引言:批處理的現代價值
在大數據時代,批處理(Batch Processing)?作為數據處理的核心范式,正經歷著復興。盡管實時流處理備受關注,但批處理在數據倉庫構建、歷史數據分析、報表生成等場景中仍不可替代。Python憑借其豐富的數據處理庫和簡潔的語法,已成為批處理任務的首選工具之一。
本文將深入探討Python批處理的核心技術、架構設計、性能優化和實戰應用,通過6000+字的系統解析和原創代碼示例,幫助您構建高效可靠的大規模數據處理系統。
第一部分:批處理基礎與架構
1.1 批處理的核心特征
批處理區別于流處理的三大特性:
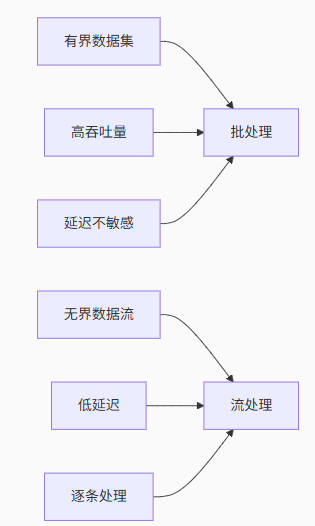
典型應用場景:
夜間ETL作業
月度財務報表生成
用戶行為歷史分析
機器學習模型訓練
1.2 批處理系統架構
現代Python批處理系統的典型架構:
數據源 --> 提取 --> 處理引擎 --> 存儲↑ ↓調度器 <-- 監控系統1.2.1 分層架構實現
class BatchProcessingSystem:"""Python批處理系統基礎架構"""def __init__(self):self.extractors = []self.transformers = []self.loaders = []self.scheduler = Noneself.monitor = BatchMonitor()def add_extractor(self, extractor):"""添加數據提取器"""self.extractors.append(extractor)def add_transformer(self, transformer):"""添加數據轉換器"""self.transformers.append(transformer)def add_loader(self, loader):"""添加數據加載器"""self.loaders.append(loader)def run_pipeline(self):"""執行批處理管道"""try:# 階段1: 數據提取raw_data = []for extractor in self.extractors:self.monitor.log(f"開始提取: {extractor.name}")data = extractor.extract()raw_data.append(data)self.monitor.log(f"提取完成: {len(data)} 條記錄")# 階段2: 數據處理processed_data = raw_datafor transformer in self.transformers:self.monitor.log(f"開始轉換: {transformer.name}")processed_data = transformer.transform(processed_data)self.monitor.log(f"轉換完成")# 階段3: 數據加載for loader, data in zip(self.loaders, processed_data):self.monitor.log(f"開始加載: {loader.name}")loader.load(data)self.monitor.log(f"加載完成: {len(data)} 條記錄")self.monitor.report_success()except Exception as e:self.monitor.report_failure(str(e))raise第二部分:核心處理技術
2.1 內存批處理:Pandas
Pandas是中小規模數據批處理的首選工具:
import pandas as pd
import numpy as npclass PandasBatchProcessor:"""基于Pandas的批處理器"""def __init__(self, chunk_size=10000):self.chunk_size = chunk_sizedef process_large_csv(self, input_path, output_path):"""處理大型CSV文件"""# 分塊讀取chunks = pd.read_csv(input_path, chunksize=self.chunk_size)processed_chunks = []for i, chunk in enumerate(chunks):print(f"處理分塊 #{i+1}")# 執行轉換操作chunk = self._clean_data(chunk)chunk = self._transform_data(chunk)chunk = self._calculate_metrics(chunk)processed_chunks.append(chunk)# 合并結果result = pd.concat(processed_chunks)# 保存結果result.to_parquet(output_path, index=False)print(f"處理完成,總記錄數: {len(result)}")def _clean_data(self, df):"""數據清洗"""# 刪除空值df = df.dropna(subset=['important_column'])# 處理異常值df = df[(df['value'] >= 0) & (df['value'] <= 1000)]return dfdef _transform_data(self, df):"""數據轉換"""# 類型轉換df['date'] = pd.to_datetime(df['timestamp'], unit='s')# 特征工程df['value_category'] = pd.cut(df['value'], bins=[0, 50, 100, 200, np.inf])return dfdef _calculate_metrics(self, df):"""指標計算"""# 分組聚合agg_df = df.groupby('category').agg({'value': ['sum', 'mean', 'count']})agg_df.columns = ['total', 'average', 'count']return agg_df.reset_index()2.2 分布式批處理:Dask
Dask用于處理超出內存限制的大型數據集:
import dask.dataframe as dd
from dask.distributed import Clientclass DaskBatchProcessor:"""基于Dask的分布式批處理器"""def __init__(self, cluster_address=None):# 連接Dask集群self.client = Client(cluster_address) if cluster_address else Client()print(f"連接到Dask集群: {self.client.dashboard_link}")def process_distributed_data(self, input_paths, output_path):"""處理分布式數據"""# 創建Dask DataFrameddf = dd.read_parquet(input_paths)# 數據轉換ddf = ddf[ddf['value'] > 0] # 過濾ddf['value_normalized'] = ddf['value'] / ddf.groupby('group')['value'].transform('max')# 復雜計算ddf['category'] = dd.map_partitions(self._categorize, ddf, meta=('category', 'str'))# 聚合操作result = ddf.groupby('category').agg({'value': ['sum', 'mean', 'count'],'value_normalized': 'mean'}).compute()# 保存結果result.to_parquet(output_path)# 關閉客戶端self.client.close()def _categorize(self, partition):"""自定義分類函數(在每個分區執行)"""# 復雜分類邏輯conditions = [(partition['value'] < 10),(partition['value'] < 50) & (partition['value'] >= 10),(partition['value'] >= 50)]choices = ['low', 'medium', 'high']partition['category'] = np.select(conditions, choices, default='unknown')return partition2.3 云原生批處理:PySpark
