
一、輸入部分介紹
輸入部分包含:
-
編碼器源文本嵌入層及其位置編碼器
-
解碼器目標文本嵌入層及其位置編碼器
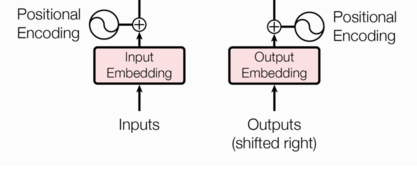
在transformer的encoder和decoder的輸入層中,使用了Positional Encoding,使得最終的輸入滿足:
![]()
這里,input_embedding是通過常規embedding層,將每一個詞的向量維度從vocab_size映射到d_model,由于是相加關系,自然而然地,這里的positional_encoding也是一個d_model維度的向量。(在原論文里,d_model=512)
二、文本嵌入層
文本嵌入層(Text Embedding Layer)是深度學習模型中將文本(通常是單詞或句子)轉換為固定大小的向量表示的一個關鍵層。它的目標是將每個文本單元(如單詞或子詞)映射到一個高維空間中,以便模型能夠更好地捕捉到詞匯的語義信息和語法信息。
無論是源文本嵌入還是目標文本嵌入,都是為了將文本中詞匯的數字表示轉變為向量表示, 希望在這樣的高維空間捕捉詞匯間的關系。常見的詞嵌入方法包括:Word2Vec, GloVe, FastText, 以及可學習的embedding層。
nn.Embedding演示:
Python
embedding = nn.Embedding(num_embeddings=10, embedding_dim=3)
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
print(embedding(input))
# padding_idx: 指定用于填充的索引。如果設置為0,則索引為0的輸入將始終映射到一個全零向量,并且在反向傳播時不會更新該嵌入。
# 全零向量:padding_idx 指定的索引(如0)會被映射到一個全零向量。
# 不更新梯度:在訓練過程中,padding_idx 對應的嵌入向量不會被更新。
# 用途:常用于處理變長序列的填充部分,避免填充部分對模型訓練產生影響。
embedding = nn.Embedding(num_embeddings=10, embedding_dim=3, padding_idx=0)
input = torch.LongTensor([[0, 2, 0, 5]])
print(embedding(input))
輸出結果:
Python
tensor([[[-1.0378, 0.0594, 2.6601],
[ 1.0423, -0.4094, 0.3436],
[-1.8989, 1.3664, -0.3701],
[ 0.3930, 0.9908, 1.5700]],
[[-1.8989, 1.3664, -0.3701],
[ 0.3479, -0.2118, -0.1244],
[ 1.0423, -0.4094, 0.3436],
[ 0.4161, 0.4799, -0.4094]]], grad_fn=<EmbeddingBackward0>)
tensor([[[ 0.0000, 0.0000, 0.0000],
[-0.3378, 1.1013, -1.7552],
[ 0.0000, 0.0000, 0.0000],
[ 0.9153, 0.3548, 2.1857]]], grad_fn=<EmbeddingBackward0>)
文本嵌入層的代碼實現:
Python
# 導入必備的工具包
import torch
# 預定義的網絡層torch.nn, 工具開發者已經幫助我們開發好的一些常用層,
# 比如,卷積層, lstm層, embedding層等, 不需要我們再重新造輪子.
import torch.nn as nn
# 數學計算工具包
import math
# Embeddings類 實現思路分析
# 1 init函數 (self, d_model, vocab)
# 設置類屬性 定義詞嵌入層 self.lut層
# 2 forward(x)函數
# self.lut(x) * math.sqrt(self.d_model)







)

)








安全保障機制(技術、標準、管理))
