摘要
背景與問題
大語言模型出色的生成能力引發了倫理與法律層面的擔憂,于是通過嵌入水印來檢測機器生成文本的方法逐漸發展起來。但現有工作在代碼生成任務中無法良好發揮作用,原因在于代碼生成任務本身的特性(代碼有其特定的語法、邏輯結構,與一般自然文本生成規律不同,現有水印方法適配性不足),具體表現為對代碼質量的保留效果差。
通過擴展了 “修改對數(logit - modifying)” 的水印方法,提出了 “通過熵閾值選擇的水印(Selective WatErmarking via Entropy Thresholding,SWEET)”。其核心思路是:在生成和檢測水印時,移除低熵的代碼片段。低熵通常意味著內容更具確定性、規律性(比如代碼中重復的結構、固定的語法模板等),移除這類片段有助于讓水印更貼合代碼生成的特點,減少對代碼正常邏輯和質量的干擾。
第一章 引言

圖1
大語言模型(LLMs)在代碼生成領域的表現,正以驚人速度向專家水準靠攏。從提升軟件工程師的生產效率,到降低非專業人士編程的門檻,它帶來的便利有目共睹。但就像一枚硬幣有正反兩面,大模型在代碼領域的飛速發展,也帶來了一系列法律、倫理和安全方面的 “暗礁”。代碼許可爭議、剽竊問題、漏洞隱患,還有惡意軟件生成等,都讓人們憂心忡忡。比如,一群個人和微軟、GitHub、OpenAI 之間,就因涉嫌非法使用與復制源代碼,陷入了一場版權集體訴訟。更讓人警惕的是,ChatGPT 推出后不久,暗網上就有不少惡意分子分享機器生成的惡意軟件和魚叉式網絡釣魚教程。
在這樣的背景下,開發能檢測機器生成代碼的可靠工具,就成了迫在眉睫且意義重大的事,這對公平部署具備編碼能力的大語言模型來說,是關鍵一步。而像論文里提到的 “SWEET(通過熵閾值選擇的水印)” 這類技術,就是探索解決之道的嘗試。它致力于在保證代碼質量的同時,有效檢測出機器生成的代碼,為代碼生成領域的知識產權保護、安全規范等,提供更有力的技術支撐,助力大模型在代碼世界里更健康地發展。
盡管機器生成代碼的檢測問題亟待解決,但目前針對該問題的研究成果寥寥。相反,眾多研究仍將重點放在普通文本的檢測問題上(引用了 Solaiman 等人 2019 年、Ippolito 等人 2020 年等諸多相關研究)。
雖然這些 “事后檢測” 方法(即在文本生成過程中不進行控制)在自然語言處理的眾多領域展現出了強大的性能,但它們在編程語言領域的應用仍未得到充分探索。簡單來說,就是現在大家更關注普通文本的檢測,而機器生成代碼的檢測研究很缺,而且那些適用于普通文本的事后檢測方法,在代碼領域還沒怎么被研究過能不能用。
與 “事后檢測” 方法不同,另一種用于檢測機器生成文本的研究方向受到了關注:基于水印的方法。這類方法會在生成的文本中嵌入隱藏信號(引用了 Kirchenbauer 等人 2023a、b;Kuditipudi 等人 2023;Wang 等人 2023 的研究)。
以 Kirchenbauer 等人(2023a)提出的一種方法為例(我們稱之為 WLLM,即大語言模型水印法):在每一個生成步驟中,它會將整個詞匯表隨機分成兩組(即 “綠色列表” 和 “紅色列表”),并提高從綠色列表中選取標記(tokens)的概率。具體來說,通過給綠色列表標記的對數概率(logits)添加標量值,模型會更傾向于生成綠色列表中的標記,而非紅色列表里的。要檢測文本中的水印,我們需要統計綠色標記的數量,然后通過假設檢驗來判斷這個數量是否具有統計顯著性,從而推斷出模型輸出是否是在不了解 “綠 - 紅規則” 的情況下生成的。
雖然基于水印的方法和事后檢測方法在許多語言生成任務中都能很好地發揮作用,但我們觀察到,這些性能在代碼生成任務中并不能很好地遷移,比如在圖 1 中就有體現。換句話說,以一種可檢測的方式嵌入水印,同時又不損害代碼功能,要困難得多。我們將此歸因于代碼生成熵極低的特性。
如果強力應用水印,會嚴重降低模型輸出的質量,這在代碼生成中尤為關鍵,因為哪怕違反一條規則,都可能使整個代碼崩潰(見圖 1 中的 “強水印”)。另一方面,如果水印應用得太弱,低熵會阻礙水印的恰當嵌入,導致綠色標記出現不足,進而增加檢測難度(見圖 1 中的 “弱水印”)。這些問題在普通文本生成中并不顯著,因為相對較高的熵讓水印候選選擇更具靈活性。
1.1方法提出與優勢
為了解決這些失效模式,我們擴展了 WLLM,并為代碼大語言模型(以及通用大語言模型)提出了通過熵閾值選擇的水印方法(Selective WatErmarking via Entropy Thresholding,SWEET)。不再對生成過程中的每個標記都應用 “綠 - 紅” 規則,而是僅對熵足夠高(基于設定的閾值)的標記應用該規則(這是與KGW方法的最大區別)。也就是說,我們不對那些對實現代碼功能至關重要的標記應用 “綠 - 紅” 規則,同時確保有足夠多的綠色列表標記,以便為不太重要的標記生成可檢測的水印,從而直接解決上述每種失效模式。在代碼生成任務中,我們的方法在檢測機器生成代碼方面超越了所有基準方法(包括事后檢測方法),同時實現的代碼質量下降程度比 WLLM 更小。此外,通過各種分析,我們證明即使在沒有提示詞,或者使用小型替代模型的情況下,我們的方法也能很好地運行,這表明它在實際場景中具有魯棒性。
