文章目錄
- 項目介紹大全(可點擊查看,不定時更新中)
- 概要
- 一、整體資源介紹
- 技術要點
- 功能展示:
- 功能1 支持單張圖片識別
- 功能2 支持遍歷文件夾識別
- 功能3 支持識別視頻文件
- 功能4 支持攝像頭識別
- 功能5 支持結果文件導出(xls格式)
- 功能6 支持切換檢測到的目標查看
- 二、系統環境與依賴配置說明
- 三、數據集
- 四、算法介紹
- 1. YOLOv8 概述
- 簡介
- 2. YOLOv5 概述
- 簡介
- 3. YOLO11 概述
- YOLOv11:Ultralytics 最新目標檢測模型
- 🌟 五、模型訓練步驟
- 🌟 六、模型評估步驟
- 🌟 七、訓練結果
- 🌟八、完整代碼
往期經典回顧
| 項目 | 項目 |
|---|---|
| 基于yolov8的車牌檢測識別系統 | 基于yolov8/yolov5/yolo11的動物檢測識別系統 |
| 基于yolov8的人臉表情檢測識別系統 | 基于深度學習的PCB板缺陷檢測系統 |
| 基于yolov8/yolov5的茶葉等級檢測系統 | 基于yolov8/yolov5的農作物病蟲害檢測識別系統 |
| 基于yolov8/yolov5的交通標志檢測識別系統 | 基于yolov8/yolov5的課堂行為檢測識別系統 |
| 基于yolov8/yolov5的海洋垃圾檢測識別系統 | 基于yolov8/yolov5的垃圾檢測與分類系統 |
| 基于yolov8/yolov5的行人摔倒檢測識別系統 | 基于yolov8/yolov5的草莓病害檢測識別系統 |
具體項目資料請看項目介紹大全
項目介紹大全(可點擊查看,不定時更新中)
概要
人工智能 (AI) 在工業質量檢測領域的應用日益廣泛,其中基于深度學習的焊縫質量檢測識別成為一個備受關注的研究方向。通過利用計算機視覺和深度學習技術,我們可以自動識別焊縫表面及內部的缺陷類型(如裂紋、氣孔、夾渣、未熔合、未焊透等),提升工業制造中焊縫檢測的精準度、效率及安全性。本文將介紹基于深度學習的焊縫質量檢測識別系統,并提供一個簡單的 Python 代碼實現,以便讀者更好地了解這一技術。
焊縫是機械制造、建筑鋼結構、石油化工管道、航空航天設備等領域的關鍵連接部位,其質量直接決定了設備的結構強度、密封性與使用壽命,甚至關系到工業生產的安全穩定。然而,傳統焊縫質量檢測面臨諸多挑戰:人工目視檢測依賴檢測人員的經驗,易受主觀判斷影響,對微小裂紋、內部氣孔等隱蔽缺陷識別能力不足;超聲、射線等傳統無損檢測方法操作復雜、檢測周期長,且難以實現大規模流水線式檢測;部分檢測方式還存在對檢測人員技能要求高、檢測成本高等問題。這些問題會導致不合格焊縫流入后續環節,輕則引發設備故障、增加維修成本,重則可能在使用過程中出現焊縫斷裂,引發安全生產事故,造成人員傷亡與財產損失。因此,高效、精準地實現焊縫質量檢測識別,對于工業制造企業與質量監管部門來說至關重要。
此外,我們開發了一款帶有UI界面的紙板缺陷檢測識別系統,支持實時檢測紙板的缺陷的識別,并能夠直觀地展示檢測結果。系統采用Python與PyQt5開發,可以對圖片、視頻及攝像頭輸入進行目標檢測,同時支持檢測結果的保存。本文還提供了完整的Python代碼和詳細的使用指南,供有興趣的讀者學習參考。獲取完整代碼資源,請參見文章末尾。
??
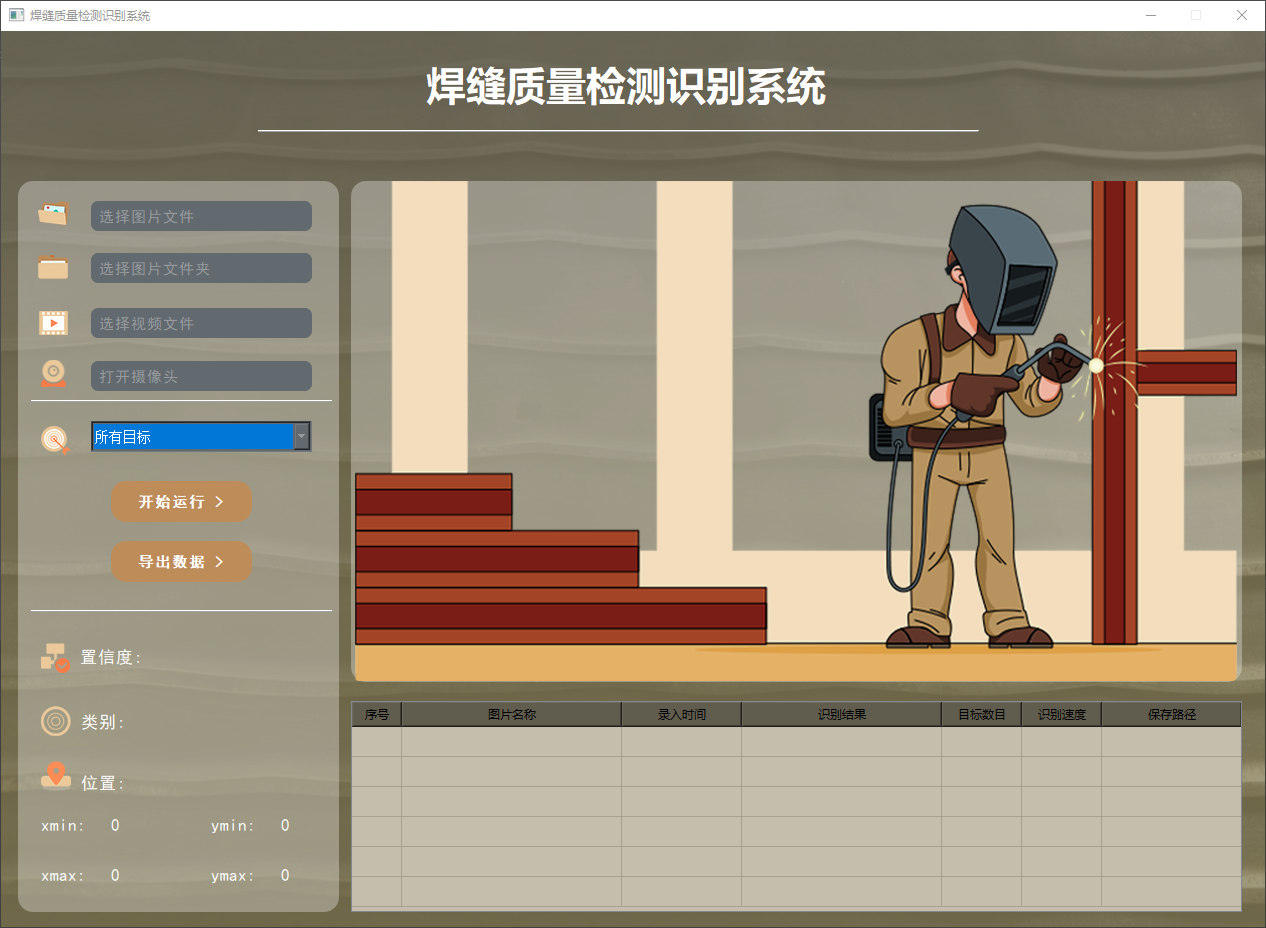
yolov8/yolov5界面如下
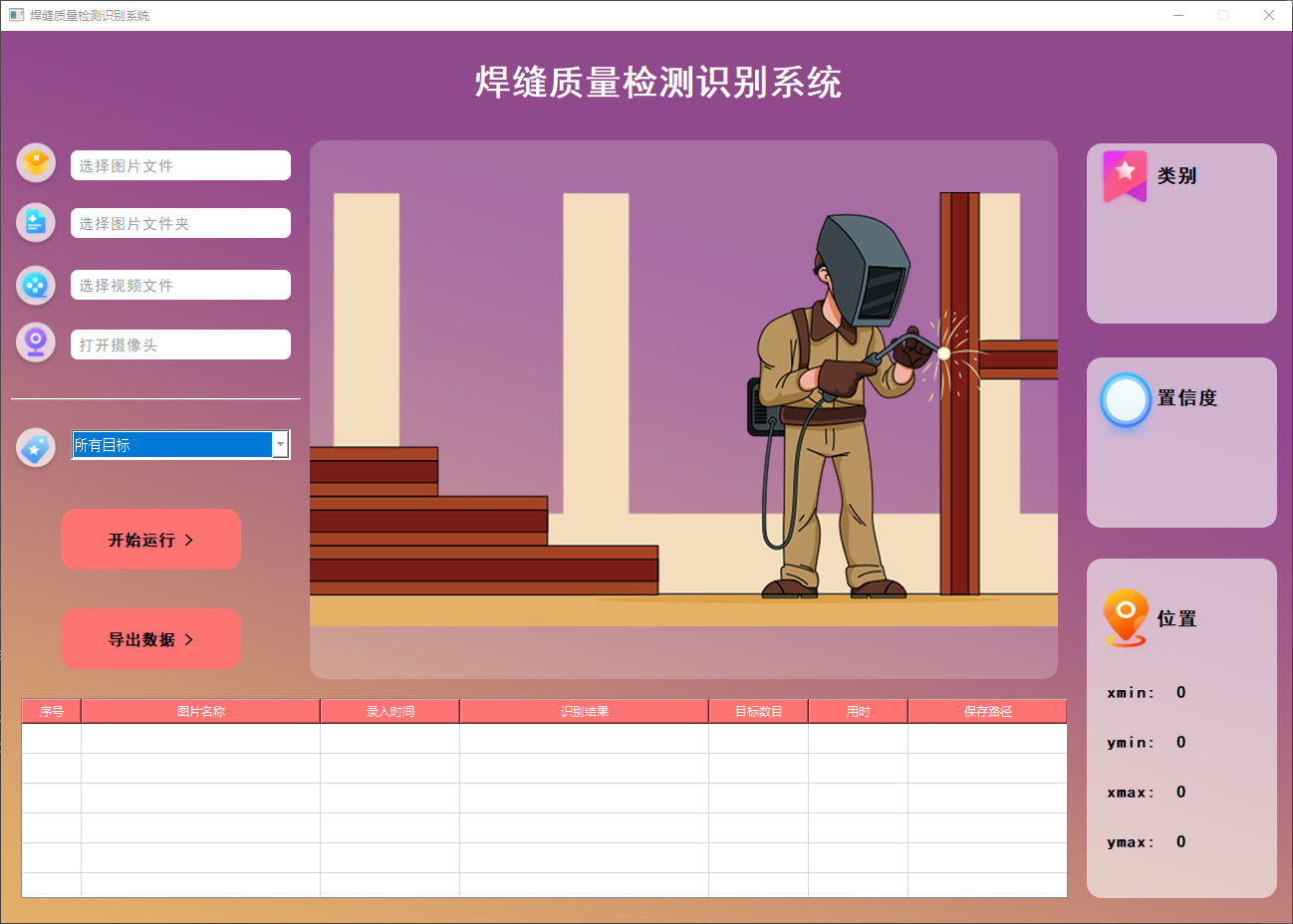
yolo11界面如下
關鍵詞:焊縫質量檢測;深度學習;特征融合;注意力機制;卷積神經網絡

