Base {private void test() {}
}public class Son extends Base {public void test() {}public static void main(String[] args) {Son son = new Son();Base father = son;// father.test();}
}? ? Base 和 Son 都有方法 test(),但是這并不是一種覆蓋,因為 private 所修飾的方法是隱式的final,也就是無法被繼承,所以更不用說是覆蓋了,在Son中的 test() 方法不過是屬于Son的新成員罷了,Son 進行向上轉型得到 father,但是 father.test() 是不可執行的,因為Base中的 test 方法是 private 的,無法被訪問到。
2.2.2.?final 方法可以被重載
我們知道父類的 final 方法是不能夠被子類重寫的,那么final方法可以被重載嗎?答案是可以的,下面代碼是正確的:
public class FinalExampleParent {public final void test() {}public final void test(String str) {}
}2.3. 修飾參數
在方法參數前面加 final 關鍵字就是為了防止數據在方法體中被修改。
主要分兩種情況:第一,用 final 修飾基本數據類型;第二,用 final 修飾引用類型。
第一種情況,修飾基本類型(非引用類型)。這時參數的值在方法體內是不能被修改的,即不能被重新賦值。否則編譯就通不過。
第二種情況,修飾引用類型。這時參數變量所引用的對象是不能被改變的。作為引用的拷貝,參數在方法體里面不能再引用新的對象。否則編譯通不過。
但是對于引用,如果只是修改引用對象成員的值,則不會報任何錯,完全能編譯通過。如下代碼:
public static void valid(final String[] args) {args[0] = "5";System.out.println(args);
}2.4. 修飾變量
? ? 被 final 修飾的變量一旦被賦值初始化后,就不能再被重新賦值。即變量值只能被賦值一次,不可被反復修改,所以叫做最終變量,也叫做常量。
? ? 并且我們在定義 final 變量時,必須顯式地進行初始化,指定初始值,否則會出現“The blank final field xxx may not have been initialized”的異常提示。變量值的初始化,可以在兩個地方:一是在變量定義處,即在 final 變量定義時直接給其賦值;二是在構造方法或靜態代碼塊中。這些地方只能選其一,不能同時既在定義時賦值,又在構造方法或靜態代碼塊中另外賦值。
我們在開發時,通常會把 final 修飾符和 static 修飾符一起使用,來創建類的常量。
根據修飾變量的作用范圍,比如在修飾局部變量和成員變量時,final 會有不同的特性:
1. final 修飾局部變量時,在使用之前必須被賦值一次才能使用;
2. final 修飾成員變量時,如果在聲明時沒有賦值,則叫做“空白 final 變量”,空白 final 變量必須在構造方法或靜態代碼塊中進行初始化。
根據修飾變量的數據類型,比如在修飾基本類型和引用類型的變量時,final 也有不同的特性:
1. final修飾基本類型的變量時,不能把基本類型的值重新賦值,因此基本類型的變量值不能被改變。
2. final修飾引用類型的變量時,final 只會保證引用類型的變量所引用的地址不會改變,即保證該變量會一直引用同一個對象。因為引用類型的變量保存的僅僅是一個引用地址,所以 final 修飾引用類型的變量時,該變量會一直引用同一個對象,但這個對象本身的成員和數據是完全可以發生改變的。
2.4.1. static final
一個既是 static 又是 final 的字段只占據一段不能改變的存儲空間,它必須在定義的時候進行賦值,否則編譯器將不予通過。
import java.util.Random;public class Test {static Random r = new Random();final int k = r.nextInt(10);static final int k2 = r.nextInt(10); public static void main(String[] args) {Test t1 = new Test();System.out.println("k=" + t1.k + " k2=" + t1.k2);Test t2 = new Test();System.out.println("k=" + t2.k + " k2=" + t2.k2);}
}// 運行結果:k=2 k2=7
k=8 k2=7我們可以發現對于不同的對象,k 的值是不同的,但是 k2 的值卻是相同的,這是為什么呢?因為static 關鍵字所修飾的字段并不屬于一個對象,而是屬于這個類的。也可簡單的理解為 static final所修飾的字段僅占據內存的一份空間,一旦被初始化之后便不會被更改。
2.4.2. blank final
? ? Java 允許生成空白 final,也就是說被聲明為 final 但又沒有給出定值的字段,但是必須在該字段被使用之前被賦值,這增強了final的靈活性。我們有兩種選擇:
1. 在定義處進行賦值(這不叫空白final);
2. 在構造器中進行賦值,保證了該值在被使用前賦值。
public class Test {final int i1 = 1;final int i2; // 空白finalpublic Test() {i2 = 1;}public Test(int x) {this.i2 = x;}
}可以看到 i2 的賦值更為靈活。但是請注意,如果字段由 static 和 final 修飾,僅能在聲明時賦值或聲明后在靜態代碼塊中賦值,因為該字段不屬于對象,屬于這個類。
2.4.3.?所有?final 修飾的字段都是編譯期常量嗎?