1.2研究貢獻
我們的貢獻如下:
- 我們是首個通過實證探索現有水印和事后檢測方法在代碼領域失效情況的研究。
- 我們提出了一種簡單卻有效的方法,名為 SWEET,它改進了 WLLM(Kirchenbauer 等人,2023),在機器生成代碼檢測方面實現了顯著更高的性能,同時比 WLLM 更好地保留了代碼質量。
- 我們已經證明了我們的方法在現實場景中的實用性和優越性,例如:1)不使用提示詞;2)使用更小的模型作為檢測器;3)面對改寫攻擊時。
第二章?相關工作
2.1軟件水印(Software Watermarking)
軟件水印是一個研究領域,旨在在不影響代碼性能的前提下,將秘密信號嵌入代碼中,以防止軟件盜版。
- 靜態水印(Static watermarking)(Hamilton and Danicic, 2011;Li and Liu, 2010;Myles et al., 2005):通常通過代碼替換和重新排序的方式來嵌入水印。
- 動態水印(Dynamic watermarking)(Wang et al., 2018;Ma et al., 2019):則是在程序的編譯或執行階段注入水印。(若需詳細綜述,可參考 Dey et al., 2018)。
從大語言模型(LLM)生成的代碼文本中嵌入水印,與靜態水印更為接近。例如,Li 等人(2023c)提出了一種使用同義代碼替換的方法。不過,由于這種方法嚴重依賴特定語言的規則,惡意用戶一旦知曉這些規則,就可能逆向破解水印。
2.2大語言模型文本水印(LLM Text Watermarking)
大多數針對大語言模型(LLM)生成文本的水印方法,都是基于通過預先定義的規則集合(Atallah et al., 2001, 2002;Kim et al., 2003;Topkara et al., 2006;Jalil and Mirza, 2009;Meral et al., 2009;He et al., 2022a,b),或者另一個語言模型(比如基于 Transformer 的網絡,Abdelnabi and Fritz, 2021;Yang et al., 2022;Yoo et al., 2023)來修改原始文本。
近來,有一類研究工作聚焦于在 LLM 的采樣過程中,將水印嵌入到標記(tokens)里(Liu et al., 2024)。它們通過兩種方式在 LLM 生成的文本中嵌入水印:一是修改來自 LLM 的對數概率(logits)(Kirchenbauer et al., 2023a,b;Liu et al., 2023a;Takezawa et al., 2023;Hu et al., 2023);二是操控采樣過程(Christ et al., 2023;Kuditipudi et al., 2023)。此外,一些近期的研究關注水印對抗攻擊的魯棒性,即抵御移除水印的攻擊(Zhao et al., 2023;Liu et al., 2023b;Ren et al., 2023)。最后,Gu 等人(2023)研究了水印在從教師模型到學生模型的蒸餾過程中的可學習性。
然而,這些水印方法在低熵場景下,水印檢測性能會出現脆弱性(Kirchenbauer et al., 2023a;Kuditipudi et al., 2023),僅有少數研究(如 CTWL,Wang et al., 2023)試圖解決這一問題。我們直接針對低熵情況下水印檢測性能下降的問題,并在低熵任務(如代碼生成)中證明了我們方法的有效性。
2.3事后檢測(Post - hoc Detection)
事后檢測方法的目標是在生成過程中不嵌入任何信號的情況下,區分出人類創作的文本和機器生成的文本。
其中一條研究路線是利用基于困惑度的特征,像 GPTZero(Tian 和 Cui,2023)、Sniffer(Li 等人,2023a)以及 LLMDet(Wu 等人,2023)都屬于這類。另一條研究路線則是使用預訓練的語言模型,例如 RoBERTa(Liu 等人,2019),并對其進行微調,將其作為分類器來識別文本來源(Solaiman 等人,2019;Ippolito 等人,2020;OpenAI,2023b;Guo 等人,2023;Yu 等人,2023;Mitrovi?等人,2023)。
與此同時,一些近期的研究在沒有額外訓練流程的情況下解決檢測問題,比如 GLTR(Gehrmann 等人,2019)、DetectGPT(Mitchell 等人,2023)以及 DNA - GPT(Yang 等人,2023)。不過,事后檢測方法仍然面臨挑戰。例如,雖然 GPTZero(Tian 和 Cui,2023)仍在使用,但 OpenAI 的 AI 文本分類器(OpenAI,2023b)在推出僅六個月后就因準確率問題停止使用了。此外,我們已經證明,事后檢測方法在檢測低熵的機器生成代碼時是失敗的。
第三章 方法(Method)
