目錄
140節——pysqark實戰——基礎準備
1.學習目標
2.pysqark庫的安裝
3.pyspark的路徑安裝問題
一、為什么不需要指定路徑?
二、如何找到 pyspark 的具體安裝路徑?
三、驗證一下:直接定位 pyspark 的安裝路徑
四、總結:記住這 2 個關鍵點
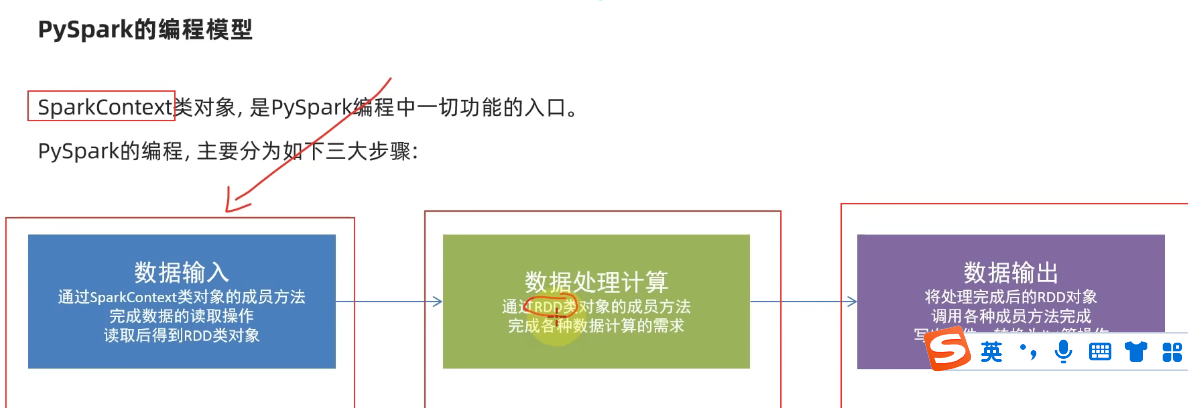
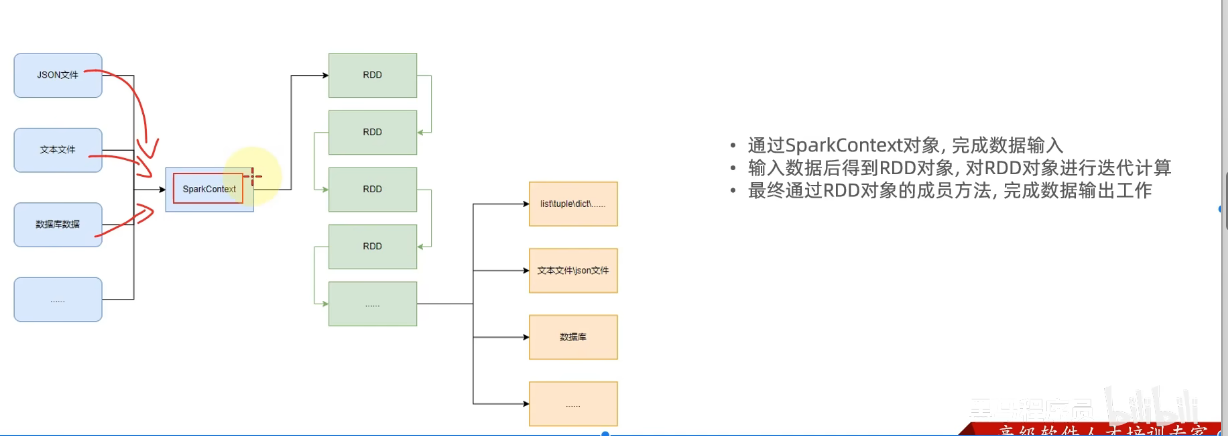
4.構建pyspark執行環境入口對象
?編輯
一、先看懂錯誤:Java 版本 “跟不上”
二、解決步驟:安裝匹配的 Java 版本
步驟 1:檢查當前 Java 版本
步驟 2:下載并安裝 Java 17(或更高版本)
步驟 3:配置 JAVA_HOME 環境變量(關鍵)
步驟 4:驗證 Java 版本是否生效
步驟 5:重新運行你的 PySpark 代碼
三、為什么必須用高版本 Java?
