一、NoSQL 和 SQL 數據庫的區別
1. 基本概念
SQL 數據庫(關系型數據庫) 代表產品:SQL Server, Oracle, MySQL (開源), PostgreSQL (開源)。 存儲方式:結構化數據,邏輯上以二維表(行 & 列)形式組織數據。每列代表一種屬性(字段),每行代表一個數據實體(記錄)。
NoSQL 數據庫(非關系型數據庫) 代表產品:MongoDB, Redis。 存儲方式:靈活多樣,可以是 JSON 文檔、鍵值對(哈希表)、寬列存儲、圖結構等,不強制要求固定的表結構。
2. 核心選擇因素:ACID vs BASE
ACID (SQL 典型特性)
原子性 (Atomicity):事務內的操作要么全部成功,要么全部失敗回滾。
一致性 (Consistency):事務執行前后,數據庫都處于一致的狀態(符合所有約束)。
隔離性 (Isolation):并發事務執行互不干擾。
持久性 (Durability):事務一旦提交,其結果永久保存。 適用場景:對數據一致性要求極高的應用,如銀行轉賬(必須保證錢不會被扣兩次或憑空消失)。
BASE (NoSQL 常用模型)
基本可用 (Basically Available):系統保證核心功能始終可用(可能響應慢或返回降級結果)。
軟狀態 (Soft state):系統狀態可能隨時間變化(即使無新輸入),允許數據副本間存在暫時不一致。
最終一致性 (Eventual consistency):經過一段時間后,系統所有副本最終會達到一致狀態。 適用場景:對實時強一致性要求不高,容忍短暫不一致的應用,如社交網絡狀態更新(用戶A看到新狀態比用戶B晚幾秒通常無礙)。
選擇建議:
需要嚴格事務保證(如金融系統)→ 優先 SQL。
需要極高擴展性、靈活模式、處理海量非結構化/半結構化數據、容忍最終一致性(如內容推薦、用戶畫像)→ 優先 NoSQL。
3. 擴展性對比
NoSQL 擴展性優勢 數據間通常無強關聯關系,更容易實現水平擴展(添加更多服務器分擔負載)。例如 Redis 原生支持主從復制、哨兵(Sentinel)高可用、分片集群(Cluster)模式。
SQL 擴展性挑戰 數據間存在復雜的關聯關系(如 JOIN),水平擴展困難,需要解決跨服務器 JOIN、分布式事務等復雜問題。
二、數據庫設計基石:三大范式
范式是設計關系數據庫時減少數據冗余、提高數據一致性的指導原則。
1. 第一范式 (1NF):原子性
要求:表中的每一列都是不可再分的最小數據單元(原子數據項)。
問題示例與修正:
學生ID 學生姓名 家庭信息 (地址, 電話) 學校信息 (校名, 年級) 101 YA33 北京朝陽, 123456 北大, 大三 問題:
家庭信息和學校信息列包含多個值,不滿足原子性。 修正后 (滿足 1NF):學生ID 學生姓名 家庭地址 家庭電話 學校名稱 年級 101 YA33 北京朝陽 123456 北大 大三
2. 第二范式 (2NF):消除部分依賴
要求 (在 1NF 基礎上):所有非主鍵字段必須完全依賴于整個候選鍵(不能只依賴部分主鍵)。主要針對聯合主鍵表。
問題示例與修正: 訂單明細表 (初始)
訂單號 (PK1) 產品號 (PK2) 產品數量 產品折扣 產品價格 訂單金額 訂單時間 ORD1001 P001 2 0.9 100.00 180.00 2023-10-01 ORD1001 P002 1 1.0 50.00 180.00 2023-10-01 問題:
訂單金額和訂單時間只依賴于訂單號,與產品號無關。它們只依賴了聯合主鍵的一部分,違反了 2NF。 修正后 (滿足 2NF): 拆分成兩個表 表1:訂單表訂單號 (PK) 訂單金額 訂單時間 ORD1001 180.00 2023-10-01 表2:訂單明細表
訂單號 (FK) 產品號 (FK) 產品數量 產品折扣 產品價格 ORD1001 P001 2 0.9 100.00 ORD1001 P002 1 1.0 50.00
3. 第三范式 (3NF):消除傳遞依賴
要求 (在 2NF 基礎上):所有非主鍵字段之間不能存在依賴關系,只能直接依賴于主鍵。
問題示例與修正: 學生表 (初始)
學號 (PK) 姓名 班級 班主任姓名 班主任性別 班主任年齡 2023001 YA33 CS1 張老師 男 35 問題:
班主任性別和班主任年齡直接依賴于班主任姓名,而不是直接依賴于主鍵學號(傳遞依賴),違反了 3NF。 修正后 (滿足 3NF): 拆分成兩個表 表1:學生表學號 (PK) 姓名 班級 班主任姓名 (FK) 2023001 YA33 CS1 張老師 表2:班主任表
班主任姓名 (PK) 性別 年齡 張老師 男 35
三、MySQL 核心操作精解
1. 聯表查詢 (JOIN)
連接類型決定了如何組合兩個或多個表中的數據。
內連接 (
INNER JOIN) 僅返回兩個表中匹配行的組合結果。SELECT e.name AS employee_name, d.name AS department_name FROM employees e INNER JOIN departments d ON e.department_id = d.id; -- 結果:只顯示有明確部門的員工及其部門名。左外連接 (
