在當今生物醫學研究中,實驗手段和數據量正以前所未有的速度膨脹。從基因組學、單細胞組學到多模態數據,再到可穿戴設備的健康監測,科研人員每天都在與龐大的數據和復雜的分析流程打交道。
然而,實驗設計瑣碎、工具分散、跨學科整合困難,成為阻礙科研效率的重要瓶頸。
👉 想象一下,如果有一個 虛擬 AI 生物學家,能夠自動理解研究問題,調用合適的數據庫、工具和算法,甚至為你寫好代碼、執行分析,并輸出結果報告------科研的效率會提升多少?
斯坦福 SNAP 團隊推出的 Biomni,正是這樣一位"科研助手"。它不僅能勝任跨領域的數據分析,還能為濕實驗研究者設計實驗流程,被稱為首個 通用型生物醫學 AI Agent。


一、Biomni 是什么?
Biomni 的目標,是構建一個 "虛擬 AI 生物學家",能像科研人員一樣思考和執行任務,覆蓋基因組學、免疫學、藥理學、病理學、臨床醫學等多個領域。
架構組成
Biomni 包括兩個核心部分:
- Biomni-E1:
一個統一的生物醫學"動作空間",相當于實驗室和計算環境的總和。它整合了:-
150 種專用生物醫學工具
-
105 個常用生物信息學軟件(支持 Python、R、Bash)
-
59 個數據庫(如 PDB、ClinVar、OpenTarget、BindingDB 等) 并通過 AI 動作發現代理 從 2500 篇最新 bioRxiv 論文中自動提取研究步驟和工具。
-
-
Biomni-A1:
一個智能代理,能夠調用 E1 環境。它通過 大語言模型 + 動態規劃 + 代碼執行,自動檢索合適工具,制定執行計劃,生成并運行代碼,在執行過程中不斷調整策略,保證靈活性與準確性。
換句話說,E1 提供實驗室,A1 提供大腦。兩者結合,使 Biomni 擁有跨學科的"科研執行力"。
二、Biomni 有何優勢?
1. 覆蓋面廣,真正通用
Biomni 并不是為某個單一任務(如 scRNA-seq 分析)定制,而是能在 零樣本(zero-shot) 情況下,處理多種復雜任務:
-
因果基因優先級排序
-
CRISPR 篩選設計
-
罕見病診斷
-
藥物重利用
-
微生物組分析
-
分子克隆實驗
2. 性能媲美甚至超過專家
在多個權威基準測試中,Biomni 表現突出:
-
LAB-Bench 數據庫問答 (DbQA) :準確率 74.4%,與專家持平(74.7%),顯著超過其他 AI(40.8%)。
-
序列問答 (SeqQA) :81.9%,高于專家(78.8%)。
-
HLE 跨 14 個學科測試:在陌生任務中,Biomni 得分 17.3%,遠高于基礎 LLM (6.0%) 和其他 AI agent (12.8%)。
-
平均性能提升 :比基礎 LLM 高402.3%,比編碼 Agent 高43%。
3. 自動化多步流程
在真實科研任務中,Biomni 平均每個任務執行 6--24 步,調用多個工具和數據庫,自動組合成復雜的工作流,無需研究人員逐步硬編碼。
4. 輸出可視化報告
不同于只給結果的 LLM,Biomni 會生成:軌跡圖、UMAP、熱圖、PCA 雙標圖、聚類圖等,幫助科研人員快速洞察數據。
三、真實案例展示
案例 1:可穿戴傳感器 + 多組學數據
研究者給 Biomni 提供了 485 份餐后體溫數據(CGM 監測)、227 晚睡眠數據,以及 脂質組、代謝組、蛋白質組數據。