PySpark適合在Hadoop集群或云平臺上處理超大規模數據:
from pyspark.sql import SparkSession
from pyspark.sql import functions as Fclass SparkBatchProcessor:"""基于PySpark的批處理器"""def __init__(self):self.spark = SparkSession.builder \.appName("LargeScaleBatchProcessing") \.config("spark.sql.shuffle.partitions", "200") \.getOrCreate()def process_huge_dataset(self, input_path, output_path):"""處理超大規模數據集"""# 讀取數據df = self.spark.read.parquet(input_path)print(f"初始記錄數: {df.count()}")# 數據清洗df = df.filter(F.col("value").isNotNull()) \.filter(F.col("value") > 0)# 數據轉換df = df.withColumn("date", F.to_date(F.from_unixtime("timestamp"))) \.withColumn("value_category", self._categorize_udf(F.col("value")))# 聚合操作result = df.groupBy("date", "value_category") \.agg(F.sum("value").alias("total_value"),F.avg("value").alias("avg_value"),F.count("*").alias("record_count"))# 保存結果result.write.parquet(output_path, mode="overwrite")print(f"處理完成,結果保存至: {output_path}")# 停止Spark會話self.spark.stop()@staticmethoddef _categorize_udf():"""定義分類UDF"""def categorize(value):if value < 10: return "low"elif value < 50: return "medium"else: return "high"return F.udf(categorize, StringType())第三部分:性能優化策略
3.1 并行處理技術
from concurrent.futures import ThreadPoolExecutor, as_completed
import multiprocessingclass ParallelProcessor:"""并行批處理執行器"""def __init__(self, max_workers=None):self.max_workers = max_workers or multiprocessing.cpu_count() * 2def process_in_parallel(self, task_list, task_function):"""并行處理任務列表"""results = []with ThreadPoolExecutor(max_workers=self.max_workers) as executor:# 提交所有任務future_to_task = {executor.submit(task_function, task): task for task in task_list}# 收集結果for future in as_completed(future_to_task):task = future_to_task[future]try:result = future.result()results.append(result)except Exception as e:print(f"任務 {task} 失敗: {str(e)}")return results# 使用示例
def process_file(file_path):"""單個文件處理函數"""print(f"處理文件: {file_path}")# 實際處理邏輯return f"{file_path}_processed"if __name__ == "__main__":files = [f"data/file_{i}.csv" for i in range(100)]processor = ParallelProcessor(max_workers=8)results = processor.process_in_parallel(files, process_file)print(f"處理完成 {len(results)} 個文件")3.2 內存優化技巧
class MemoryOptimizedProcessor:"""內存優化的批處理器"""def __init__(self, max_memory_mb=1024):self.max_memory = max_memory_mb * 1024 * 1024 # 轉換為字節def process_large_data(self, data_generator):"""處理大型數據集(使用生成器)"""batch = []current_size = 0for item in data_generator:item_size = self._estimate_size(item)# 檢查批次內存if current_size + item_size > self.max_memory:# 處理當前批次self._process_batch(batch)# 重置批次batch = []current_size = 0batch.append(item)current_size += item_size# 處理剩余批次if batch:self._process_batch(batch)def _process_batch(self, batch):"""處理單個批次"""print(f"處理批次: {len(batch)} 條記錄")# 實際處理邏輯# ...def _estimate_size(self, item):"""估算對象內存占用(簡化版)"""return len(str(item)) * 8 # 近似估算3.3 磁盤輔助處理
import sqlite3
import os
