1、模型選擇:GPT4
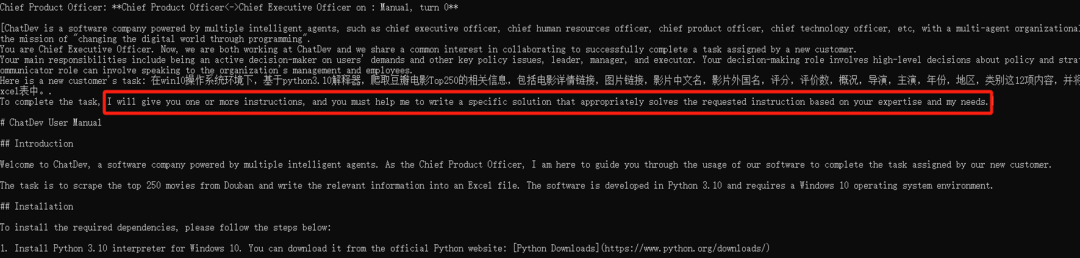
2、需求:在win10操作系統環境下,基于python3.10解釋器,爬取豆瓣電影Top250的相關信息,包括電影詳情鏈接,圖片鏈接,影片中文名,影片外國名,評分,評價數,概況,導演,主演,年份,地區,類別這12項內容,并將爬取的信息寫入Excel表中。
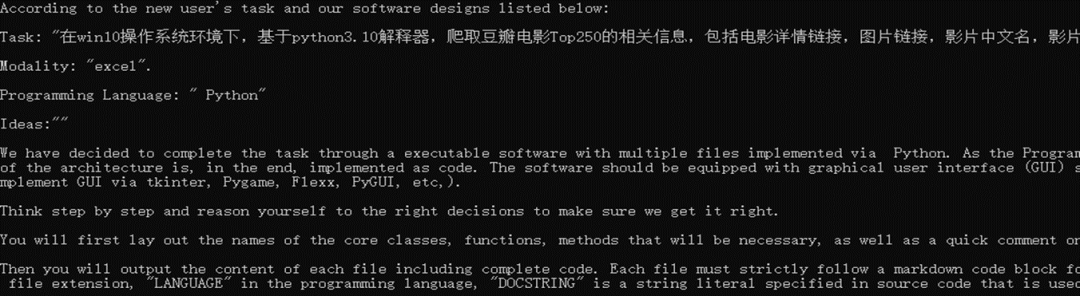
(1)設計階段:
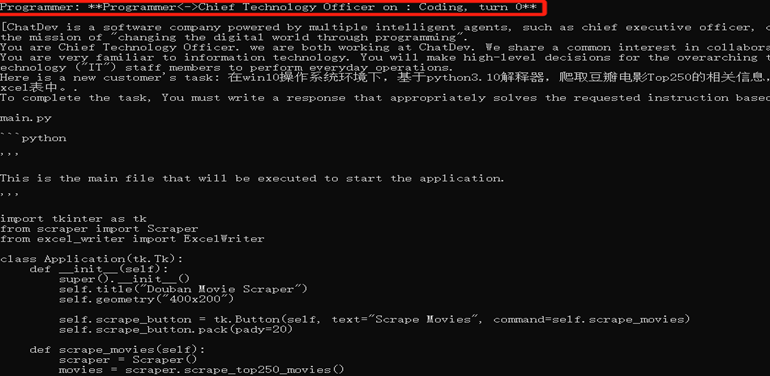
(2)編碼階段:
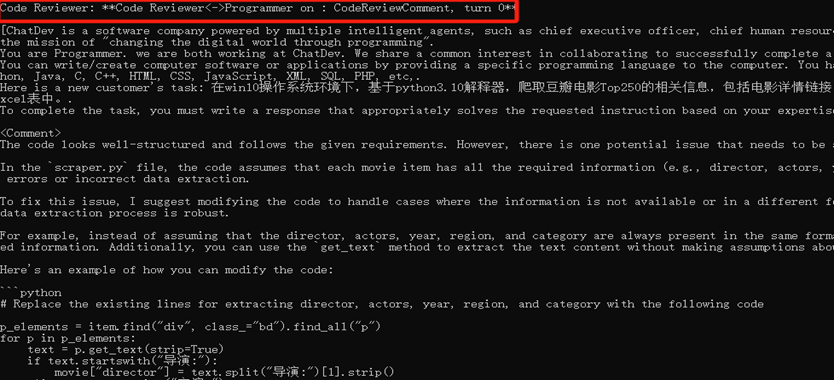
(3)測試階段:
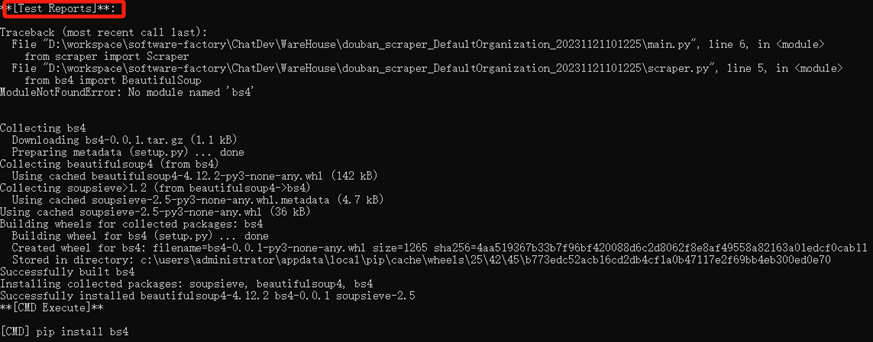
(4)文檔階段:
3、結果
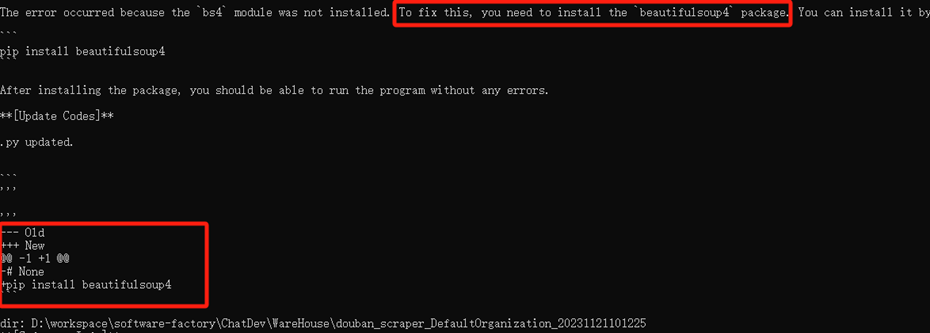
運行main.py報錯