我們提出了一種新的水印方法 ——SWEET,它僅對熵足夠高的標記(tokens)進行選擇性水印嵌入。
3.1 動機(Motivation)
盡管之前的水印方法 WLLM(Kirchenbauer 等人,2023a)可以應用于大語言模型(LLM)生成文本的任何領域,但在代碼生成中進行水印嵌入和檢測時,會引發兩個關鍵問題,這歸因于水印強度方面的困境。
水印會導致性能下降。在編程語言中,表達相同含義的方式僅有少數幾種,而且一個錯誤的標記就可能導致不理想的輸出。如果像 WLLM 那樣強力嵌入水印(WLLM 會在不利用任何上下文信息的情況下,隨機將詞匯表分為綠色和紅色列表,只提升綠色列表標記的對數概率),必然會增加生成錯誤標記的可能性。例如,在圖 2(a)中,第二行的 “return” 標記之后,對數概率最高的下一個標記是 “sum”,這也是標準解決方案的一部分。但 WLLM 把 “sum” 放到了紅色列表,而把 “mean” 放到了綠色列表。因此,采樣到的標記是 “mean”,從而導致了語法錯誤。

圖2
3.2圖2解析:
- 問題與標準解法:左側呈現了 HumanEval/4 的問題(要求實現計算平均絕對偏差的函數)以及標準的正確解法。
- 不同方法的代碼生成與指標:
- (a)WLLM:生成的代碼存在錯誤(Correctness 為 ×),水印可檢測性低(z - score 僅 2.45,水印嵌入比例 1.0)。代碼里錯誤地使用了
mean相關操作,偏離了標準解法中基于sum計算均值的邏輯。 - (b)SWEET - 低熵閾值:生成的代碼仍錯誤(Correctness 為 ×),雖 z - score 提升到 3.39,但水印嵌入比例降至 0.44,代碼質量未得到有效改善。
- (c)SWEET - 中等熵閾值:生成的代碼正確(Correctness 為√),z - score 達到峰值 4.96,水印嵌入比例 0.20。代碼邏輯貼合標準解法,通過合理的變量定義(如
distances列表)和計算步驟,實現了平均絕對偏差的正確計算。 - (d)SWEET - 高熵閾值:代碼正確(Correctness 為√),z - score 為 4.67,水印嵌入比例 0.19。代碼邏輯同樣正確,但相比中等熵閾值,z - score 有所下降。
- (a)WLLM:生成的代碼存在錯誤(Correctness 為 ×),水印可檢測性低(z - score 僅 2.45,水印嵌入比例 1.0)。代碼里錯誤地使用了
3.3低熵序列會避免被加水印。
另一個關鍵問題是,當水印強度過弱,無法在低熵文本中嵌入水印時,若紅色列表的標記具有極高的對數概率(logit)值,以至于必然會被生成,就會阻礙水印檢測。例如,在圖 2(a)中,帶有白色背景的標記代表低熵且幾乎沒有候選標記。這在代碼生成任務中會變得更為致命,因為代碼生成的結果相對普通文本更短,比如只要求生成一個函數的代碼塊?。WLLM 的檢測方法基于統計檢驗,涉及統計整個長度內綠色列表標記的數量。然而,如果文本長度較短,基于統計檢驗的水印檢測效果就會下降?。
3.4SWEET 方法
SWEET 能夠通過區分可應用水印的標記,緩解水印強度方面的困境,也就是說,我們僅在熵高的標記中嵌入和檢測水印。
生成階段:我們方法的生成步驟如算法 1 所示。給定一個分詞后的提示以及已生成的標記
,模型會計算
的概率分布的熵值
。然后,只有當
高于閾值τ時,我們才應用水印。我們以固定的綠色標記比例
,將詞匯表隨機分為綠色和紅色兩類。如果一個標記被選中進行水印嵌入,我們就給綠色標記的對數概率(logits)加上一個常數
,目的是促進綠色標記的采樣。通過僅對高熵的標記促進綠色標記的采樣,我們防止了模型對其有信心(因此熵低)的標記的對數概率分布發生變化,從而保留了代碼質量。
具體說明:
假設我們要生成一個計算數組元素和的 Java 方法,以此具體展示 SWEET 方法的生成階段:
初始狀態
- 提示詞分詞后
:
["Write", "a", "Java", "method", "to", "calculate", "the", "sum", "of", "an", "array", "of", "integers", "."] - 已生成標記
:
["public", "static", "int", "sumArray", "(", "int", "[", "nums", "]"]
- 提示詞分詞后
計算下一個標記的熵值
- 模型預測下一個標記時,候選可能有?
{")", ":", "{\n", "//"} - 這些候選標記的概率分布比較分散(比如各占 20% - 30% 左右),計算得到熵值
,假設閾值
,由于
,觸發水印嵌入。
- 模型預測下一個標記時,候選可能有?
應用水印機制
- 設定綠色標記比例
,隨機將詞匯表分為綠色列表(如?
{")", "{\n"})和紅色列表(如?{":", "//"})。 - 給綠色列表標記的對數概率增加
,調整后:
- 原概率:
")": 25%,?"{\n": 20%,?":": 30%,?"//": 25%。 - 調整后概率:
