基于YOLOv8和Streamlit的汽車碰撞事故檢測系統
文末附下載地址
開發目的
隨著城市化進程的加快和機動車保有量的持續攀升,道路交通安全問題日益突出,汽車碰撞事故頻發不僅嚴重威脅駕乘人員的生命安全,也對公共秩序、應急響應效率及交通管理能力提出了嚴峻挑戰。傳統的交通事故監測主要依賴人工報警、路面監控巡查或車載傳感器觸發,存在響應滯后、覆蓋盲區多、人力成本高等弊端,難以滿足現代智慧交通對實時性與智能化的雙重需求。尤其在無人值守路段或夜間低光照環境下,事故難以被及時發現,極易引發二次傷害或交通擁堵。為破解這一難題,亟需構建一套高效、精準、可落地的自動化碰撞事故識別系統。
YOLOv8作為當前最先進的實時目標檢測模型,憑借其卓越的檢測精度、推理速度以及對多尺度、遮擋目標的強適應能力,能夠有效識別復雜交通場景中車輛的異常狀態,如劇烈位移、變形、翻車及散落物等碰撞特征。結合Streamlit這一高效交互式Web應用框架,本系統實現了檢測模型的可視化部署與實時視頻流分析,支持用戶便捷上傳視頻、查看檢測結果并獲取預警提示,極大提升了系統的可用性與推廣價值。
基于YOLOv8和Streamlit的汽車碰撞事故檢測系統不僅能夠實現對交通事故的秒級識別與自動報警,助力交管部門快速響應、縮短救援時間,還可在智能交通監控、自動駕駛輔助、保險定損等多個場景中發揮重要作用,推動人工智能技術在交通安全治理領域的深度應用,具有顯著的社會效益與技術創新意義。
YOLO介紹
YOLOv8是Ultralytics公司于2023年推出的最新目標檢測模型,作為YOLO系列的最新迭代,它在檢測精度、推理速度和模型可擴展性方面實現了顯著提升。YOLOv8延續了YOLO系列“一階段檢測”的高效架構,但在骨干網絡、Neck結構和檢測頭設計上進行了多項關鍵優化,進一步提升了整體性能。以下從骨干網絡、Neck和檢測頭三個方面深入解析YOLOv8,并對比其與YOLOv5、YOLOv7的主要改進與創新。
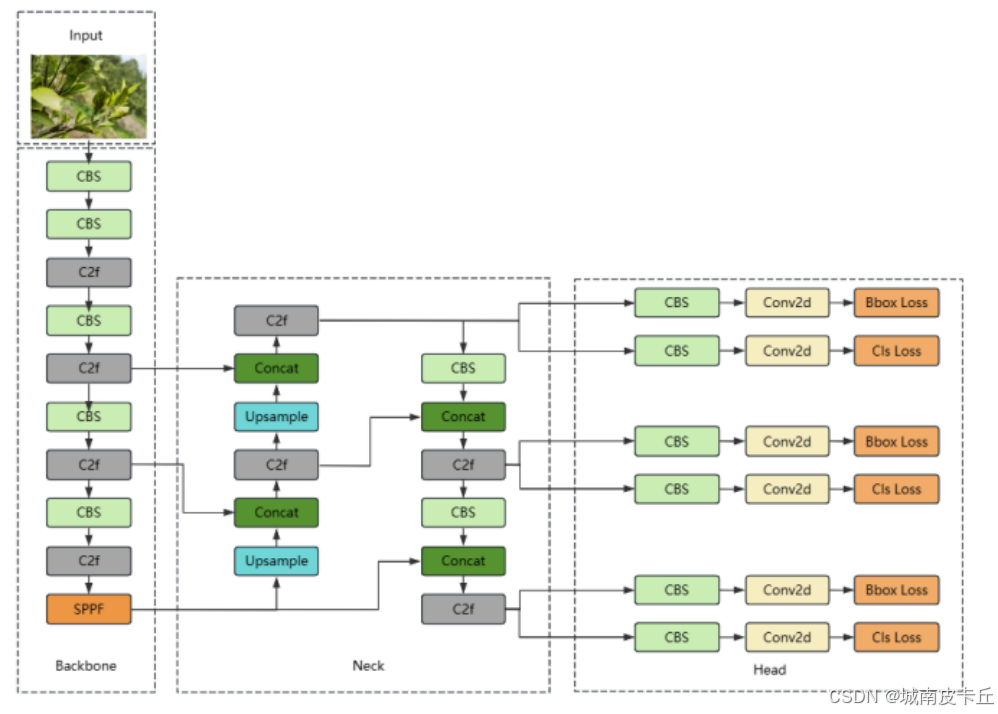
1. 骨干網絡(Backbone)
YOLOv8的骨干網絡采用CSP(Cross Stage Partial)結構的改進版本,引入了更高效的C2f模塊替代YOLOv5中的C3模塊。C2f模塊通過更輕量的特征融合方式,在減少參數量的同時增強了梯度流動,提升了特征提取能力。此外,YOLOv8在不同尺度模型(如YOLOv8n、YOLOv8s、YOLOv8m等)中靈活調整網絡深度和寬度,實現精度與速度的良好平衡。相比YOLOv5中使用的Focus結構,YOLOv8采用標準卷積進行下采樣,避免信息丟失,提升特征完整性。而相較于YOLOv7中復雜的ELAN(Extended Efficient Layer Aggregation Networks)結構,YOLOv8的C2f設計更加簡潔高效,兼顧性能與部署便捷性。