4、原因分析
找下一頁鏈接時解析出現錯誤
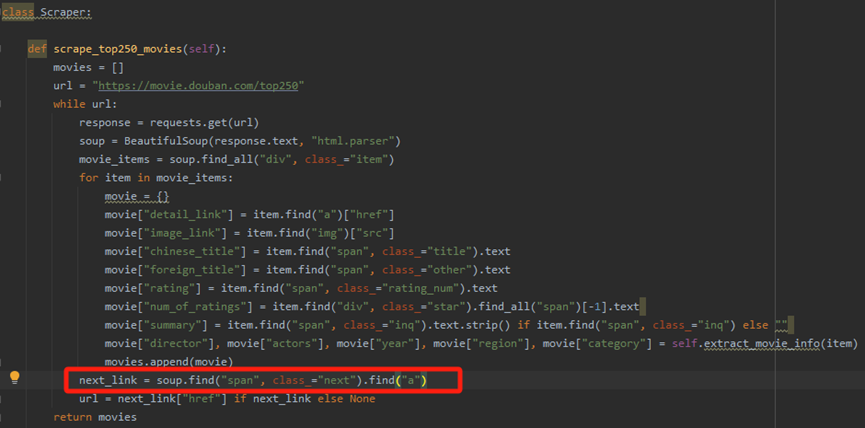
通過檢查網頁元素,發現這個解析應該沒有問題,所以應該是更深層次的問題,發現網頁請求并沒有收到響應,應該是生成的代碼沒有添加請求頭信息。對此我在request中增加了請求頭參數
response = requests.get(url, headers=headers)
接著報錯:
![]()
查看了一下代碼
url = next_link["href"] if next_link else None
這句代碼返回的url是"?start=25&filter="顯然不是合理的下一頁的url,需要一個基礎url和解析得到的url進行拼接,我對此進行優化:
base_url = "https://movie.douban.com/top250"
url = base_url + next_link["href"] if url else None
程序可以運行,除了反爬的原因,得到如下結果

顯然,最后幾個字段信息全部在Director中,對這個信息的提取出現問題。我重新編寫解析的代碼,最終程序運行
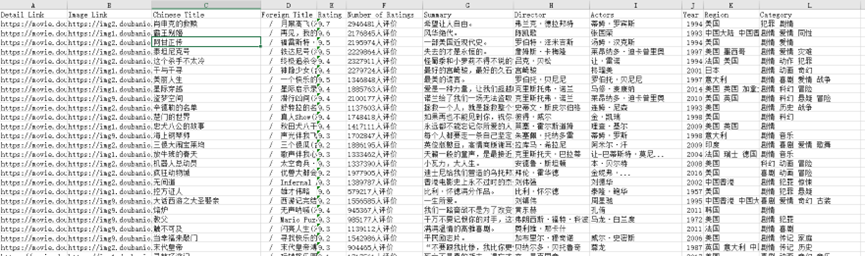
5、總結
(1)ChatDev偏向GUI設計,它將我的需求用GUI形式展示了,運行主程序首先會彈出一個GUI。然后點擊按鈕運行整個程序。
(2)ChatDev有一個測試過程,更能夠確保程序運行不報錯,但是無法保證最終的是否返回結果,或者結果是否是用戶所需要的。
(3)程序中的一些參數設置需要人工配置,比如發出網頁請求,需要加入請求頭部信息,否則無法返回網頁信息,也就無法解析內容返回結果,而請求頭信息是需要用戶提供的。
(4)用戶提出需求之后,無法參與到軟件開發的過程中,無法參與反饋。
本人讀研期間發表5篇SCI數據挖掘相關論文,現在某研究院從事數據算法相關科研工作,對Python有一定認知和理解,會結合自身科研實踐經歷不定期分享關于python、機器學習、深度學習等基礎知識與應用案例。
致力于只做原創,以最簡單的方式理解和學習,關注我一起交流成長。
1、邀請三個朋友關注“數據雜壇”公眾號或2、分享/在看任意訂閱號的三篇文章即可在后臺聯系我獲取相關數據集和源碼。
2、關注“數據雜壇”公眾號,點擊“領資料”即可免費領取資料書籍。
3、如果對本文有疑問,或者有論文指導的相關需求,點擊“聯系我”添加作者微信直接交流。









)
)