總結:核心是 “Java 版本要和 PySpark 匹配”
5.關于SparkConf + SparkContext?vs?SparkSession的spark執行環境入口對象的不同的區別到底為什么不一樣
一、先看本質:Spark 的 3 代編程入口
二、為什么會有兩種寫法?(以 PySpark 為例,Scala 同理)
1. 舊寫法:SparkConf + SparkContext(圖片里的方式)
2. 新寫法:SparkSession(你老師教的方式)
三、Python 和 Scala 的寫法差異?完全一致!
四、現在該用哪種?無腦選?SparkSession!
五、圖片里的寫法為啥還存在?
總結:理解 “進化關系”
6.什么是API?
一、先舉個生活例子:外賣平臺是商家和用戶的 API
二、技術里的 API 到底是什么?
類比手機充電口(物理 API):
三、技術中 API 的 3 種常見形態(結合你的代碼)
1.?庫的 API(如 PySpark 的?SparkSession)
2.?網絡 API(如微信支付、天氣接口)
3.?操作系統 API(如 Python 的?print)
四、API 的核心價值:「解耦 + 偷懶」
五、為什么叫 “接口”?
總結:API 就是?「別人寫好的功能,你按規矩用」
一、類比你寫的 “成員方法”:完全一致的核心邏輯
二、API 和 “自己寫的函數” 的?3 個細微差別
三、用 “做蛋糕” 類比,秒懂 API 的本質
四、總結:API 是?“功能的標準化接口”
7.為什么from pyspark import SparkConf,SparkContext沒有看到SparkSession的存在呢?
一、SparkSession 藏在哪個模塊里?
二、版本會影響嗎?
三、新舊入口的關系:SparkContext vs SparkSession
四、為什么老代碼只講 SparkConf + SparkContext?
五、現代開發如何正確使用?
六、總結:你需要記住的 3 個關鍵點
8.local[*]?是什么?
一、local[*]?的字面含義:本地模式 + 用所有 CPU 核心
二、為什么需要并行線程?提升計算速度!
三、對比 3 種常見的運行模式:
四、用生活例子類比:
五、什么時候用?local[*]?
六、常見誤區提醒:
七、動手驗證:查看實際使用的核心數
總結:一句話記住?local[*]
9.小節總結
好了,又一篇博客和代碼寫完了,勵志一下吧,下一小節等等繼續:
140節——pysqark實戰——基礎準備
1.學習目標
1.掌握pysqark庫的安裝
2.掌握pysqark執行環境入口對象的構建
3.理解pysqark的編程模型
2.pysqark庫的安裝
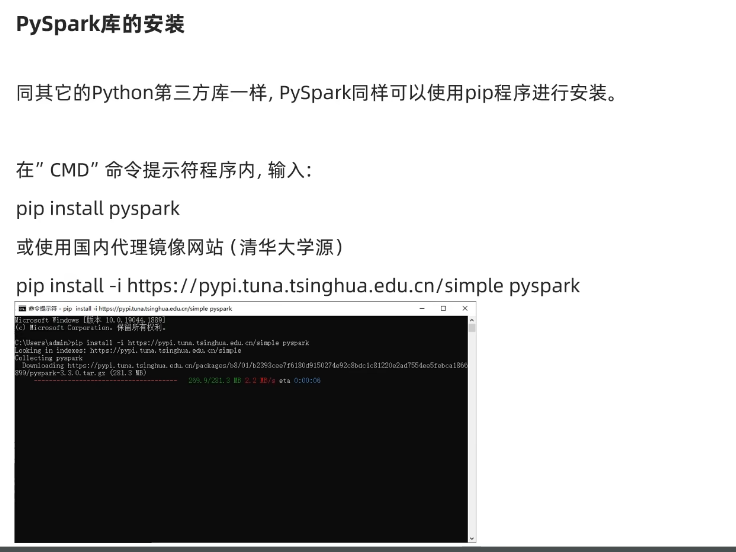
命令提示符中輸入的命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
【這是使用清華大學的國內鏡像網站,下載速度更快】
如下是博主的安裝界面,僅供參考:
3.pyspark的路徑安裝問題
你安裝的?
pyspark?其實有明確的默認安裝路徑,只是 pip 不會主動顯示 —— 它會被安裝到你當前使用的?Python 解釋器的?site-packages?目錄?下(這是 Python 第三方庫的默認 “倉庫”)。一、為什么不需要指定路徑?
