Q1: Redis為什么這么快?
Redis速度快主要有四個核心原因。首先是基于內存操作,所有數據都存儲在內存中,避免了磁盤I/O的開銷,內存讀寫速度比磁盤快幾萬倍。其次采用單線程模型,避免了多線程環境下的線程切換和鎖競爭帶來的性能損耗。再者是優秀的底層數據結構設計,比如哈希表、跳躍表等高效數據結構,保證了各種操作的時間復雜度。最后是采用多路復用I/O模型,通過epoll等機制同時處理多個客戶端連接,在等待某個連接的同時可以處理其他連接的請求,大大提升了整體吞吐量。
Q2: Redis都有哪些數據類型,分別適用什么場景?
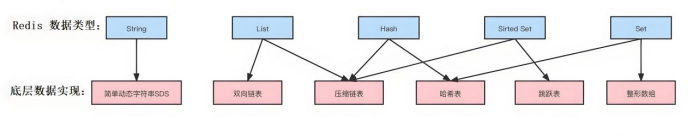
Redis有五種基本數據類型。String字符串是最基礎的類型,適用于緩存用戶信息、session存儲,還可以存儲數字進行計數器操作。List列表是有序可重復的,常用來實現消息隊列和存儲時間線數據。Hash哈希結構特別適合存儲對象信息,比如用戶詳情、商品信息,還有購物車場景,可以用用戶ID作為key,商品ID和數量作為field-value。Set集合保證元素唯一性和無序性,適合去重和實現點贊、關注等功能。Sorted Set有序集合在Set基礎上增加了score排序功能,是實現排行榜、熱門推薦的最佳選擇。
Q3: Sorted Set的底層是怎么實現的?
Sorted Set的底層實現會根據數據量動態選擇不同的數據結構。

當數據量較小時,具體是元素個數小于128個且所有元素長度都小于64字節時,會使用壓縮列表ziplist存儲,這種方式內存占用小,遍歷效率高。
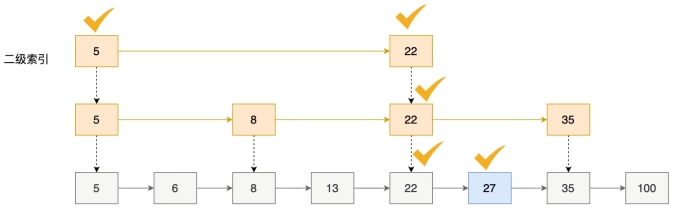
當超過這個閾值時,就會轉換為跳躍表skiplist實現。跳躍表是一種概率型數據結構,通過多層索引實現快速查找,平均時間復雜度是O(log n),最壞情況是O(n)。每個節點維護指向不同層級的指針,查找時從最高層開始,逐層下降,這樣既保證了查找效率,又支持范圍查詢操作。
Q4: 為什么Redis不用B+樹而用跳表?
這個問題其實是Redis和MySQL設計理念的差異體現。MySQL使用B+樹是因為數據存儲在磁盤上,需要考慮磁盤I/O的成本,B+樹的設計讓葉子節點存儲數據,非葉子節點存儲索引,每次讀取一個磁盤頁就能獲取一個節點的所有數據,并且葉子節點之間有指針連接,這樣能最大限度減少磁盤I/O次數。而Redis的數據完全在內存中,不涉及磁盤I/O,內存訪問速度是磁盤的百萬倍,這種情況下跳表就更有優勢了。跳表的實現比B+樹簡單很多,而且在內存環境下性能更好,維護成本也更低,所以Redis選擇了跳表。
Q5: Redis可以用來做什么?
Redis的應用場景非常廣泛。最常見的是作為緩存,將熱點數據存儲在內存中,減少對后端數據庫的訪問壓力,大幅提升系統性能。還可以作為消息隊列使用,利用List的push和pop操作實現簡單隊列,或者使用發布訂閱功能實現更復雜的消息傳遞,實現系統解耦和異步處理。在分布式系統中,Redis還能實現分布式鎖,使用SETNX命令可以保證同一時間只有一個進程獲取鎖,避免并發修改導致的數據不一致,不過生產環境建議使用Redisson等成熟框架實現可重入鎖。另外Redis在計數器、排行榜、分布式會話管理等場景都有很好的應用,比如我之前項目中就用Redis存儲AI對話的會話信息,用會話ID作為key,對話內容以JSON格式存儲。
Q6: Redis的持久化機制有哪些?
Redis提供了三種持久化方案。RDB快照是將某個時間點的內存數據完整保存到磁盤,文件緊湊,恢復速度快,但可能會丟失最后一次快照后的數據。AOF日志是記錄每個寫操作命令,數據丟失風險小,文件可讀性好,但文件相對較大,恢復速度較慢。Redis 4.0后推出了混合持久化方案,這是目前推薦的方式,它結合了RDB和AOF的優點,在AOF重寫時,會把重寫那一刻之前的內存以RDB格式寫入AOF文件開頭,后續的增量數據以AOF格式追加,這樣既保證了快速啟動,又最大程度減少了數據丟失風險。不過這種方案也有缺點,就是實現復雜度高,需要維護兩種格式,AOF文件的可讀性也會下降。
Q7: Redis集群了解嗎?
Redis提供了三種集群方案。主從復制是最基礎的,一個主節點負責寫操作,多個從節點負責讀操作,通過數據同步保證一致性,主要解決讀壓力問題。哨兵模式在主從基礎上增加了高可用性,哨兵節點監控主從狀態,當主節點故障時自動進行故障轉移,選舉新的主節點。Redis Cluster是官方的分布式解決方案,支持數據自動分片,通過一致性哈希將數據分散到不同節點,每個節點既可以是主節點也可以是從節點,支持橫向擴展和故障自動轉移,是大規模分布式場景的首選方案。
Q8: 緩存常見問題怎么解決?
緩存使用中主要有三個經典問題。緩存穿透是指請求的數據既不在緩存也不在數據庫中,每次請求都會穿透到數據庫,解決方案是緩存空值或使用布隆過濾器。緩存擊穿是指熱點數據過期的瞬間大量請求直接打到數據庫,可以通過設置熱點數據永不過期或使用互斥鎖重建緩存來解決。緩存雪崩是指大量緩存同時過期,解決方案包括設置隨機過期時間、使用多級緩存、限流降級等。
另外還有緩存一致性問題,可以通過延時雙刪、消息隊列異步更新等方式來保證緩存和數據庫的數據一致性。
數據類型與運算符)

—Vue3 ref相關API》)



)
![[特殊字符] 深入解析String的不可變性:Java字符串設計的精妙之處](http://pic.xiahunao.cn/[特殊字符] 深入解析String的不可變性:Java字符串設計的精妙之處)


中模型參數選擇:MLM、GLM與FarmCPU的深度解析)





 求解二維 Rastrigin 函數最小值問題)
】深入理解 on、jobs、steps 的核心語法與執行邏輯)

什么是渲染管線)