2. Neck結構
YOLOv8的Neck部分延續了PANet(Path Aggregation Network)的雙向特征融合思想,但對結構進行了簡化和優化。它采用改進的PAN結構,結合C2f模塊進行多尺度特征融合,增強了高層語義信息與底層細節特征的交互能力。與YOLOv5相比,YOLOv8的Neck在特征融合路徑上減少了冗余連接,提升了計算效率。而相較于YOLOv7中高度復雜且深度定制的E-ELAN結構,YOLOv8的Neck更注重模塊化與通用性,避免過度設計,在保持高性能的同時提升了模型的可維護性和跨平臺部署能力。
3. 檢測頭(Head)
YOLOv8最大的創新之一在于檢測頭的設計:它摒棄了YOLOv5和YOLOv7中沿用的“耦合頭”(即分類與回歸共用部分參數),轉而采用解耦頭(Decoupled Head)結構。這種結構將分類任務和邊界框回歸任務完全分離,各自擁有獨立的卷積分支,顯著提升了模型的表達能力與檢測精度。此外,YOLOv8引入了任務對齊分配器(Task-Aligned Assigner)作為標簽分配策略,動態匹配正樣本,使分類得分與定位精度更一致,提升訓練穩定性與推理效果。在回歸分支中,YOLOv8還采用更先進的損失函數(如DFL,Distribution Focal Loss),進一步優化邊界框的定位能力。
與YOLOv5、YOLOv7的對比與創新總結
-
相比YOLOv5:YOLOv8在結構上更為先進,采用C2f模塊增強特征提取,使用解耦頭提升檢測性能,并引入更優的標簽分配策略。整體精度更高,尤其在小目標檢測和密集場景下表現更優。同時,YOLOv8取消了Anchor-Based設計中的手動Anchor聚類,支持Anchor-Free模式,適應性更強。
-
相比YOLOv7:YOLOv7強調極致的參數利用和復合縮放,結構復雜,訓練成本高。而YOLOv8在保持高性能的同時,追求簡潔與高效,避免了YOLOv7中復雜的模塊堆疊和訓練技巧(如模型重參數化、輔助頭等),更適合工業級部署。此外,YOLOv8在架構設計上更具統一性,支持分類、檢測、分割等多任務,生態更完善。
綜上所述,YOLOv8在繼承YOLO系列高效特性的同時,通過C2f骨干、優化Neck結構和解耦檢測頭等創新,實現了精度與速度的雙重提升。相比YOLOv5和YOLOv7,它在模型設計上更加現代化、模塊化,兼顧高性能與易用性,成為當前目標檢測領域極具競爭力的主流模型。