")": 38%,?"{\n": 32%,?":": 20%,?"//": 10%。
- 原概率:
- 設定綠色標記比例
采樣生成下一個標記
- 最終采樣到綠色列表中的
")",已生成標記更新為["public", "static", "int", "sumArray", "(", "int", "[", "nums", "]", ")"]。
- 最終采樣到綠色列表中的
繼續生成后續標記
- 當下一個預測標記為
"{"時,模型對這個方法體開始的大括號標記的概率預測高達 90%,計算得到,不應用水印。
- 直接按照原概率分布采樣,保留
"{"這一低熵但關鍵的語法標記。
- 當下一個預測標記為
通過這樣的過程,SWEET 只在")"這類高熵標記上嵌入水印,既確保了"public"、"{"等低熵關鍵標記的生成質量,又通過對綠色列表標記的選擇性增強實現了水印嵌入。
3.5檢測(Detection)
我們在算法 2 中概述了檢測過程。給定一個標記序列,標記序列:就是大模型生成的代碼,我們的任務是檢測
中是否存在水印,從而確定它是否由特定的語言模型生成。與生成階段類似,我們為每個
計算熵值
。令
表示熵值
高于閾值τ的標記數量,令
表示在
中綠色標記的數量。最后,利用生成步驟中使用的整個詞匯表的綠色列表比例
,在文本未被水印嵌入的零假設下,計算z分數:
z分數越高,我們就越有信心認為文本被嵌入了水印。我們將設為臨界分數。如果
成立,我們就判定水印被嵌入到
中,因此該文本是由大語言模型(LLM)生成的。檢測階段中熵閾值的影響將在后續章節中描述。
具體說明:
假設我們有一段生成的 Java 代碼標記序列\(\boldsymbol{y}\),用于實現計算數組元素和的功能,來具體說明檢測過程:
步驟 1:確定標記序列
標記序列為:
["public", "static", "int", "sumArray", "(", "int", "[", "nums", "]", ")", "{", "int", "sum", "=", "0", ";", "for", "(", "int", "i", "=", "0", ";", "i", "<", "nums", ".", "length", ";", "i++", ")", "{", "sum", "+", "=", "nums", "[", "i", "]", ";", "}", "return", "sum", ";", "}"]
步驟 2:計算每個標記的熵值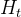 并統計相關數量
并統計相關數量
- 對序列中每個標記
計算熵值
- 熵值
的標記(即
對應的標記)有:
"sumArray",?"sum",?"length",?"i++",?"return",共個。
- 在這
對應的標記)有:
"sumArray",?"sum",?"return",共個。
- 熵值
步驟 3:設定綠色列表比例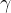 并計算z分數
并計算z分數
- 假設生成步驟中使用的整個詞匯表的綠色列表比例
。
- 根據公式
,代入
步驟 4:與臨界分數比較判定結果
- 假設設定的臨界分數
常見的統計臨界值,對應 90% 置信水平單側檢驗)。
- 由于計算得到的
,所以判定這段代碼序列
沒有被嵌入該方法對應的水印,即不認為是由特定大語言模型生成的(當然,實際情況中若z大于臨界值則判定為是)。
3.6?熵閾值的影響(Effect of Entropy Thresholding)
本節將展示,基于熵閾值的選擇性水印檢測能夠提高可檢測性。
定理 1 表明,與 WLLM 相比,通過 SWEET 檢測方法,我們能夠確保z分數有更高的下限。這是通過忽略低熵的標記來實現的,這會提高文本中綠色標記的比例,進而提升可檢測性。為了進行理論分析,我們使用了尖峰熵(公式 4),它是 Kirchenbauer 等人(2023a)中定義的熵的一個變體。在實際應用中,我們使用公式 5 中的熵。
定理 1
考慮由帶水印的代碼大語言模型(LLM)生成的標記序列。
是對應的尖峰熵序列,其中模量為
。令
為熵閾值,
和
分別為尖峰熵低于或高于該閾值的標記數量。
若關于低熵標記比例的如下假設成立:那么,當應用熵閾值時,z分數始終存在一個更高的下限。其中,
,
,且
(1為指示函數,滿足條件時取 1,否則取 0)。
注記:該假設意味著,選擇一個不會忽略過多標記的熵閾值十分重要。
第四章 實驗
我們開展了一系列實驗,從兩個方面評估我們的水印方法在代碼生成任務中的有效性:(i)質量保持能力;(ii)檢測強度。我們的基礎模型是 StarCoder(Li 等人,2023b),它是一款專門用于代碼生成的開源大語言模型(LLM)。我們還在一款通用大語言模型 LLaMA2(Touvron 等人,2023)上進行了實驗(實驗結果見附錄 F)。
4.1 任務與指標(Tasks and Metrics)
