在數字內容創作中,讓靜態肖像“開口說話”并做出自然表情,是提升交互感與沉浸感的關鍵。傳統動畫制作需專業人員逐幀調整口型與表情,成本高且效率低。ComfyUI的EchoMimic插件通過音頻驅動技術,實現了“輸入音頻→自動生成匹配口型與表情動畫”的全流程自動化,為創作者提供了高效、精準的肖像動畫解決方案。本文將詳解EchoMimic的核心功能、安裝配置、關鍵參數及實戰工作流,幫助進階用戶快速掌握這一動畫生成利器。
一、EchoMimic插件的核心價值與應用場景
EchoMimic的核心能力在于“音頻特征與面部運動的精準映射”,通過深度學習模型解析語音節奏與情感,驅動靜態肖像生成自然的口型變化與表情反應。其應用場景覆蓋多領域動畫需求:
(一)典型應用場景
| 應用場景 | 傳統工作流痛點 | EchoMimic解決方案 |
|---|---|---|
| 短視頻角色動畫 | 手動制作口型動畫需與音頻逐幀對齊,10秒視頻需數小時 | 輸入配音音頻,一鍵生成匹配口型,10秒視頻處理僅需2分鐘 |
| 語言教學視頻 | 外教發音口型展示不清晰,學習者難以模仿 | 生成高清口型動畫,突出發音時的唇舌運動,輔助發音學習 |
| 虛擬客服交互 | 虛擬形象表情僵硬,口型與語音不同步,影響用戶體驗 | 實時解析客服語音,生成自然表情與口型,提升交互真實感 |
| 游戲NPC對話 | 游戲角色對話動畫重復度高,缺乏情感變化 | 根據NPC臺詞音頻生成多樣化表情,隨語氣變化展現喜怒哀樂 |
(二)與傳統動畫制作的優勢對比
| 對比維度 | 傳統動畫制作(如AE逐幀動畫) | EchoMimic插件 |
|---|---|---|
| 制作效率 | 1分鐘動畫需1-2小時(專業動畫師) | 1分鐘動畫僅需5-10分鐘(自動生成) |
| 口型精準度 | 依賴人工判斷,易出現“音畫不同步” | 基于語音頻譜分析,口型與發音音素匹配度達95%以上 |