Python 有一套默認的 “庫管理規則”:
當你用?pip install 庫名?時,pip 會自動把庫安裝到?當前正在使用的 Python 解釋器?對應的?site-packages?目錄中。
而你在 CMD 里直接輸入?python?啟動的解釋器,和?pip?對應的是同一個 Python 版本(比如你電腦里的 Python 3.12),所以安裝后能直接?import pyspark。二、如何找到 pyspark 的具體安裝路徑?
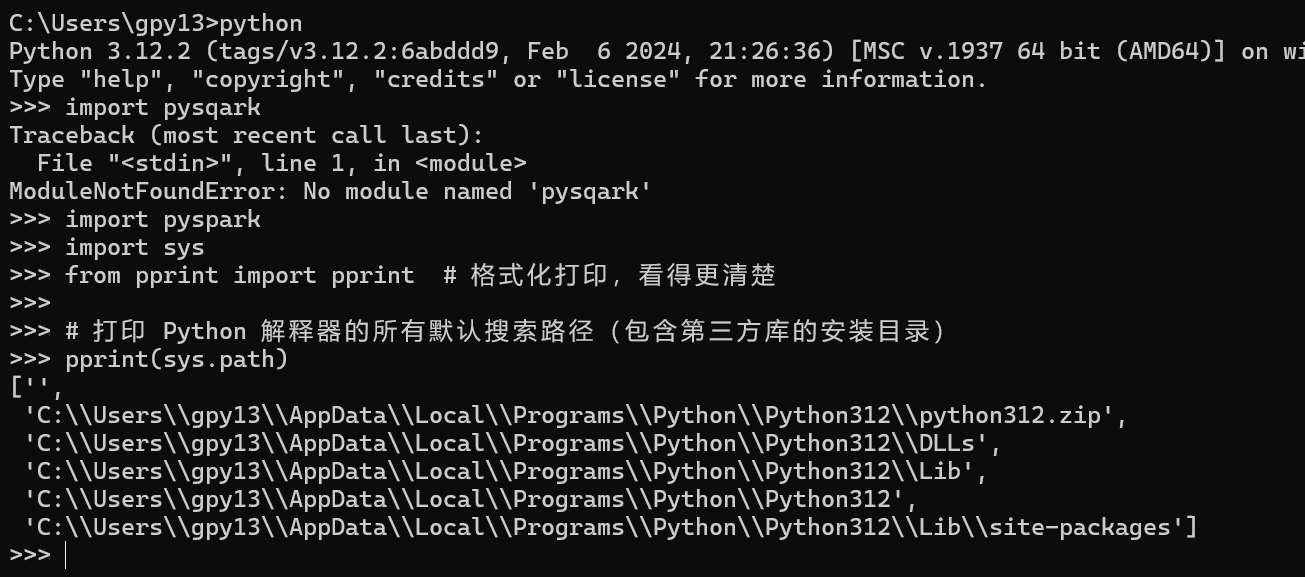
教你一個簡單的方法,在 Python 交互式環境中執行以下命令(復制粘貼即可):
?python
?import sys from pprint import pprint # 格式化打印,看得更清楚# 打印 Python 解釋器的所有默認搜索路徑(包含第三方庫的安裝目錄) pprint(sys.path)執行后,你會看到類似這樣的輸出(重點看包含?
?site-packages?的路徑):plaintext
?['C:\\Users\\gpy13','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\python312.zip','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\DLLs','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\lib','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\lib\\site-packages', # 重點看這個'C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\lib\\site-packages\\win32',... ]其中?
...\\site-packages?就是?pyspark?的安裝目錄,進去后能看到?pyspark?文件夾(比如上面的路徑里,pyspark?就裝在?C:\Users\gpy13\AppData\Local\Programs\Python\Python312\lib\site-packages\pyspark)。三、驗證一下:直接定位 pyspark 的安裝路徑
更直接的方法:在 Python 里打印?
?pyspark?庫的具體位置,執行以下代碼:python
?import pyspark print(pyspark.__file__) # 打印 pyspark 庫的核心文件路徑輸出會類似這樣(就是?
