公眾號「架構成長指南」,專注于生產實踐、云原生、分布式系統、大數據技術分享。
數據庫和Redis如何保存強一致性,這篇文章告訴你
目的
Redis和Msql來保持數據同步,并且強一致,以此來提高對應接口的響應速度,剛開始考慮是用mybatis的二級緩存,發現坑不少,于是決定自己搞
要關注的問題點
操作數據必須是唯一索引
如果更新數據不是唯一索引,則數據庫更新后的值,與緩存不一致,而查詢還會走緩存,而查詢的值是臟值。
查詢唯一數據,數據值必須是全部字段
假如:B交易查詢字段不是全部字段,進行查詢放入緩存,A交易進行查詢時,從緩存獲取,由于A交易需要全部字段,所以就會出現不可預知的問題。
查詢緩存數據后,必須要在程序中再次進行條件判斷
因為在redis中,存儲的的key是唯一索引,所以當查詢數據后,只會命中唯一索引的數據,其他附帶查詢條件不生效。
例如:唯一索引為:user_id ,那么執行
select * from t_user_auth_info where user_id=‘111’ and user_level=‘1’是,條件user_level是不會生效
高并發場景下要注意臟數據的控制
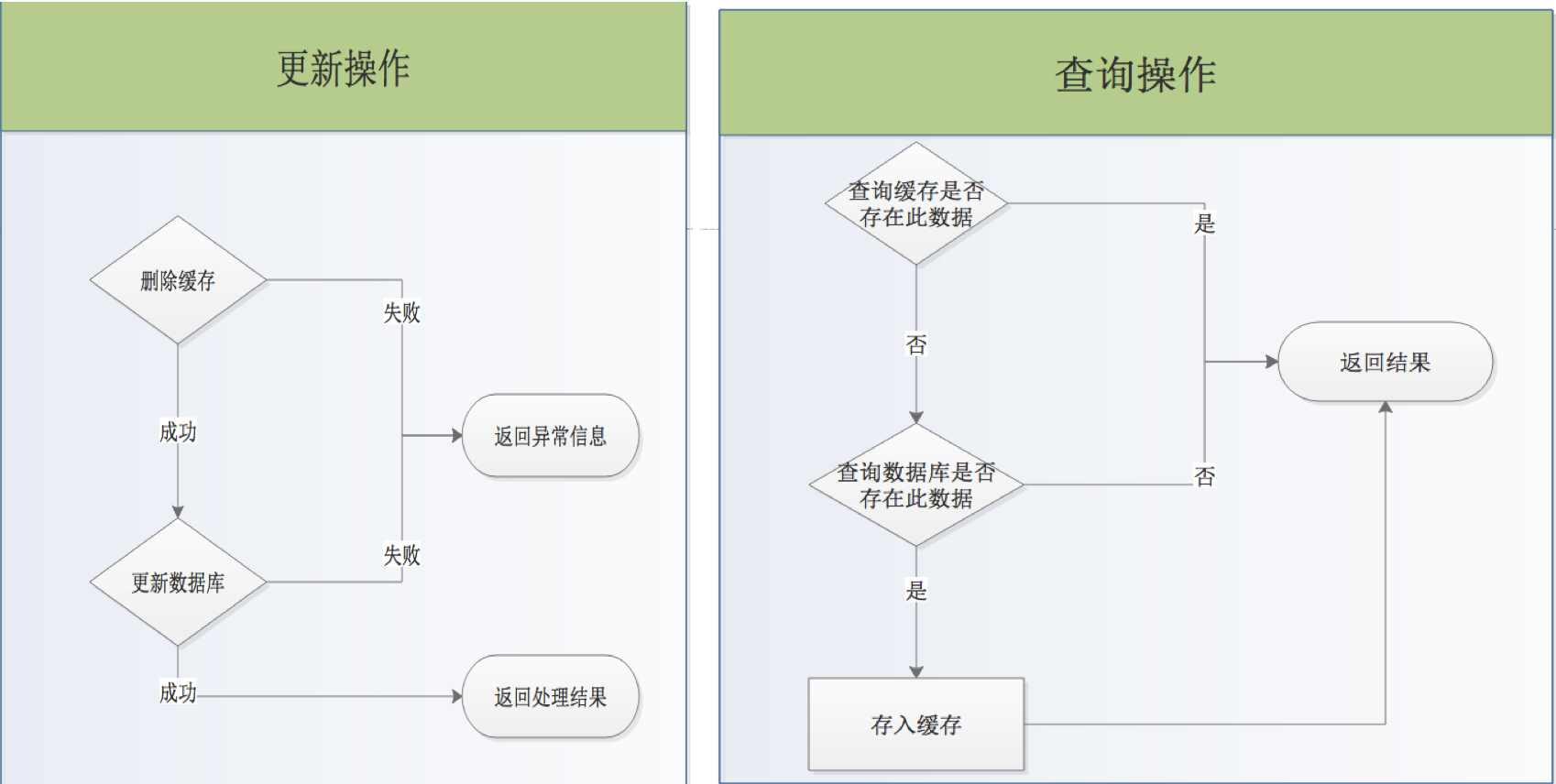
假設是以上流程圖,在更新操作,第一步刪除緩存后,線程切換到查詢線程,查詢操作判斷緩存中沒有數據,就會查詢數據庫,并把數據存入到緩存中,這時線程在切換到更新線程,進行數據庫的更新,這會就會造成,數據庫的數據與緩存有不一致性。
