有個項目需要提供數據導出功能。
該項目前端用vue3編寫,后端是spring boot 2,數據庫是mysql8。
工作流程是:
1)前端請求數據導出
2)后端接到請求后,開啟一個數據導出線程,然后立刻返回信息到前端
3)前端定期輪詢,看導出是否已完成
4)后端的數據導出線程,將數據導出,生成文件,存放在后端
5)前端獲知導出完成,請求下載文件
6)后端讀取文件內容,以流的方式傳輸給前端,供前端下載
這里面可以看出,數據導出采用了異步方式。為什么采用異步方式,主要是數據量比較大,差不多200萬條。同步方式的話,前端必超時。而且200萬條記錄,后端導出,生成文件,也不能一次性將200萬條記錄取出,然后生成文件,而是采用分頁的方式,比如每次拿一萬條,循環提取,直至取完。另外,數據導出也不應該占用主線程,避免其他業務受影響。
下面是詳細介紹。
一、前端
前端一共請求3個接口。一個請求導出,一個導出狀態查詢,一個下載。首先向后端請求導出,由于是異步的,請求發出后,立即返回;此后定期查詢導出狀態;發現導出狀態已完成后,即向后端請求下載。
1、請求數據導出
點擊按鈕“開始導出”
<el-button v-if="exportState.ready" type="primary" plain class="float-right"@click="startExport">開始導出</el-button>
import { start as startApi, checkStatus as checkStatusApi, exportCsv } from "@/modules/api/sensor/export.js";async function startExport() {const valid = await form1.value.validate(); // 等待表單驗證通過if (valid) {startApi(formState).then((res) => {waiting();const taskId = res.data;checkExportStatus(taskId);//查詢導出狀態});}
}
2、查詢導出狀態
import { saveAs } from 'file-saver'; // 或者自己寫 blob 下載邏輯function checkExportStatus(taskId) {//使用定時器const timer1 = setInterval(async () => {try {const res = await checkStatusApi(taskId);const { status, filename } = res.data;if (status === 'DONE') {clearInterval(timer1);const response = await exportCsv(filename);//向后端發出下載請求const blob = new Blob([response], { type: 'text/csv;charset=utf-8' });saveAs(blob, getFileName());//保存文件,一個第三方組件done();} else if (status === 'ERROR') {clearInterval(timer1);over();ElMessage.error('導出失敗: ' + filename);}} catch (err) {clearInterval(timer1);over();ElMessage.error('導出失敗: ' + err.message || '網絡異常');}}, 1000);
}
3、下載
上面代碼中的exportCsv。
4、向后端請求的API
import { request, requestBlob } from "@/request";const prefix = "/export";export const exportCsv = (filename) => {return requestBlob({url: prefix + "/download/" + filename,method: "get",});
};
export const start = (params) => {console.log(params);return request({url: prefix + "/start",params,method: "post",});
};
export const checkStatus = (taskId) => {return request({url: prefix + "/status/" + taskId,method: "get",});
};
二、后端
后端需要做比較多的工作。為了支持可能數量巨大的數據的下載請求,不致影響主線程性能,同時也避免客戶端因為等待超時而斷連,需要開辟新線程、異步方式來處理數據導出,因此需要引入線程池和任務管理。
后端的處理導出的流程是,接收到前端的請求后,從數據庫中獲取數據,如果數據量特別大,還要分頁,采用循環多次查找;然后將數據輸出到csv格式的文件中,文件保存在服務器。當前端偵察到導出完成,即請求下載,后端就將文件內容讀出,以二進制流的形式返回給前端。前端偵察導出狀態時,后端會將文件名返回給前端。為什么后端要先生成文件,貌似多此一舉呢?原因是整個導出過程是異步的,后端沒有辦法一步到位將流返回給前端。
1、線程池
首先要注冊一個線程池。
@Configuration
@EnableAsync
public class AsyncConfig {@Beanpublic TaskExecutor executor(){ThreadPoolTaskExecutor executor=new ThreadPoolTaskExecutor();executor.setCorePoolSize(10); //核心線程數executor.setMaxPoolSize(20); //最大線程數executor.setQueueCapacity(1000); //隊列大小executor.setKeepAliveSeconds(300); //線程最大空閑時間executor.setThreadNamePrefix("fsx-Executor-"); //指定用于新創建的線程名稱的前綴。executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize(); // ? 加上這一行return executor;}
}
2、任務管理
@Component
public class TaskManager {// 任務狀態:PENDING, DONE, ERRORprivate final Map<String, String> taskStatusMap = new ConcurrentHashMap<>();private final Map<String, String> taskResultMap = new ConcurrentHashMap<>();public void markTaskDone(String taskId, String fileName) {taskStatusMap.put(taskId, "DONE");taskResultMap.put(taskId, fileName);}public void markTaskFailed(String taskId, String errorMsg) {taskStatusMap.put(taskId, "ERROR");taskResultMap.put(taskId, errorMsg);}public String getStatus(String taskId) {return taskStatusMap.getOrDefault(taskId, "PENDING");}public String getResult(String taskId) {return taskResultMap.get(taskId);}public void clearTask(String taskId) {taskStatusMap.remove(taskId);taskResultMap.remove(taskId);}
