使用 NVProf 檢測 CUDA kernel 的 bank conflict
NVProf 指令
使用 NVProf 可以對 bank conflict 進行檢測:
nvprof --events shared_ld_bank_conflict,shared_st_bank_conflict <app> [args...]
其中:
--events選項指定的shared_ld_bank_conflict,shared_st_bank_conflict分別代指從 shared memory 加載(讀取)時產生的 bank conflict, 以及向 shared memory 存儲(寫入)時產生的 bank conflict.<app> [args...]即要檢測的 CUDA 二進制程序及其參數.
額外說明
值得一提的是, 如果沒有從 shared memory 讀取的指令, 且沒有使用 -G 編譯, 則兩種 bank conflict 事件都無法檢測出來, 即使存在向 shared memory 寫入產生的 bank conflict.
(沒有讀取的 bank conflict 很好理解, 因為都沒有從 shared memory 讀取數據; 而至于寫入的 bank conflict, 應該是編譯器做了一定的優化, 即 shared memory 雖被寫入但數據沒有被讀取, 則寫入是沒有意義的, 這部分代碼實際并不執行, 所有寫入的 bank conflict 就不會檢測到了.)
這個主要作用是, 當我們對自己寫的 kernel 的 bank conflict 進行檢測的時候, 要確保保留對 shared memory 讀取的相關代碼或設置 -G 編譯選項, 否則可能會影響 bank conflict 的檢測.
舉例
以下代碼是一個很簡單的 CUDA kernel 示例, 考慮到 bank conflict 是 warp 層面的問題, 所有 kernel 中我定義了 warp_id, land_id 等變量便于后續 bank conflict 的說明.
#include <iostream>
#include <cstdio>
#include <vector>
#include <cuda.h>using namespace std;constexpr int SIZE_A = 64;
constexpr int SIZE_C = 64;__global__ void kernel(const int* a, int* c) {auto tid = (blockIdx.x * blockDim.x + threadIdx.x);auto lane_id = threadIdx.x & 0x1F;auto warp_id = tid >> 5;auto warp_in_block = threadIdx.x >> 5;__shared__ int shm[SIZE_A];if (tid < SIZE_A) {shm[warp_id * 32 + lane_id] = a[warp_id * 32 + lane_id];}if (tid < SIZE_C) {c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];}
}int main() {vector<int> a(SIZE_A);for (int i = 0; i < SIZE_A; ++i) {a[i] = i;}int* d_a;cudaMalloc(&d_a, sizeof(int) * SIZE_A);cudaMemcpy(d_a, a.data(), sizeof(int) * SIZE_A, cudaMemcpyHostToDevice);int* d_c;cudaMalloc(&d_c, sizeof(int) * SIZE_C);cudaMemset(d_c, 0, sizeof(int) * SIZE_C);kernel<<<1, 128>>>(d_a, d_c);vector<int> c(SIZE_C);cudaMemcpy(c.data(), d_c, sizeof(int) * SIZE_C, cudaMemcpyDeviceToHost);for (auto x : c) {cout << x << " ";}cout << endl;cudaFree(d_c);cudaFree(d_a);return 0;
}
kernel() 函數完成的功能很簡單, 就是想數組 a 中的一部分數據先寫至 shared memory shm, 再寫入到 c 中. 在沒有額外說明時, 不使用 -G 選項編譯代碼.
很明顯的是, 由于 shm 的讀寫時, 每個 warp 的 32 個線程分片讀取不同的 4 字節數據, 因此代碼沒有 bank conflict.