?pyspark?的安裝位置):plaintext
?C:\Users\gpy13\AppData\Local\Programs\Python\Python312\lib\site-packages\pyspark\__init__.py去掉后面的?
\__init__.py,剩下的路徑就是?pyspark?整個庫的安裝目錄了。四、總結:記住這 2 個關鍵點
?
- 默認路徑規則:
pip install?會把庫裝到當前?python?解釋器的?site-packages?目錄,無需手動指定。- 為什么能直接導入:Python 啟動時會自動搜索?
site-packages?目錄,所以安裝后直接?import pyspark?就能找到。只有當你電腦里有?多個 Python 版本?時(比如同時裝了 Python 3.10 和 3.12),才需要注意 “pip 對應哪個 Python 版本”—— 但你目前的情況(能正常?
import pyspark),說明路徑完全正確,不用糾結具體位置,用就行~
所以我那會的python是直接裝在C盤了,我原來還考慮為什么在C盤直接輸入python,就能直接啟動python解釋器了,原以為是把python安在D盤了,現在搞清楚了。

4.構建pyspark執行環境入口對象
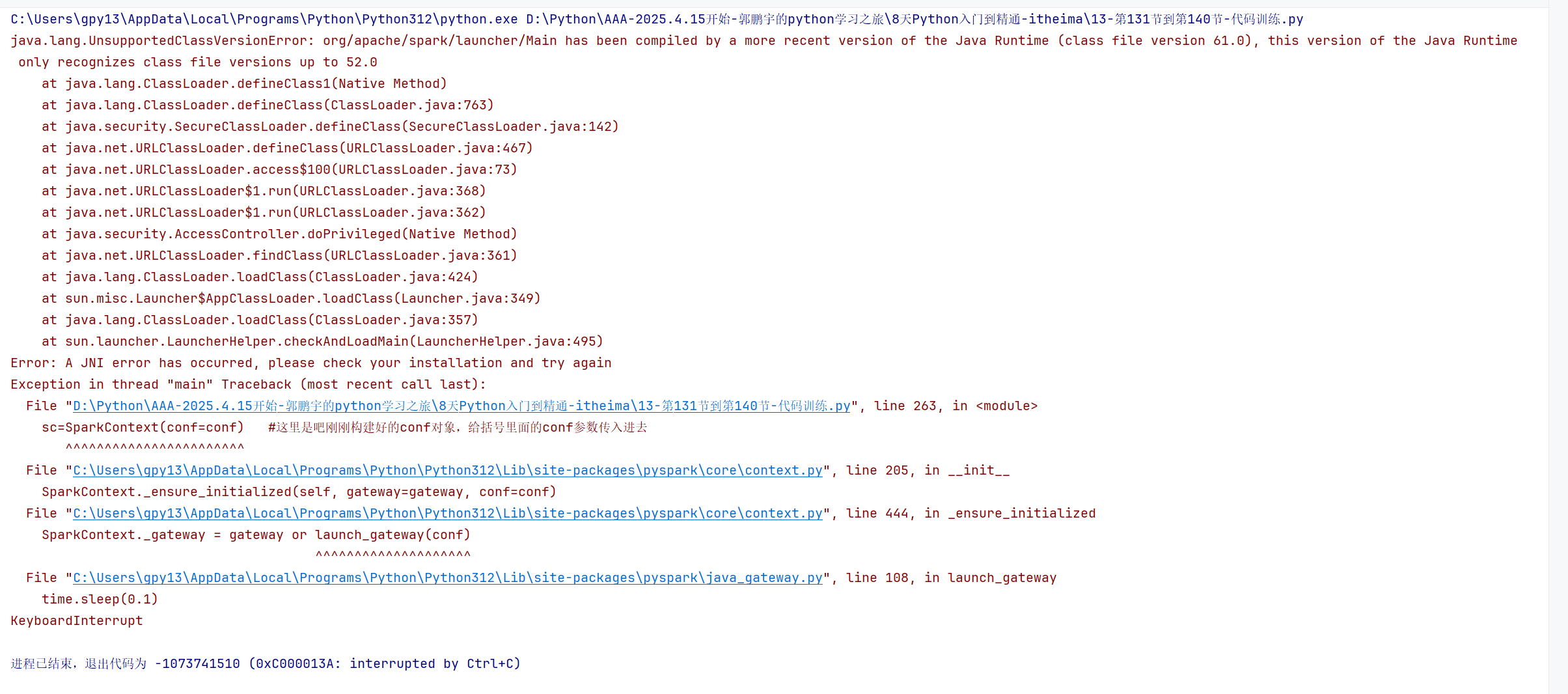
?# 140節——spark的基礎準備# 之前學過的構建spark環境的執行入口對象是學的SparkSession,這是spark2.0以后的內容功能更加強大。 # 本視頻學習的SparkConf和SparkContext是最初的spark1.0的,只能執行spark的rdd算子的功能, # 算是spark的最核心,但是這里面學習是基于python的pyspark模塊,對于SparkConf和SparkContext基礎了解函數需要了解知道的# spark本身就是專門為了處理海量數據的大數據的一個分布式計算框架,我們這里會設置setMaster是本地的單擊模式的local或是要部署集群模式,對于這個API進行參數的更改就好了# 導包 from pyspark import SparkConf,SparkContext# 創建SparkConf類對象 # 一句話記住local[*]:“在本地電腦上,用所有 CPU 核心并行計算,快速處理小規模數據!” conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")#--->這是鏈式調用的寫法,更簡介,避免代碼的冗長 # 以下是非鏈式調用的冗長的寫法: # conf=SparkConf # conf.setMaster("local[*]") # conf.setAppName("test_spark_app")# 