1 遷移學習概述
遷移學習(Transfer Learning)是機器學習中的一種方法,它允許模型將從一個任務中學到的知識應用到另一個相關的任務中。這種方法在數據稀缺的情況下尤為有用,因為它減少了對大量標記數據的需求。遷移學習已成為深度學習和人工智能領域的一個熱門話題。
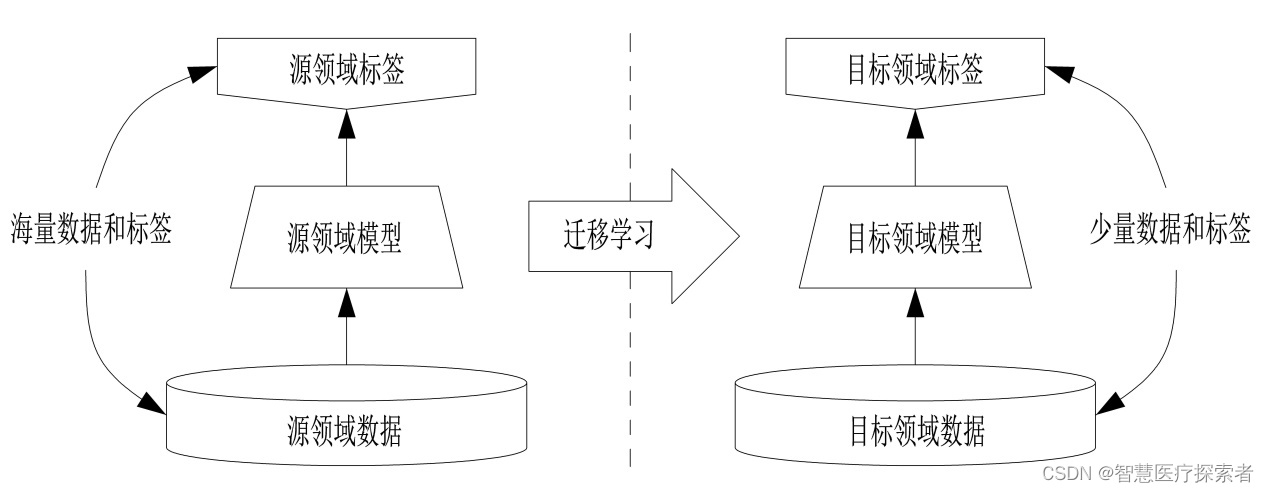
1.1 遷移學習的基本原理
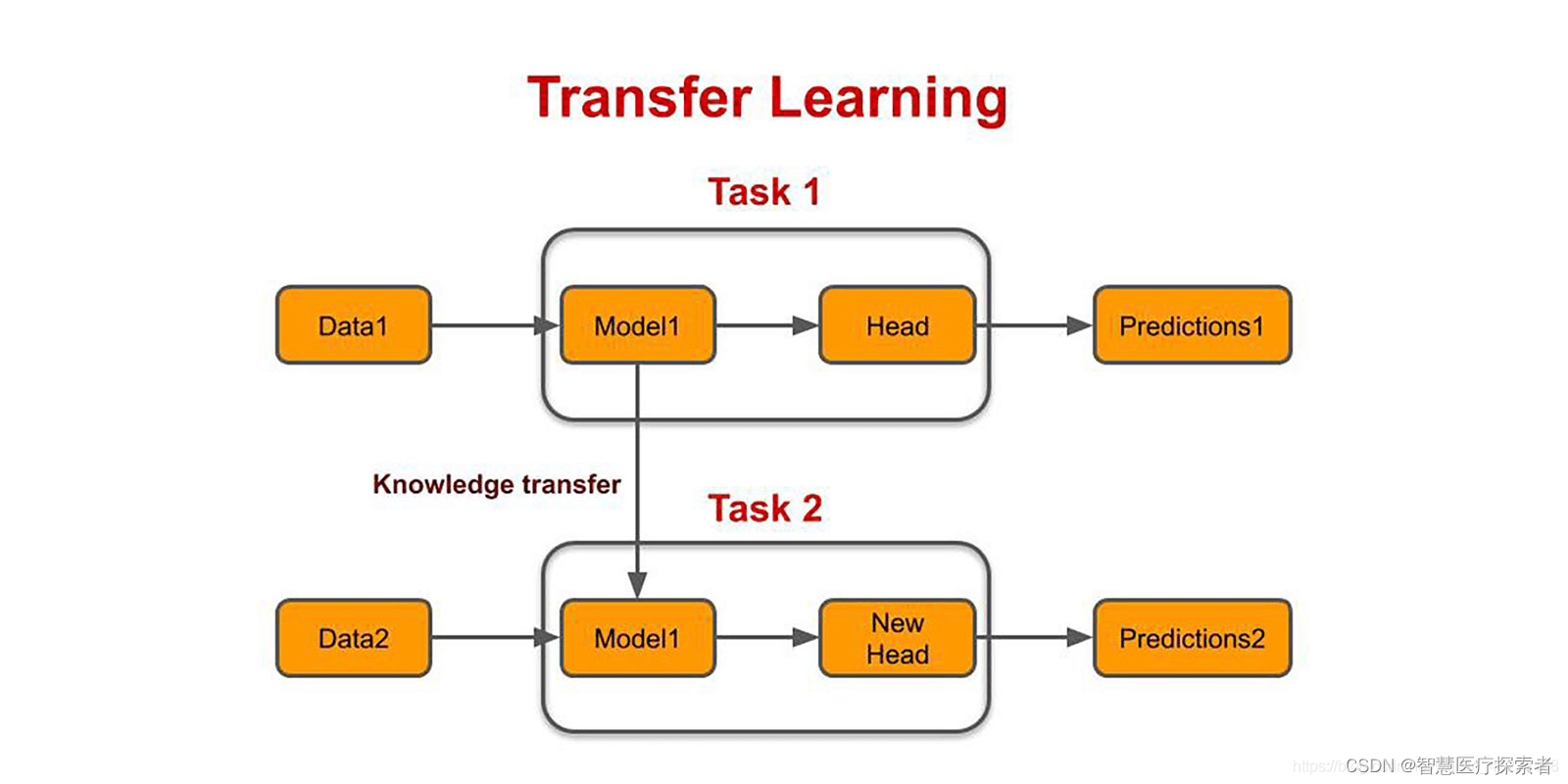
遷移學習的核心思想是:在一個任務上訓練得到的模型包含的知識可以部分或全部地轉移到另一個任務上。這通常涉及以下兩個主要步驟:
-
源任務學習: 在源任務上訓練模型,這個任務通常有大量的數據可用。
-
知識遷移: 將從源任務學到的知識(如網絡參數、特征表示等)應用到目標任務上。
1.2 遷移學習的類型
-
基于模型的遷移學習: 直接使用源任務的預訓練模型作為目標任務的起點。
-
基于特征的遷移學習: 從源任務中提取特征表示,然后在這些特征上訓練目標任務的模型。
-
基于關系的遷移學習: 從源任務中學習數據間的關系,然后將這種關系應用到目標任務中。
?
2 遷移學習的典型算法
遷移學習是一種在機器學習領域中越來越流行的方法,旨在利用在一個任務上學到的知識來提高在另一個相關任務上的學習效果。以下是一些遷移學習領域中的典型算法和方法:
2.1 微調(Fine-tuning)
-
基本概念: 微調是一種常見的遷移學習策略,涉及對預訓練模型的最后幾層進行重新訓練以適應新任務。
-
典型應用: 在深度學習中,比如使用在大型數據集(如ImageNet)上預訓練的卷積神經網絡(CNN)模型,然后對其進行微調以適應特定的圖像分類任務。
2.2 特征提取(Feature Extraction)
-