import pickleclass DiskBackedProcessor:"""磁盤輔助的批處理器"""def __init__(self, temp_dir="temp"):self.temp_dir = temp_diros.makedirs(temp_dir, exist_ok=True)def process_very_large_data(self, data_generator):"""處理超大數據集(使用磁盤輔助)"""# 步驟1: 分塊寫入磁盤chunk_files = []chunk_size = 100000 # 每塊記錄數current_chunk = []for i, item in enumerate(data_generator):current_chunk.append(item)if len(current_chunk) >= chunk_size:chunk_file = self._save_chunk(current_chunk, i // chunk_size)chunk_files.append(chunk_file)current_chunk = []if current_chunk:chunk_file = self._save_chunk(current_chunk, len(chunk_files))chunk_files.append(chunk_file)# 步驟2: 并行處理分塊results = []with multiprocessing.Pool() as pool:results = pool.map(self._process_chunk_file, chunk_files)# 步驟3: 合并結果final_result = self._combine_results(results)# 步驟4: 清理臨時文件for file in chunk_files:os.remove(file)return final_resultdef _save_chunk(self, chunk, index):"""保存分塊到磁盤"""file_path = os.path.join(self.temp_dir, f"chunk_{index}.pkl")with open(file_path, 'wb') as f:pickle.dump(chunk, f)return file_pathdef _process_chunk_file(self, file_path):"""處理單個分塊文件"""with open(file_path, 'rb') as f:chunk = pickle.load(f)# 實際處理邏輯return len(chunk) # 示例返回結果def _combine_results(self, results):"""合并處理結果"""return sum(results)第四部分:錯誤處理與容錯機制
4.1 健壯的批處理框架
class RobustBatchProcessor:"""帶錯誤處理和重試的批處理器"""def __init__(self, max_retries=3, retry_delay=10):self.max_retries = max_retriesself.retry_delay = retry_delaydef safe_process(self, processing_func, data):"""安全執行處理函數"""retries = 0while retries <= self.max_retries:try:result = processing_func(data)return resultexcept TransientError as e: # 可重試錯誤print(f"可重試錯誤: {str(e)}. 重試 {retries}/{self.max_retries}")retries += 1time.sleep(self.retry_delay * retries)except CriticalError as e: # 不可恢復錯誤print(f"不可恢復錯誤: {str(e)}")raiseexcept Exception as e: # 其他未知錯誤print(f"未知錯誤: {str(e)}")raiseraise MaxRetriesExceeded(f"超過最大重試次數 {self.max_retries}")# 自定義異常
class TransientError(Exception):"""臨時性錯誤(可重試)"""passclass CriticalError(Exception):"""關鍵性錯誤(不可恢復)"""passclass MaxRetriesExceeded(Exception):"""超過最大重試次數"""pass4.2 狀態檢查點機制
import json
from abc import ABC, abstractmethodclass StatefulBatchProcessor(ABC):"""支持檢查點的狀態化批處理器"""def __init__(self, state_file="batch_state.json"):self.state_file = state_fileself.state = self._load_state()def process(self, data_source):"""執行帶狀態檢查點的處理"""# 恢復上次狀態current_position = self.state.get("last_position", 0)try:for i, item in enumerate(data_source):if i < current_position:continue # 跳過已處理項# 處理當前項self.process_item(item)# 更新狀態self.state["last_position"] = i + 1# 定期保存狀態if (i + 1) % 1000 == 0:self._save_state()# 處理完成self.state["completed"] = Trueself._save_state()except Exception as e:print(f"處理在位置 {self.state['last_position']} 失敗: {str(e)}")self._save_state()raise@abstractmethoddef process_item(self, item):"""處理單個數據項(由子類實現)"""passdef _load_state(self):"""加載處理狀態"""try:if os.path.exists(self.state_file):with open(self.state_file, 'r') as f:return json.load(f)except:passreturn {"last_position": 0, "completed": False}def _save_state(self):"""保存處理狀態"""with open(self.state_file, 'w') as f:json.dump(self.state, f)第五部分:批處理系統實戰案例
5.1 電商數據分析系統