系統設計
數據集
(1) 數據集基本情況
本項目使用的數據集為專門用于車輛碰撞事故檢測的目標檢測數據集,數據來源于在網絡上爬取的真實交通事故場景采集圖像,并經過專業篩選與清洗。整個數據集包含超過一萬張標注圖像,具體劃分為:
- 訓練集:9758張圖像
- 驗證集:1347張圖像
- 測試集:675張圖像
數據集中包含兩個類別標簽:
- 中度碰撞
- 重度碰撞
所有圖像均已使用LabelMe工具完成標注,并轉換為YOLO系列模型所需的格式。數據集附帶完整的classes.yaml配置文件,用戶下載后無需任何預處理即可直接用于YOLOv8模型訓練。經實測,使用YOLOv8n(nano版本)在該數據集上訓練后,mAP@50可達0.985,表明數據質量高、標注準確,適合用于高精度事故識別任務。
(2) 數據集處理
原始圖像在采集后,使用開源標注工具 LabelMe 進行人工標注。LabelMe 是一個基于圖形界面的圖像標注工具,支持多邊形、矩形、點等多種標注方式,廣泛應用于目標檢測、語義分割等任務。
標注完成后,每張圖像會生成一個對應的 .json 文件,記錄了圖像中每個目標的位置信息(如邊界框坐標)、類別名稱及圖像元數據。
由于 YOLO 系列模型要求輸入的數據格式為歸一化后的文本格式(.txt),因此我們將 LabelMe 生成的 .json 標注文件統一轉換為 YOLO 所需的格式:

YOLO目標檢測數據格式說明:
對于每張圖像 image.jpg,需提供一個同名的 .txt 文件(如 image.txt),其內容為每一行代表一個目標對象,格式如下:
<class_id> <x_center> <y_center> <width> <height>
其中:
class_id:類別索引(從0開始)x_center,y_center:邊界框中心點坐標(相對于圖像寬高的歸一化值,范圍 [0,1])width,height:邊界框的寬和高(同樣為歸一化值)
例如:
0 0.456 0.321 0.210 0.150
1 0.789 0.654 0.180 0.120
表示圖像中有兩個目標,分別為“中度碰撞”和“重度碰撞”,其位置信息已歸一化。
最終,整個數據集組織結構如下:
dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── labels/
│ ├── train/
│ ├── val/
│ └── test/
└── data.yaml
data.yaml 文件定義了類別數量、類別名稱列表以及訓練/驗證/測試集路徑,供模型訓練時讀取。