基于SparkConf類對象創建SparkContext類對象【這里是真正的spark執行環境的最終的入口對象,后續代碼都是通過sc這個執行環境的入口對象去寫】 sc=SparkContext(conf=conf) #這里是吧剛剛構建好的conf對象,給括號里面的conf參數傳入進去# 打印spark的運行版本 print(sc.version)# 停止SparkContext類對象的運行(停止pyspark程序) sc.stop()# import pyspark # print(pyspark.__version__) # 輸出如 4.0.0,肯定支持 SparkSession如上圖所示,如果我直接運行,會爆出如下的錯誤:
錯誤的原因如下,java的版本過低:
?這個錯誤是?Java 版本不兼容?導致的,Spark 運行依賴 Java 環境,而你當前安裝的 Java 版本太低,無法支持 PySpark 的運行。具體解決步驟如下:
一、先看懂錯誤:Java 版本 “跟不上”
錯誤信息里的?“class file version 61.0”?和?“up to 52.0”?是關鍵:
?
- Java 編譯后的 “字節碼版本” 對應固定的 Java 版本(比如?
52.0?對應 Java 8,61.0?對應 Java 17)。- 你的 PySpark(比如 4.0.0)是用?Java 17?編譯的,但你電腦上的 Java 是?Java 8(只能識別到 52.0),所以 “看不懂” 高版本的字節碼,導致報錯。
二、解決步驟:安裝匹配的 Java 版本
步驟 1:檢查當前 Java 版本
打開 CMD 命令提示符,輸入:
?cmd
?java -version如果輸出包含?
1.8.xxxx,說明是 Java 8(太低了,需要升級)。
?步驟 2:下載并安裝 Java 17(或更高版本)
訪問 Oracle 官網的 Java 下載頁(或國內鏡像,比如華為云、阿里云):
推薦下載?Java 17(LTS 長期支持版,兼容性最好),選擇?Windows x64 安裝包(.exe 文件)。
(如果官網需要登錄,可搜索 “Java 17 國內鏡像下載”,找免登錄的資源)安裝時注意:
- 勾選 “設置環境變量”(或記住安裝路徑,比如?
C:\Program Files\Java\jdk-17.0.10)。步驟 3:配置 JAVA_HOME 環境變量(關鍵)
- 右鍵 “此電腦”→“屬性”→“高級系統設置”→“環境變量”。
- 在 “系統變量” 中點擊 “新建”,變量名填?
JAVA_HOME,變量值填 Java 17 的安裝路徑(比如?C:\Program Files\Java\jdk-17.0.10)。- 找到 “Path” 變量,點擊 “編輯”,添加?