-
Biomni 自動分析后發現:
-
平均餐后體溫上升 2.19°C;
-
睡眠效率在周三最高,周日最低,規律性比總時長更關鍵;
-
脂質、代謝物與蛋白質之間形成緊密調控網絡。
這一過程,從原始數據到假設提出,完全自動完成。
案例 2:胚胎骨骼多組學數據
Biomni 處理了 33.6 萬個胚胎細胞核的 snRNA-seq + snATAC-seq 數據,構建了 10 步分析流程:
-
比較不同解剖位置的細胞組成;
-
構建發育軌跡;
-
分析轉錄因子與靶基因調控網絡。
它自動生成可視化結果,提出了與文獻一致且可驗證的新假設。
案例 3:分子克隆實驗
研究者要求 Biomni 設計"將 B2M 基因的 sgRNA 插入 lentiCRISPR v2 載體"的實驗。
-
Biomni 自動完成:
-
質粒結構解析
-
sgRNA 設計
-
寡核苷酸合成
-
Golden Gate 裝配
-
菌落篩選與測序驗證
-
實驗人員嚴格按照 Biomni 的協議操作,成功獲得正確克隆,驗證其可靠性。
這意味著,Biomni 不只是"分析助手",還可以成為 濕實驗研究的實驗設計師。
四、Biomni 的意義
-
對科研人員:減少重復勞動,把更多精力放在假設生成和創新思考上;
-
對制藥公司:可自動篩選靶點、設計干預實驗、加速藥物發現;
-
對臨床:輔助罕見病診斷、基因優先排序,提升個性化醫療水平;
-
對公眾健康:結合可穿戴設備,實現實時健康監測與干預。
五、未來展望與挑戰
Biomni 雖然表現出色,但仍存在挑戰:
-
對臨床推理、創新實驗設計等高層次任務仍不如專家;
-
傾向依賴最新文獻,可能忽略經典方法;
-
尚未整合圖像、病理切片等多模態信息。
未來,Biomni 團隊計劃:
-
引入強化學習機制,讓代理能自我迭代提升;
-
更好地整合多模態數據(文本 + 圖像 + 結構化信息);
-
自動發現并引入新工具與數據庫,保持長遠適用性。
📝 總結
Biomni = 實驗室的 AI 科研助手
它能看文獻、會寫代碼、懂組學,還能幫你設計實驗。
無論你是生物信息學分析人員,還是實驗室的分子生物學家,Biomni 都可能成為你未來工作中最強大的伙伴。
在人工智能推動科研的浪潮中,Biomni 代表著一個新起點------讓 AI 真正成為科研過程中的 共同發現者。
-
官網網站 👉 https://biomni.stanford.edu
現在 Biomni 官網顯示無法直接使用,是因為該項目還處于受控測試階段。你可以通過 Request access 填寫申請表,進入等待名單,等待官方邀請開放使用權限。
-
GitHub 開源地址 👉 https://github.com/snap-stanford/Biomni
Biomni 本地安裝與配置
一、環境準備
-
操作系統:推薦使用 Ubuntu 22.04 (64-bit),已驗證兼容性較好。
-
工具需求:安裝 Conda(用于創建隔離環境),建議安裝 Miniconda 或 Anaconda。
二、克隆倉庫 & 環境搭建
-
克隆官方 GitHub 倉庫:
git?clone?https://github.com/snap-stanford/Biomni.git cd?Biomni -