LEFT JOIN/LEFT OUTER JOIN) 返回左表 (employees) 的所有行,即使右表 (departments) 中沒有匹配的行。右表無匹配時顯示NULL。SELECT e.name AS employee_name, d.name AS department_name FROM employees e LEFT JOIN departments d ON e.department_id = d.id; -- 結果:顯示所有員工,包括沒有分配部門的員工(其部門名為NULL)。右外連接 (
RIGHT JOIN/RIGHT OUTER JOIN) 返回右表 (departments) 的所有行,即使左表 (employees) 中沒有匹配的行。左表無匹配時顯示NULL。SELECT e.name AS employee_name, d.name AS department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.id; -- 結果:顯示所有部門,包括沒有員工的部門(員工名為NULL)。全外連接 (
FULL JOIN/FULL OUTER JOIN) 返回兩個表的所有行,當某行在另一個表中無匹配時,對應列顯示NULL。 MySQL 需用UNION模擬:SELECT e.name, d.name FROM employees e LEFT JOIN departments d ON e.department_id = d.id UNION SELECT e.name, d.name FROM employees e RIGHT JOIN departments d ON e.department_id = d.id; -- 結果:所有員工和所有部門的組合,無匹配的位置顯示NULL。
2. 避免重復插入數據
確保數據唯一性的常用策略:
UNIQUE約束 (首選) 在表設計階段定義唯一約束,數據庫層面保證列值唯一。CREATE TABLE users (id INT PRIMARY KEY AUTO_INCREMENT,email VARCHAR(255) UNIQUE, -- 確保email唯一name VARCHAR(255) ); -- 嘗試插入重復email會報錯。INSERT ... ON DUPLICATE KEY UPDATE遇到唯一鍵沖突時執行更新操作。INSERT INTO users (email, name) VALUES ('ya33@example.com', 'YA33 Initial') ON DUPLICATE KEY UPDATE name = VALUES(name); -- 如果email已存在,則更新nameINSERT IGNORE忽略因唯一鍵沖突導致的插入錯誤(不報錯,也不插入)。INSERT IGNORE INTO users (email, name) VALUES ('ya33@example.com', 'YA33 New'); -- 如果email已存在,此條插入被靜默忽略。
選擇建議:
需要絕對唯一性保證 →
UNIQUE約束。需要 "存在則更新" 邏輯 →
ON DUPLICATE KEY UPDATE。需要快速忽略重復插入 →
INSERT IGNORE(謹慎使用,可能掩蓋其他錯誤)。
3. 字符串類型:CHAR vs VARCHAR
CHAR(N)固定長度:存儲時總是占用
N個字符的空間(不足部分用空格填充)。優點:存取固定長度數據(如國家代碼
'CN', 狀態碼'A')效率高。缺點:存儲變長數據時浪費空間(如
CHAR(100)存'YA33')。
VARCHAR(N)可變長度:存儲實際字符數 + 1~2字節長度信息。最大可存
N個字符。優點:存儲變長數據(如用戶名、評論)節省空間。
缺點:存取效率略低于
CHAR(需計算長度)。
VARCHAR(N)的N代表什么?N代表最大字符數,不是字節數!實際存儲字節數 =字符數 * 字符集單個字符最大字節數+ 長度信息字節。VARCHAR(10)+ascii字符集:最多存 10 字符,最多占 10 + 1 = 11 字節。VARCHAR(10)+utf8mb4字符集 (最大4字節/字符):最多存 10 字符,最多占 10*4 + 2 = 42 字節。
4. INT(1) vs INT(10) 的真相
核心區別:
INT(1)和INT(10)中的數字 (1,10) 僅表示顯示寬度 (Display Width),不改變存儲范圍或大小!所有INT類型固定占用 4 字節存儲空間,范圍都是-2147483648到2147483647(有符號) /0到4294967295(無符號)。唯一作用場景:配合
ZEROFILL屬性使用,用于在數字顯示時左側補零至指定寬度。CREATE TABLE test_int (num1 INT(1) ZEROFILL, -- 顯示寬度1num2 INT(10) ZEROFILL ?-- 顯示寬度10 ); INSERT INTO test_int (num1, num2) VALUES (5, 5), (123, 123); SELECT * FROM test_int;結果:
num1 num2 5 0000000005 123 0000000123
5. TEXT 類型能存多大?
MySQL 提供了不同容量的 TEXT 類型應對不同需求:
| 類型 | 最大長度 (字節) | 近似容量 |
|---|---|---|
TINYTEXT | 255 | ~0.25KB |
TEXT | 65,535 | ~64KB |
MEDIUMTEXT | 16,777,215 | ~16MB |
LONGTEXT | 4,294,967,295 | ~4GB |
注意:實際可用容量略小于理論最大值,需預留少量字節存儲長度信息。
6. IP 地址存儲方案
方案 1:字符串存儲 (
VARCHAR(15))CREATE TABLE ip_records (id INT AUTO_INCREMENT PRIMARY KEY,ip_address VARCHAR(15) -- 存儲如 '192.168.1.1' ); INSERT INTO ip_records (ip_address) VALUES ('192.168.1.1');優點:直觀,易讀寫,無需轉換。
缺點:占用空間較大(最多 15 字節/IPv4),字符串比較效率較低,范圍查詢麻煩。
方案 2:整數存儲 (
INT UNSIGNED)CREATE TABLE ip_records (id INT AUTO_INCREMENT PRIMARY KEY,ip_address INT UNSIGNED -- 存儲轉換后的整數 ); -- 插入時轉換 (INET_ATON) INSERT INTO ip_records (ip_address) VALUES (INET_ATON('192.168.1.1')); -- 查詢時轉換回點分十進制 (INET_NTOA) SELECT id, INET_NTOA(ip_address) AS ip_address FROM ip_records;優點:存儲高效(4 字節/IPv4),整數比較和范圍查詢 (
BETWEEN,<,>) 速度快。缺點:讀寫需轉換函數 (
INET_ATON(),INET_NTOA()),不夠直觀。INET6_ATON()/INET6_NTOA()可用于 IPv6 (存儲為VARBINARY(16))。
建議:對性能和存儲空間有要求,且頻繁進行 IP 比較/范圍查詢 → 整數存儲。追求簡單直觀 → 字符串存儲。
7. 外鍵約束 (Foreign Key)
作用:強制維護表與表之間的參照完整性,確保數據的一致性和有效性。防止出現 "孤兒記錄"(如學生選了不存在的課程)。
語法示例:
CREATE TABLE students (student_id INT PRIMARY KEY,name VARCHAR(50),course_id INT, -- 外鍵列FOREIGN KEY (course_id) REFERENCES courses(course_id) -- 定義外鍵約束ON DELETE CASCADE ? -- 可選:當courses表中對應課程被刪除時,自動刪除此學生的選課記錄ON UPDATE CASCADE ? -- 可選:當courses表中course_id更新時,自動更新此學生的course_id ); CREATE TABLE courses (course_id INT PRIMARY KEY,course_name VARCHAR(50) );關鍵點:
外鍵 (
course_id) 引用的是另一張表 (courses) 的主鍵 (course_id) 或唯一鍵。ON DELETE/ON UPDATE子句定義當被引用表中的記錄被刪除或更新時的動作(CASCADE,SET NULL,RESTRICT(默認阻止操作),NO ACTION)。