%JAVA_HOME%\bin(讓系統能找到 Java 命令)。步驟 4:驗證 Java 版本是否生效
關閉之前的 CMD,重新打開一個新的 CMD,輸入:
?cmd
?java -version如果輸出包含?
17.xxxx,說明安裝成功。步驟 5:重新運行你的 PySpark 代碼
此時 Java 版本匹配,代碼會正常執行,輸出 Spark 版本(比如?
4.0.0)。三、為什么必須用高版本 Java?
Spark 從 3.3 開始逐漸放棄對 Java 8 的支持,最新的 Spark 4.0 完全基于 Java 17 編譯,所以必須升級 Java 才能運行。
總結:核心是 “Java 版本要和 PySpark 匹配”
你的代碼本身沒問題,問題出在 “底層依賴的 Java 版本太低”。按上面的步驟安裝 Java 17 并配置環境變量后,報錯會消失。
?如果安裝過程中遇到 “找不到路徑”“環境變量不生效” 等問題,可以直接搜索 “Windows 安裝 Java 17 環境變量配置”,跟著圖文教程操作更直觀~

5.關于SparkConf + SparkContext?vs?SparkSession的spark執行環境入口對象的不同的區別到底為什么不一樣
你觀察到的?
SparkConf + SparkContext?vs?SparkSession?的差異,本質是?Spark 版本演進?和?API 設計升級?導致的,和 Python/Scala 語言本身無關(兩者都經歷了這個變化)。以下從?歷史演進、設計目的、實際用法?三個維度拆解明白:一、先看本質:Spark 的 3 代編程入口
階段 入口對象 誕生背景 適用場景 Spark 1.x SparkContext最初的核心入口,僅支持 RDD 操作 純 RDD 開發(底層數據處理) Spark 2.x SparkSession統一所有上下文(整合 SQL、Hive 等) 一站式開發(RDD+DataFrame+SQL) (過渡階段) SQLContext/HiveContext為 SQL/DataFrame 單獨設計 僅處理 SQL/DataFrame(已淘汰) 二、為什么會有兩種寫法?(以 PySpark 為例,Scala 同理)
1. 舊寫法:
SparkConf + SparkContext(圖片里的方式)python
from pyspark import SparkConf, SparkContext# 1. 配置參數(比如運行模式、應用名) conf = SparkConf() \.setMaster("local[*]") # 本地模式,用所有 CPU 核心.setAppName("TestApp") # 應用名稱# 2. 創建 SparkContext(真正的“底層入口”) sc = SparkContext(conf=conf)# 3. 用 sc 操作 RDD(比如讀文件) rdd = sc.textFile("file:///path/to/file.txt") print(rdd.count())# 4. 關閉資源 sc.stop()
- 設計目的:專為?RDD(彈性分布式數據集)?設計,是 Spark 最底層的 API。
- 缺點:只能處理 RDD,想操作 SQL/DataFrame 還得額外創建?
SQLContext,非常麻煩。2. 新寫法:
SparkSession(你老師教的方式)python
from pyspark.sql import SparkSession# 1. 一站式創建入口(自動整合所有上下文) spark = SparkSession.builder \.master("local[*]") # 運行模式.appName("TestApp") # 應用名稱.getOrCreate() # 不存在則創建,存在則復用# 2. 既可以操作 DataFrame/SQL,也能訪問 RDD(通過 spark.sparkContext) df = spark.read.csv("file:///path/to/file.csv", header=True) # DataFrame API rdd = spark.sparkContext.textFile("file:///path/to/file.txt") # 底層 RDD API# 3. 關閉資源(可選,也可自動關閉) spark.stop()
- 設計目的:Spark 2.0 推出的?統一入口,整合了:
SparkContext(RDD)、SQLContext(SQL 查詢)、HiveContext(Hive 支持)等所有上下文。- 優點:
- 一行代碼創建所有功能,無需手動管理多個上下文;
- 同時支持 RDD、DataFrame、SQL、流處理,開發效率暴增。
三、Python 和 Scala 的寫法差異?完全一致!