模型訓練
安裝 Ultralytics
YOLOv8 由 Ultralytics 公司開發并維護,提供了簡潔高效的 API 接口。我們通過 ultralytics 庫來完成模型的訓練與推理。
安裝命令如下:
pip install ultralytics
訓練代碼編寫
訓練腳本通常以 Python 腳本形式編寫,調用 YOLO 類進行訓練。示例代碼如下:
from ultralytics import YOLO# 加載預訓練模型
model = YOLO('yolov8n.pt') # 可替換為其他規模模型# 開始訓練
results = model.train(data='path/to/data.yaml',epochs=100,imgsz=640,batch=16,name='yolov8n-crash-detection'
)
訓練參數設置(超參數詳解)
Ultralytics 提供了豐富的可調超參數,以下為本次訓練中關鍵超參數的設置及其含義說明:
| 超參數 | 取值 | 含義說明 |
|---|---|---|
epochs | 100 | 訓練總輪數,控制模型學習充分性 |
batch | 16 | 每批次處理的圖像數量,影響內存占用與梯度穩定性 |
imgsz | 640 | 輸入圖像尺寸(H×W),越大細節越多但計算量增加 |
optimizer | ‘auto’ | 優化器選擇(SGD/Adam/AdamW),默認自動選擇 |
lr0 | 0.01 | 初始學習率,決定參數更新步長 |
lrf | 0.01 | 最終學習率與初始學習率的比率(線性衰減) |
momentum | 0.937 | SGD動量因子,提升收斂速度 |
weight_decay | 5e-4 | L2正則化系數,防止過擬合 |
warmup_epochs | 3.0 | 學習率預熱階段的epoch數 |
warmup_momentum | 0.8 | 預熱階段動量值 |
box | 7.5 | 邊界框回歸損失權重 |
cls | 0.5 | 分類損失權重 |
conf | 1.0 | 置信度損失權重 |
iou | 0.5 | IoU損失閾值 |
patience | 50 | EarlyStop耐心值,若50輪無提升則停止訓練 |
這些超參數可根據實際硬件條件和性能需求進行微調。Ultralytics 支持從外部 YAML 文件加載自定義超參數,便于復現實驗結果。
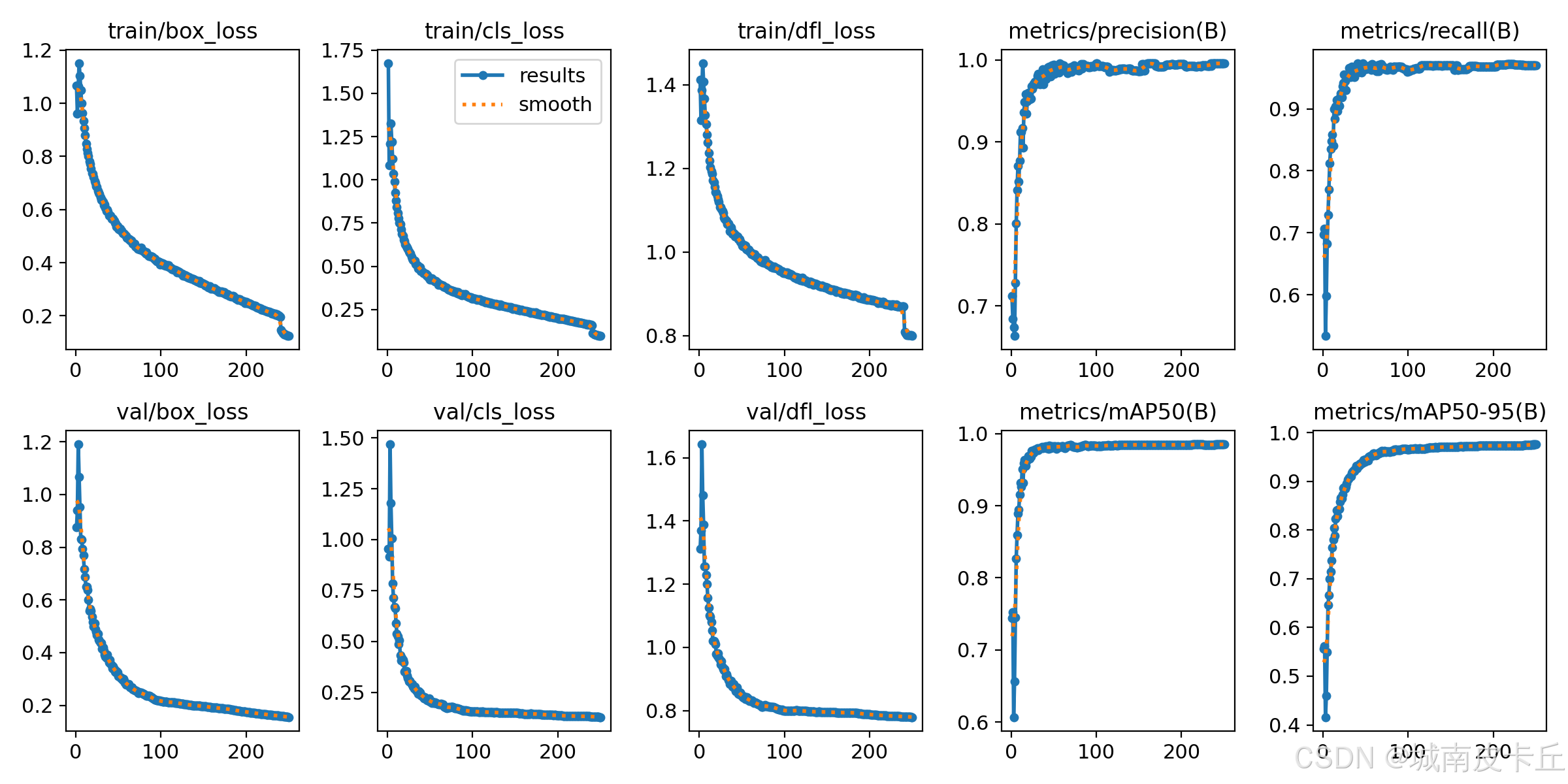
訓練后評估
為什么需要模型評價?