基本概念: 特征提取涉及使用預訓練模型的一部分(通常是除了最后的分類層之外的所有層)來作為新任務的特征提取器。
-
典型應用: 在圖像處理或自然語言處理任務中,提取通用特征后,可以在這些特征的基礎上訓練一個新的分類器或回歸器。
2.3 多任務學習(Multi-task Learning)
-
基本概念: 在多任務學習中,模型被同時訓練以執行多個相關任務,目的是通過這種聯合學習提高所有任務的性能。
-
典型應用: 在自然語言處理中,一個模型可能同時學習語言模型任務、文本分類任務和命名實體識別任務。
2.4 域自適應(Domain Adaptation)
-
基本概念: 域自適應關注于調整模型以便在源域學到的知識能適用于與之分布不同的目標域。
-
典型應用: 將在一個領域(如在線評論)訓練的情感分析模型調整到另一個領域(如微博)。
2.5 零樣本學習(Zero-shot Learning)
-
基本概念: 零樣本學習是指訓練模型以識別在訓練過程中未出現過的類別。
-
典型應用: 在圖像識別任務中,模型可以識別它在訓練集中從未見過的物體類別。
2.6 對抗性訓練(Adversarial Training)
-
基本概念: 利用對抗性網絡來訓練模型,使其在源域和目標域上都有良好的表現。
-
典型應用: 用于圖像風格轉換或在不同數據集上的圖像分類。
2.7 學習表示遷移(Representation Transfer)
-
基本概念: 側重于將從源任務中學到的表示(如權重、特征圖等)遷移到目標任務。
-
典型應用: 在深度學習模型中遷移學習不同層的權重。
2.8 元學習(Meta-learning)
-
基本概念: 也被稱為“學會學習”,元學習旨在通過學習多種任務來發展快速適應新任務的能力。
-
典型應用: 快速適應新的分類任務,如小樣本圖像識別。
?