一、整體資源介紹
項目中所用到的算法模型和數據集等信息如下:
算法模型:
? ? yolov8、yolov8 + SE注意力機制 或 yolov5、yolov5 + SE注意力機制 或 yolo11、yolo11 + SE注意力機制
數據集:
? ? 網上下載的數據集,格式都已轉好,可直接使用。
以上是本套代碼算法的簡單說明,添加注意力機制是本套系統的創新點 。
技術要點
- OpenCV:主要用于實現各種圖像處理和計算機視覺相關任務。
- Python:采用這種編程語言,因其簡潔易學且擁有大量豐富的資源和庫支持。
- 數據增強技術: 翻轉、噪點、色域變換,mosaic等方式,提高模型的魯棒性。
功能展示:
部分核心功能如下:
- 功能1: 支持單張圖片識別
- 功能2: 支持遍歷文件夾識別
- 功能3: 支持識別視頻文件
- 功能4: 支持攝像頭識別
- 功能5: 支持結果文件導出(xls格式)
- 功能6: 支持切換檢測到的目標查看
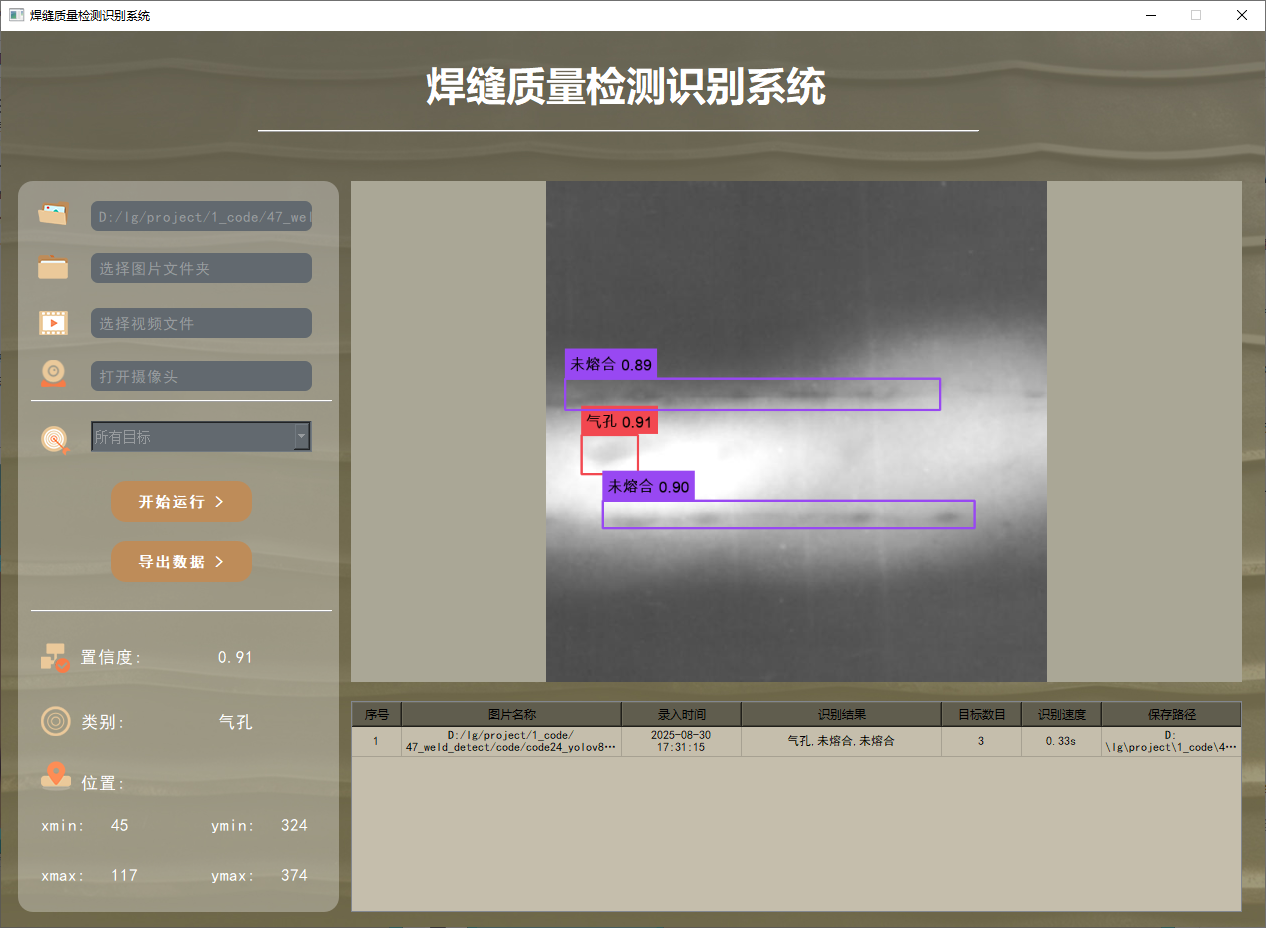
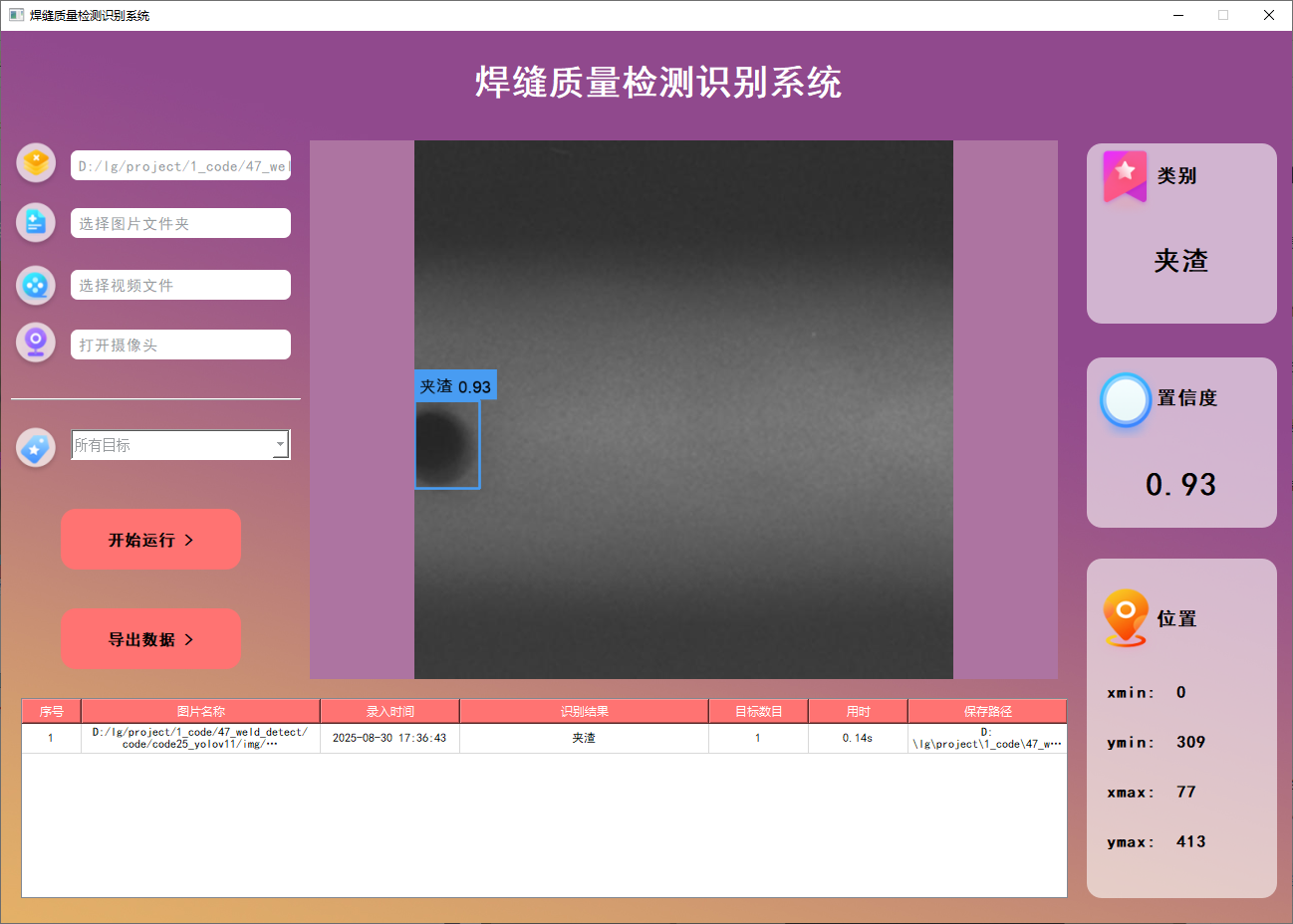
功能1 支持單張圖片識別
系統支持用戶選擇圖片文件進行識別。通過點擊圖片選擇按鈕,用戶可以選擇需要檢測的圖片,并在界面上查看所有識別結果。該功能的界面展示如下圖所示:
功能2 支持遍歷文件夾識別