現在來看編譯期常量和非編譯期常量,如:
public class Test {// 編譯期常量final int i = 1;final static int J = 1;final int[] a = { 1,2,3,4 };// 非編譯期常量Random r = new Random();final int k = r.nextInt();public static void main(String[] args) {}
}k 的值由隨機數對象決定,所以不是所有?final 修飾的字段都是編譯期常量,只是 k 的值在被初始化后無法被更改。?
三.?final 域重排序規則
? ? 上面我們聊的 final 使用,是屬于 Java 基礎層面的,當理解這些后我們就真的算是掌握了 final嗎?有考慮過 final 在多線程并發的情況嗎?在 Java 內存模型中,我們知道 Java 內存模型為了能讓處理器和編譯器底層發揮他們的最大優勢,對底層的約束就很少,也就是說針對底層來說 Java 內存模型就是一弱內存數據模型。同時,處理器和編譯器為了性能優化,會對指令序列有編譯器和處理器重排序。那么,在多線程情況下,final 會進行怎樣的重排序?會導致線程安全的問題嗎?下面,就來看看 final 的重排序。
3.1.?final 域為基本類型
看下面這段示例性代碼,假設線程A 在執行 writer() 方法,線程B 執行 reader() 方法:
public class FinalDemo {private int a; // 普通域private final int b; // final域private static FinalDemo finalDemo;public FinalDemo() {a = 1; // 1.寫普通域b = 2; // 2.寫final域}public static void writer() {finalDemo = new FinalDemo();}public static void reader() {FinalDemo demo = finalDemo; // 3.讀對象引用int a = demo.a; // 4.讀普通域int b = demo.b; // 5.讀final域}
}3.1.1.?寫 final 域重排序規則
? ? 寫 final 域的重排序規則禁止對 final 域的寫重排序到構造函數之外,這個規則的實現主要包含了兩個方面:
1. JMM 禁止編譯器把 final 域的寫重排序到構造函數之外;
2. 編譯器會在 final 域寫之后,構造函數 return 之前,插入一個 StoreStore 屏障。這個屏障可以禁止處理器把 final 域的寫重排序到構造函數之外。
我們再來分析 writer 方法,雖然只有一行代碼,但實際上做了兩件事情:
1. 構造了一個FinalDemo對象;
2. 把這個對象賦值給成員變量 finalDemo。
我們來畫下存在的一種可能執行時序圖,如下:

由于 a、b 之間沒有數據依賴性,普通域(普通變量)a 可能會被重排序到構造函數之外,線程B就有可能讀到的是普通變量a 初始化之前的值(零值),這樣就可能出現錯誤。而 final 域變量b,根據重排序規則,會禁止 final 修飾的變量b 重排序到構造函數之外,從而變量b 能夠正確賦值,線程B 就能夠讀到 final 變量初始化后的值。?
