Prometheus:云原生時代的監控利器
在當今快速發展的云原生和微服務架構時代,傳統的監控系統面臨著巨大的挑戰:如何高效地收集海量、動態變化的指標?如何實時告警并快速定位問題?如何實現靈活的可視化和強大的數據查詢能力?Prometheus,作為 CNCF(云原生計算基金會)的畢業項目,憑借其強大的功能和云原生友好的設計,已成為監控領域的事實標準。
本文將帶你深入了解 Prometheus 的核心概念、架構、優勢以及如何快速上手。
一、什么是 Prometheus?
Prometheus 是一個開源的系統監控和告警工具包,最初由 SoundCloud 開發,并于 2016 年加入 CNCF。它特別適用于記錄任意純數字時間序列數據,即按時間順序記錄的數值。
核心特點:
- 多維數據模型: 數據由指標名稱(metric name)和鍵值對(標簽/labels)唯一標識。例如:
http_requests_total{method="POST", endpoint="/api/users", status="200"}。這種模型使得查詢和聚合極其靈活。 - 靈活的查詢語言(PromQL): Prometheus Query Language (PromQL) 允許用戶以強大的方式選擇和聚合時間序列數據。
- 不依賴分布式存儲: 單個 Prometheus 服務器是自治的,本地存儲其抓取的所有數據,無需依賴外部存儲(如 HDFS)。
- 通過 HTTP 拉取(Pull)模式收集數據: Prometheus 周期性地從配置的目標(targets)的 HTTP 接口拉取(scrape)指標數據。這與傳統的推送(Push)模式(如 StatsD)不同。
- 服務發現: 支持動態發現監控目標,與 Kubernetes、Consul、etcd 等集成,自動管理目標列表。
- 強大的告警功能: 通過
Alertmanager組件,支持基于 PromQL 的復雜告警規則,并能對告警進行分組、抑制、靜默和路由到多種通知渠道(郵件、Slack、PagerDuty 等)。 - 圖形化和儀表板: 雖然自帶簡單的圖形界面,但通常與 Grafana 等專業可視化工具集成,創建豐富的儀表板。
二、Prometheus 核心組件與架構
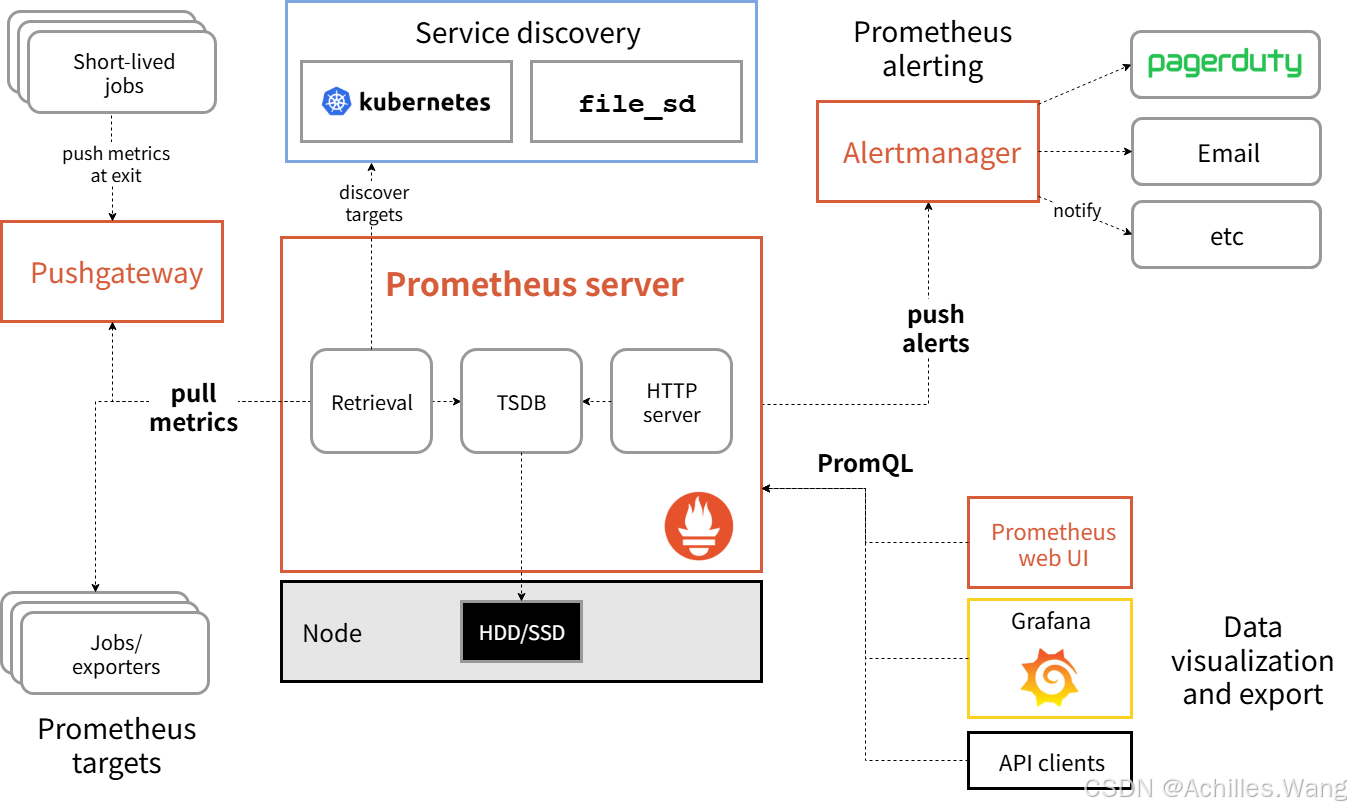
一個典型的 Prometheus 監控系統包含以下核心組件:
-
Prometheus Server: 核心組件,負責:
- 抓取(Scraping): 從配置的 HTTP endpoints 拉取指標數據。
- 存儲(Storage): 將收集到的時間序列數據存儲在本地磁盤。
- 查詢(Querying): 通過 PromQL 提供數據查詢接口。
- 規則處理(Rule Processing): 計算預定義的記錄規則(Recording Rules)和告警規則(Alerting Rules)。
-
Exporters: 這是 Prometheus 生態的關鍵。由于 Prometheus 本身不直接監控應用程序,需要由 Exporter 將第三方系統的指標暴露為 Prometheus 可讀的格式(通常是
/metrics的 HTTP 端點)。- 官方/社區 Exporter: 如
node_exporter(監控主機)、mysqld_exporter(MySQL)、redis_exporter(Redis)、blackbox_exporter(黑盒探測) 等。 - 應用內嵌 Exporter: 許多現代應用(如 Kubernetes 組件、etcd)直接內置了 Prometheus metrics 端點。
- 官方/社區 Exporter: 如
-
Pushgateway: 用于處理來自短生命周期作業(如批處理任務、Cron Jobs)的指標。這些作業在 Prometheus 完成抓取前可能已經結束,因此需要先將指標推送到 Pushgateway,再由 Prometheus 從 Pushgateway 拉取。
-
Alertmanager: 專門處理由 Prometheus Server 發送的告警。它負責:
- 去重(Deduplication)
- 分組(Grouping)
- 路由(Routing)到正確的接收者
- 抑制(Inhibition)
- 靜默(Silences)
- 發送通知(通過郵件、Webhook、Slack 等)
-
客戶端庫(Client Libraries): 用于在應用程序代碼中直接暴露自定義指標(如計數器 Counter、儀表 Gauge、直方圖 Histogram、摘要 Summary)。支持多種語言(Go, Java, Python, Ruby, .NET 等)。