系統支持選擇整個文件夾進行批量識別。用戶選擇文件夾后,系統會自動遍歷其中的所有圖片文件,并將識別結果實時更新顯示在右下角的表格中。該功能的展示效果如下圖所示:
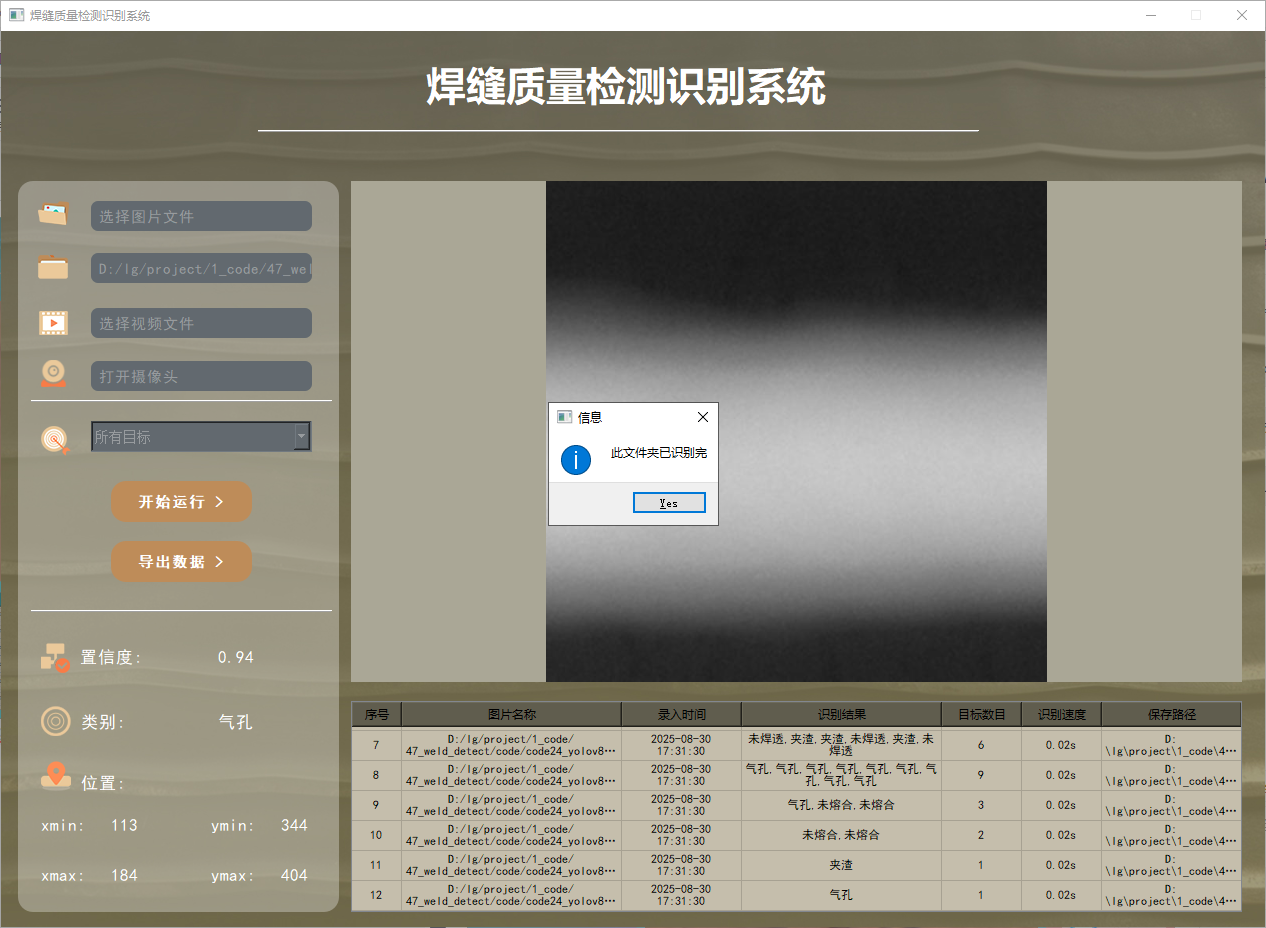
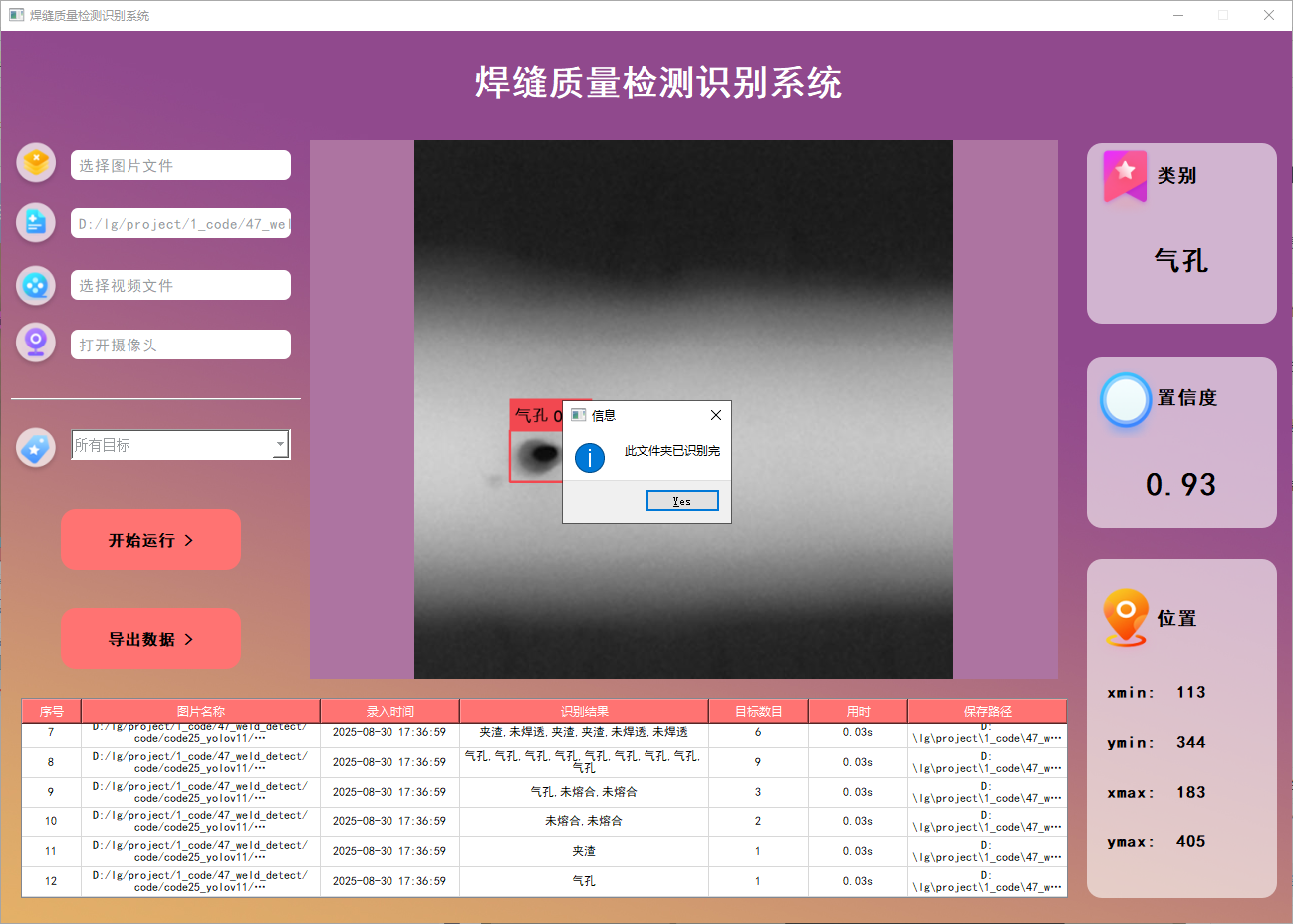
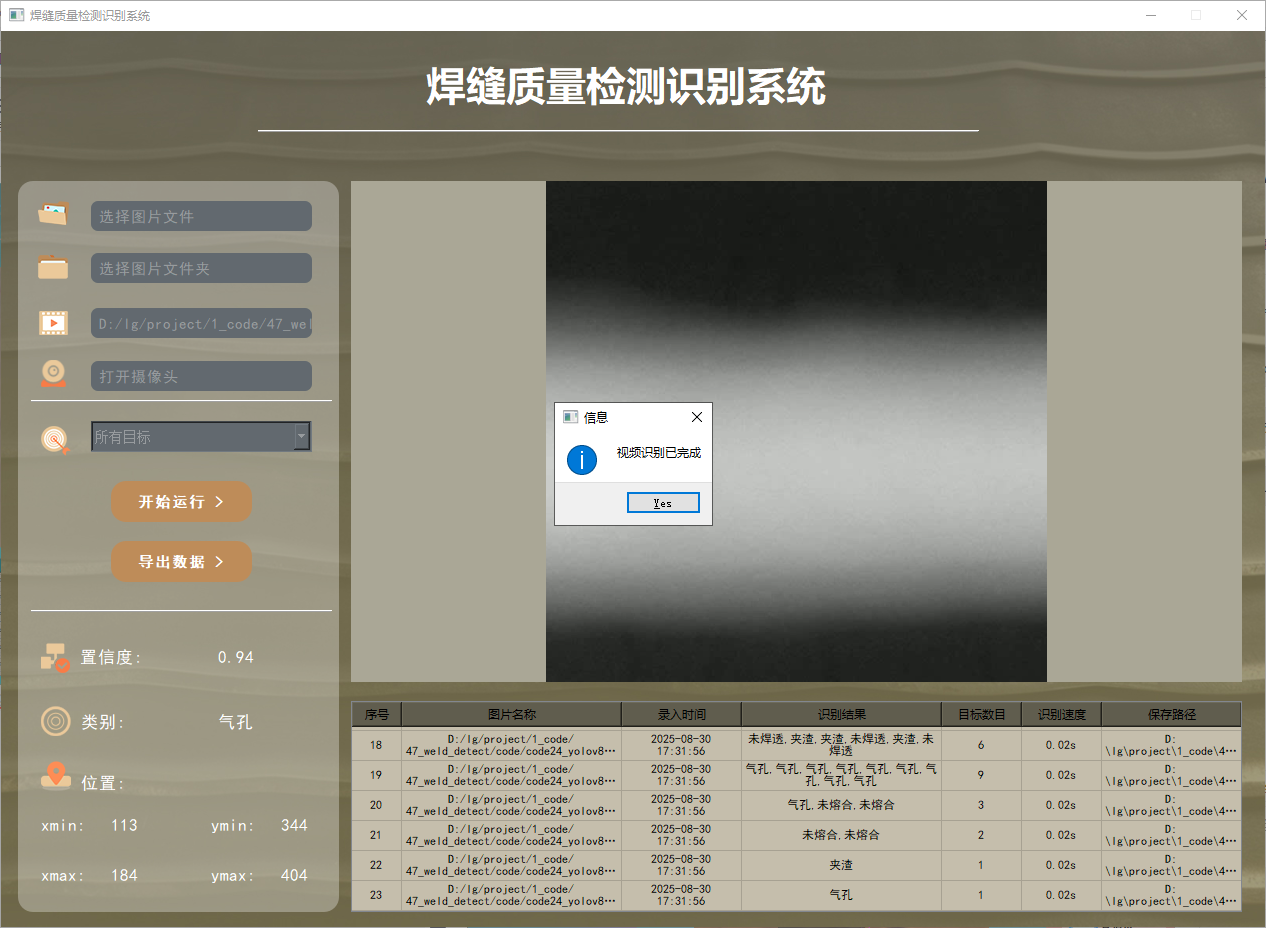
功能3 支持識別視頻文件
在許多情況下,我們需要識別視頻中的目標。因此,系統設計了視頻選擇功能。用戶點擊視頻按鈕即可選擇待檢測的視頻,系統將自動解析視頻并逐幀識別多個車牌,同時將識別結果記錄在右下角的表格中。以下是該功能的展示效果:
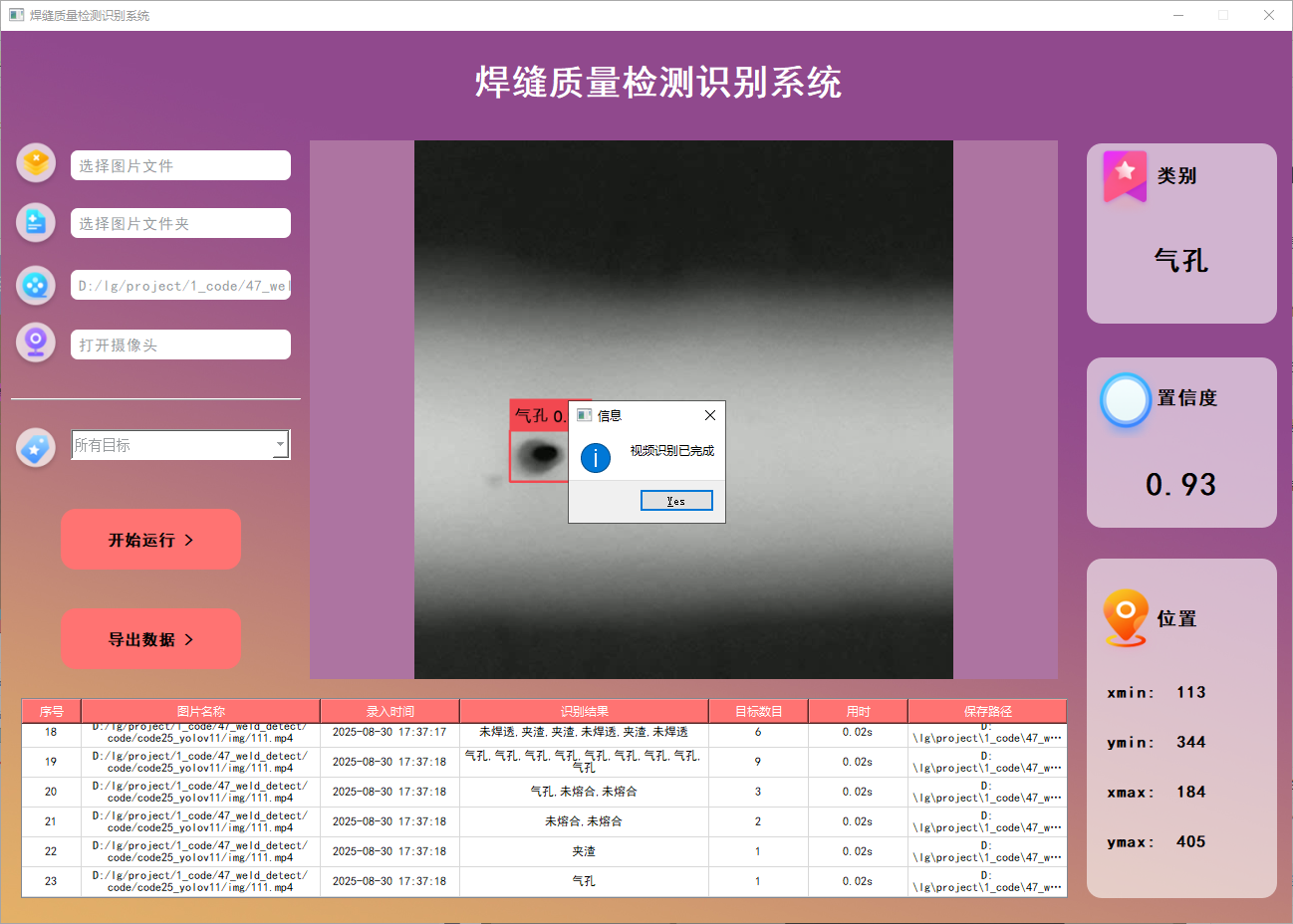
功能4 支持攝像頭識別
在許多場景下,我們需要通過攝像頭實時識別目標。為此,系統提供了攝像頭選擇功能。用戶點擊攝像頭按鈕后,系統將自動調用攝像頭并進行實時車牌識別,識別結果會即時記錄在右下角的表格中。
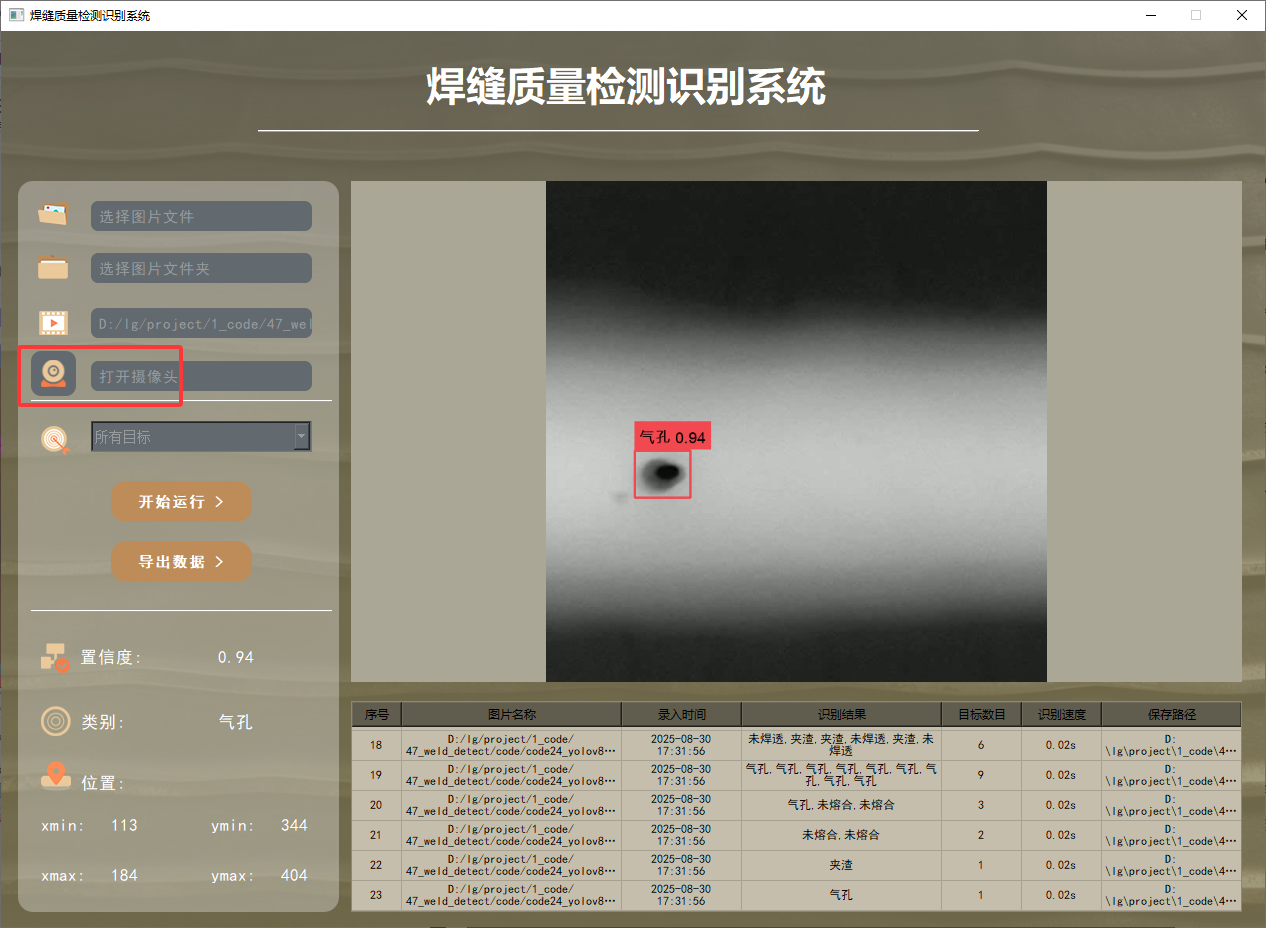
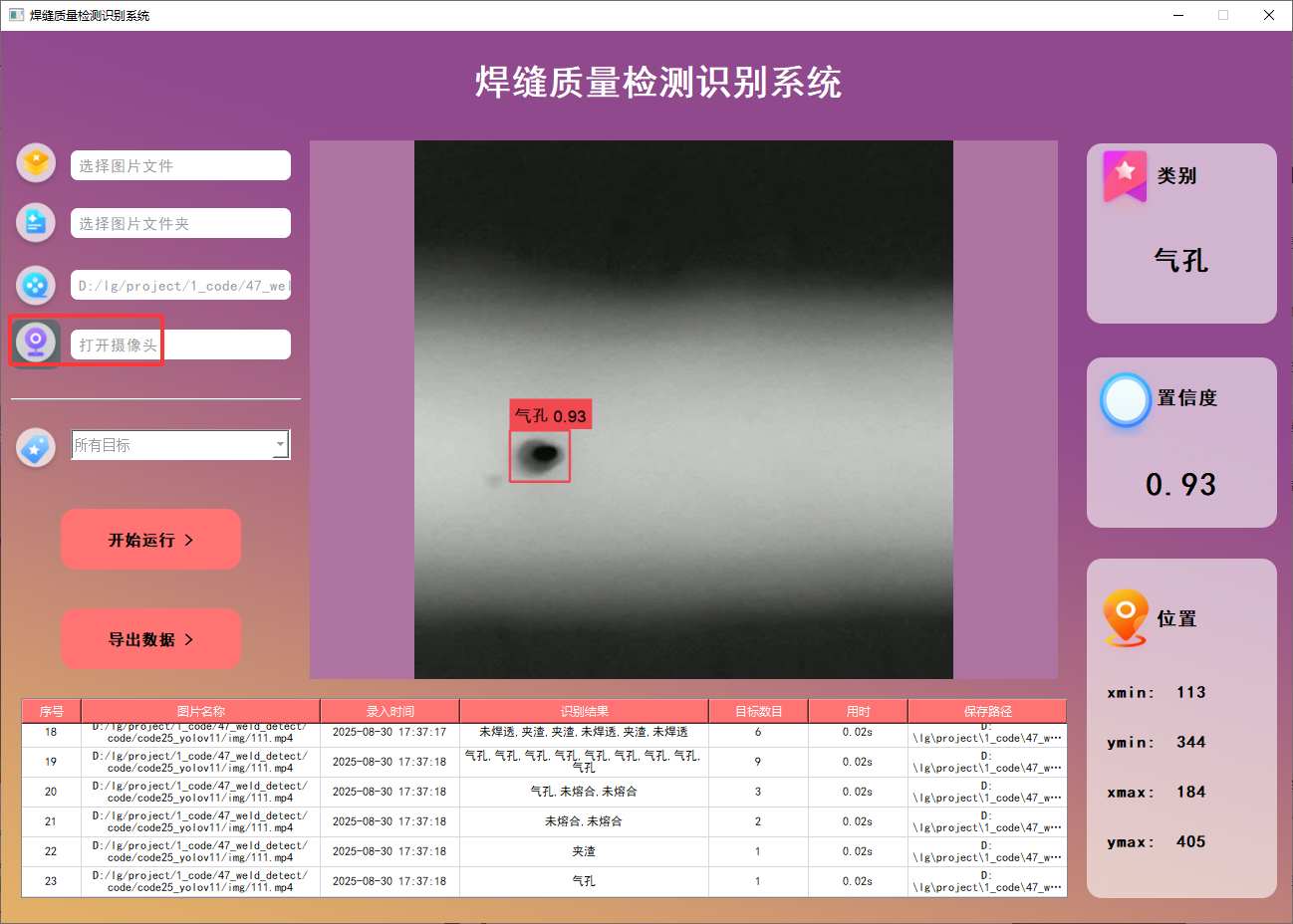
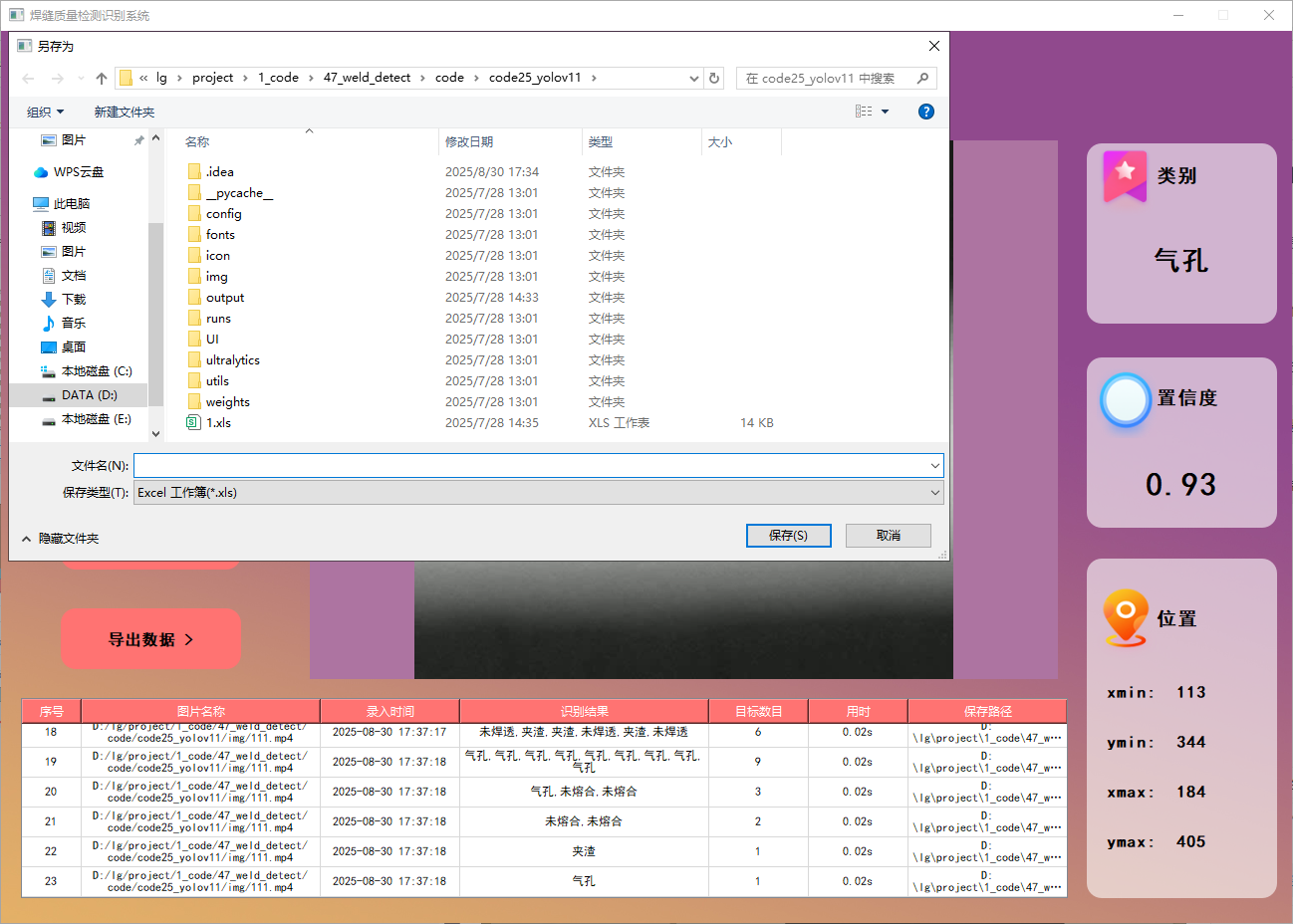
功能5 支持結果文件導出(xls格式)
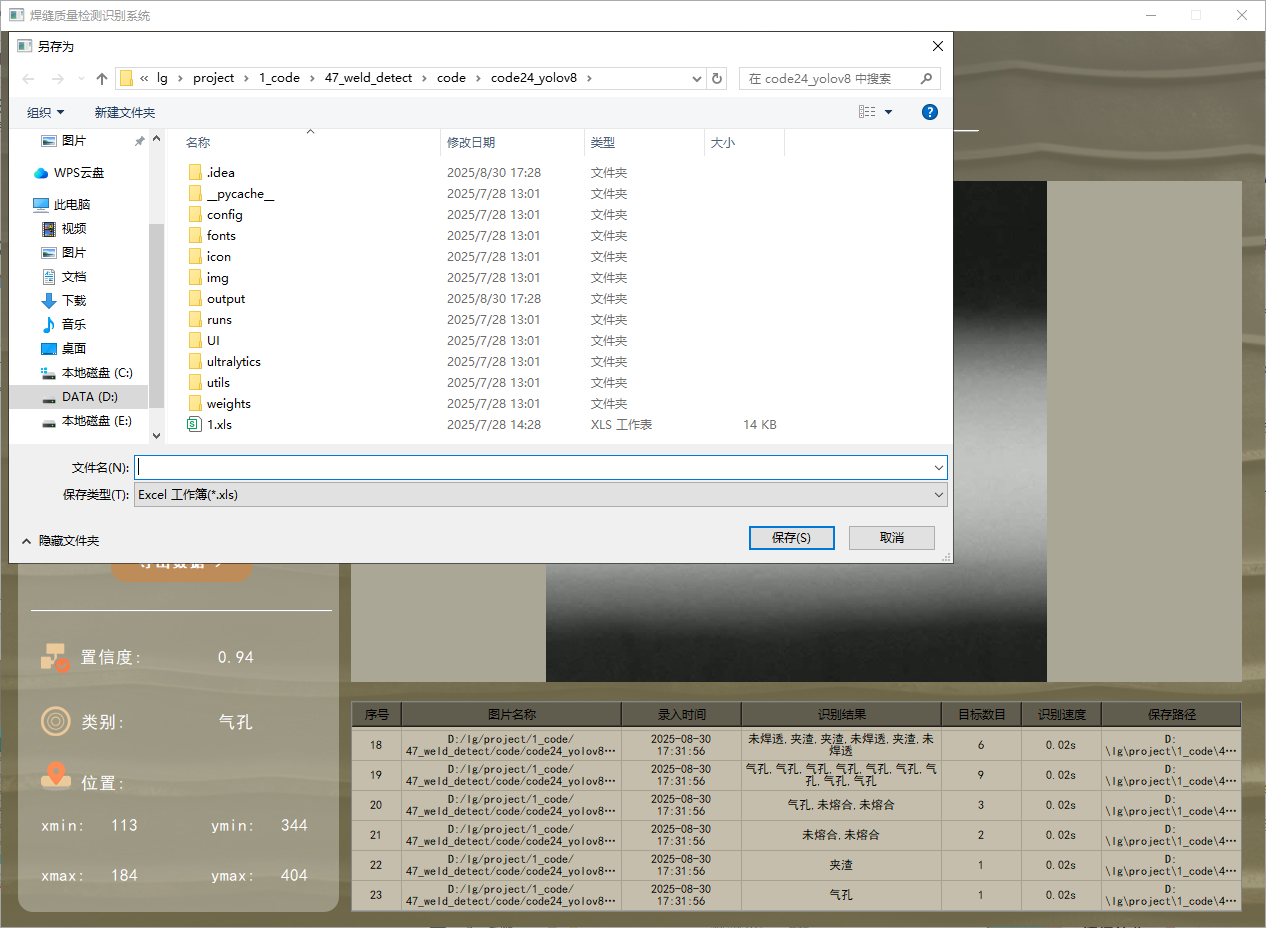