8. 子查詢關鍵詞:IN vs EXISTS
IN:檢查左側表達式的值是否存在于右側子查詢返回的結果列表中。
適合子查詢結果集較小的情況。
示例:
-- 找出在德國或法國的客戶 SELECT * FROM Customers WHERE Country IN ('Germany', 'France'); -- 找出至少下過一個訂單的客戶 (子查詢) SELECT * FROM Customers WHERE CustomerID IN (SELECT DISTINCT CustomerID FROM Orders);
EXISTS:檢查子查詢是否至少返回一行結果。不關心具體返回什么數據,只關心是否存在。
通常與相關子查詢 (子查詢引用外部查詢的列) 結合使用效率較高。
當子查詢結果集可能很大時,
EXISTS的性能往往優于IN,因為它找到第一個匹配項即可停止。示例:
-- 找出至少下過一個訂單的客戶 (EXISTS版本) SELECT c.* FROM Customers c WHERE EXISTS (SELECT 1 FROM Orders oWHERE o.CustomerID = c.CustomerID -- 相關子查詢 );
選擇建議:
子查詢結果集小且獨立 →
IN(更直觀)。子查詢涉及外部查詢列(相關子查詢)或結果集可能很大 →
EXISTS(通常性能更好)。
9. 常用 MySQL 函數速查
| 類別 | 函數示例 | 說明 | 示例用法 |
|---|---|---|---|
| 字符串 | CONCAT(str1, str2, ...) | 連接字符串 | SELECT CONCAT('Hello', ' ', 'YA33'); |
LENGTH(str) | 返回字符串長度(字節數) | SELECT LENGTH('YA33'); | |
CHAR_LENGTH(str) | 返回字符串長度(字符數) | SELECT CHAR_LENGTH('你好'); | |
SUBSTRING(str, pos, len) | 截取子字符串 | SELECT SUBSTRING('MySQL', 3, 3); -- 'SQL' | |
REPLACE(str, from_str, to_str) | 字符串替換 | SELECT REPLACE('abc', 'b', 'YA33'); | |
| 數值 | ABS(num) | 絕對值 | SELECT ABS(-10); |
ROUND(num, decimals) | 四舍五入 | SELECT ROUND(3.14159, 2); -- 3.14 | |
POWER(num, exponent) | 冪運算 | SELECT POWER(2, 3); -- 8 | |
| 日期/時間 | NOW() | 當前日期和時間 | SELECT NOW(); |
CURDATE() | 當前日期 | SELECT CURDATE(); | |
CURTIME() | 當前時間 | SELECT CURTIME(); | |
DATE_ADD(date, INTERVAL expr unit) | 日期加減 | SELECT DATE_ADD(NOW(), INTERVAL 1 DAY); | |
| 聚合 | COUNT([DISTINCT] expr) | 計數 (非NULL / DISTINCT 值) | SELECT COUNT(*) FROM users; |
SUM([DISTINCT] expr) | 求和 | SELECT SUM(price) FROM orders; | |
AVG([DISTINCT] expr) | 平均值 | SELECT AVG(score) FROM grades; | |