-
可視化工具(如 Grafana): 雖然不是 Prometheus 的一部分,但 Grafana 是最流行的與 Prometheus 集成的可視化平臺,用于創建交互式儀表板。
[應用程序/服務] --> (通過客戶端庫暴露指標 或 Exporter)|v[Prometheus Server]/ \/ \(抓取數據) / \ (發送告警)/ \v v[本地時間序列數據庫] [Alertmanager]| || v| [通知渠道 (郵件, Slack...)]|v[Grafana (可視化)]
三、快速上手:部署一個簡單的 Prometheus
1. 下載并運行 Prometheus
# 下載 Prometheus (以 Linux 為例)
wget https://github.com/prometheus/prometheus/releases/download/v2.50.0/prometheus-2.50.0.linux-amd64.tar.gz
tar xvfz prometheus-2.50.0.linux-amd64.tar.gz
cd prometheus-2.50.0.linux-amd64/# 查看配置文件 (prometheus.yml)
# 默認配置會監控自己
cat prometheus.yml# 啟動 Prometheus
./prometheus --config.file=prometheus.yml
Prometheus 默認在 http://localhost:9090 提供 Web UI。
2. 配置監控目標
編輯 prometheus.yml,添加一個 node_exporter 目標:
global:scrape_interval: 15s # 默認抓取間隔scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090'] # 監控 Prometheus 自身- job_name: 'node' # 監控主機static_configs:- targets: ['your-server-ip:9100'] # 假設 node_exporter 運行在 9100 端口
重啟 Prometheus 服務,訪問 Web UI 的 Status -> Targets 頁面,應該能看到新的目標處于 UP 狀態。
3. 使用 PromQL 查詢
在 Prometheus Web UI 的 Graph 標簽頁,嘗試一些簡單的 PromQL 查詢:
up{job="node"}:查看node任務的監控目標是否在線(1=在線,0=離線)。node_memory_MemAvailable_bytes{job="node"}:查看主機可用內存。rate(node_cpu_seconds_total{job="node",mode="idle"}[5m]):計算過去 5 分鐘 CPU 空閑時間的平均使用率(注意:idle 時間減少代表 CPU 使用增加)。node_filesystem_avail_bytes{job="node",mountpoint="/"} / node_filesystem_size_bytes{job="node",mountpoint="/"}:計算根分區的可用空間百分比。
4. 集成 Grafana
- 安裝并啟動 Grafana。
- 在 Grafana 中添加 Prometheus 作為數據源(URL:
http://<your-prometheus-host>:9090)。 - 導入或創建儀表板。例如,導入
Node Exporter Full儀表板 (ID: 1860) 可以全面監控主機狀態。
prometheus doc
prometheus與k8s的結合
真實的生產環境往往很復雜,并不能通過單一的prometheus解決整個系統的監控,因此這里推薦一個工業級別的項目
kube-prometheus
接下來對于prometheus的學習也是基于kube-prometheus開源庫進行的,可以這樣說,只要你把這個庫掌握了你就可以直接去找與prometheus相關的工作了





)




![[硬件電路-148]:數字電路 - 什么是CMOS電平、TTL電平?還有哪些其他電平標準?發展歷史?](http://pic.xiahunao.cn/[硬件電路-148]:數字電路 - 什么是CMOS電平、TTL電平?還有哪些其他電平標準?發展歷史?)
 --(前端篇 2)--)



)