訓練完成后,必須對模型性能進行全面評估,以判斷其是否具備實際部署能力。僅憑訓練損失下降無法反映模型在真實場景中的表現,因此需要引入標準化的評估指標。
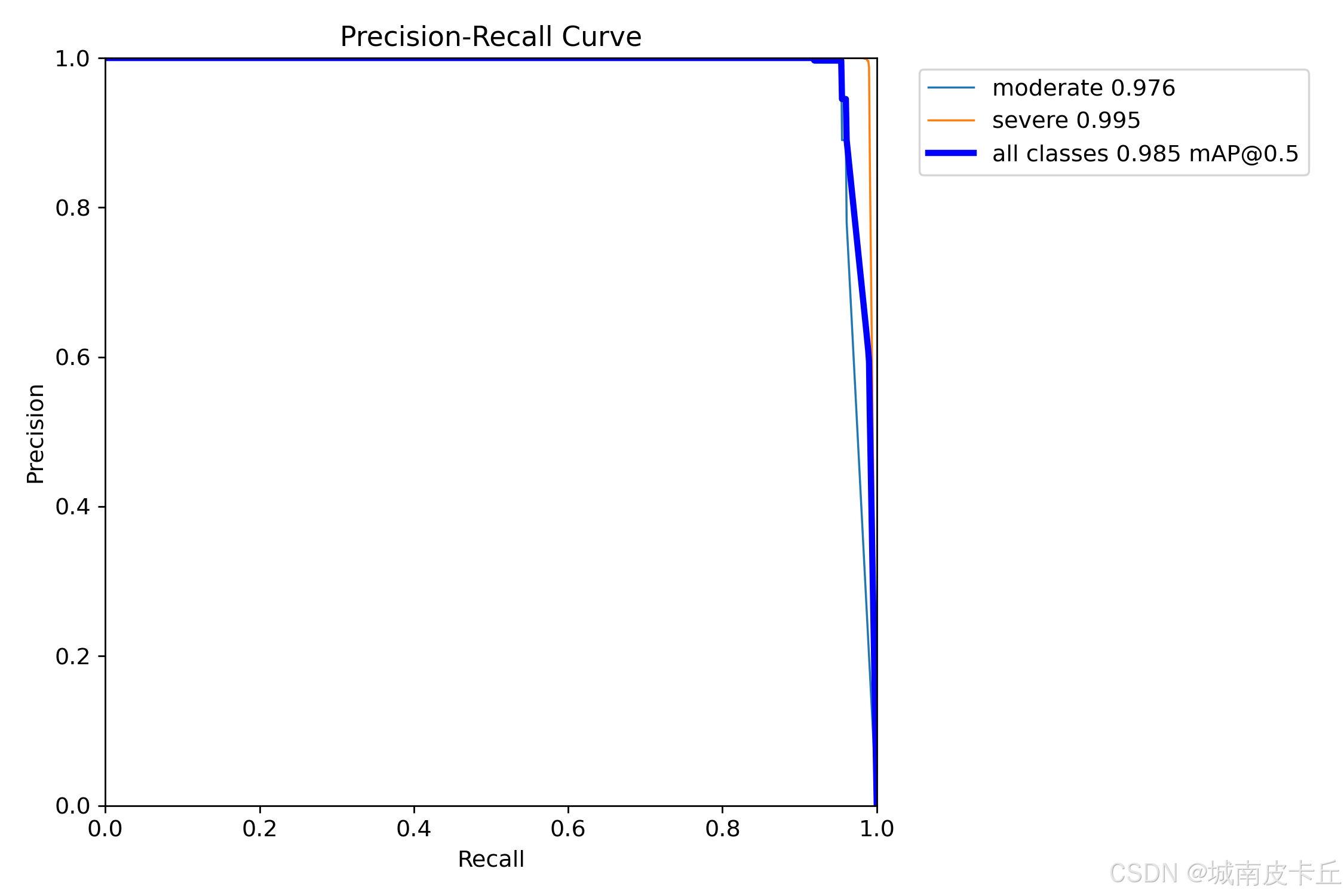
PR曲線(Precision-Recall Curve)
PR曲線是目標檢測中最常用的可視化工具之一,橫軸為召回率(Recall),縱軸為精確率(Precision)。
-
精確率(Precision):預測為正類的樣本中,實際為正類的比例
Precision=TPTP+FP\text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP? -
召回率(Recall):實際為正類的樣本中,被正確預測的比例
Recall=TPTP+FN\text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP?
其中:
- TP:真正例(True Positive)
- FP:假正例(False Positive)
- FN:假反例(False Negative)
PR曲線越靠近右上角,說明模型性能越好。曲線下面積即為 AP(Average Precision)。
mAP(mean Average Precision)
mAP 是綜合衡量目標檢測性能的核心指標,是對所有類別 AP 的平均值。
- mAP@0.5:IoU 閾值為 0.5 時的平均精度
- mAP@0.5:0.95:在 IoU 從 0.5 到 0.95(步長0.05)共10個閾值下的平均 mAP
數學表達式:
mAP=1N∑i=1NAPi\text{mAP} = \frac{1}{N} \sum_{i=1}^{N} \text{AP}_i mAP=N1?i=1∑N?APi?