本系統還添加了對識別結果的導出功能,方便后續查看,目前支持導出xls數據格式,功能展示如下:
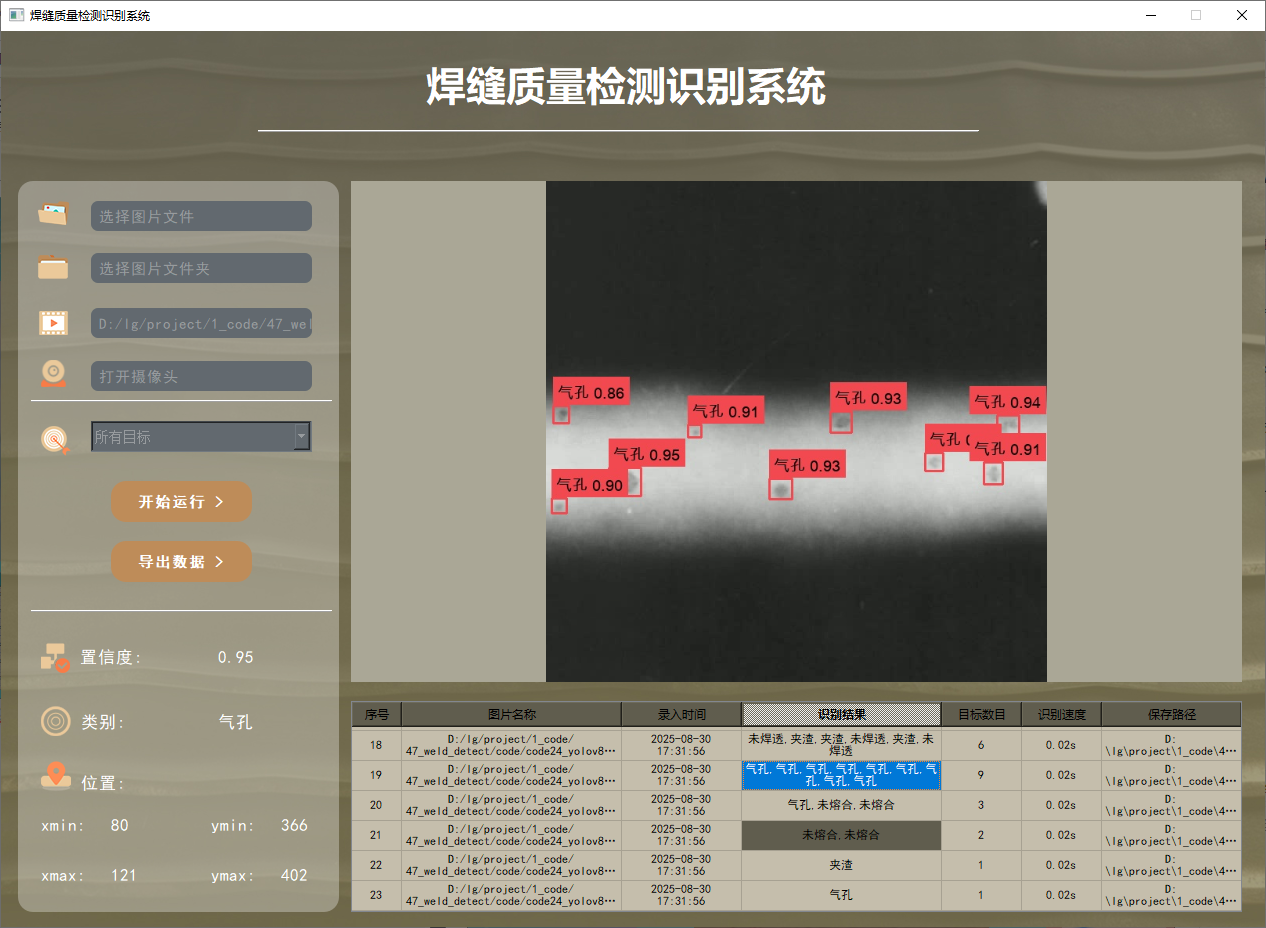
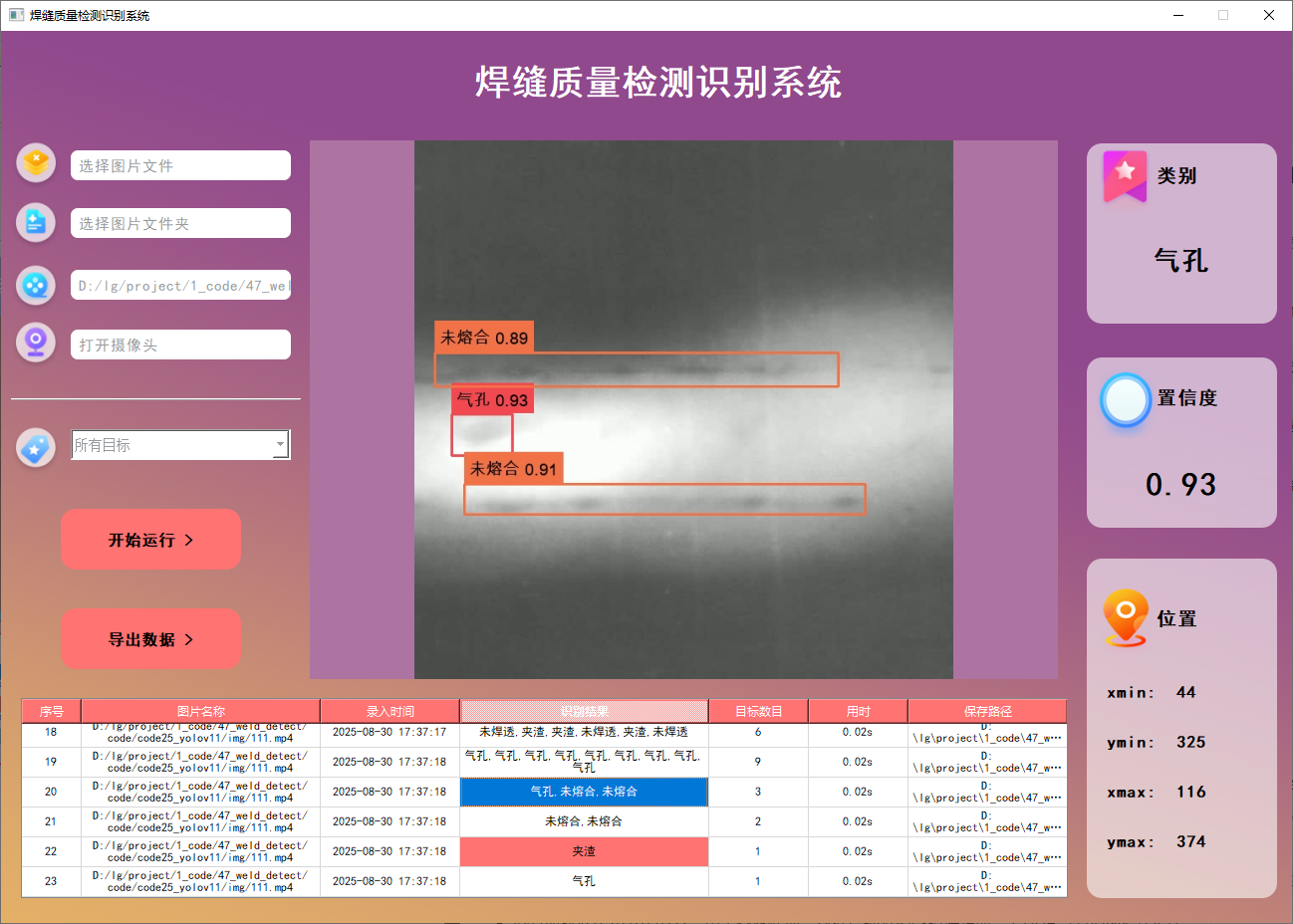
功能6 支持切換檢測到的目標查看
二、系統環境與依賴配置說明
本項目采用 Python 3.8.10 作為開發語言,整個后臺邏輯均由 Python 編寫,主要依賴環境如下:
圖形界面框架:
- PyQt5 5.15.9:用于搭建系統圖形用戶界面,實現窗口交互與組件布局。 深度學習框架:
- torch 1.9.0+cu111: PyTorch 深度學習框架,支持 CUDA 11.1 加速,用于模型構建與推理。
- torchvision 0.10.0+cu111:用于圖像處理、數據增強及模型組件輔助。 CUDA與 cuDNN(GPU 加速支持):
- CUDA 11.1.1(版本號:cuda_11.1.1_456.81):用于 GPU 加速深度學習運算。
- cuDNN 8.0.5.39(適用于 CUDA 11.1):NVIDIA 深度神經網絡庫,用于加速模型訓練與推理過程。 圖像處理與科學計算:
- opencv-python 4.7.0.72:實現圖像讀取、顯示、處理等功能。
- numpy 1.24.4:用于高效數組計算及矩陣操作。
- PIL (pillow) 9.5.0:圖像文件讀寫與基本圖像處理庫。
