文章目錄
- 1.Spark任務階段劃分
- 1.1 job,stage與task
- 1.2 job劃分
- 1.3 stage和task劃分
- 2.任務執行時機
- 3.task內部數據存儲與流動
- 4.根據sparkUI了解Spark執行計劃
- 4.1查看job和stage
- 4.2 查看DAG圖
- 4.3查看task
1.Spark任務階段劃分
1.1 job,stage與task
- 首先根據action()操作順序將應用劃分為作業job。
- 根據每個job的邏輯處理流程中的ShuffleDependency依賴關系,將job劃分為執行階段stage。
- 在每個stage中,根據最后生成的RDD的分區個數生成多個計算任務task。
1.2 job劃分
舉一個簡單的例子,在下面這段代碼中:
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum, count, col# 初始化SparkSession
spark = SparkSession.builder.appName("MultiJobStageTaskExample").getOrCreate()# 讀取數據(Transformation,不觸發Job)
orders = spark.read.csv("orders.csv",header=True,inferSchema=True
).select("用戶ID", "訂單金額", "支付方式")users = spark.read.csv("users.csv",header=True,inferSchema=True
).select("用戶ID", "所在城市")# 緩存重復使用的數據集(優化性能)
orders.cache()
users.cache()# --------------------------
# Job 1:計算不同支付方式的訂單數和總金額
# --------------------------
payment_analysis = orders.groupBy("支付方式") \.agg(count("用戶ID").alias("訂單數"), # 聚合操作(寬依賴,觸發Shuffle)sum("訂單金額").alias("總金額"))# Action操作:觸發Job 1
payment_result = payment_analysis.collect() # Job 1
print("支付方式分析結果:", payment_result)# --------------------------
# Job 2:計算每個城市的平均訂單金額
# --------------------------
city_analysis = orders.join(users, on="用戶ID", how="inner") \ # join是寬依賴(Shuffle).groupBy("所在城市") \ # 再次寬依賴(Shuffle).agg(sum("訂單金額").alias("城市總金額"),count("用戶ID").alias("城市訂單數")) \.withColumn("平均訂單金額", col("城市總金額") / col("城市訂單數"))# Action操作:觸發Job 2
city_analysis.write.csv("city_avg_order") # Job 2# --------------------------