因此,寫 final 域的重排序規則可以確保:在對象引用為任意線程可見之前,對象的 final 域已經被正確初始化過了,而普通域就不具有這個保障。比如在上例,線程B 有可能就是一個未正確初始化的對象 finalDemo。
3.1.2.?讀 final 域重排序規則
? ? 讀 final 域重排序規則為:在一個線程中,初次讀對象引用和初次讀該對象包含的 final 域,JMM會禁止這兩個操作的重排序。(注意,這個規則僅僅是針對處理器),處理器會在讀 final 域操作的前面插入一個 LoadLoad屏障。實際上,讀對象的引用和讀該對象的 final 域存在間接依賴性,一般處理器不會重排序這兩個操作。但是有一些處理器會重排序,因此,這條禁止重排序規則就是針對這些處理器而設定的。
read() 方法主要包含了三個操作:
1. 初次讀引用變量 finalDemo;
2. 初次讀引用變量 finalDemo 的普通域 a;
3. 初次讀引用變量 finalDemo 的 final 域 b。
假設線程A 寫過程沒有重排序,那么線程A 和線程B 有一種的可能執行時序為下圖:
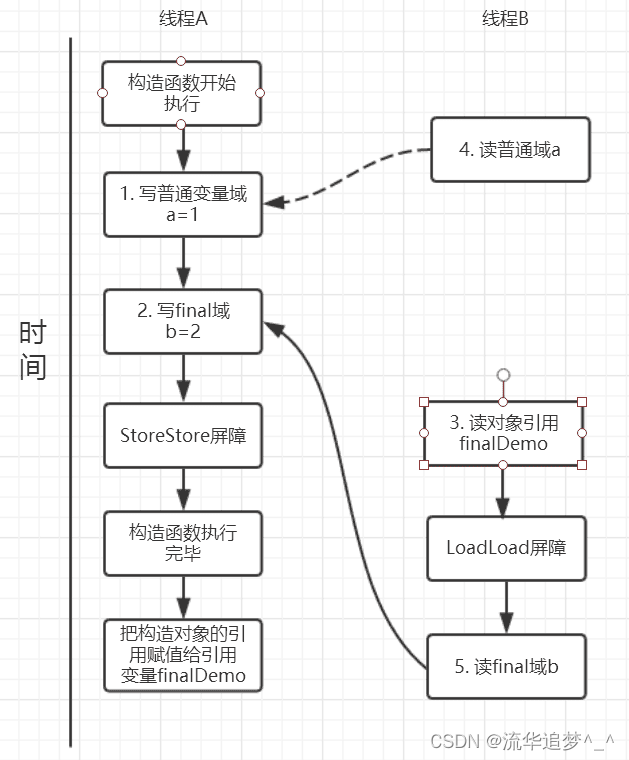
讀對象的普通域被重排序到了讀對象引用的前面,就會出現線程B 還未讀到對象引用就在讀取該對象的普通域變量,這顯然是錯誤的操作。而 final 域的讀操作就“限定”了在讀 final 域變量前已經讀到了該對象的引用,從而就可以避免這種情況。?
讀 final 域的重排序規則可以確保:在讀一個對象的 final 域之前,一定會先讀包含這個 final 域的對象的引用。
3.2.?final 域為引用類型
? ? 我們已經知道了 final 域是基本數據類型的時候重排序規則是怎么樣的了?如果是引用數據類型呢? 我們接著繼續來探討。
3.2.1.?對 final 修飾的對象的成員域寫操作
? ? 針對引用數據類型,final 域寫針對編譯器和處理器重排序增加了這樣的約束:在構造函數內對一個 final 修飾的對象的成員域的寫入,與隨后在構造函數之外把這個被構造的對象的引用賦給一個引用變量,這兩個操作是不能被重排序的。注意這里的是“增加”,也就說前面對 final 基本數據類型的重排序規則在這里還是使用。這句話是比較拗口的,下面結合實例來看:
public class FinalReferenceDemo {final int[] arrays;private FinalReferenceDemo finalReferenceDemo;public FinalReferenceDemo() {arrays = new int[1]; // 1arrays[0] = 1; // 2}public void writerOne() {finalReferenceDemo = new FinalReferenceDemo(); // 3}public void writerTwo() {arrays[0] = 2; // 4}public void reader() {if (finalReferenceDemo != null) { // 5int temp = finalReferenceDemo.arrays[0]; // 6}}
}針對上面的實例程序,線程線程A 執行 wirterOne() 方法,執行完后線程B 執行 writerTwo()?方法,然后線程C 執行 reader() 方法。下圖就以這種執行時序出現的一種情況來討論(耐心看完才有收獲)。