- matplotlib 3.7.1(可選):用于結果圖形化展示與可視化調試。
三、數據集
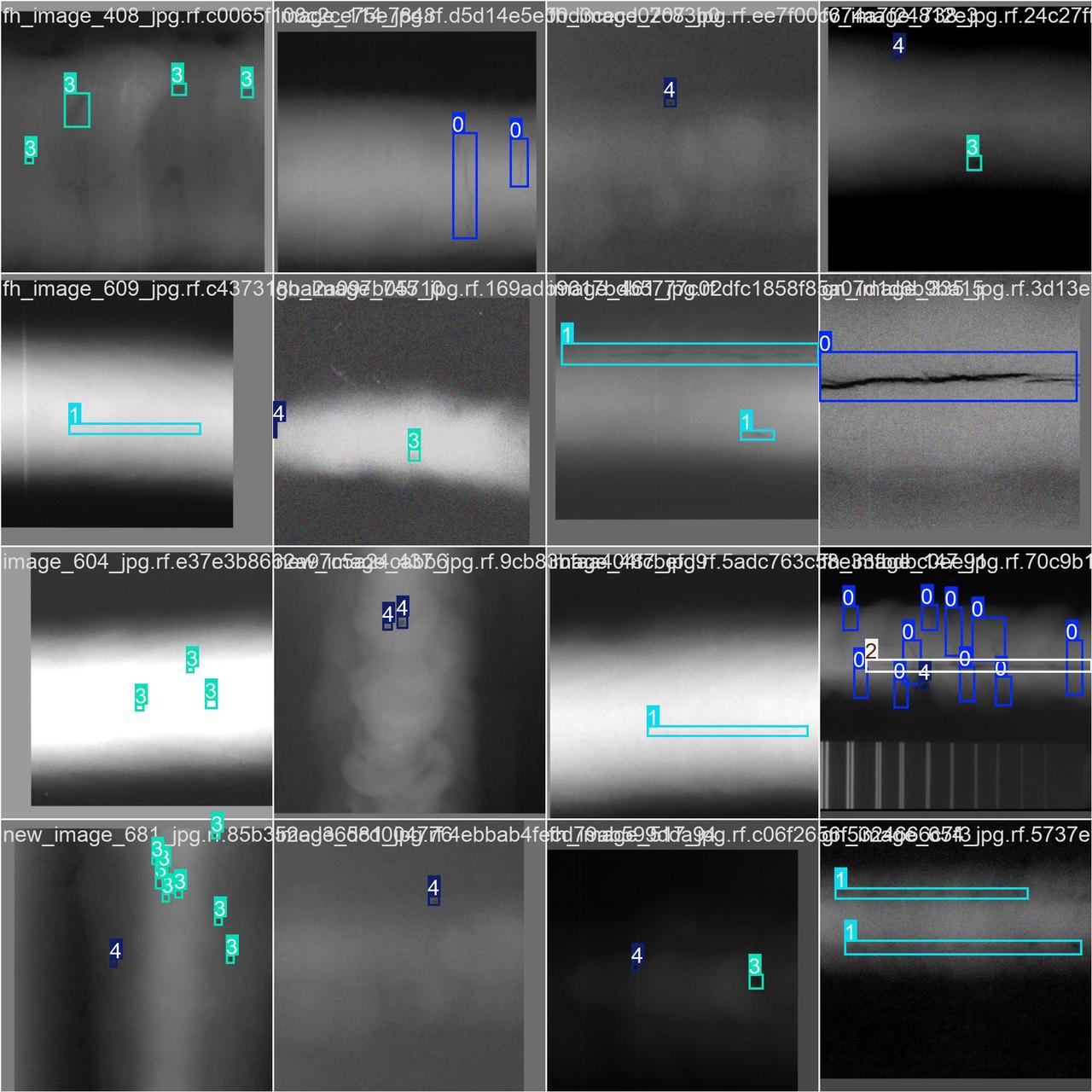
該焊接缺陷圖像數據集共包含6379張圖像,主要用于焊接質量檢測與缺陷分類任務。數據集中涵蓋5種常見的焊接缺陷類型,分別為:
- 裂紋(Crack):焊縫中出現的斷裂,多因應力集中或冷卻不均引起;
- 未熔合(Lack_Of_Fusion):相鄰焊道或焊縫與母材之間未完全熔化,導致結合不良;
- 未焊透(Lack_Of_Penetration):焊接深度不足,未完全穿透母材;
- 氣孔(Porosity):焊縫中形成的小孔,通常由于氣體未及時逸出;
- 夾渣(Slag_Inclusion):焊縫中殘留的熔渣雜質,常因清渣不徹底造成。
四、算法介紹
1. YOLOv8 概述
簡介
YOLOv8算法的核心特性和改進如下:
- 全新SOTA模型
YOLOv8 提供了全新的最先進(SOTA)的模型,包括P5 640 和 P6 1280分辨率的目標檢測網絡,同時還推出了基于YOLACT的實例分割模型。與YOLOv5類似,它提供了N/S/M/L/X五種尺度的模型,以滿足不同場景的需求。 - Backbone
骨干網絡和Neck部分參考了YOLOv7 ELAN的設計思想。
將YOLOv5的C3結構替換為梯度流更豐富的C2f結構。
針對不同尺度的模型,調整了通道數,使其更適配各種任務需求。