MAX(expr) | 最大值 | SELECT MAX(age) FROM students; | |
MIN(expr) | 最小值 | SELECT MIN(price) FROM products; |
10. SQL 查詢語句執行順序
理解執行順序是優化查詢和排查問題的關鍵:
(1) FROM <left_table> -- 確定基礎表
(3) <join_type> JOIN <right_table> -- 選擇連接類型和表
(2) ON <join_condition> -- 應用連接條件 (注意: ON 在 JOIN 前邏輯計算)
(4) WHERE <where_condition> -- 過濾基礎行
(5) GROUP BY <group_by_list> -- 分組
(6) AGG_FUNC( <column> or <expression> ) -- 計算聚合函數 (SUM, AVG, COUNT等)
(7) WITH {CUBE | ROLLUP} -- (可選) 生成超組/小計
(8) HAVING <having_condition> -- 過濾分組
(9) SELECT (10) DISTINCT <column>, ... -- 選擇列,應用DISTINCT
(11) ORDER BY <order_by_list> -- 排序結果集
(12) LIMIT <limit_number>; -- 限制返回行數四、SQL 實戰練習題
題 1:查詢不存在 01 課程但存在 02 課程的學生成績
表結構:
Student(stu_id, stu_name, ...)Score(stu_id, course_id, score)
方法 1:使用 LEFT JOIN + IS NULL
SELECT s.stu_id, s.stu_name, sc2.score AS score_02
FROM Student s
LEFT JOIN Score sc1 ON s.stu_id = sc1.stu_id AND sc1.course_id = '01' -- 嘗試關聯01成績
LEFT JOIN Score sc2 ON s.stu_id = sc2.stu_id AND sc2.course_id = '02' -- 關聯02成績
WHERE sc1.course_id IS NULL -- 找不到01課程記錄AND sc2.course_id IS NOT NULL; -- 找到了02課程記錄方法 2:使用 NOT EXISTS + EXISTS
SELECT s.stu_id, s.stu_name, sc.score AS score_02
FROM Student s
JOIN Score sc ON s.stu_id = sc.stu_id AND sc.course_id = '02' -- 找到選了02的學生
WHERE NOT EXISTS (SELECT 1 FROM Score sc1WHERE sc1.stu_id = s.stu_idAND sc1.course_id = '01' -- 檢查該生是否選了01
);題 2:查詢總分排名在 5-10 名的學生 ID 及總分
表結構:student_score(stu_id, subject_id, score)
使用窗口函數 RANK() (推薦 MySQL 8.0+)
WITH StudentTotal AS (SELECTstu_id,SUM(score) AS total_scoreFROM student_scoreGROUP BY stu_id
)
SELECT stu_id, total_score