我們選取了三項 Python 代碼生成任務,即 HumanEval(Chen 等人,2021)、MBPP(Austin 等人,2021)和 DS - 1000(Lai 等人,2023),作為主要的測試平臺。這些任務包含 Python 編程問題、測試用例以及人類編寫的標準答案。大語言模型會被給予編程問題提示,并需要生成能通過測試用例的正確代碼。為了在更多樣化的軟件開發場景(如其他語言或其他代碼生成范圍)中評估我們方法的性能,我們還納入了另外兩個數據集:HumanEvalPack(Muenighoff 等人,2024)和 ClassEval(Du 等人,2023)。有關這些基準測試的實現細節,請參考附錄 E。
為了評估生成的源代碼的功能質量,我們使用 pass@k(Chen 等人,2021)指標,即對于每個編程問題,生成個輸出。該指標用于估計生成的代碼中能正確運行的比例。對于檢測能力,我們使用 AUROC(即 ROC 曲線下面積)值作為主要指標。我們還報告了當假陽性率(FPR;將人類編寫的代碼錯誤檢測為大語言模型生成的代碼)被限制在低于 5% 時的真陽性率(TPR;將大語言模型生成的代碼正確檢測為大語言模型生成的代碼)。這是為了觀察實際場景下的檢測比例,在實際場景中,高假陽性比假陰性更不受歡迎。
4.2 基準方法(Baselines)
我們將 SWEET 與機器生成文本檢測的基準方法進行對比。事后檢測基準方法在生成過程中無需任何修改,因此絕不會損害模型輸出的質量。LOGP (X)、LOGRANK(Gehrmann 等人,2019)和 DETECTGPT(Mitchell 等人,2023)是零樣本檢測方法,不需要帶標簽的數據集。GPTZERO(Tian 和 Cui,2023)和 OPENAI CLASSIFIER(Solaiman 等人,2019)是經過訓練的分類器。對于基于水印的方法,我們納入了兩個基準:WLLM(Kirchenbauer 等人,2023a)和 EXP - EDIT(Kuditipudi 等人,2023)。為了嵌入水印,像 WLLM 或我們的方法這類會扭曲模型采樣分布的方法,往往具有更好的檢測能力,但可能會導致文本質量下降。另一方面,EXP - EDIT 預計不會造成文本質量下降,因為它們不會扭曲模型的采樣分布?。更多實現細節見附錄 D。
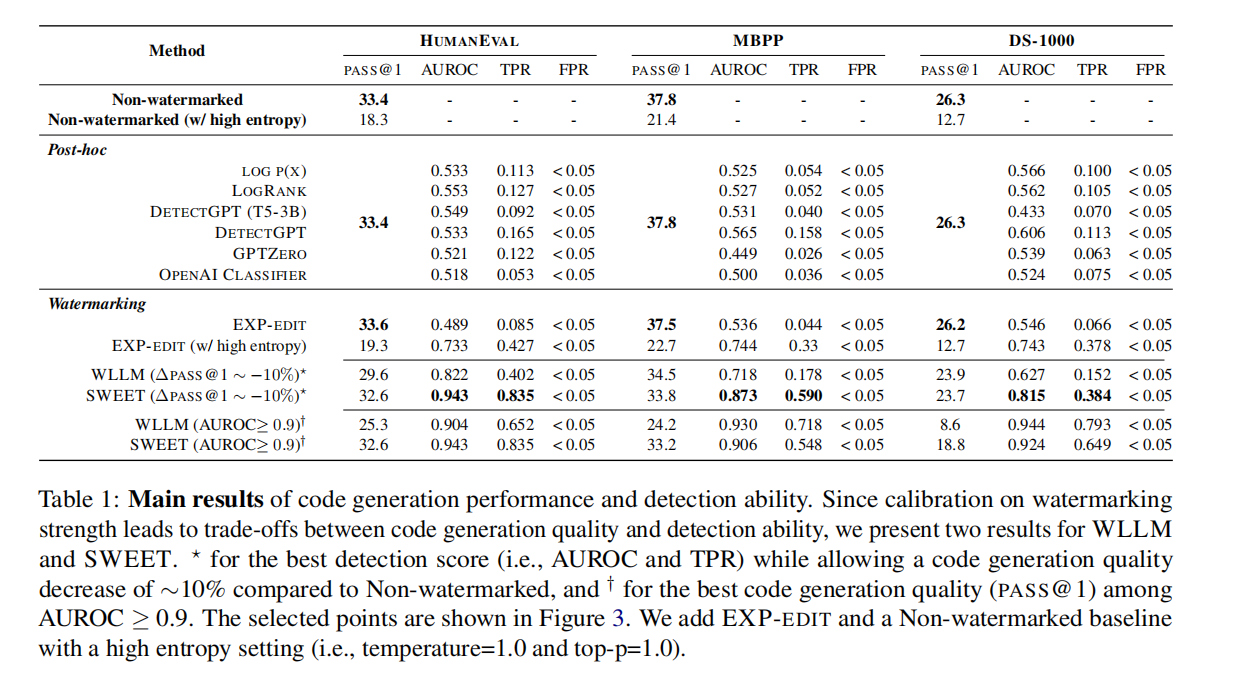
表1
表1解釋:
先明確兩個核心評價維度
- 代碼生成質量:用 “PASS@1” 表示,數值越高越好。意思是 “生成 1 份代碼,能通過測試用例的概率”(比如 33.4 表示 33.4% 的概率正確)。
- 檢測能力:
- “AUROC”:數值越接近 1 越好,反映 “能否準確區分機器生成代碼和人類代碼” 的整體能力(0.9 以上算優秀)。
- “TPR@FPR=5%”:在 “錯誤把人類代碼當成機器生成” 的概率≤5% 時,“正確識別機器生成代碼” 的概率,數值越高越好。
不同方法的表現對比
1. 無水印方法(作為基準)
- “Non-watermarked”:正常生成代碼,不加水印。
- 優點:代碼質量最高(PASS@1 在三個任務中分別是 33.4、37.8、26.3)。
- 缺點:無法檢測(因為沒水印)。
- “Non-watermarked (w/high entropy)”:故意讓生成更隨機(高熵)。
- 結果:代碼質量下降明顯(PASS@1 變低),也沒法檢測。
2. 事后檢測方法(生成時不修改代碼,事后判斷)
- 包括 LOGP (X)、LOGRANK、DETECTGPT 等。
- 優點:代碼質量和 “無水印” 一樣(因為生成時沒動過)。
- 缺點:檢測能力弱(AUROC 大多低于 0.8,TPR 也低),很難準確認出機器生成的代碼。
3. 基于水印的方法(生成時嵌入水印,方便后續檢測)
EXP-EDIT:嵌入水印但不影響代碼生成的選擇。
- 特點:代碼質量接近無水印,但檢測能力差(AUROC 低);如果強行提高檢測能力(高熵設置),代碼質量會暴跌。
WLLM(傳統水印方法):
- 帶
:為了提高檢測能力,犧牲代碼質量(比無水印下降約 10%),但檢測效果仍一般。
- 帶?:要求檢測能力達標(AUROC≥0.9),但代碼質量下降更多,且正確識別率(TPR)較低。
- 帶
SWEET(本文方法):
- 帶*:同樣允許代碼質量下降約 10%,但檢測能力顯著優于 WLLM(AUROC 達 0.943、0.873 等,TPR 更高)。
- 帶?:在保證檢測能力達標(AUROC≥0.9)的前提下,代碼質量比 WLLM 更好,正確識別率也更高。
第一大列:HumanEval
包含經典的 Python 編程問題(如函數實現、算法題),側重基礎編程能力的測試。比如 “實現計算斐波那契數列的函數” 這類類問題。第二大列:MBPP
以 “自然語言描述 + 測試用例” 的形式呈現,更貼近實際開發中 “根據需求寫代碼” 的場景,問題更偏向實用功能(如 “寫一個函數統計字符串中單詞出現次數”)。第三大列:DS-1000