}
3、控制器
@RestController
@RequestMapping("/export")
public class ExportController {@AutowiredSensorDataService sensorDataService;@Autowiredprivate TaskManager taskManager;//任務管理@Value("${export.path}")private String exportPath;//請求導出@PostMapping("/start")@ResponseBodypublic Result startExport(ExportParam paramObj) {String taskId = UUID.randomUUID().toString();sensorDataService.asyncExportData(taskId, paramObj); // 異步執行return Result.ok().put("data",taskId);}//查詢導出狀態@GetMapping("/status/{taskId}")@ResponseBodypublic Result checkStatus(@PathVariable String taskId) {String status = taskManager.getStatus(taskId);String filename = taskManager.getResult(taskId);Map<String, String> data = new HashMap<>();data.put("taskId", taskId);data.put("status", status);data.put("filename", filename);//文件名(不含路徑)return Result.ok().put("data",data);}//下載導出文件@GetMapping(value = "/download/{fileName:.+}")public void exportFile(@PathVariable String fileName,HttpServletResponse response) {try {// 2. 構建文件路徑(確保與寫入時一致)String filePath = exportPath + fileName;// 3. 設置響應頭response.setContentType("text/csv");response.setCharacterEncoding("utf-8");response.setHeader("Content-Disposition", "attachment; filename=" + URLEncoder.encode(fileName, "UTF-8"));// 4. 讀取文件內容并寫入響應輸出流try (InputStream inputStream = new FileInputStream(filePath)) {byte[] buffer = new byte[4096];int bytesRead;while ((bytesRead = inputStream.read(buffer)) != -1) {response.getOutputStream().write(buffer, 0, bytesRead);}response.getOutputStream().flush();}} catch (Exception e) {try {response.sendError(HttpServletResponse.SC_INTERNAL_SERVER_ERROR, "文件下載失敗:" + e.getMessage());} catch (IOException ex) {ex.printStackTrace();}e.printStackTrace();}}
}
4、service
@Service
public class SensorDataServiceImpl implements SensorDataService {@Value("${export.path}")private String exportPath;@Value("${export.page-size:10000}")private Integer exportPageSize;//每頁多少條記錄@Override@Async("executor") // 指定使用定義的線程池public void asyncExportData(String taskId, ExportParam param) {System.out.println("當前線程: " + Thread.currentThread().getName());try {// 執行導出邏輯exportDataToFile(taskId, param);} catch (Exception e) {System.err.println("導出數據時發生異常:");e.printStackTrace();}}// 數據導出主方法private void exportDataToFile(String taskId, ExportParam param) throws Exception {// 1. 定義文件路徑(請確保該目錄存在且有寫權限)String exportDir = exportPath;String fileName = getDownloadDataFileName(param);String filePath = exportDir + fileName;// 2. 創建 CSV 文件并寫入表頭try (CSVWriter writer = new CSVWriter(new FileWriter(filePath))) {// 獲取表頭(根據 param 可以動態生成)String[] headers = getHeaders(param);writer.writeNext(headers);// 3. 分頁查詢數據int pageNumber = 0;int pageSize = exportPageSize; // 每頁查詢 5000 條boolean hasMore = true;while (hasMore) {String sql = getSqlWithPagination(param, pageSize, pageNumber);List<Map<String, Object>> rows = jdbcTemplate.queryForList(sql);if (rows.isEmpty()) {hasMore = false;} else {for (Map<String, Object> row : rows) {String[] rowData = formatRow(row, headers);writer.writeNext(rowData);}writer.flush(); // 及時刷新,避免內存積壓pageNumber++;}}// 4. 導出完成后記錄任務狀態和文件路徑taskManager.markTaskDone(taskId, fileName);} catch (Exception e) {// 記錄錯誤信息taskManager.markTaskFailed(taskId, e.getMessage());throw e;}}// 構建帶分頁的 SQLprivate String getSqlWithPagination(ExportParam paramObj, int pageSize, int pageNumber) {String baseSql = getSql(paramObj);return (baseSql.length() > 0) ? baseSql + " LIMIT " + pageSize + " OFFSET " + (pageNumber * pageSize) : "";}
}
三、效果
1、組件全貌