class EcommerceAnalyzer:"""電商批處理分析系統"""def __init__(self, data_path, output_path):self.data_path = data_pathself.output_path = output_pathself.report_date = datetime.now().strftime("%Y-%m-%d")def generate_daily_report(self):"""生成每日分析報告"""# 1. 加載數據orders = self._load_orders()users = self._load_users()products = self._load_products()# 2. 數據清洗orders = self._clean_orders(orders)# 3. 數據合并merged = orders.merge(users, on='user_id', how='left') \.merge(products, on='product_id', how='left')# 4. 關鍵指標計算report = {"report_date": self.report_date,"total_orders": len(orders),"total_revenue": orders['amount'].sum(),"top_products": self._top_products(merged),"user_metrics": self._user_metrics(merged),"category_analysis": self._category_analysis(merged)}# 5. 保存報告self._save_report(report)def _load_orders(self):"""加載訂單數據"""return pd.read_parquet(f"{self.data_path}/orders")def _load_users(self):"""加載用戶數據"""return pd.read_parquet(f"{self.data_path}/users")def _load_products(self):"""加載產品數據"""return pd.read_parquet(f"{self.data_path}/products")def _clean_orders(self, orders):"""清洗訂單數據"""# 過濾無效訂單orders = orders[orders['status'] == 'completed']# 轉換日期orders['order_date'] = pd.to_datetime(orders['order_timestamp'], unit='s')return ordersdef _top_products(self, data):"""計算熱銷商品"""top = data.groupby('product_name')['amount'] \.sum() \.sort_values(ascending=False) \.head(10)return top.to_dict()def _user_metrics(self, data):"""用戶指標分析"""# 新用戶數new_users = data[data['user_type'] == 'new']['user_id'].nunique()# 平均訂單價值avg_order_value = data.groupby('order_id')['amount'].sum().mean()return {"new_users": new_users,"avg_order_value": round(avg_order_value, 2)}def _save_report(self, report):"""保存分析報告"""report_path = f"{self.output_path}/daily_report_{self.report_date}.json"with open(report_path, 'w') as f:json.dump(report, f, indent=2)print(f"報告已保存至: {report_path}")5.2 機器學習特征工程流水線
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputerclass FeatureEngineeringPipeline:"""批處理特征工程流水線"""def __init__(self, config):self.config = configself.pipeline = self._build_pipeline()def _build_pipeline(self):"""構建特征工程流水線"""# 數值特征處理numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())])# 分類特征處理categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='constant', fill_value='missing')),('onehot', OneHotEncoder(handle_unknown='ignore'))])# 組合處理preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, self.config['numeric_features']),('cat', categorical_transformer, self.config['categorical_features'])])return preprocessordef process_batch(self, data):"""處理數據批次"""return self.pipeline.fit_transform(data)def save_pipeline(self, file_path):"""保存訓練好的流水線"""joblib.dump(self.pipeline, file_path)print(f"流水線已保存至: {file_path}")def load_pipeline(self, file_path):"""加載預訓練的流水線"""self.pipeline = joblib.load(file_path)return selfdef transform_batch(self, data):"""使用預訓練流水線轉換數據"""return self.pipeline.transform(data)# 使用示例
if __name__ == "__main__":config = {'numeric_features': ['age', 'income', 'credit_score'],'categorical_features': ['gender', 'education', 'occupation']}# 加載數據data = pd.read_csv("user_data.csv")# 創建并運行特征工程fe_pipeline = FeatureEngineeringPipeline(config)processed_data = fe_pipeline.process_batch(data)# 保存處理后的數據和流水線pd.DataFrame(processed_data).to_parquet("processed_data.parquet")fe_pipeline.save_pipeline("feature_pipeline.joblib")第六部分:調度與監控系統
6.1 基于APScheduler的調度系統
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTriggerclass BatchScheduler:"""批處理作業調度器"""def __init__(self):self.scheduler = BackgroundScheduler()self.jobs = {}def add_daily_job(self, job_id, func, hour=3, minute=0):"""添加每日任務"""trigger = CronTrigger(hour=hour, minute=minute)job = self.scheduler.add_job(func, trigger, id=job_id)self.jobs[job_id] = jobprint(f"已安排每日任務 {job_id} 在 {hour}:{minute} 執行")def add_interval_job(self, job_id, func, hours=12):"""添加間隔任務"""job = self.scheduler.add_job(func, 'interval', hours=hours, id=job_id)self.jobs[job_id] = jobprint(f"已安排間隔任務 {job_id} 每 {hours} 小時執行")def start(self):"""啟動調度器"""self.scheduler.start()print("調度器已啟動")def shutdown(self):"""關閉調度器"""self.scheduler.shutdown()print("調度器已關閉")# 使用示例