專注于數據科學領域的代碼生成(如使用 NumPy、Pandas 處理數據),問題更專業,對領域知識要求更高(如 “用 Pandas 計算 DataFrame 中某列的均值”)。
結論
SWEET 在 “生成高質量代碼” 和 “準確檢測機器生成代碼” 之間找到了更好的平衡 —— 要么在相同代碼質量下檢測更準,要么在相同檢測能力下代碼質量更高,明顯優于其他方法
第五章 結果(Results)
5.1 主要結果(Main Results)
表 1 呈現了所有基準方法和我們方法的結果。在 WLLM 和 SWEET 中,根據水印強度的不同,檢測能力和代碼生成能力之間存在明顯的權衡。因此,我們在為一個領域的分數設定最大值的同時,為其他領域的分數設定下限。具體而言,為了衡量 AUROC 分數,我們在無水印基礎模型約 90% 的 pass@1 性能附近尋找最佳 AUROC 分數。另一方面,為了衡量 pass@1,我們從 AUROC 為 0.9 或更高的結果中進行選擇。
檢測性能:表 1 顯示,總體而言,我們的 SWEET 方法在檢測機器生成代碼方面優于所有基準方法,代價是代碼功能性下降 10%。在 MBPP 和 DS - 1000 數據集上,SWEET 分別實現了 0.873 和 0.815 的 AUROC,而所有基準方法的 AUROC 均未超過 0.8。在 HumanEval 上,SWEET 甚至實現了 0.943 的 AUROC,且代碼功能性僅下降 2.4%。然而,當僅允許代碼功能性下降約 10% 時,WLLM 的檢測性能低于我們的方法。對于無失真水印方法,由于代碼生成任務的熵較低,EXP - EDIT 在所有情況下都無法實現超過 0.6 的 AUROC 分數,即使是采用高熵設置的 EXP - EDIT,在檢測性能方面也無法超越我們的方法。雖然所有事后檢測基準方法都能保留代碼功能性,因為它們不修改生成的代碼,但它們的 AUROC 分數均未超過 0.6?。
代碼質量保持(Code Quality Preservation)
在表 1 的最后兩行中,盡管 WLLM 和 SWEET 都會不可避免地導致文本質量下降,但與 WLLM 相比,我們的 SWEET 方法在保持 AUROC>0.9 的高檢測能力的同時,能更好地保留代碼功能性。具體而言,WLLM 在 HumanEval 上的 pass@1 從 33.4 下降到 25.3,代碼執行通過率損失了 24.3%。類似地,在 MBPP 和 DS - 1000 數據集上,性能分別下降了 36.0% 和 67.3%。另一方面,我們的方法在 HumanEval、MBPP 和 DS - 1000 上分別僅損失了 2.4%、12.2% 和 28.5%,這顯著低于 WLLM 的損失比例。
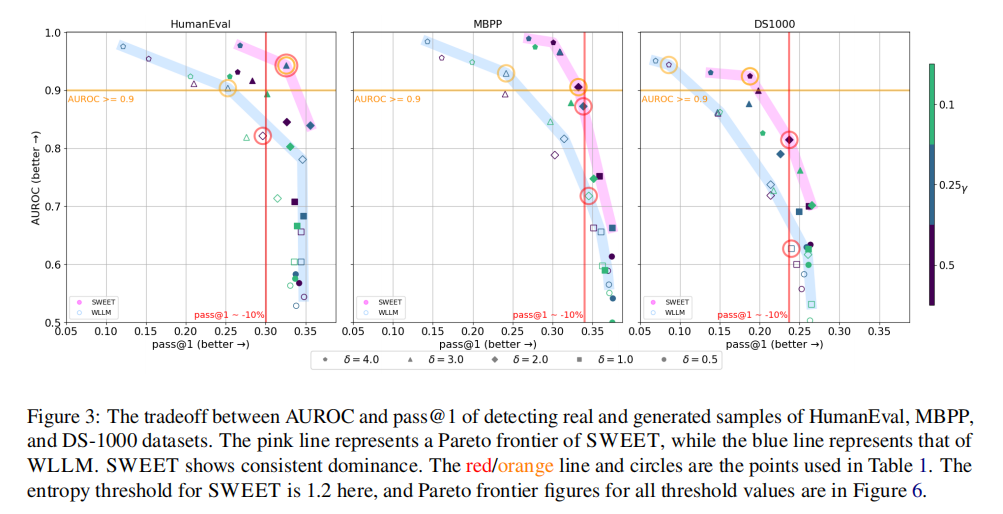
圖3
(1)HumanEval 子圖
- SWEET(粉色標記):在?
AUROC ≥ 0.9?時,pass@1?仍保持較高水平;即使代碼質量下降約 10%(紅色豎線處),AUROC 也接近 1.0,檢測能力極強。 - WLLM(淺藍色標記):若要滿足?
AUROC ≥ 0.9,pass@1?下降更明顯;在代碼質量下降 10% 時,AUROC 遠低于 SWEET。
(2)MBPP 子圖
- SWEET:在?
AUROC ≥ 0.9?時,pass@1?優于 WLLM;代碼質量下降 10% 時,AUROC 也高于 WLLM。 - WLLM:檢測能力達標時,代碼質量損失更大;同等代碼質量損失下,檢測能力更弱。
(3)DS1000 子圖
- SWEET:整體在 “高 AUROC” 與 “高 pass@1” 的權衡中更占優,即使任務難度大(DS1000 是數據科學領域代碼,更復雜),仍能在檢測能力達標時,保留更好的代碼質量。
- WLLM:檢測能力和代碼質量的權衡更 “失衡”,要么檢測能力不足,要么代碼質量下降過多。
C++/Java/ 類級代碼生成
表 2 呈現了在其他編程語言(C++ 和 Java)以及另一種代碼生成范圍(即類級)上的結果。在比 WLLM 更好地保留代碼功能性的同時,SWEET 展現出了最高的檢測性能,不過在 Java 環境中是例外,此時 WLLM 的真陽性率(TPR)得分高于 SWEET。這些結果表明,我們方法的有效性并不局限于特定類型的編程語言或軟件開發環境。有關結果的更多分析,請參考附錄 E。
5.2 SWEET 與 WLLM 的帕累托前沿對比
在 SWEET 和 WLLM 的情況中,水印強度和范圍會根據綠色列表標記的比例\(\gamma\)以及對數概率增加值\(\delta\)而變化。為了證明無論\(\gamma\)和\(\delta\)取值如何,SWEET 都始終優于基準方法 WLLM,我們在圖 3 中繪制了以 pass@1 和 AUROC 為軸的帕累托前沿曲線。我們觀察到,在所有三個任務中,SWEET 的帕累托前沿都領先于 WLLM 的。此外,正如圖 6 所示,無論我們的方法為熵閾值選擇什么值,在所有配置下 SWEET 都優于基準方法。這表明,在廣泛的超參數設置范圍內,我們的 SWEET 模型在檢測能力和代碼生成能力方面都能產生更優的結果。完整結果和不同設置請見附錄 F。