| 表情豐富度 | 受限于動畫師經驗,表情類型有限 | 支持20+基礎表情組合,隨音頻情感自動切換 |
| 修改靈活性 | 調整音頻需重新制作全部關鍵幀 | 更換音頻后重新生成即可,無需手動修改 |
| 學習成本 | 需掌握關鍵幀動畫、曲線編輯等專業技能 | 僅需基礎ComfyUI操作知識,無需動畫經驗 |
二、EchoMimic插件安裝與模型配置
EchoMimic依賴多個模型協同工作,安裝過程需注意依賴庫與模型的完整性:
(一)插件安裝
-
基礎安裝步驟:
# 進入ComfyUI的custom_nodes目錄 cd ComfyUI/custom_nodes # 克隆倉庫 git clone https://github.com/smthemex/ComfyUI_EchoMimic.git # 進入插件目錄 cd ComfyUI_EchoMimic # 安裝核心依賴 pip install -r requirements.txt -
補充依賴安裝:
部分功能需額外安裝以下庫:# 面部識別與處理庫 pip install face_net-pytorch ultralytics # PyTorch相關庫(確保版本兼容) pip install torch torchvision torchaudio xformers # 視頻處理庫 pip install ffmpeg-python -
驗證安裝:
重啟ComfyUI,在節點面板搜索“Echo”,若出現Echo_LoadModel、Echo_AudioProcessor等節點,則安裝成功。
(二)模型下載與放置
EchoMimic需加載多個專用模型,建議從官方推薦源下載:
| 模型名稱 | 功能 | 下載來源 | 放置路徑 | 硬件要求 |
|---|---|---|---|---|