網絡結構如下:

相比之前版本,YOLOv8對模型結構進行了精心微調,不再是“無腦”地將同一套參數應用于所有模型,從而大幅提升了模型性能。這種優化使得不同尺度的模型在面對多種場景時都能更好地適應。
然而,新引入的C2f模塊雖然增強了梯度流,但其內部的Split等操作對特定硬件的部署可能不如之前的版本友好。在某些場景中,C2f模塊的這些特性可能會影響模型的部署效率。
2. YOLOv5 概述
簡介
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五個版本。這個模型的結構基本一樣,不同的是deth_multiole模型深度和width_multiole模型寬度這兩個參數。就和我們買衣服的尺碼大小排序一樣,YOLOV5n網絡是YOLOV5系列中深度最小,特征圖的寬度最小的網絡。其他的三種都是在此基礎上不斷加深,不斷加寬。不過最常用的一般都是yolov5s模型。

本系統采用了基于深度學習的目標檢測算法——YOLOv5。作為YOLO系列算法中的較新版本,YOLOv5在檢測的精度和速度上相較于YOLOv3和YOLOv4都有顯著提升。它的核心理念是將目標檢測問題轉化為回歸問題,簡化了檢測過程并提高了性能。
YOLOv5引入了一種名為SPP (Spatial Pyramid Pooling)的特征提取方法。SPP能夠在不增加計算量的情況下,提取多尺度特征,從而顯著提升檢測效果。
在檢測流程中,YOLOv5首先通過骨干網絡對輸入圖像進行特征提取,生成一系列特征圖。然后,對這些特征圖進行處理,生成檢測框和對應的類別概率分數,即每個檢測框內物體的類別和其置信度。
YOLOv5的特征提取網絡采用了CSPNet (Cross Stage Partial Network)結構。它將輸入特征圖分成兩部分,一部分通過多層卷積處理,另一部分進行直接下采樣,最后再將兩部分特征圖進行融合。這種設計增強了網絡的非線性表達能力,使其更擅長處理復雜背景和多樣化物體的檢測任務。