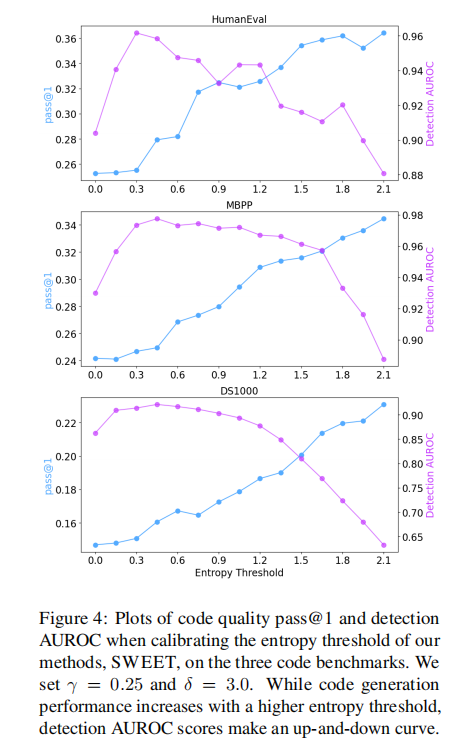
圖4
圖 4 展示了在三個代碼基準測試(HumanEval、MBPP、DS1000)上,校準我們的方法 SWEET 的熵閾值時,代碼質量指標 pass@1 和檢測指標 AUROC 的變化情況。我們將設為 0.25,
設為 3.0。當熵閾值增大時,代碼生成性能(pass@1)有所提升,而檢測 AUROC 分數則呈現出上下波動的曲線。
從圖中具體來看:
- HumanEval 子圖:隨著熵閾值從 0.0 增加到 2.1,pass@1(紫色線)整體呈上升趨勢,而檢測 AUROC(藍色線)先上升后下降,呈現波動。
- MBPP 子圖:pass@1(紫色線)隨熵閾值增大而上升,檢測 AUROC(藍色線)同樣有波動,先升后降再升。
- DS1000 子圖:pass@1(紫色線)隨著熵閾值增大而上升,檢測 AUROC(藍色線)則是先有小幅度波動后上升,但整體波動也較為明顯。
這表明熵閾值的選擇對 SWEET 的代碼生成質量和檢測能力有重要影響,且兩者的變化趨勢并非完全一致,存在一定的權衡與復雜的相互作用。
第六章?分析
6.1 熵閾值的影響(Impact of Entropy Thresholds)
圖 4 展示了在我們的方法中校準熵閾值時,代碼生成性能和檢測能力是如何權衡的。WLLM 是不應用熵閾值的情況(即熵閾值 = 0)。隨著熵閾值的增加,被水印標記的標記比例下降,因此代碼生成性能會向無水印的基礎模型收斂。這表明,在代碼生成性能方面,我們的方法始終介于 WLLM 和無水印基礎模型之間。另一方面,檢測能力隨著熵閾值的增加,會達到一個局部最大值,但最終會下降。雖然與 WLLM 相比,我們采用適度閾值的方法能有效限制生成紅色列表標記,但如果閾值過高,以至于很少有標記被水印化,檢測能力最終會下降。我們在附錄 H 中進一步研究了如何有效地校準熵閾值。
6.2 無提示時的檢測能力
由于檢測階段需要熵信息,因此在我們的方法中,對每個生成時間步t的熵值進行近似是至關重要的。在主要實驗中,我們會在目標代碼前添加生成階段所使用的提示(例如圖 2 中的問題),以此來重現相同的熵。然而,在現實世界中,我們幾乎無法知曉為給定目標代碼所使用的提示。因此,我們沒有使用理想的提示,而是附加了一個通用的代碼生成提示來近似熵信息。我們使用了以下五個通用提示,并對它們的z分數取平均值,用于檢測過程。

圖 8 展示了在 HumanEval 數據集上使用通用提示時檢測能力的變化情況。使用通用提示的 SWEET 表現出比原始 SWEET 更低的 AUROC 值,這表明不準確的近似熵信息會損害檢測能力。盡管如此,在檢測能力方面,它仍然優于 WLLM 基準方法,在所有熵閾值取值下,其繪制的帕累托前沿都領先于 WLLM。
注記:
“帕累托前沿(Pareto Frontier)” 是一個源于帕累托最優的概念,用來描述 “多目標優化” 中,“無法在不犧牲一個目標的前提下改善另一個目標” 的最優解集合。
結合論文里 “代碼生成質量(pass@1)” 和 “水印檢測能力(AUROC)” 這兩個目標,我們可以這樣通俗理解:
1. 核心邏輯:兩個目標的 “權衡”
論文里要同時優化?代碼生成質量(越高越好,比如pass@1數值高,代表生成的代碼更可能正確)和?水印檢測能力(越高越好,比如AUROC數值高,代表越容易檢測出 “代碼是機器生成的”)。
但這兩個目標往往是互斥的:
- 若想 “檢測能力強”,可能需要在生成代碼時嵌入更多水印,這會影響代碼的自然性,導致 “代碼質量下降”;
- 若想 “代碼質量高”,又可能因為嵌入水印少,導致 “檢測能力變弱”。
2. 帕累托前沿的作用:找 “最優權衡點”
帕累托前沿就是 “所有無法再同時優化兩個目標” 的點的集合。比如在圖中,前沿上的每個點都滿足:
- “如果想讓檢測能力更好,代碼質量一定會下降”;
- “如果想讓代碼質量更好,檢測能力一定會下降”。
前沿左邊 / 下邊的點,屬于 “可以被前沿上的點支配” 的 “非最優解”(比如檢測能力和代碼質量都不如前沿上的點);前沿上的點才是 “在當前條件下,兩個目標的最優權衡”。
3. 論文里的具體意義
論文說 “SWEET 的帕累托前沿領先于 WLLM”,意思是:
在 “代碼生成質量” 和 “檢測能力” 的權衡中,SWEET 能做到 “相同代碼質量下,檢測能力更強”;或者相同檢測能力下,代碼質量更高”,所以它的 “最優權衡邊界” 比 WLLM 更 “靠前 / 靠上”,整體性能更優。
簡單總結:帕累托前沿是 “多目標優化中,最優權衡方案的集合”,論文用它來證明 SWEET 在 “代碼質量” 和 “檢測能力” 的平衡上,比其他方法更優秀~
6.3 替代模型的使用
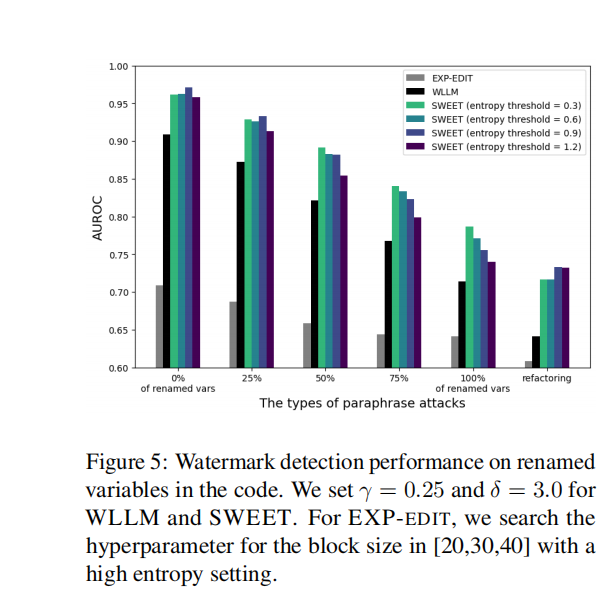
圖 5 展示了在代碼中變量重命名情況下的水印檢測性能。對于 WLLM 和 SWEET,我們將設為 0.25,