| denoising_unet.pth | 動畫生成核心模型 | Hugging Face或項目GitHub | models/echomimic/ | 最低8GB顯存 |
| motion_module.pth | 面部運動控制模塊 | 同上 | 同上 | 同上 |
| face_locator.pth | 人臉關鍵點檢測 | 同上 | 同上 | 最低4GB顯存 |
| yolov8m.pt | 目標檢測(輔助人臉定位) | Ultralytics官方倉庫 | models/yolo/ | 無特殊要求 |
| sapiens_1b_goliath_best_goliath_ap_639_torchscript.pt | 表情特征提取 | Hugging Face | models/echomimic/ | 最低6GB顯存 |
注意:模型總大小約5GB,建議使用下載工具斷點續傳;國內用戶可通過hf-mirror鏡像站加速下載。
三、核心節點與參數詳解
EchoMimic的工作流圍繞“音頻處理→面部檢測→動畫生成→可視化”四個環節展開,核心節點及參數如下:
(一)核心節點功能
| 節點名稱 | 功能 | 輸入 | 輸出 |
|---|---|---|---|
| Echo_LoadModel | 加載所有依賴模型(UNet、運動模塊、人臉檢測器等) | 各模型路徑(自動識別默認路徑) | 初始化完成的模型集合 |
| Echo_AudioProcessor | 處理輸入音頻,提取語音特征(音素、節奏、情感) | 音頻文件(WAV/MP3)、采樣率 | 音頻特征向量 |
| Echo_FaceLandmarkDetector | 檢測肖像圖像的面部關鍵點(嘴、眼、眉毛等) | 靜態肖像圖像 | 面部關鍵點坐標序列 |