其中 NNN 為類別總數,APi\text{AP}_iAPi? 為第 iii 類的平均精度。
在本項目中,YOLOv8n 模型在測試集上達到了 mAP@50 = 0.985,表明模型對車輛碰撞具有極高的檢測準確率。
模型推理
圖片推理代碼
使用訓練好的模型進行單張圖像推理:
from ultralytics import YOLOmodel = YOLO('runs/detect/yolov8n-crash-detection/weights/best.pt')
results = model.predict(source='test.jpg', conf=0.5, iou=0.45)for r in results:im_array = r.plot() # 繪制檢測結果im = Image.fromarray(im_array[..., ::-1]) # BGR to RGBim.show()
視頻推理代碼
對視頻文件逐幀進行推理:
import cv2
from ultralytics import YOLOmodel = YOLO('best.pt')
cap = cv2.VideoCapture('input.mp4')while cap.isOpened():success, frame = cap.read()if not success:breakresults = model.predict(frame, conf=0.5)annotated_frame = results[0].plot()cv2.imshow('Crash Detection', annotated_frame)if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release()
cv2.destroyAllWindows()
以上代碼可用于離線視頻分析或實時攝像頭檢測。
系統UI設計
Streamlit 框架優勢
本系統采用 Streamlit 作為前端交互框架,其主要優點包括:
- 開發簡單:純 Python 編寫(Streamlit本質上是利用Python對前端的HTML、CSS、JS做了封裝),因此無需HTML/CSS/JS知識,直接調用Streamlit的Python接口即可產生精美的Web界面
- 快速部署:幾行代碼即可構建Web應用