3 遷移學習的優勢和挑戰
3.1 優勢
-
數據效率: 減少了對大量標記數據的需求,特別是在目標任務的數據稀缺時。
-
提高性能: 預訓練模型可以提高模型在特定任務上的性能。
-
節省時間: 減少了從頭開始訓練模型的時間。
3.2 挑戰
-
負遷移: 如果源任務和目標任務不夠相關,遷移學習可能導致性能下降。
-
領域適應: 需要有效的方法來處理源任務和目標任務之間的領域差異。
-
模型選擇: 如何選擇合適的源任務和模型結構仍然是一個開放的問題。
4 遷移學習的應用與未來
4.1 應用
遷移學習作為一種強大的機器學習策略,通過利用在一個任務上獲得的知識來加速和改進另一個任務的學習過程,為處理數據稀缺、提升模型性能、加速研發進程等問題提供了有效解決方案。已被廣泛應用于多個領域,提高了學習效率,減少了對大量標注數據的依賴。以下是遷移學習的一些主要應用領域:
-
計算機視覺
圖像分類: 使用在大規模數據集(如ImageNet)上預訓練的模型來提高小型數據集上的圖像分類性能。
物體檢測: 遷移學習用于訓練能夠在不同背景下識別特定物體的模型。
圖像分割: 在復雜的圖像分割任務中,遷移學習能提高模型對新環境的適應性。
-
自然語言處理(NLP)
情感分析: 將在大型文本數據集上訓練的模型應用于特定領域的情感分析任務。
機器翻譯: 使用遷移學習在有限的平行語料上提高翻譯質量。
文本分類: 在預訓練的語言模型上進行微調,用于特定類型文本的分類。
-
醫學影像分析
疾病診斷: 利用遷移學習提高在醫學圖像(如X射線、MRI)上的疾病診斷準確率。
影像分割: 應用于識別和分割醫學影像中的特定結構或區域。
-
語音識別
語音到文本: 在不同語言或口音的語音識別任務中應用遷移學習。
語音助手: 提高語音助手在不同環境下的理解和響應能力。
?
-
強化學習
游戲玩法: 在一種游戲中訓練的模型遷移到另一種類似游戲的學習中。
仿真到現實: 將在仿真環境中訓練的模型遷移到現實世界應用。
?
4.2 未來方向
遷移學習作為一種高效的機器學習方法,在近年來已經取得了顯著的進展。遷移學習的未來發展方向將集中在提高其泛化能力、自適應性、無監督學習能力,以及與元學習、其他學習范式的結合上。隨著技術的不斷發展,它的未來方向可能包括以下幾個關鍵領域:
-
更好的泛化能力
任務和領域泛化: 遷移學習將致力于更好地泛化到各種任務和領域,這意味著在一個領域學到的知識可以更有效地應用到其他領域。
跨模態學習: 開發能夠跨越不同數據模態(如文本、圖像、聲音)的遷移學習模型。
-
自適應遷移學習
動態遷移: 未來的遷移學習方法可能會更加動態和自適應,能夠根據目標任務的特定需求自動調整遷移策略。
環境感知: 模型能夠意識到環境變化并相應地調整遷移策略。
-
無監督和半監督遷移學習
減少標注數據依賴: 無監督和半監督的遷移學習方法將減少對大量標注數據的依賴,使得模型能在少量或無標簽數據的情況下進行有效學習。
利用未標記數據: 開發新的算法來更有效地利用未標記數據。
-
元學習(Meta-Learning)
“學會學習”: 元學習,或學會學習的方法,將成為遷移學習的一個重要方向。這種方法使得模型能夠快速適應新任務。
快速適應新任務: 開發能夠在極少樣本學習情況下快速適應新任務的模型。
-
解釋性和可信賴性
可解釋的遷移學習: 提高遷移學習模型的解釋性,使用戶能夠理解模型的決策過程。
提高可信賴性: 確保遷移學習在各種應用中的可靠性和魯棒性。
-
跨界集成
與其他學習范式結合: 將遷移學習與強化學習、聯邦學習等其他學習范式結合,發揮各自的優勢。
多學科融合: 結合認知科學、心理學等學科的理論和方法,以啟發遷移學習的新策略。
-
應用拓展
新領域應用: 將遷移學習應用于更廣泛的領域,如生物信息學、天體物理學等。
實際問題解決: 解決更多實際問題,如氣候變化預測、精準醫療等。
5 總結
遷移學習是解決數據稀缺、提高模型性能和加快訓練進程的有效方法。隨著機器學習和人工智能的不斷發展,遷移學習在許多領域都顯示出巨大的潛力。然而,如何有效地實施遷移學習、選擇合適的源任務和處理領域差異仍然是該領域的研究熱點。隨著技術的進步,預計遷移學習將在未來的人工智能應用中扮演更加重要的角色。
)



)
)



)





語法分析實驗(附完整C/C++代碼與測試))