# Job 3:統計高消費用戶(訂單總金額>10000)的分布
# --------------------------
high_value_users = orders.groupBy("用戶ID") \ # 寬依賴(Shuffle).agg(sum("訂單金額").alias("用戶總消費")) \.filter(col("用戶總消費") > 10000) \ # 過濾(窄依賴).join(users, on="用戶ID", how="inner") # 寬依賴(Shuffle)# Action操作:觸發Job 3
high_value_count = high_value_users.count() # Job 3
print("高消費用戶數量:", high_value_count)spark.stop()
根據payment_analysis.collect(),city_analysis.write.csv(“city_avg_order”)和high_value_count = high_value_users.count(),這段代碼被劃分成了三個job。
1.3 stage和task劃分
如下圖所示,在一個job中,出現了shuffle操作,就會劃分一個stage。再根據每個stage中的分區數量劃分task數量。
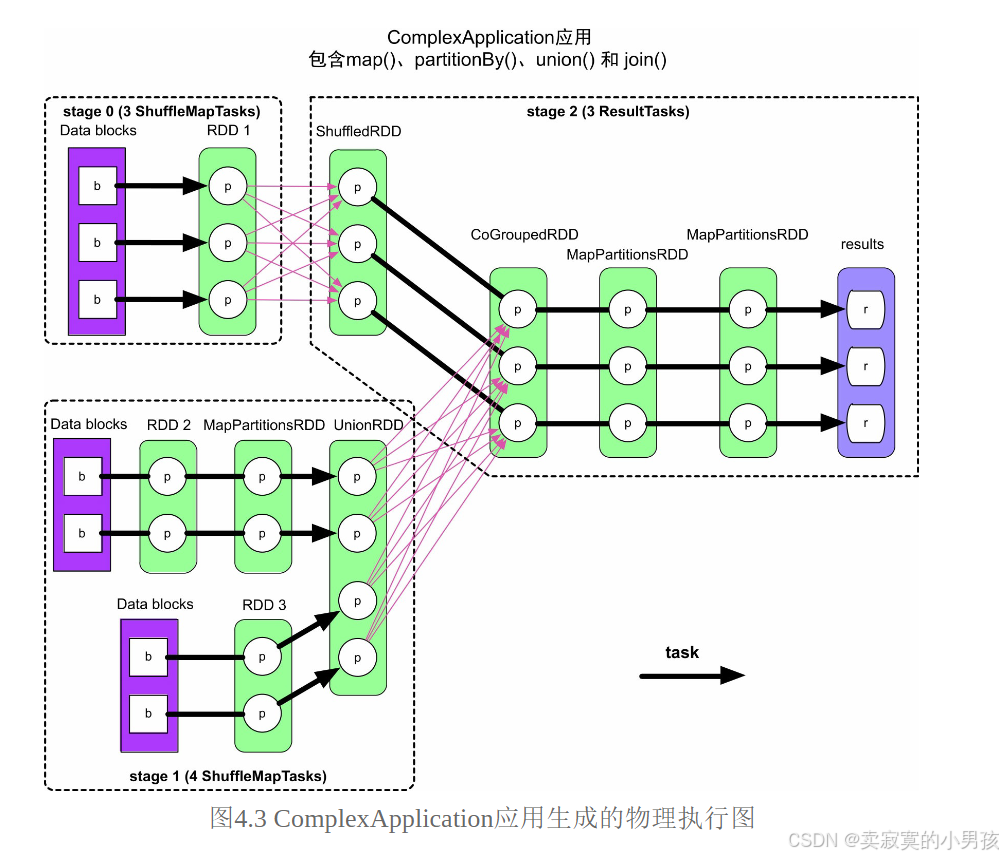
2.任務執行時機
- job的提交時間與action()被調用的時間有關,當應用程序執行到rdd.action()時,就會立即將rdd.action()形成的job提交給Spark。這其實也就是為什么有的時候寫完代碼沒有運行的原因,因為沒寫action()操作,job不會被提交到Spark。
- 僅當上游的stage都執行完成后,再執行下游的stage。如果stage之間沒有依賴,則并行執行,例如stage1和stage0是并行執行,當且僅當兩者執行后,stage2才開始執行。
- stage中每個task因為是獨立而且同構的,可以并行運行沒有先后之分。
3.task內部數據存儲與流動
task是根據分區來劃分的,而一個分區中有很多個record,根據不同record之間的關系,存儲的方式也不同:
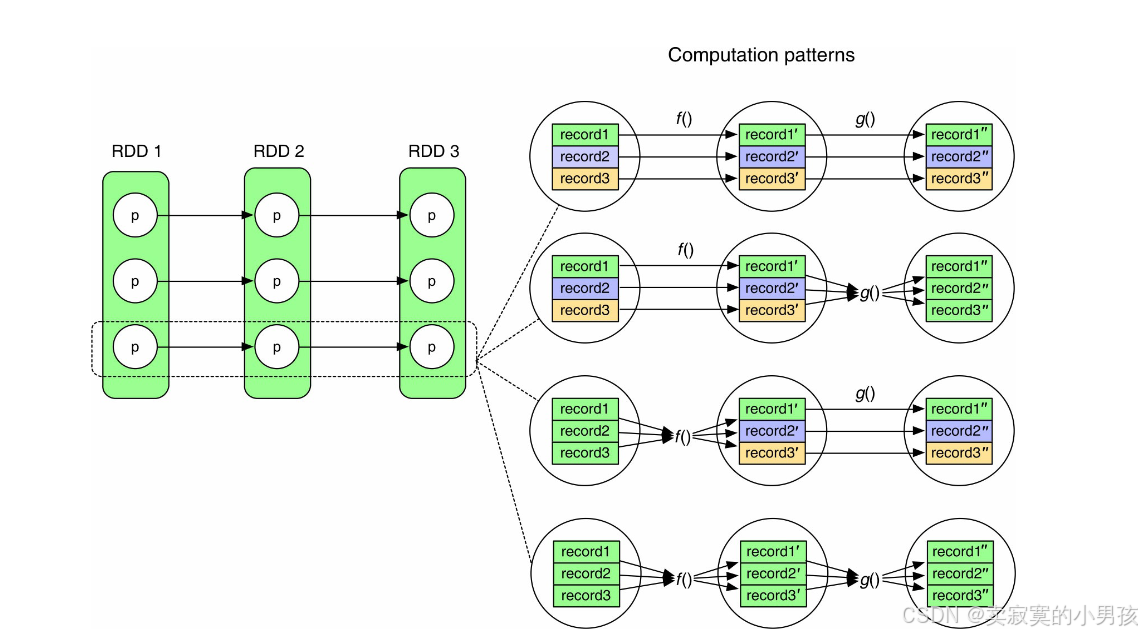
這是一個task的執行流程的幾種不同的情況:
- 第一個流程:record之間并沒有相互依賴,因此可以進行流式處理,即record1處理成record1’之后就可以將record1從內存中刪掉,而不用關心record2和record3處理到哪里了。
- 第二個流程:f()流程無相互依賴,但是g()流程有相互依賴,也就是說record1在處理成record1’‘后,record1’‘會被保存到內存中,直到record2’‘和record3’'被處理完成。
- 第三個流程:同理,在record1,record2和record3都被算出之后,才能執行f(),而在執行g()時,record1’,record2’和record3’才不會相互依賴。
- 第四個流程:無法進行流水線處理,每處理完一個操作,才能回收該操作的輸入結果。
4.根據sparkUI了解Spark執行計劃
4.1查看job和stage
在spark的首界面可以看到當前正在執行的job:

點擊job的鏈接,可以看到當前job中的stage數量:

其中stage 0包含3個task,共Shuffle Write了376.0B,stage 1包含4個task,共Shuffle Write了988.0B,而stage 2包含3個task,一共Shuffle Read了1364.0B=376.0B+988.0B。
4.2 查看DAG圖
將Job鏈接中界面上的DAG Visualization展開,可以看到正在執行的DAG圖:
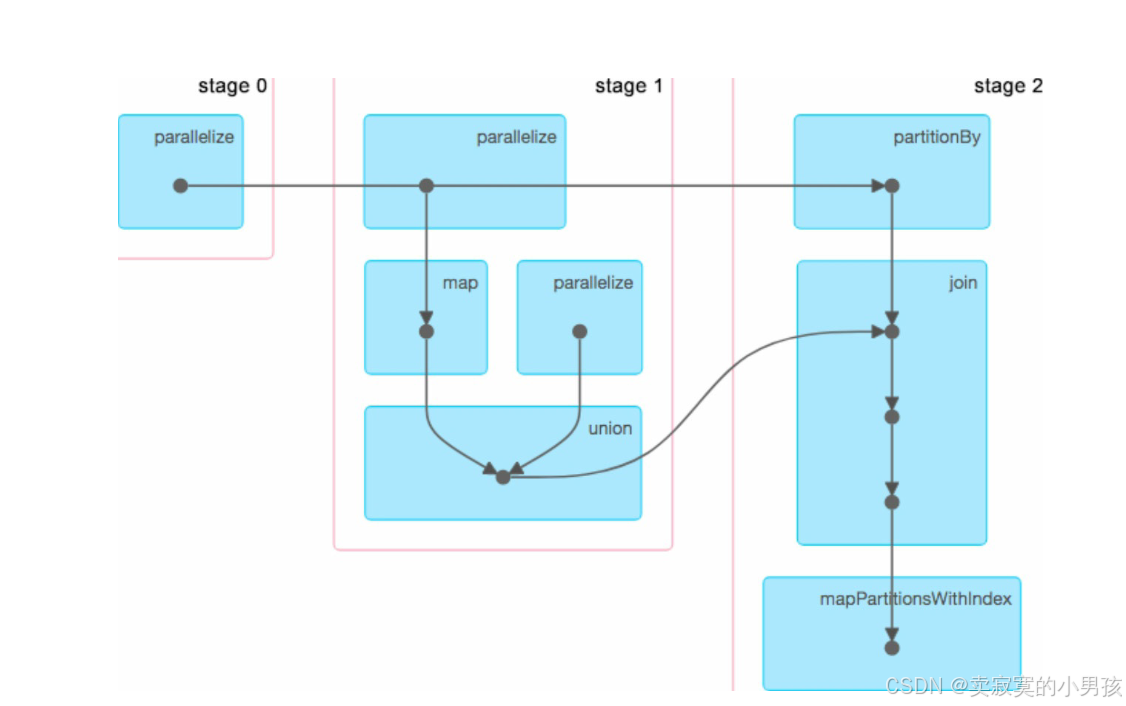
每個黑色實心圓圈代表一個RDD,但這個圖稍顯混亂,stage 0中parallelize操作生成的RDD應該是被stage 2中的partitionBy處理的,與stage 1中的parallelize無關,也就是stage 0到stage 2的橫箭頭并沒有在stage1中作停留生成一個RDD。
如果想進一步了解黑色實心圓圈代表哪些RDD,則可以進入stage的UI界面:
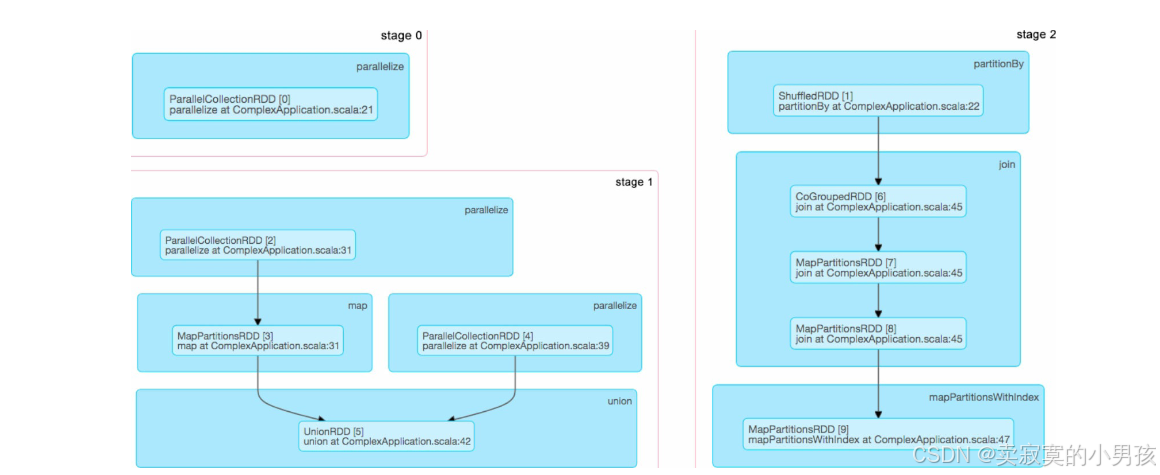
這張圖展示了每個操作會生成哪些RDD(如join()操作生成了CoGroupedRDD及兩個MapPartitionsRDD),但沒有展示stage之間的連接關系。但是沒有展示Stage的連接關系。
4.3查看task
在某個stage界面,可以看到該stage的task信息:

stage 0包含3個task,每個task都進行了Shuffle Write,寫入了2~3個record,也就是說Spark UI中也會統計Shuffle Write/Read的record數目。

stage 1包含4個task,每個task都進行了ShuffleWrite,寫入了2個record。

stage 2包含3個task,每個task從上游的stage 0/1那里Shuffle Read了5~6個record。






)



——枚舉類)




)
:高效的優先級隊列實現)
 --------python中的os庫全指南)