if __name__ == "__main__":def generate_reports():print("開始生成報告...")# 實際報告生成邏輯print("報告生成完成")scheduler = BatchScheduler()scheduler.add_daily_job("daily_report", generate_reports, hour=2, minute=30)scheduler.start()try:# 保持主線程運行while True:time.sleep(1)except KeyboardInterrupt:scheduler.shutdown()6.2 批處理監控系統
import logging
from logging.handlers import RotatingFileHandler
import socketclass BatchMonitor:"""批處理作業監控系統"""def __init__(self, log_file="batch_monitor.log"):self.logger = self._setup_logger(log_file)self.hostname = socket.gethostname()self.start_time = datetime.now()self.metrics = {"processed_items": 0,"errors": 0,"last_error": None}def _setup_logger(self, log_file):"""配置日志記錄器"""logger = logging.getLogger("BatchMonitor")logger.setLevel(logging.INFO)# 文件處理器file_handler = RotatingFileHandler(log_file, maxBytes=10*1024*1024, backupCount=5)file_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')file_handler.setFormatter(file_formatter)# 控制臺處理器console_handler = logging.StreamHandler()console_handler.setFormatter(file_formatter)logger.addHandler(file_handler)logger.addHandler(console_handler)return loggerdef log(self, message, level="info"):"""記錄消息"""log_method = getattr(self.logger, level.lower(), self.logger.info)log_method(message)def increment_counter(self, counter_name, amount=1):"""增加計數器"""if counter_name in self.metrics:self.metrics[counter_name] += amountdef record_error(self, error_message):"""記錄錯誤"""self.metrics["errors"] += 1self.metrics["last_error"] = error_messageself.log(f"錯誤: {error_message}", "error")def report_start(self, job_name):"""報告作業開始"""self.start_time = datetime.now()self.log(f"作業 {job_name} 在 {self.hostname} 開始執行")def report_success(self, job_name):"""報告作業成功"""duration = datetime.now() - self.start_timeself.log(f"作業 {job_name} 成功完成! "f"處理時長: {duration.total_seconds():.2f}秒, "f"處理項: {self.metrics['processed_items']}")self._reset_counters()def report_failure(self, job_name, error_message):"""報告作業失敗"""duration = datetime.now() - self.start_timeself.record_error(error_message)self.log(f"作業 {job_name} 失敗! "f"運行時長: {duration.total_seconds():.2f}秒, "f"錯誤: {error_message}", "error")def _reset_counters(self):"""重置計數器"""self.metrics = {k: 0 for k in self.metrics}self.metrics["last_error"] = None第七部分:最佳實踐與未來趨勢
7.1 Python批處理最佳實踐
數據分塊處理:始終將大數據集分解為可管理的塊
資源監控:實時跟蹤內存、CPU和I/O使用情況
冪等設計:確保作業可安全重試而不會產生副作用
增量處理:使用狀態檢查點處理新增數據
測試策略:
單元測試:針對每個處理函數
集成測試:完整管道測試
負載測試:模擬生產數據量
7.2 批處理架構演進

7.3 云原生批處理技術棧
| 組件類型 | AWS生態系統 | Azure生態系統 | GCP生態系統 |
|---|---|---|---|
| 存儲 | S3, EFS | Blob Storage, ADLS | Cloud Storage |
| 計算引擎 | AWS Batch, EMR | Azure Batch, HDInsight | Dataproc, Dataflow |
| 編排調度 | Step Functions, MWAA | Data Factory | Cloud Composer |
| 監控 | CloudWatch | Monitor | Cloud Monitoring |
結語:批處理的未來之路
Python批處理技術正朝著更智能、更高效的方向發展:
AI增強處理:集成機器學習優化處理邏輯
自動優化:基于數據特征的運行時優化
無服務器批處理:按需使用的云原生架構
批流融合:統一批處理和流處理的編程模型
"批處理不是過時的技術,而是數據生態的基石。掌握批處理的藝術,就是掌握數據的過去、現在和未來。" —— 數據工程箴言
通過本文的系統探索,您已掌握Python批處理的核心技術和實踐方法。無論您處理的是GB級還是PB級數據,這些知識和工具都能幫助您構建健壯、高效的批處理系統。在實際應用中,建議根據數據規模和處理需求靈活選擇技術方案,并持續優化您的處理流水線。





常用管理SQL命令(3))




的詳解、常見場景、常見問題及最佳解決方案的綜合指南)

![[leetcode] 位運算](http://pic.xiahunao.cn/[leetcode] 位運算)
函數,eval()函數,include)





)