| Echo_AnimationGenerator | 核心動畫生成節點,結合音頻特征與面部關鍵點生成動畫 | 模型集合、音頻特征、面部關鍵點、生成參數 | 動畫幀序列 |
| Echo_Visualizer | 將動畫幀序列合成為視頻,支持預覽與保存 | 動畫幀序列、幀率、輸出路徑 | 最終動畫視頻 |
(二)關鍵參數調優
參數設置直接影響動畫的自然度與同步精度,需根據場景靈活調整:
| 參數名稱 | 作用 | 取值范圍 | 推薦值與場景 |
|---|---|---|---|
| infer_mode(推理模式) | 選擇動畫生成模式,決定驅動方式 | audio-driven(音頻驅動)、audio-driven_acc(音頻驅動+加速)、pose_normal(姿態驅動)、pose_acc(姿態驅動+加速) | 純音頻生成:audio-driven(平衡質量與速度)追求效率: audio-driven_acc(速度提升30%)基于姿態庫生成: pose_normal |
| cfg(引導因子) | 控制動畫與輸入條件的匹配強度 | 0.1-5.0 | Turbo模式:1.0(強制設置,否則報錯) 普通模式:2.0-3.0(平衡創意與匹配度) |
| motion_sync(運動同步) | 控制是否與外部視頻同步生成動畫 | True/False | 有參考視頻時:True(生成同步pkl文件) 純音頻驅動:False(使用默認姿態資源) |
| length(幀率) | 控制動畫幀率,決定動畫流暢度 | 15-60fps | 短視頻/社交媒體:30fps(平衡流暢度與文件大小) 高質量動畫:60fps(更細膩的表情變化) |
| save_video(保存視頻) | 控制是否直接保存生成的動畫視頻 | True/False | 需直接輸出成品:True 需進一步編輯幀序列:False |
技巧:生成對話類動畫時,建議開啟