最終方案
基于以上問題,我們的最終流程圖如下
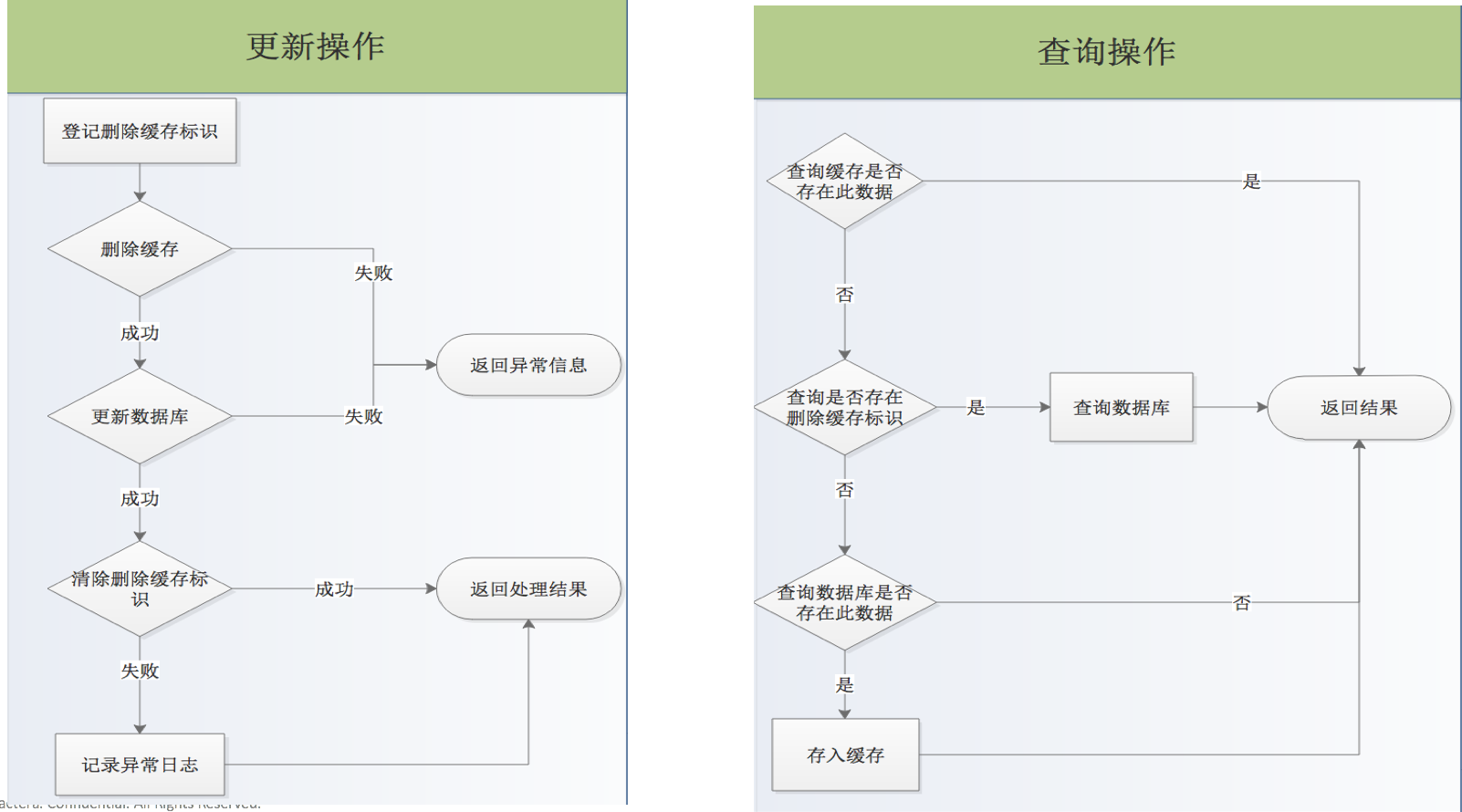
以上流程圖在進行更新操作時,增加刪除緩存lock,如果這會查詢操作判斷緩存中有數據,就直接返回數據,如果沒有再次判斷有沒有存在刪除緩存lock,如果有則走數據庫查詢,并返回,不放入緩存,如果沒有則查詢數據庫,并放入緩存,并返回。
注意: 登記緩存標識時,增加緩存lock失效時間,因為有可能刪除緩存和數據庫更新成功了,而刪除緩存lock失敗了,那這樣后續查詢就都走數據庫了,這個方案就失去意義了。
代碼實現方案
通過aop對db的操作方法,進行攔截,查詢方法采用一個切面,刪除和更新方法采用一個切面,然后再按照以上流程進行編寫,我們這邊是使用框架進行封裝,最后只需要開發人員配置以下xml即可
<cache-config><cache-entity po="com.demo.po.AuthUser" key-prefix="SYSTEM_Person" po-throws="true" key-expire="" key-expire-time-unit=""><key-properties>userId</key-properties> </cache-entity>
</cache-config>
如果需要具體實現方案,請聯系作者

)
)















——第4期)