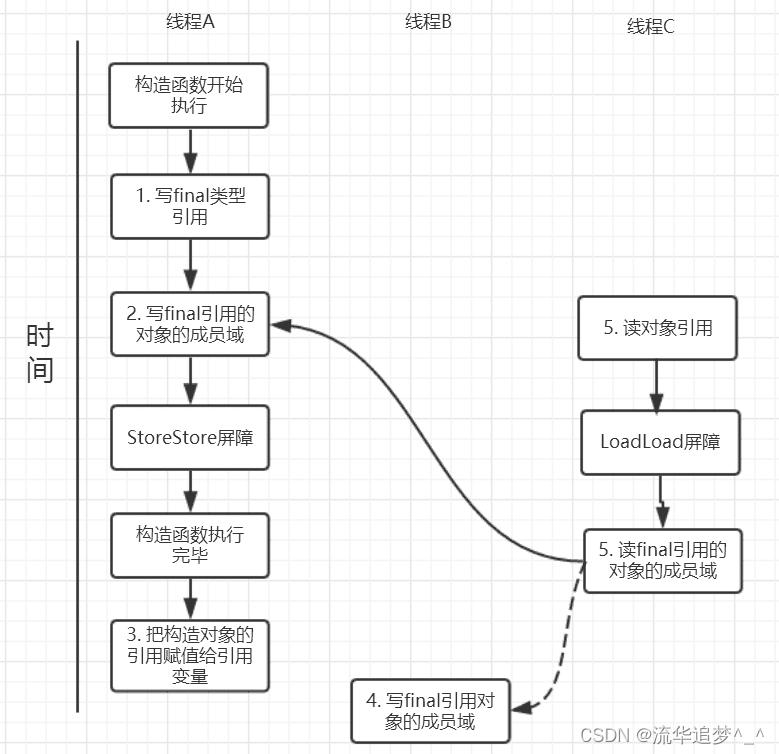
由于對 final 域的寫禁止重排序到構造方法外,因此1 和 3 不能被重排序。由于一個 final 域的引用對象的成員域寫入不能與隨后將這個被構造出來的對象賦給引用變量重排序,因此 2 和 3 不能重排序。?
3.2.2.?對 final 修飾的對象的成員域讀操作
? ? JMM 可以確保線程C 至少能看到寫線程A 對 final 引用的對象的成員域的寫入,即能看下arrays[0] = 1,而寫線程B 對數組元素的寫入可能看到可能看不到。JMM 不保證線程B 的寫入對線程C 可見,線程B 和線程C 之間存在數據競爭,此時的結果是不可預知的。如果可見的,可使用鎖或者 volatile。
3.3.?final 重排序的總結
按照 final 修飾的數據類型分類:
基本數據類型:
1. final 域寫:禁止final域寫與構造方法重排序,即禁止 final 域寫重排序到構造方法之外,從而保證該對象對所有線程可見時,該對象的final域全部已經初始化過。
2. final 域讀:禁止初次讀對象的引用與讀該對象包含的 final 域的重排序。
引用數據類型:
額外增加約束:禁止在構造函數對一個 final 修飾的對象的成員域的寫入與隨后將這個被構造的對象的引用賦值給引用變量重排序。
四. final 再深入理解
4.1.?final 的實現原理
? ? 上面我們提到過,寫 final 域會要求編譯器在 final 域寫之后,構造函數返回前插入一個StoreStore 屏障。讀 final 域的重排序規則會要求編譯器在讀 final 域的操作前插入一個 LoadLoad屏障。
? ? 很有意思的是,如果以 X86 處理器為例,X86 處理器不會對寫-寫重排序,所以 StoreStore屏障可以省略。由于不會對有間接依賴性的操作重排序,所以在 X86 處理器中,讀 final 域需要的LoadLoad 屏障也會被省略掉。也就是說,以 X86 為例的話,對 final 域的讀/寫的內存屏障都會被省略!具體是否插入還是得看是什么處理器。
4.2.?為什么 final 引用不能從構造函數中“溢出”
? ? 這里還有一個比較有意思的問題:上面對 final 域寫重排序規則可以確保我們在使用一個對象引用的時候,該對象的 final 域已經在構造函數被初始化過了。但是這里其實是有一個前提條件的,也就是:在構造函數,不能讓這個被構造的對象被其他線程可見,也就是說該對象引用不能在構造函數中“溢出”。以下面的例子來說:
public class FinalReferenceEscapeDemo {private final int a;private FinalReferenceEscapeDemo referenceDemo;public FinalReferenceEscapeDemo() {a = 1; // 1referenceDemo = this; // 2}public void writer() {new FinalReferenceEscapeDemo();}public void reader() {if (referenceDemo != null) { // 3int temp = referenceDemo.a; // 4}}
}可能的執行時序如圖所示:?