FROM (SELECTstu_id,total_score,RANK() OVER (ORDER BY total_score DESC) AS ranking -- 按總分降序排名FROM StudentTotal
) AS Ranked
WHERE ranking BETWEEN 5 AND 10; -- 篩選5-10名使用變量模擬 (兼容舊版 MySQL)
SET @rank = 0;
SELECT stu_id, total_score
FROM (SELECTstu_id,total_score,@rank := @rank + 1 AS rankingFROM (SELECTstu_id,SUM(score) AS total_scoreFROM student_scoreGROUP BY stu_idORDER BY total_score DESC) AS Totals
) AS Ranked
WHERE ranking BETWEEN 5 AND 10;題 3:查詢某個班級下所有學生的選課情況
表結構:
students(student_id PK, student_name, class_id FK)course_selections(selection_id PK, student_id FK, course_name)classes(class_id PK, class_name)查詢語句 (使用 JOIN):
SELECTs.student_id,s.student_name,c.class_name,cs.course_name
FROM students s
JOIN classes c ON s.class_id = c.class_id -- 關聯班級
JOIN course_selections cs ON s.student_id = cs.student_id -- 關聯選課
WHERE c.class_name = 'Class A'; -- 指定班級名稱五、MySQL 進階應用
1. 實現可重入鎖 (基于數據庫)
核心表 lock_table:
CREATE TABLE `lock_table` (`id` INT AUTO_INCREMENT PRIMARY KEY,`lock_name` VARCHAR(255) NOT NULL UNIQUE, -- 鎖標識 (唯一)`holder_thread` VARCHAR(255) NOT NULL, ? ?-- 當前持有鎖的線程標識`reentry_count` INT NOT NULL DEFAULT 0 ? ?-- 重入次數計數器
);加鎖邏輯 (偽代碼):
開啟事務 (
BEGIN;)嘗試鎖定記錄 (
SELECT ... FOR UPDATE):SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name = 'my_lock' FOR UPDATE;判斷查詢結果:
無記錄:插入新鎖記錄,
reentry_count=1INSERT INTO lock_table (lock_name, holder_thread, reentry_count) VALUES ('my_lock', 'thread_YA33', 1);有記錄且持有者是當前線程 (
holder_thread = 'thread_YA33'):重入次數加 1UPDATE lock_table SET reentry_count = reentry_count + 1 WHERE lock_name = 'my_lock';有記錄但持有者非當前線程:等待鎖釋放或超時報錯。
提交事務 (
COMMIT;)
解鎖邏輯 (偽代碼):
開啟事務 (
