paper link:?paperlink
Abstract: 這個數據集是個RGB-D視頻數據集,在707個不同空間中獲取了1513個掃描的場景,250w個視圖,并且標注了相機位姿,表面重建,語義分割。本數據集共有20人掃描+500名工作者進行標注。
數據集獲取框架
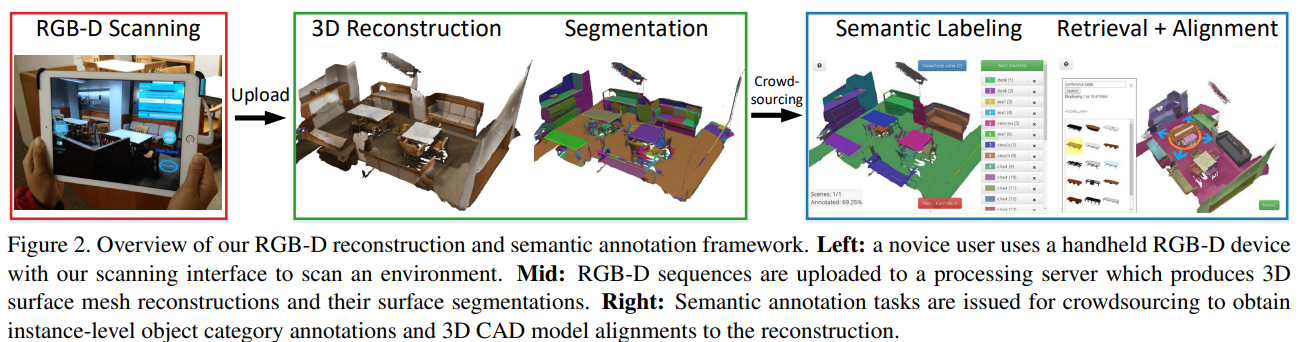
硬件設備: 使用Structure Sensor + ipad Air 2 進行收集,RGB 1296*968, Depth 640*480,默認啟用白平衡+自動曝光。
相機校準:可以使用Srructure Sensor的Calibrate 軟件進行校準。得到深度相機和彩色相機的關系。
用戶界面:創建了ScannerApp進行數據集的采集,(但目前已經很久沒更新了,sdk里有些類已經棄用了)
存儲:128GB可以存儲數小時的拍攝場景,用戶可以隨時點擊“上傳”按鈕將掃描數據上傳到處理服務器。
表面重建: BundleFusion 進行重建,1cm的?voxel resolution,VoxelHashing(?通過 VoxelHashing 實現體素融合 (Volumetric Integration)),marching cubes 在分辨率為4mm *4mm *4mm的voxel下進行高分辨率網格提取。對網格進行自動清理和簡化(合并距離較近的頂點,刪除重復的網格面和孤立的網格部分,對網格進行多分辨率的下采樣,生成高中低分辨率的網格模型)
- 使用 BundleFusion 計算每幀掃描數據的位姿。
- 使用 VoxelHashing 構建 TSDF 表達的全局稠密體素網格。
- 使用 Marching Cubes 提取高分辨率的三角網格。
- 對網格進行清理、去噪和下采樣,生成高、中、低分辨率的版本。
方向:自動將所有相機姿態對齊到一個共同的坐標系中,Z軸向上向量,xy平面和地面對齊。
驗證:會自動丟棄較短、殘差重建誤差較大或對齊幀百分比較低的掃描序列。然后,也會手動檢查并丟棄存在明顯錯位的重建。
準備復現一下,上述的效果,如果效果好,我再繼續寫
Semantic Annotation
總包。。待續


安全保障機制(技術、標準、管理))



(DAY 002))












![[網絡入侵AI檢測] 深度前饋神經網絡(DNN)模型](http://pic.xiahunao.cn/[網絡入侵AI檢測] 深度前饋神經網絡(DNN)模型)