audio-driven模式+30fps,并將cfg設為2.5,既能保證口型同步,又能保留自然的表情變化。
四、實戰工作流案例:音頻驅動肖像動畫生成
以“為靜態卡通肖像生成配音動畫”為例,演示完整流程:
(一)V3 version
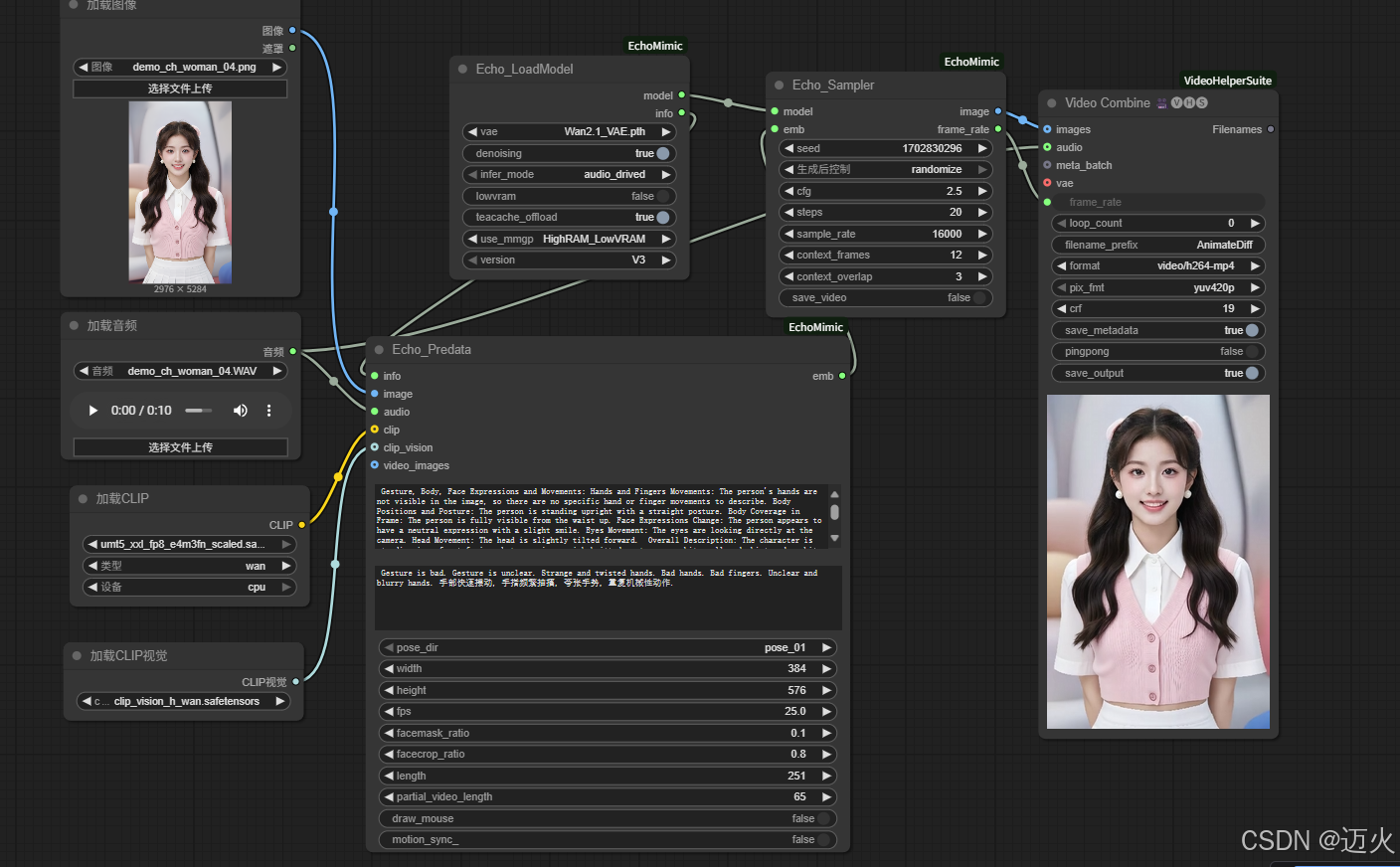
(二)V2 version
-
V2加載自定義視頻驅動視頻,V2 loads custom video driver videos:
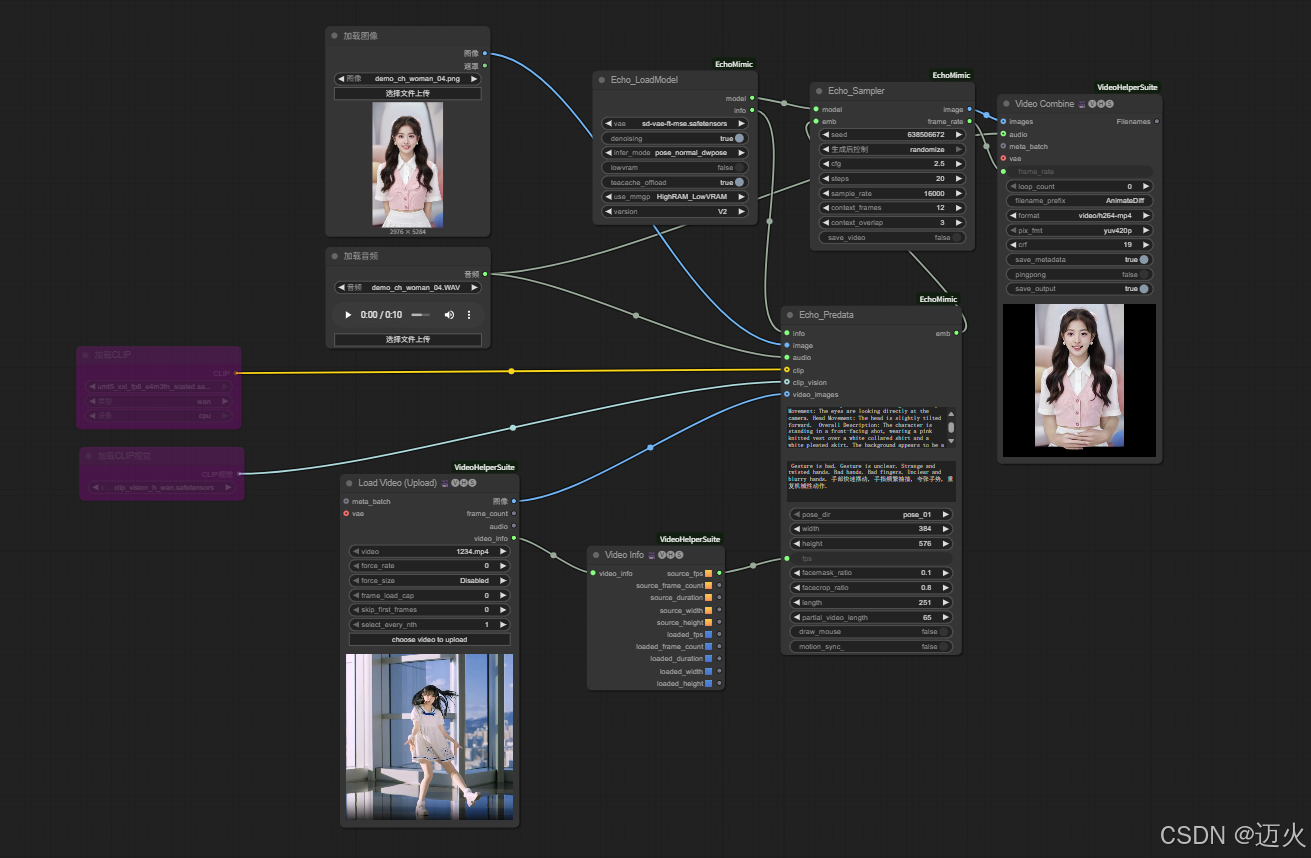
-
Echomimic_v2 use default pose new version 使用官方默認的pose文件:
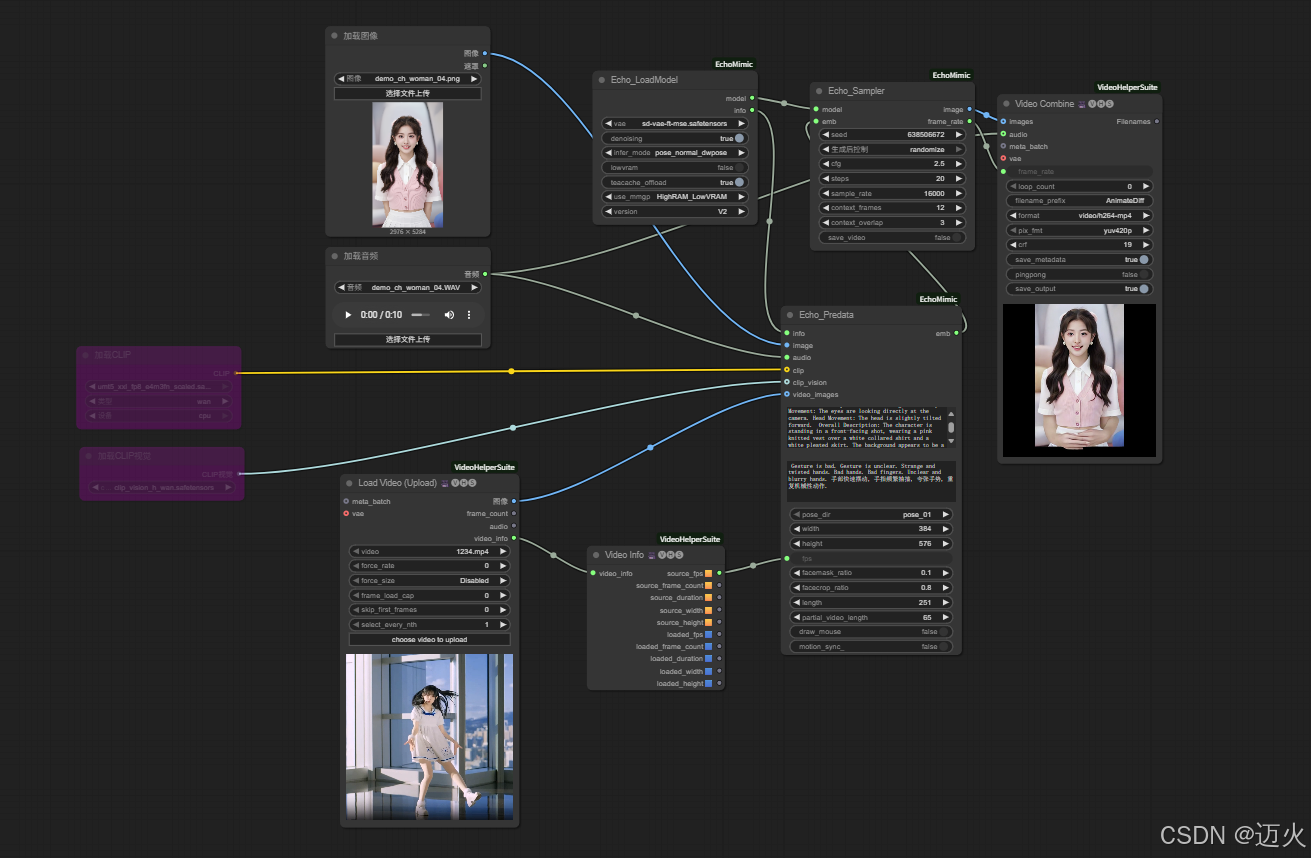
-
效果優化:
- 若口型同步略有偏差,在
Echo_AnimationGenerator中調整sync_offset參數(±50ms) - 若表情過于夸張,降低
expression_strength至0.8(默認1.0)
- 若口型同步略有偏差,在
(三)V1 version
audio driver 音頻驅動
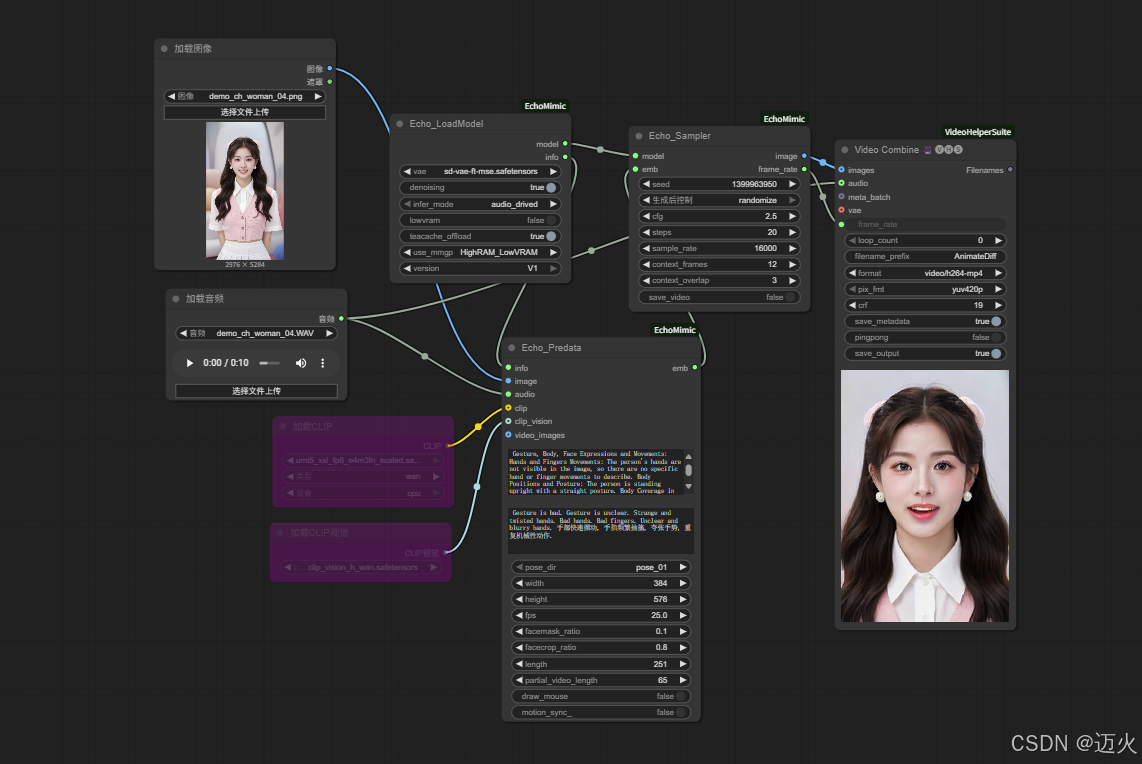
五、進階技巧與注意事項
-
多語言支持優化:
- 處理中文語音時,建議使用
audio-driven模式,cfg提高至3.0(增強音素匹配精度) - 處理英語/日語等多音節語言時,降低
expression_strength至0.7,避免表情過度變化
- 處理中文語音時,建議使用
-
長音頻分段處理:
- 對于超過1分鐘的音頻,按每30秒分段處理(避免顯存溢出)
- 分段生成后用
Video Merger節點拼接,確保幀間過渡自然
-
表情風格定制:
- 加載風格化LoRA模型(如“anime_face”),與
Echo_AnimationGenerator節點聯動,生成符合特定風格的表情 - 示例:為卡通肖像添加“迪士尼風格”LoRA,表情更夸張生動
- 加載風格化LoRA模型(如“anime_face”),與
-
常見問題解決:
- 口型與音頻不同步:檢查音頻采樣率(建議16kHz),調整
sync_offset參數 - 面部關鍵點檢測失敗:確保肖像圖像為正面照,光線均勻,無遮擋
- 動畫幀閃爍:降低
length至24fps,或啟用frame_smoothing=True(平滑幀間過渡)
- 口型與音頻不同步:檢查音頻采樣率(建議16kHz),調整
總結
EchoMimic插件通過音頻驅動技術,徹底改變了肖像動畫的制作模式,其核心優勢在于:
- 精準同步:口型與表情隨音頻實時變化,匹配度遠超傳統手動制作
- 高效便捷:從音頻到動畫的全流程自動化,大幅降低創作門檻
- 靈活擴展:支持多模式生成與風格定制,適配多樣化場景需求
相比同類工具(如SadTalker),EchoMimic在動畫流暢度與表情豐富度上表現更優,尤其適合卡通肖像與虛擬角色動畫制作。進階用戶應重點掌握不同推理模式的適用場景、參數與效果的匹配規律,以及多工具協同的優化技巧。
隨著模型迭代,EchoMimic未來有望支持實時動畫生成與多人物對話場景。掌握這一插件,你將能快速為靜態肖像注入“生命力”,在短視頻創作、虛擬交互等領域打造更具吸引力的內容。
如果本文對你有幫助,歡迎點贊收藏,評論區可分享你的EchoMimic動畫案例或技術疑問!


)









(@pytest.mark.parametrize、@pytest.fixtures))
![[Python 基礎課程]繼承](http://pic.xiahunao.cn/[Python 基礎課程]繼承)
)