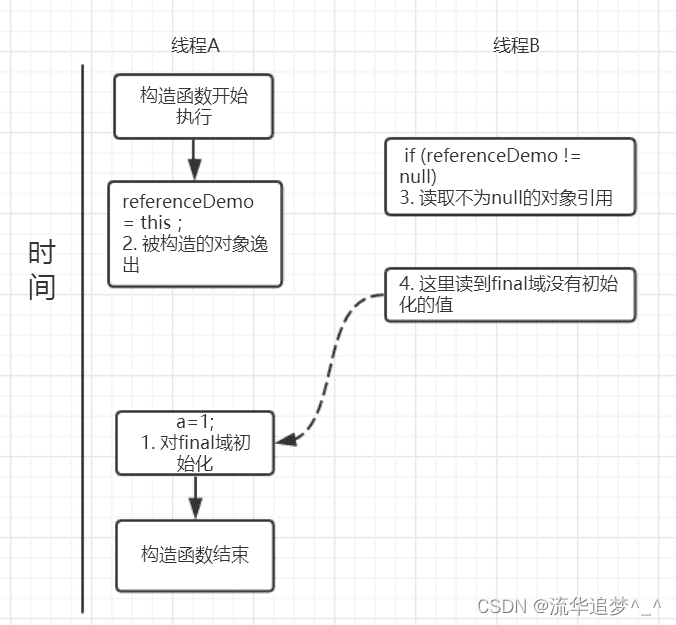
假設一個線程A 執行 writer() 方法,另一個線程執行 reader() 方法。因為構造函數中操作 1 和 2 之間沒有數據依賴性,1 和 2 可以重排序,先執行了 2,這個時候引用對象 referenceDemo 是個沒有完全初始化的對象,而當線程B 去讀取該對象時就會出錯。盡管依然滿足了 final 域寫重排序規則:在引用對象對所有線程可見時,其 final 域已經完全初始化成功。但是,引用對象 this 逸出,該代碼依然存在線程安全的問題。
4.3.?使用 final 的限制條件和局限性
當聲明一個 final 成員時,必須在構造函數退出前設置它的值。
public class MyClass {private final int myField = 1;public MyClass() {...}
}// 或者public class MyClass {private final int myField;public MyClass() {...myField = 1;...}
}將指向對象的成員聲明為 final 只能將該引用設為不可變的,而非所指的對象。
下面的方法仍然可以修改該 list:
private final List myList = new ArrayList();
myList.add("Hello");聲明為 final 可以保證如下操作不合法:
final List myList = new ArrayList();
myList = someOtherList;如果一個對象將會在多個線程中訪問,并且你并沒有將其成員聲明為 final,則必須提供其他方式保證線程安全。其他方式可以包括聲明成員為 volatile,使用 synchronized 或者顯式 Lock 控制所有該成員的訪問。
再思考一個有趣的現象:
byte b1 = 1;
byte b2 = 3;
byte b3 = b1 + b2; // 當程序執行到這一行的時候會出錯,因為b1、b2可以自動轉換成int類型的變量,運算時Java虛擬機對它進行了轉換,結果導致把一個int賦值給byte-----出錯
如果對b1 b2加上final就不會出錯:
final byte b1 = 1;
final byte b2 = 3;
byte b3 = b1 + b2; // 不會出錯,相信你看了上面的解釋就知道原因了。












——第4期)



解決方法)