- 實時交互:支持滑塊、按鈕、上傳組件等動態控件
- 集成性強:易于與PyTorch、OpenCV、Pandas等庫結合
- 本地運行:無需服務器即可啟動本地Web服務
UI搭建流程(結合源碼說明)
根據提供的 app.py 源碼,系統UI主要由以下部分構成:
-
頁面配置與標題設置
st.set_page_config(page_title="code learn corner", layout="centered") st.markdown("<h1 style='text-align: center;'>基于YOLO8的汽車碰撞事故檢測系統</h1>", unsafe_allow_html=True) -
側邊欄控制面板
- 模型選擇下拉框
- 置信度與IoU滑動條調節
- 檢測類型單選(圖片/視頻/攝像頭)
-
主區域功能實現
- 圖像上傳與結果顯示
- 視頻上傳并逐幀播放檢測結果
- 攝像頭實時檢測(通過OpenCV捕獲)
-
結果展示增強
- 使用
st.data_editor展示檢測結果表格(類別、置信度、坐標) - 實時圖像渲染使用
st.image()顯示帶框圖
- 使用
-
隱藏默認樣式
st.markdown(hide_streamlit_style, unsafe_allow_html=True)去除Streamlit默認頁腳和菜單,提升專業感。
整個UI邏輯清晰,模塊化程度高,用戶可通過簡單操作完成多種模式下的碰撞檢測任務。
系統功能
根據源碼分析,本系統具備以下核心功能:
-
? 多模型切換支持
用戶可在側邊欄選擇不同規模的YOLOv8模型(如n/s/m/l/x),靈活平衡速度與精度。 -
? 置信度與IoU閾值可調
提供滑塊控件,允許用戶動態調整conf和iou參數,適應不同檢測場景需求。 -
? 三種檢測模式
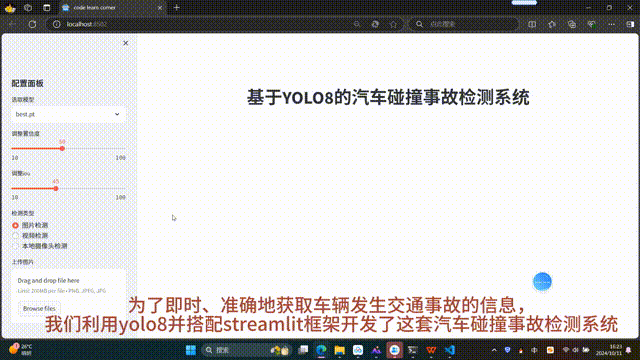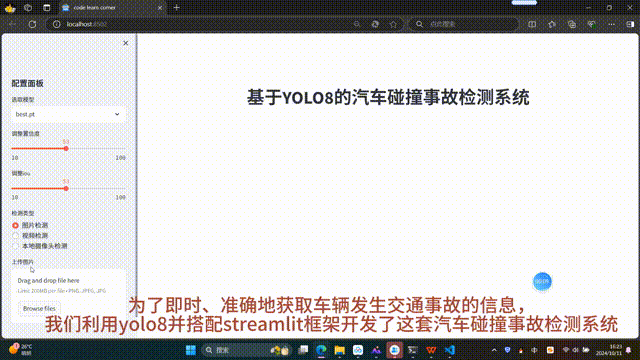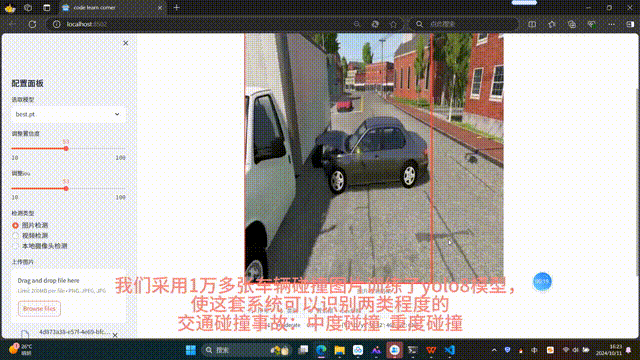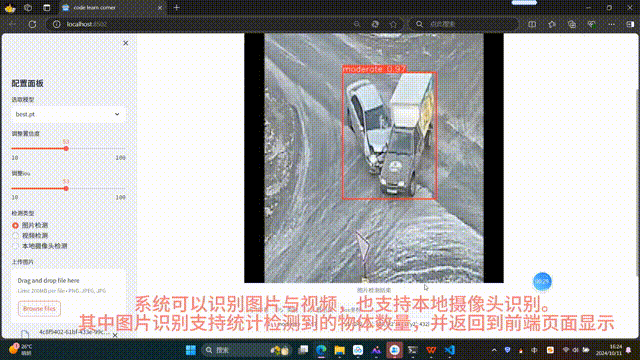
- 圖片檢測:支持上傳 JPG/PNG/JPEG 圖像,顯示檢測結果、標注框、類別統計表
- 視頻檢測:上傳 MP4 視頻文件,逐幀推理并實時播放帶框視頻流