使用上述 NVProf 指令檢測, 結果也印證了上述推斷.
現在將 Kernel 修改如下:
__global__ void kernel(const int* a, int* c) {auto tid = (blockIdx.x * blockDim.x + threadIdx.x);auto lane_id = threadIdx.x & 0x1F;auto warp_id = tid >> 5;auto warp_in_block = threadIdx.x >> 5;__shared__ int shm[SIZE_A];// if (tid < SIZE_A) {// shm[warp_id * 32 + lane_id] = a[warp_id * 32 + lane_id];// }for (auto i = threadIdx.x; i < SIZE_A; i += blockDim.x) {shm[(i % 2) * SIZE_A / 2 + i / 2] = a[i];}if (tid < SIZE_C) {c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];;}
}
我們在讀取 a 數組到 shared memory 的時候, 進行了一點修改. 可以看到, 對應相鄰的兩個線程, t 和 t+1 (假設 t % 2 ==0), 則一個寫入到 shm[t/2], 一個寫入到 shm[SIZE_A/2+(t+1)/2] 即 shm[32+t/2], 由于恰好差了 32 個元素, 因此會訪問到相同的 bank, 會觸發 bank conflict. 通過 NVProf 檢測也得到了證實:

這里的 2 次, 原因筆者猜測為 SIZE_A 大小為 64, 對應 2 個 warp, 每個 warp 相鄰的奇數線程和偶數線程訪問同一 bank, 以 warp 為單位, 每個 warp 產生 1 個 bank conflict, 共 2 個.
但如果我們將后面將 shm 寫入 c 數組的代碼注釋掉, 即沒有從 shared memory 讀取的代碼, 則可以看到 NVProf 并不會檢測到剛剛的 shared_st_bank_conflict.
if (tid < SIZE_C) {c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];;}

但如果我們在編譯的時候使用 -G 選項, 則可以看到剛剛的 shared_st_bank_conflict 有可以被檢測到了:
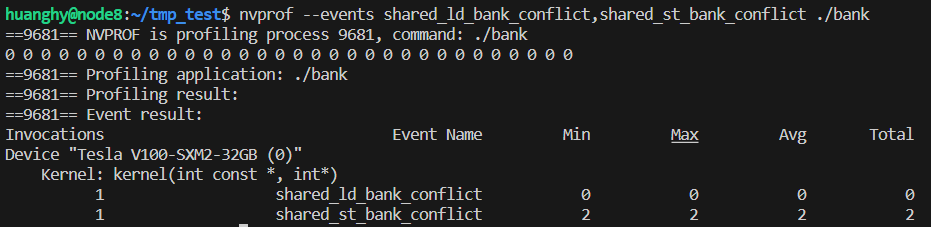
因此, 可以推斷出, 在默認情況下, 編譯器對于不讀取的 shared memory 的寫入操作會進行優化, 實際上并不會執行 shared memory 的寫入操作, 而 debug 模式 (帶 -G 選項)時, 則不會進行該優化.
如下代碼展示了在從 shared memory shm 讀取到 c 數組時的 bank conflict.
constexpr int SIZE_A = 64;
constexpr int SIZE_C = 32;__global__ void kernel(const int* a, int* c) {auto tid = (blockIdx.x * blockDim.x + threadIdx.x);auto lane_id = threadIdx.x & 0x1F;auto warp_id = tid >> 5;auto warp_in_block = threadIdx.x >> 5;__shared__ int shm[SIZE_A];if (tid < SIZE_A) {shm[warp_id * 32 + lane_id] = a[warp_id * 32 + lane_id];}if (tid < SIZE_C) {// c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];c[warp_id * 32 + lane_id] =shm[warp_in_block * 32 + lane_id / 8 + (lane_id % 2) * 32];}
}
可以看到, 相鄰的 8 個線程分奇偶訪問同一 bank 的兩個地址. NVProf 輸出如下:
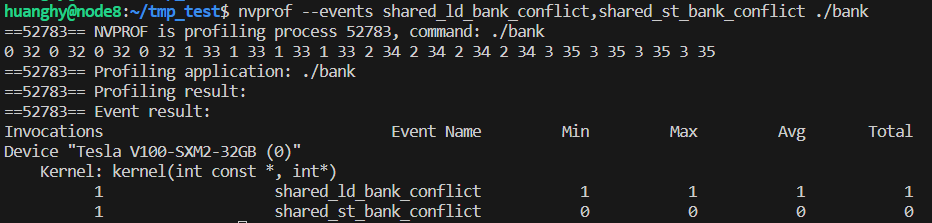

















)

應用開發——安裝DevEco Studio安裝)