近幾年做跨境電商或內容運營的同學,應該都能感受到視頻內容正逐漸從“錦上添花”變成了“必選項”。
尤其是 TikTok、Instagram Reels、Facebook 短視頻、甚至一些獨立站內嵌視頻講解頁,對帶講解、有人臉、自然語音的視頻內容都有顯著的轉化提升作用。
但實際做過的人都知道——內容制作往往是最難推進的一環:
視頻要講解,就要出鏡
出鏡就涉及拍攝、化妝、場地、設備
還需要錄音、剪輯、調色、字幕配合
如果要做多語言,還得翻譯+重新錄制
對于個體從業者、小團隊、或沒有視頻制作經驗的人來說,這是一道很難跨過去的門檻。
內容自動化的突破口:語音+口型生成技術
隨著文本轉語音(TTS)和視頻合成技術的發展,AI 在內容生產中的角色越來越明顯。
現在,借助一些輕量化工具,不錄音、不出鏡、不剪輯也能完成一條講解類視頻的核心內容。
例如我最近測試的一款工具:LipSync, 它的實現方式是:給定一段語音(或 TTS 合成語音),自動生成與之口型同步的人臉視頻。
實際效果比傳統的 Avatar 類工具更自然,尤其在口型、語速和語音同步方面準確率非常高,配合剪映等工具即可快速生成完整內容。
實踐場景舉例:AI 驅動的“講解視頻自動化”流程
這是我現在常用的一套工作流,適合用于 TikTok 產品講解、廣告片段、多語言教程等內容場景:
文案撰寫(中文或英文)
使用 AI 配音工具生成語音
將語音導入生成對口型講解視頻
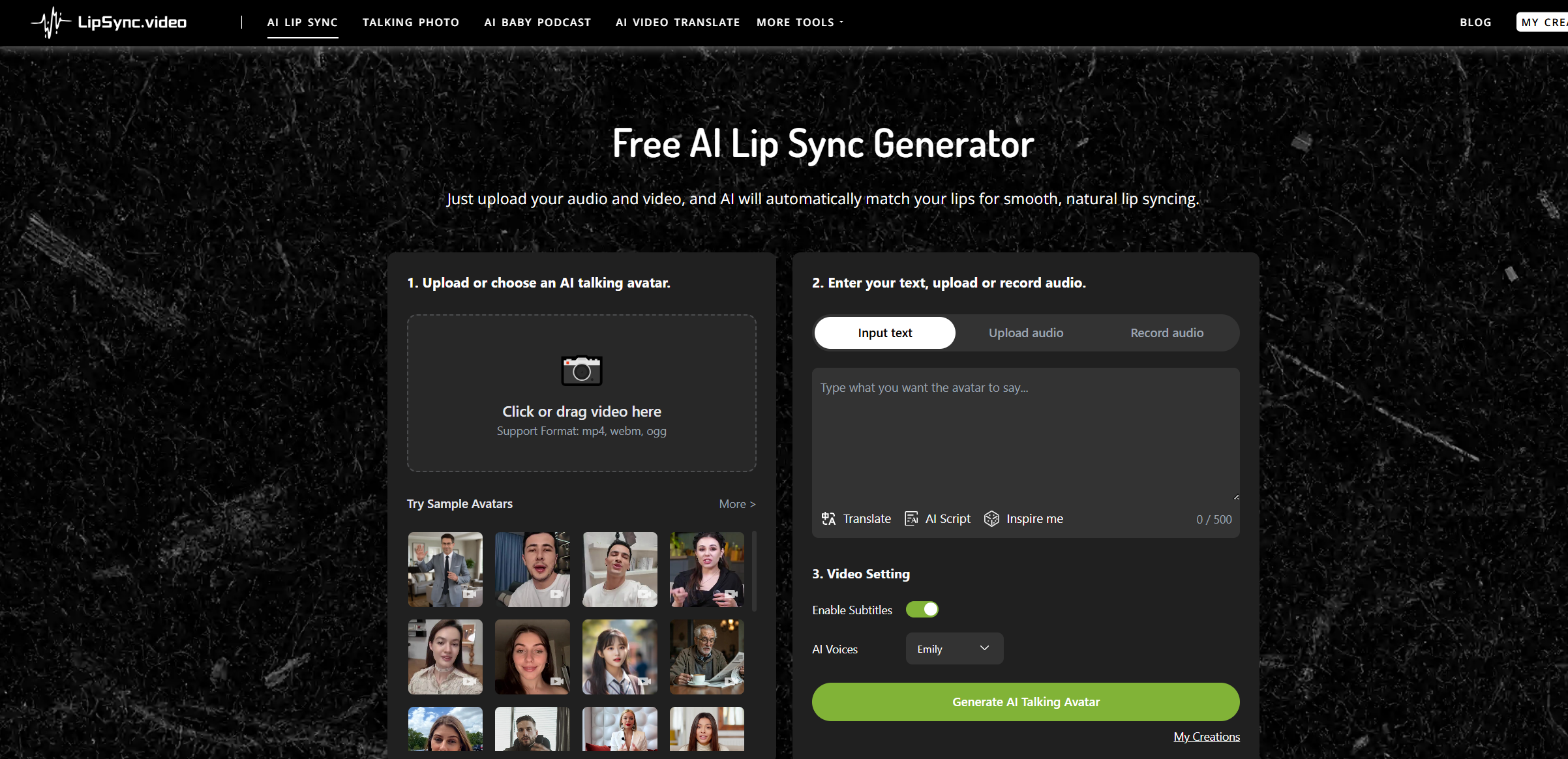
使用剪映 / capcut 添加產品畫面、字幕、BGM
輸出并發布
這種流程的優勢是:
成本極低:不需要請配音、不請模特、不用剪輯師
速度極快:平均一條視頻制作耗時可控制在 30 分鐘內
支持多語言版本:只需替換配音內容,其余流程保持一致
技術角度簡析核心原理
該工具背后的合成邏輯主要涉及三類關鍵技術:
語音驅動的人臉動作建模:通過聲音頻譜分析與機器學習模型,提取關鍵嘴型動作參數;
動態面部渲染:將靜態頭像素材進行動態映射(類似 Talking Head 技術);
音視頻對齊與合成引擎:保證輸出視頻與音頻節奏同步,自然過渡不跳幀。
這種方式較傳統的剪輯式口型合成,具備更強的時間一致性和面部動態還原能力。
哪些人適合這種內容制作方式?
跨境電商團隊:多語言視頻內容本地化需求大,傳統方式成本高;
一人公司 / 自由職業者:沒有拍攝條件但需要大量產出;
教育 / SaaS 產品運營:需要批量輸出講解內容,提高客戶留存;
AI 工具測評 / 視頻播客制作者:需要大量 AI 人像視頻素材支持。
小結:技術正在降低內容門檻
內容創作曾經是一個“門檻高、流程重”的領域,但 AI 正在逐漸解構這些壁壘。
從文字 → 語音 → 視頻,整條鏈路如今都可以借助 AI 自動完成。
像這樣的工具,提供了一個很實用的切入點,讓“不會出鏡”的創作者也有機會參與到視頻內容生態中。
如果你正面臨視頻內容制作上的難題,不妨嘗試這類工具輔助制作,可能會帶來意想不到的效率提升。
中模型參數選擇:MLM、GLM與FarmCPU的深度解析)





 求解二維 Rastrigin 函數最小值問題)
】深入理解 on、jobs、steps 的核心語法與執行邏輯)

什么是渲染管線)




以pinia為中心的開發模板)



全面指南)