設為 3.0。對于 EXP - EDIT,我們在高熵設置下,在 [20,30,40] 范圍內搜索塊大小的超參數。從圖中可以看到,不同的改寫攻擊類型(變量重命名比例為 0%、25%、50%、75%、100% 以及代碼重構)下,不同方法(EXP - EDIT、WLLM、不同熵閾值的 SWEET)的 AUROC(檢測性能指標)存在差異。整體而言,SWEET 在不同熵閾值下,相比 EXP - EDIT 和 WLLM,在多數改寫攻擊類型下都展現出更優的檢測性能,不過隨著變量重命名比例增加或進行代碼重構,各方法的檢測性能均有不同程度的下降。
在檢測文本中的水印時,使用更小的語言模型(LM)作為替代模型可能在計算上更高效且更具成本效益(Wang 等人,2023)。我們研究了在檢測階段使用這種替代模型的影響。具體而言,我們使用原始模型(LLaMA2 - 13B)生成帶水印的代碼,并使用更小的模型(LLaMA2 - 7B)檢測水印。
在圖 10 的結果中,檢測性能的下降并不顯著,而且我們使用替代模型的方法仍然超過了基準方法。這種性能的保持可能是因為 LLaMA2 7B 和 13B 是在相同的訓練語料庫上訓練的(Touvron 等人,2023)。有關計算成本的進一步分析可在附錄 I 中找到。
6.4 對改寫攻擊的魯棒性
即便文本帶有水印,惡意用戶仍可能嘗試通過改寫來移除文本中的水印(Krishna 等人,2023;Sadasivan 等人,2023)。對代碼文本進行改寫比處理普通文本更具限制性,因為必須避免引發任何代碼故障。我們通過采用兩種類型的攻擊 —— 更改變量名和使用商業代碼重構服務,來評估水印方法針對改寫的魯棒性 1?。具體而言,對于每種水印方法,我們從 MBPP 任務中選取 273 個源代碼,這三種方法都能成功生成這些代碼且無語法錯誤。在代碼重命名攻擊中,我們選擇帶水印代碼中的變量,并用長度在 2 到 5 個字符之間的隨機生成字符串對其進行重命名。我們使用五個隨機種子進行重命名。
圖 5 展示了對改寫后代碼的檢測性能結果。當改寫程度增加時,所有水印方法的 AUROC 分數都有所下降,而我們的方法仍然表現出比基準方法更好的性能。然而,我們的方法也顯示出,當所有變量都被重命名時,AUROC 分數下降到約 0.8。我們發現這是因為變量名在代碼文本中占高熵標記的很大比例(詳情見附錄 J)。
第七章 結論
我們明確并強調了代碼大語言模型(Code LLM)水印的需求,且首次對其進行了形式化定義。盡管大語言模型的編碼能力發展迅速,但鼓勵代碼生成模型安全使用的必要措施尚未落實。我們的實驗表明,現有水印和檢測技術在代碼生成場景下無法正常運作。這種失效存在兩種模式:一是代碼未妥善嵌入水印(因此無法被檢測到);二是帶水印的代碼無法正常執行(質量下降)。另一方面,我們提出的方法 SWEET,通過引入選擇性熵閾值(過濾與執行質量最不相關的標記),在一定程度上改善了這兩種失效模式。在代碼生成任務中,我們的方法優于包括事后檢測方法在內的基準方法,同時實現的質量下降更少。更全面的分析表明,我們的方法在現實場景中仍然表現良好,特別是在沒有提示、使用更小的替代模型或遭受改寫攻擊的情況下。
7.1局限性
我們指出了本研究的局限性,并提出了減輕這些局限性的方法。首先,該領域當前存在以下兩個共性問題。(1)對抗改寫攻擊的魯棒性:由于用戶可根據自身特定需求調整大語言模型(LLM)的代碼,因此對抗改寫攻擊的魯棒性至關重要。我們在第 6.4 節中探討了這一問題,并將進一步增強魯棒性的工作留待未來開展。(2)水印偽造的可能性:攻擊者可能會窺探出水印規則,而暴力機制中的次運行會使攻擊成為可能。為應對這種攻擊,可應用增強水印模型安全性的技術,例如像 WLLM 論文中提到的那樣,根據之前的
個標記劃分綠色 / 紅色列表,或者應用如 SelfHash(Kirchenbauer 等人,2023b)之類的方法。
對于我們的研究,還存在以下兩個額外問題。(1)熵閾值校準:我們證明了在廣泛的熵閾值范圍內,我們的方法優于基準方法(見第 6.1 節),并研究了如何校準熵閾值(見附錄 H)。然而,要獲得最佳性能,我們仍需要對熵閾值進行調整,這會帶來計算成本。(2)檢測時對源大語言模型的依賴:SWEET 在白盒設置下工作。盡管已經表明,即使使用更小的替代大語言模型,仍能在一定程度上保持檢測性能(見第 6.3 節),但這對于一些想要應用我們研究成果的用戶來說,可能是一種計算負擔。
7.2倫理聲明
盡管水印方法旨在通過檢測機器生成的文本來應對大語言模型(LLMs)所有潛在的濫用情況,但它們同時也可能帶來新的風險。例如,如果特定大語言模型的水印機制被泄露給公眾,知曉該機制的惡意用戶可能會濫用水印,去創建嵌入了該模型水印的不道德文本。為了防止此類情況發生,我們建議所有用戶務必謹慎行事,避免暴露詳細的機制,比如我們方法中用于劃分綠色和紅色列表的哈希函數的密鑰值。
文獻來源:Who Wrote this Code? Watermarking for Code Generation



和8080端口(備用HTTP端口)區別)



 綜合練習--博客系統)








)