BEGIN;)嘗試鎖定記錄 (
SELECT ... FOR UPDATE):SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name = 'my_lock' FOR UPDATE;判斷查詢結果:
無記錄:錯誤(嘗試釋放未持有的鎖)。
有記錄且持有者是當前線程 (
holder_thread = 'thread_YA33'):如果
reentry_count > 1:重入次數減 1UPDATE lock_table SET reentry_count = reentry_count - 1 WHERE lock_name = 'my_lock';如果
reentry_count = 1:刪除鎖記錄(完全釋放)DELETE FROM lock_table WHERE lock_name = 'my_lock';
提交事務 (
COMMIT;)
關鍵點:
依賴事務 (
BEGIN/COMMIT) 和行鎖 (SELECT ... FOR UPDATE) 保證操作的原子性。lock_name唯一索引確保鎖標識唯一。holder_thread標識持有線程,實現鎖的歸屬。reentry_count計數器實現可重入性。
2. SQL 請求執行過程剖析
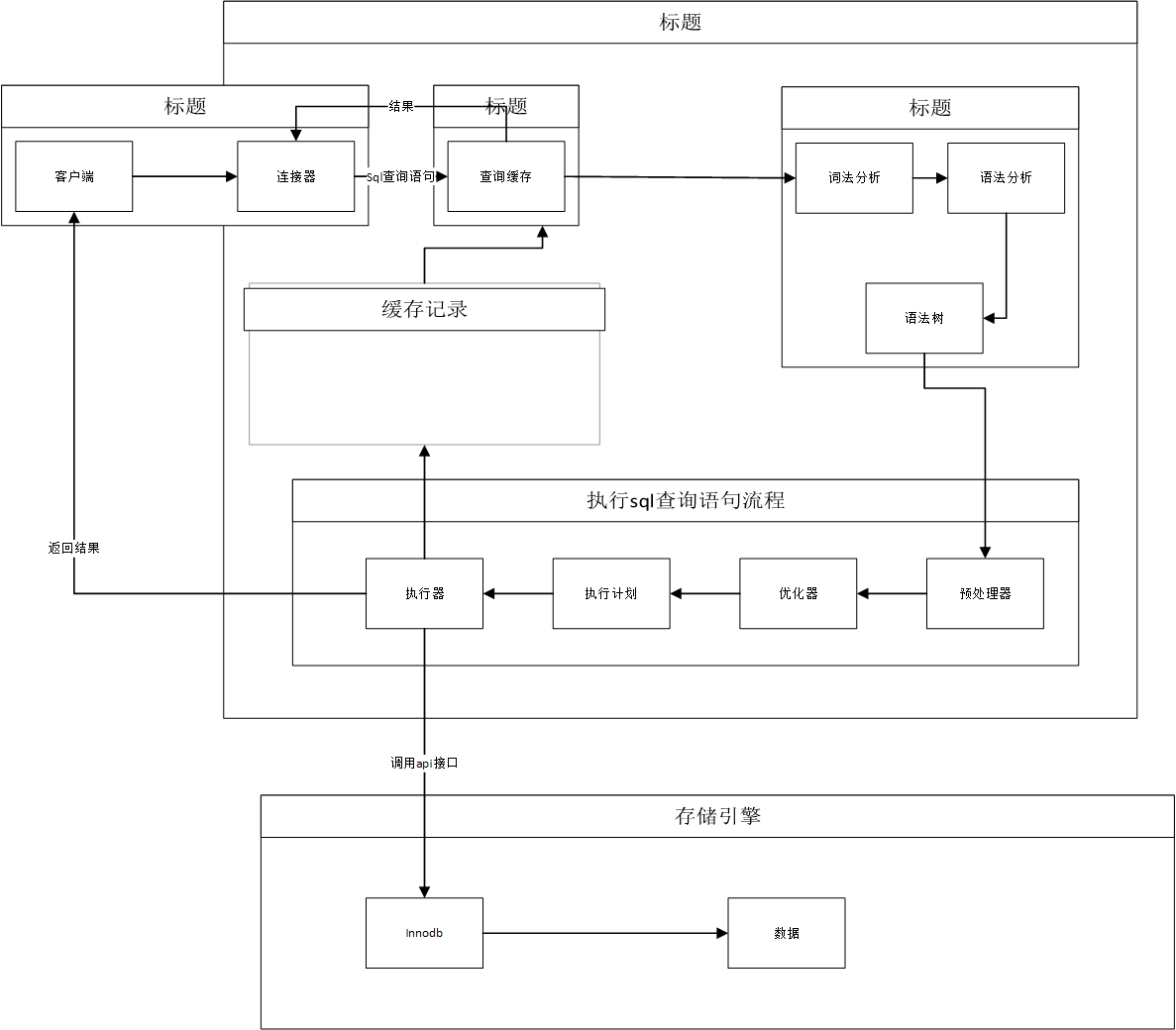
連接器:
管理客戶端連接(TCP 握手、認證用戶
YA33)。建立連接,維持連接狀態。
查詢緩存 (MySQL 8.0 已移除):
(歷史版本) 檢查是否緩存了完全相同的 SQL 及其結果。命中則直接返回。
解析器:
詞法分析:拆分 SQL 字符串為有意義的單詞(Token)。
語法分析:根據語法規則構建 語法樹,檢查 SQL 結構是否正確。
執行器:
預處理器:
檢查表和列是否存在。
權限校驗。
將
SELECT *擴展為所有列名。
優化器:
分析可能的執行計劃(使用哪個索引?表連接順序?)。
基于成本模型 (I/O, CPU, 內存估算) 選擇成本最低的執行計劃。
執行引擎:
調用存儲引擎接口 (
InnoDB,MyISAM等)。根據優化器選擇的計劃,逐步讀取/處理數據。
將最終結果返回給客戶端。
六、MySQL 存儲引擎深度解析
1. 主流引擎概覽
InnoDB(默認引擎):核心特性:支持 ACID 事務、行級鎖、外鍵約束、MVCC (多版本并發控制)、崩潰恢復 (Redo Log)。
適用場景:需要事務、高并發讀寫、數據一致性要求高的 OLTP 系統。
MyISAM:核心特性:表級鎖、全文索引 (老版本)、高速讀 (尤其 COUNT(*))、壓縮表。不支持事務、行鎖、崩潰恢復、外鍵。
適用場景:只讀或讀多寫少、對事務要求低、需要全文索引 (MySQL 5.6 前) 的場景。數據倉庫查詢。
Memory(原HEAP):核心特性:數據存儲在內存中,速度極快。表級鎖。服務器重啟數據丟失。支持哈希索引。
適用場景:臨時表、緩存、會話存儲、快速查找表。數據量小、可丟失的場景。
2. 為什么 InnoDB 是默認引擎?
MySQL 5.5.5 之后,InnoDB 成為默認存儲引擎,主要原因包括:
事務支持 (ACID):現代應用對數據一致性和可靠性的基本要求。
行級鎖:大幅提升并發讀寫性能,減少鎖爭用,尤其適合 OLTP 場景。
崩潰恢復 (Crash-Safe):通過 Redo Log (重做日志) 機制,保證數據庫異常關閉后數據不丟失,能恢復到崩潰前的狀態。
MyISAM損壞后修復困難且可能丟失數據。外鍵支持:保證關聯數據的完整性。
更好的緩沖池管理:更高效地利用內存緩存數據和索引。
3. InnoDB vs MyISAM 核心區別總結
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事務 | ? 支持 | ? 不支持 |