- 本地攝像頭檢測:調用設備攝像頭(ID=0),實現現場實時監控
-
? 結構化結果輸出
- 表格展示每個檢測目標的序號、類別、置信度、邊界框坐標(x1,y1,x2,y2)
- 統計各類別總數(如“中度碰撞:2輛”,“重度碰撞:1輛”)
-
? 高效推理與緩存機制
- 使用
@st.cache_resource緩存已加載模型,避免重復加載導致延遲 - 視頻幀率控制(每2幀處理一次),提升運行流暢度
- 使用
-
? 用戶友好界面
- 中文標題與提示
- 實時進度提示(如“圖片推理執行中…”)
- 支持一鍵終止攝像頭檢測
該系統集成了數據處理、模型推理、可視化展示于一體,具備良好的實用性與擴展性,適用于智能交通、保險定損、自動駕駛輔助等應用場景。
總結
本文圍繞“基于YOLOv8和Streamlit的汽車碰撞事故檢測系統”展開,系統性地闡述了項目的開發背景、核心技術選型、數據處理流程、模型訓練與評估方法,以及前端交互系統的設計與實現。通過整合YOLOv8在目標檢測領域的先進性能與Streamlit在Web應用開發中的便捷性,成功構建了一套高效、直觀、可擴展的智能交通監控解決方案。
該系統不僅實現了對中度與重度碰撞事故的高精度識別(mAP@50達0.985),還支持圖片、視頻及實時攝像頭三種檢測模式,具備良好的實用性與部署靈活性。同時,通過可調節的置信度與IoU參數、結構化結果輸出和模型緩存機制,顯著提升了用戶體驗與系統響應效率。
未來,本系統可進一步拓展至多車協同檢測、事故嚴重性分級、自動報警聯動、與交通信號控制系統集成等方向,助力構建更加智能化、自動化的城市交通安全管理體系。總體而言,該項目充分體現了人工智能技術在現實場景中的落地價值,為智慧交通與公共安全領域提供了有力的技術支撐。
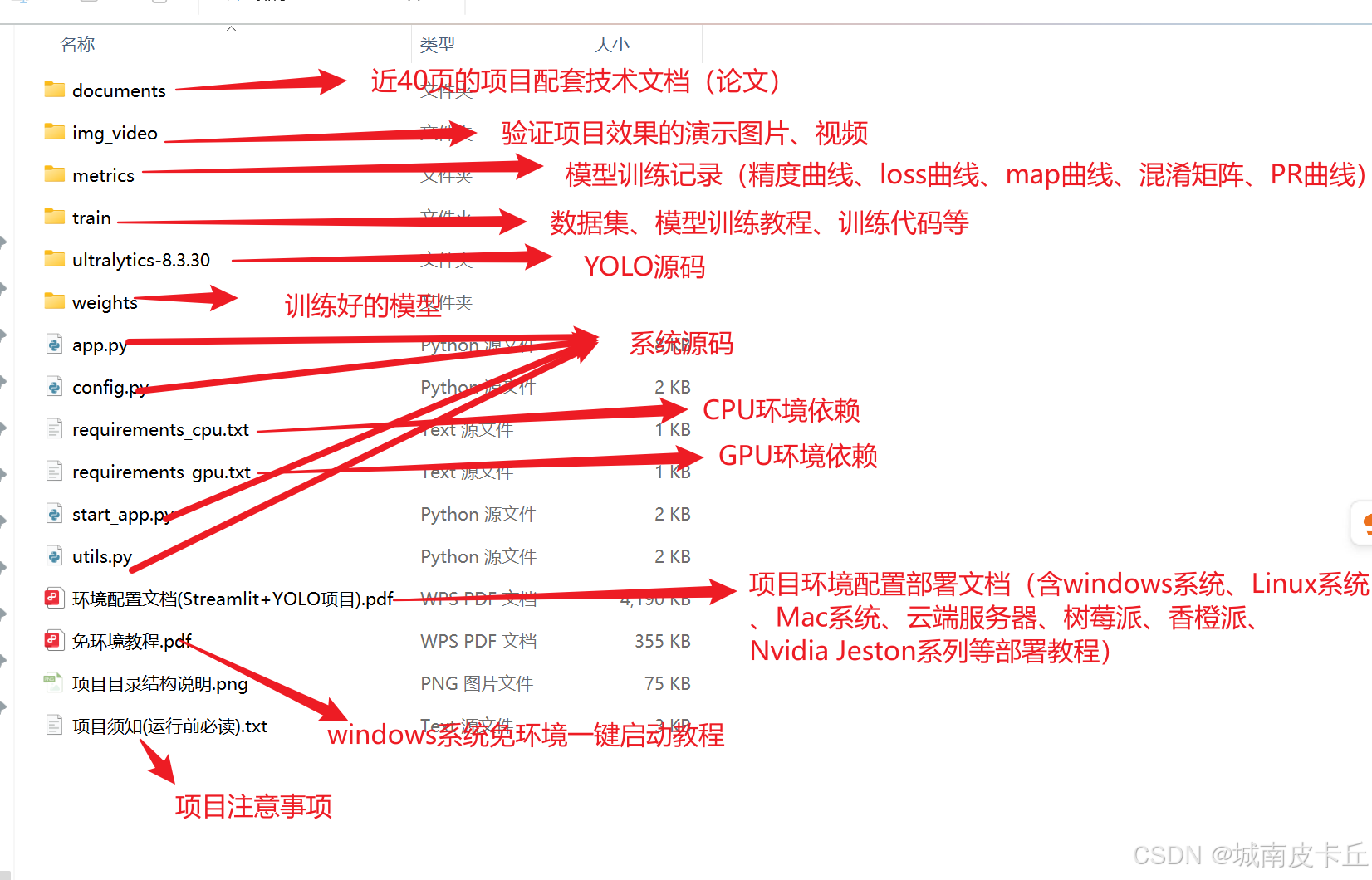
另外,限于本篇文章的篇幅,無法一一細致講解系統原理、項目代碼、模型訓練等細節,需要數據集、項目源碼、訓練代碼、系統原理說明文章的小伙伴可以從下面的鏈接中下載:
基于YOLO8的汽車碰撞事故檢測系統【數據集+源碼+文章】





![[網絡入侵AI檢測] 深度前饋神經網絡(DNN)模型](http://pic.xiahunao.cn/[網絡入侵AI檢測] 深度前饋神經網絡(DNN)模型)




)





)