2、點擊開始導出
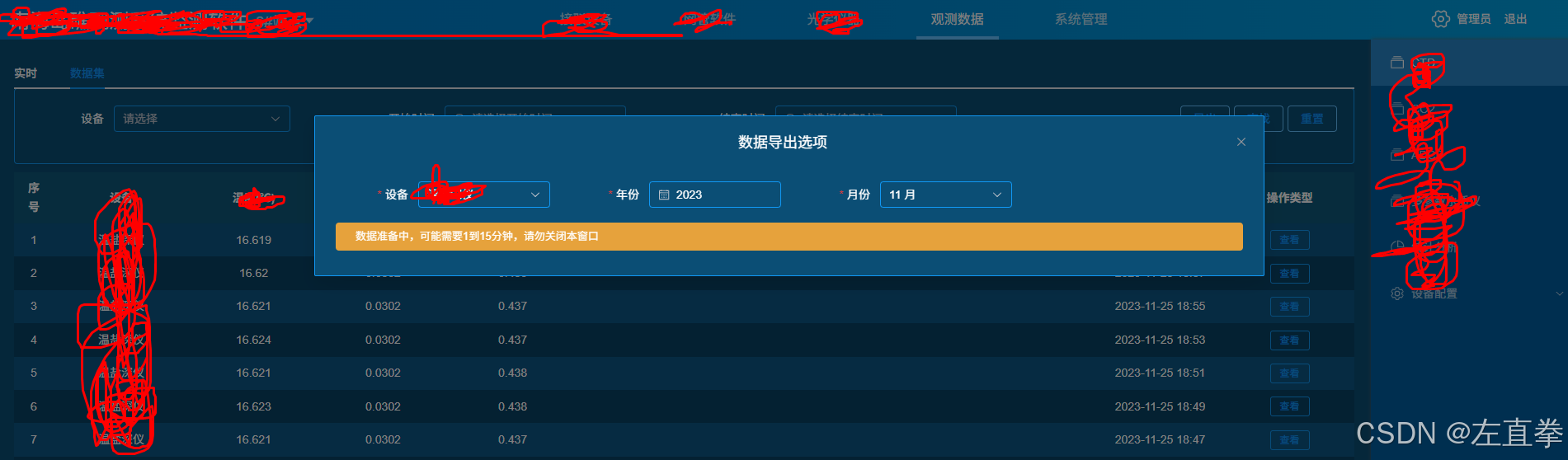
3、導出成功
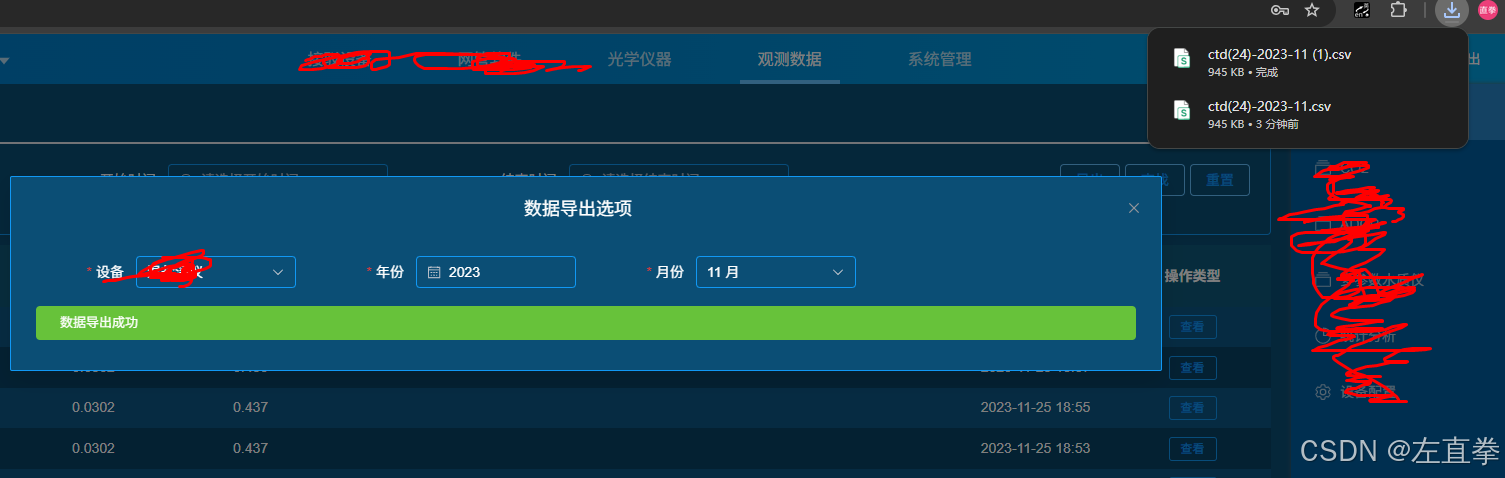
四、小結
有的表數據量特別巨大,一個月有記錄幾百萬條。按分頁查找,每頁5萬條記錄處理,下載一個月數據需要2、3分鐘。

)








)



——枚舉類)




)