執行設置腳本
setup.sh,構建基礎環境:bash?setup.sh此腳本將創建一個名為
biomni_e1的 Conda 環境,并安裝所需依賴包。
> 注意:整個環境可能需要 約 10 小時 構建完成,并消耗 30?GB 存儲空間。 -
環境搭建完成后,激活:
conda?activate?biomni_e1
三、安裝 Python 包
-
從 PyPI 安裝穩定版本:
pip?install?biomni?--upgrade -
安裝最新源碼版本:
pip?install?git+https://github.com/snap-stanford/Biomni.git@main
四、配置 API Key 與環境變量
Biomni 依賴外部 LLM 模型(如 Claude、OpenAI、Gemini 等)。
方法一:通過 .env 文件配置
在項目根目錄執行:
cp?.env.example?.env
編輯 .env 文件:
ANTHROPIC_API_KEY=你的_Claude_API_密鑰# 可選字段
OPENAI_API_KEY=你的_OpenAI_密鑰
OPENAI_ENDPOINT=https://... # Azure OpenAI 的 endpoint
GEMINI_API_KEY=你的_Gemini_密鑰
GROQ_API_KEY=你的_groq_密鑰
LLM_SOURCE=指定模型來源("OpenAI" / "Anthropic" / 等)BIOMNI_DATA_PATH=/path/to/your/data
BIOMNI_TIMEOUT_SECONDS=600
方法二:使用 Shell 環境變量
export?ANTHROPIC_API_KEY="你的_API_密鑰"
export?OPENAI_API_KEY="你的_OpenAI_密鑰"
export?LLM_SOURCE="Anthropic"#?AWS?Bedrock?配置
export?AWS_BEARER_TOKEN_BEDROCK="你的_密鑰"
export?AWS_REGION="us-east-1"
五、安全注意事項
Biomni 會以 系統權限執行 LLM 生成的代碼,具備文件、網絡、系統命令訪問權限。
?? 務必在隔離或沙箱環境中運行,避免潛在安全風險。
六:運行示例
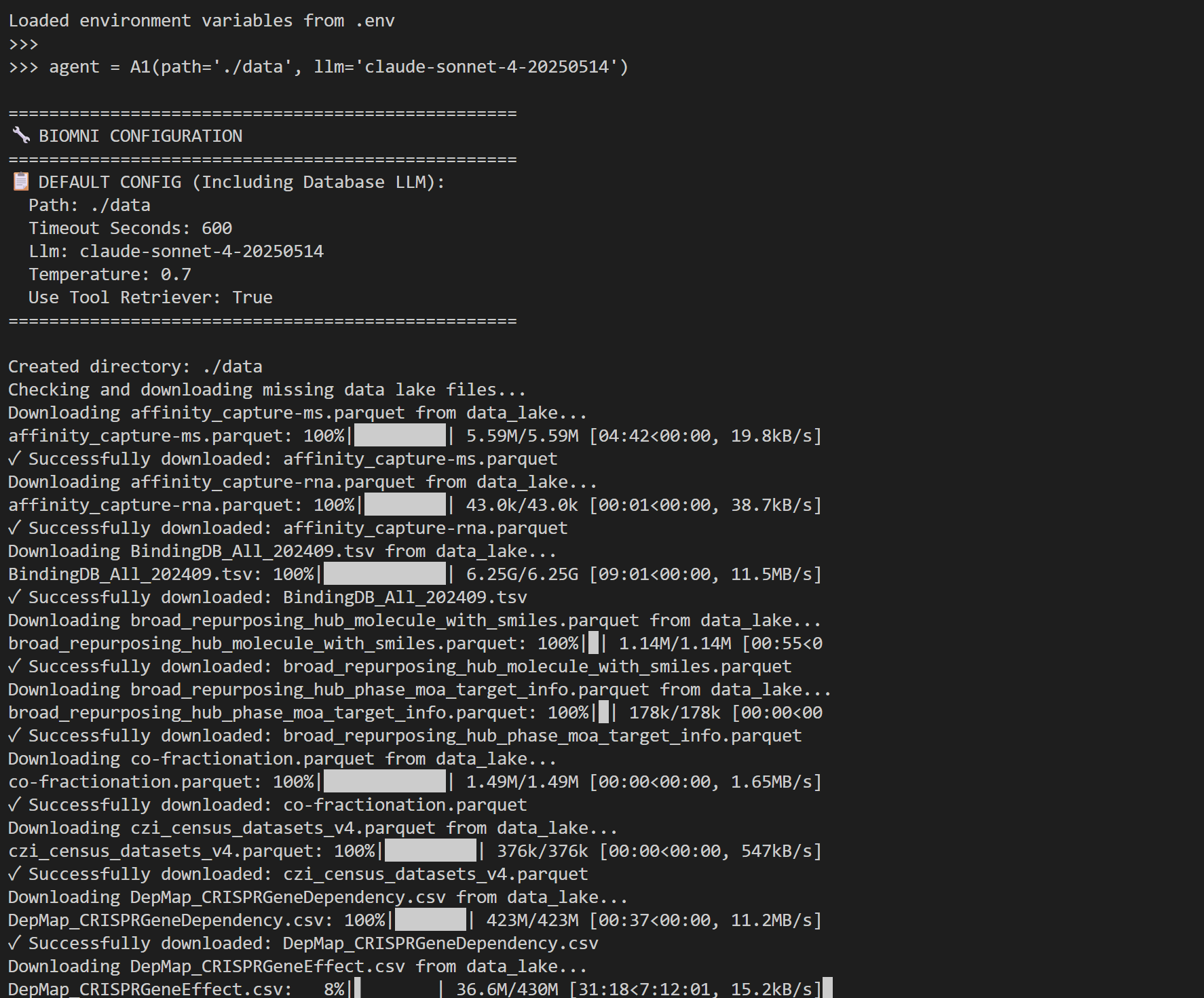
from?biomni.agent?import?A1
agent?=?A1(path="./data",?llm="claude-sonnet-4-20250514")
result?=?agent.go("Plan?a?CRISPR?screen?to?identify?genes?that?regulate?T?cell?exhaustion,?generate?32?genes…")
print(result)
使用前還要下載一個大概11G大小的文件,我的還在下載中,明天試試效果,給大家繼續反饋。

(DAY 002))












![[網絡入侵AI檢測] 深度前饋神經網絡(DNN)模型](http://pic.xiahunao.cn/[網絡入侵AI檢測] 深度前饋神經網絡(DNN)模型)




)