3. YOLO11 概述
YOLOv11:Ultralytics 最新目標檢測模型
YOLOv11 是 Ultralytics 公司在 2024 年推出的 YOLO 系列目標檢測模型的最新版本。以下是對 YOLOv11 的具體介紹:
主要特點
-
增強的特征提取:
- 采用改進的骨干和頸部架構,如在主干網絡中引入了 c2psa 組件,并將 c2f 升級為 c3k2。
- c3k 允許用戶自定義卷積模塊的尺寸,提升了靈活性。
- c2psa 通過整合 psa(位置敏感注意力機制)來增強模型的特征提取效能。
- 頸部網絡采用了 pan 架構,并集成了 c3k2 單元,有助于從多個尺度整合特征,并優化特征傳遞的效率。
-
針對效率和速度優化:
- 精細的架構設計和優化的訓練流程,在保持準確性和性能最佳平衡的同時,提供更快的處理速度。
- 相比 YOLOv10,YOLOv11 的延遲降低了 25%-40%,能夠達到每秒處理 60 幀 的速度,是目前最快的目標檢測模型之一。
-
更少的參數,更高的準確度:
- YOLOv11m 在 COCO 數據集上實現了比 YOLOv8m 更高的 mAP,參數減少了 22%,提高了計算效率,同時不犧牲準確度。
-
跨環境的適應性:
- 可無縫部署在 邊緣設備、云平臺 和配備 NVIDIA GPU 的系統上,確保最大的靈活性。
-
支持廣泛的任務范圍:
- 支持多種計算機視覺任務,包括 目標檢測、實例分割、圖像分類、姿態估計 和 定向目標檢測(OBB)。
架構改進
-
主干網絡:
- 引入了 c2psa 組件,并將 c2f 升級為 c3k2。
- c3k 支持用戶自定義卷積模塊尺寸,增強靈活性。
- c2psa 整合了 psa(位置敏感注意力機制),提升特征提取效能。
-
頸部網絡:
- 采用 pan 架構,并集成了 c3k2 單元,幫助從多個尺度整合特征并優化特征傳遞效率。
-
頭部網絡:
- YOLOv11 的檢測頭設計與 YOLOv8 大致相似。
- 在分類(cls)分支中,采用了 深度可分離卷積 來增強性能。
性能優勢
-
精度提升:
- 在 COCO 數據集上取得了顯著的精度提升:
- YOLOv11x 模型的 mAP 得分高達 54.7%。
- 最小的 YOLOv11n 模型也能達到 39.5% 的 mAP 得分。
- 與前代模型相比,精度有明顯進步。
- 在 COCO 數據集上取得了顯著的精度提升:
-
速度更快:
- 能夠滿足實時目標檢測需求
🌟 五、模型訓練步驟
? ?提供封裝好的訓練腳本,如下圖,更加詳細的的操作步驟可以參考我的飛書在線文檔:https://aax3oiawuo.feishu.cn/wiki/HLpVwQ4QWiTd4Ckdeifcvvdtnve , 強烈建議直接看文檔去訓練模型,文檔是實時更新的,有任何的新問題,我都會實時的更新上去。另外B站也會提供視頻。
-
使用pycharm打開代碼,找到
train.py打開,示例截圖如下:

-
修改
model_yaml的值,根據自己的實際情況修改,想要訓練yolov8s模型 就 修改為model_yaml = yaml_yolov8s, 訓練 添加SE注意力機制的模型就修改為model_yaml = yaml_yolov8_SE -
修改
data_path數據集路徑,我這里默認指定的是traindata.yaml文件,如果訓練我提供的數據,可以不用改 -
修改
model.train()中的參數,按照自己的需求和電腦硬件的情況更改# 文檔中對參數有詳細的說明 model.train(data=data_path, # 數據集imgsz=640, # 訓練圖片大小epochs=200, # 訓練的輪次batch=2, # 訓練batchworkers=0, # 加載數據線程數device='0', # 使用顯卡optimizer='SGD', # 優化器project='runs/train', # 模型保存路徑name=name, # 模型保存命名) -
修改
traindata.yaml文件, 打開traindata.yaml文件,如下所示:

在這里,只需修改 path 的值,其他的都不用改動(仔細看上面的黃色字體),我提供的數據集默認都是到yolo文件夾,設置到 yolo 這一級即可,修改完后,返回train.py中,執行train.py。 -
打開
train.py,右鍵執行。

-
出現如下類似的界面代表開始訓練了

-
訓練完后的模型保存在runs/train文件夾下

🌟 六、模型評估步驟
-
打開
val.py文件,如下圖所示:

-
修改
model_pt的值,是自己想要評估的模型路徑 -
修改
data_path,根據自己的實際情況修改,具體如何修改,查看上方模型訓練中的修改步驟 -
修改
model.val()中的參數,按照自己的需求和電腦硬件的情況更改model.val(data=data_path, # 數據集路徑imgsz=300, # 圖片大小,要和訓練時一樣batch=4, # batchworkers=0, # 加載數據線程數conf=0.001, # 設置檢測的最小置信度閾值。置信度低于此閾值的檢測將被丟棄。iou=0.6, # 設置非最大抑制 (NMS) 的交叉重疊 (IoU) 閾值。有助于減少重復檢測。device='0', # 使用顯卡project='runs/val', # 保存路徑name='exp', # 保存命名) -
修改完后,即可執行程序,出現如下截圖,代表成功(下圖是示例,具體以自己的實際項目為準。)

-
評估后的文件全部保存在在
runs/val/exp...文件夾下

🌟 七、訓練結果
我們每次訓練后,會在 run/train 文件夾下出現一系列的文件,如下圖所示:
? ?如果大家對于上面生成的這些內容(confusion_matrix.png、results.png等)不清楚是什么意思,可以在我的知識庫里查看這些指標的具體含義,示例截圖如下:

🌟八、完整代碼
? ?如果您希望獲取博文中提到的所有實現相關的完整資源文件(包括測試圖片、視頻、Python腳本、UI文件、訓練數據集、訓練代碼、界面代碼等),這些文件已被全部打包。以下是完整資源包的截圖:

您可以通過下方演示視頻的視頻簡介部分進行獲取
演示視頻:
47-基于深度學習的焊縫質量檢測識別系統-yolov8/yolov5-經典版界面
47-基于深度學習的焊縫質量檢測識別系統-yolo11-彩色版界面





)