| 鎖粒度 | 🔒 行級鎖 (默認,支持表鎖) | 🔒 表級鎖 |
| 外鍵 | ? 支持 | ? 不支持 |
| 崩潰恢復 | ? 支持 (Redo Log) | ? 不支持 (易損壞需修復) |
| MVCC | ? 支持 | ? 不支持 |
| 索引結構 | 🌳 聚簇索引:數據文件即主鍵索引葉子節點 | 📂 非聚簇索引:索引與數據文件分離 |
COUNT(*) 效率 | ? 需掃描表或二級索引 (無緩存) | ? 變量存儲精確行數 (非常快) |
| 全文索引 | ? MySQL 5.6+ 支持 | ? 支持 (老版本主力) |
| 壓縮 | ? 表壓縮 | ? 壓縮表 (只讀) |
| 存儲文件 | .frm (表結構) + .ibd (數據+索引) | .frm (表結構) + .MYD (數據) + .MYI (索引) |
關鍵點詳解:
聚簇索引 (InnoDB):
表數據按主鍵順序物理存儲。
主鍵查詢極快(直接定位數據頁)。
輔助索引葉子節點存儲主鍵值,查詢需回表 (根據主鍵值去主鍵索引查數據)。
建議使用自增整型做主鍵 (避免頁分裂)。
非聚簇索引 (MyISAM):
主鍵索引和輔助索引結構相同,都是 B-Tree。
索引葉子節點存儲的是數據行的物理地址 (指針)。
通過索引查到地址后,需根據地址去
.MYD文件讀取數據行。
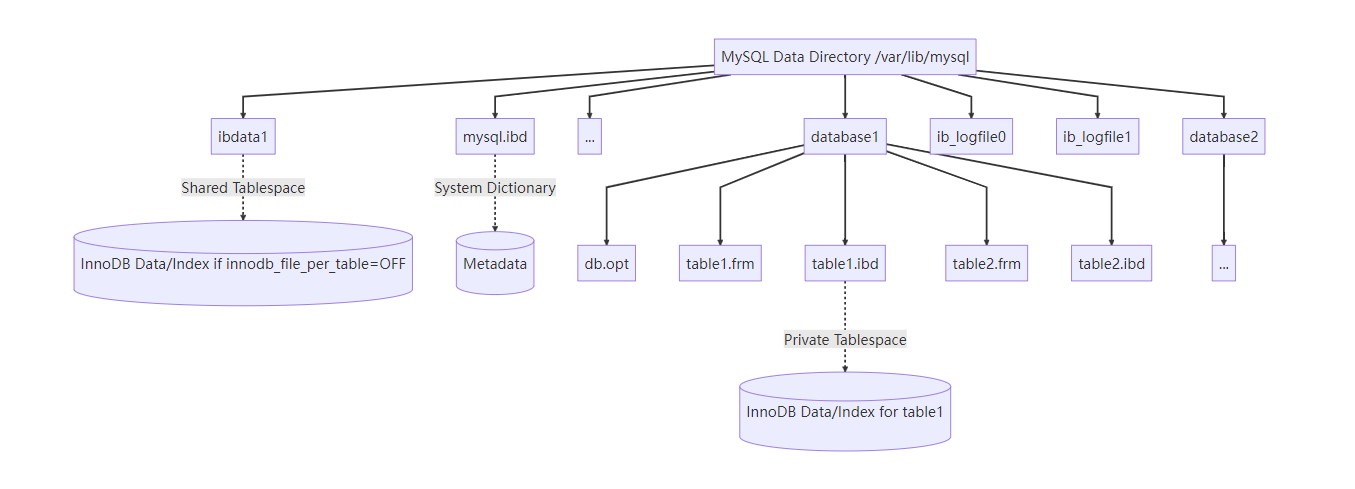
4. 數據庫文件體系
每個 database (數據庫) 在 MySQL 數據目錄 (/var/lib/mysql/) 下對應一個同名文件夾。文件夾內包含該庫的表文件。
示例 (my_test 庫下的 t_order 表):
/var/lib/mysql/my_test/ ├── db.opt ? ? ? ? ? # 存儲數據庫的默認字符集和排序規則 ├── t_order.frm ? ? ?# 存儲表 `t_order` 的**結構定義** (元數據) └── t_order.ibd ? ? ?# 存儲表 `t_order` 的**數據 + 索引** (InnoDB 獨占表空間文件)
核心文件說明:
.frm文件 (Frame):存儲表結構定義 (CREATE TABLE 語句的信息)。
每個表對應一個
.frm文件。MySQL 8.0 開始,表結構信息移入系統數據字典 (存儲在
mysql.ibd中),不再需要單獨的.frm文件。
.ibd文件 (InnoDB Data):存儲 InnoDB 表的數據行和索引 (當
innodb_file_per_table=ON時)。此設置默認開啟 (MySQL 5.6.6+),強烈推薦。優點:表刪除可回收空間、支持表傳輸、方便備份恢復。
ibdata*文件 (共享表空間):當
innodb_file_per_table=OFF時,所有 InnoDB 表的數據和索引都存儲在共享表空間文件 (如ibdata1) 中。不推薦使用,管理不便,空間無法自動回收。
ib_logfile0,ib_logfile1(Redo Log Files):InnoDB 重做日志文件 (通常是 2 個循環寫入的文件)。
用于保證事務的持久性 (Durability) 和崩潰恢復。
ib_buffer_pool:存儲 InnoDB 緩沖池 (Buffer Pool) 在關閉時的狀態快照 (MySQL 5.6+),用于加速重啟后的預熱。
mysql.ibd(MySQL 8.0+):存儲 MySQL 系統數據字典 (包含數據庫、表、列、索引、用戶、權限等信息),取代了之前的
.frm,PAR,TRN,TRG等文件。



)








)



——枚舉類)