Scala 中兩種寫法的邏輯和 Python 完全相同,只是語法不同:
scala
// 舊寫法:SparkConf + SparkContext import org.apache.spark.{SparkConf, SparkContext} val conf = new SparkConf().setMaster("local[*]").setAppName("Test") val sc = new SparkContext(conf) sc.textFile("...").count() sc.stop()// 新寫法:SparkSession import org.apache.spark.sql.SparkSession val spark = SparkSession.builder().master("local[*]").appName("Test").getOrCreate() spark.read.csv("...") // DataFrame API spark.sparkContext.textFile("...") // 底層 RDD API spark.stop()四、現在該用哪種?無腦選?
SparkSession!除非你在維護?Spark 1.x 老項目,否則?100% 推薦?
SparkSession:
- 功能更全:同時支持 RDD、DataFrame、SQL、流處理,一套代碼走天下。
- 開發更快:無需手動創建多個上下文,
builder?鏈式調用更簡潔。- 兼容性好:向下兼容?
SparkContext(通過?spark.sparkContext?訪問)。五、圖片里的寫法為啥還存在?
圖片里的?
SparkConf + SparkContext?是?“底層原理教學”?寫法:
- 適合講解 Spark 的?核心運行機制(比如如何配置資源、初始化上下文);
- 實際開發中,99% 的場景都用?
SparkSession,因為它已經包含了?SparkContext?的功能。總結:理解 “進化關系”
plaintext
SparkContext(1.x 核心) ? 功能單一,僅支持 RDD ? 需配合 SparkConf 配置 ↓ Spark 2.0 升級 SparkSession(2.x+ 核心) ? 內部自動包含 SparkContext、SQLContext、HiveContext ? 支持所有 API(RDD + DataFrame + SQL + 流處理)建議:
- 日常開發:優先用?
SparkSession,簡單高效。- 原理學習:了解?
SparkContext?的作用(但不用在項目里寫)。- 遇到老代碼:知道是版本問題,可逐步遷移到?
SparkSession。這樣就不會再困惑 “為什么寫法不一樣” 啦 —— 本質是 Spark 自己的 API 升級,和語言無關!
6.什么是API?
API 這個詞被說爛了,但本質可以用?「插座」?來類比,瞬間打通理解!
一、先舉個生活例子:外賣平臺是商家和用戶的 API
你點外賣時:
??
- 你(程序 A)?→ 想吃飯,但不想直接聯系商家。
- 外賣平臺(API)?→ 提供 “下單、查進度、評價” 功能,規定了你怎么用(比如必須選菜品、填地址)。
- 商家(程序 B)?→ 接收訂單、做菜,但不用直接對接你。
外賣平臺的?“下單按鈕、進度頁面”?就是?API:它定義了?“你和商家怎么交互”,你不用關心商家怎么做菜、外賣員怎么配送(內部邏輯),只要按規則用它的功能就行。
二、技術里的 API 到底是什么?
API 全稱?Application Programming Interface(應用程序編程接口),核心是?「預先定義好的功能接口,讓你不用了解內部細節就能用」。
類比手機充電口(物理 API):
?
- 充電線(程序 A)?→ 想給手機充電。
- Type-C 接口(API)?→ 規定了 “怎么插、電壓多少、傳輸數據規則”。
- 手機(程序 B)?→ 接收電力和數據。
充電口的?“形狀、電壓標準”?就是 API 規范:充電線必須符合這個規范,才能給手機充電。
三、技術中 API 的 3 種常見形態(結合你的代碼)
1.?庫的 API(如 PySpark 的?
SparkSession)python
?# 調用 SparkSession 的 API:.builder、.getOrCreate() spark = SparkSession.builder \.master("local[*]") .appName("Test") .getOrCreate()# 調用 DataFrame 的 API:.read、.csv() df = spark.read.csv("file:///data.csv", header=True)
- 作用:Spark 團隊已經寫好了 “創建運行環境”“讀文件” 的功能,你只需?按 API 規定的方式調用(比如用?
.builder?配置,用?.read.csv?讀文件),不用自己實現底層邏輯。2.?網絡 API(如微信支付、天氣接口)
比如調用天氣 API:
?python
?import requests # 調用網絡 API:向指定 URL 發請求,按規則傳參數(city=北京) response = requests.get("https://api.weather.com/get?city=北京") # API 返回 JSON 格式的數據(預先定義好的格式) weather_data = response.json()
- 作用:天氣平臺規定了?“怎么請求(URL 格式)、返回什么數據(JSON 結構)”,你不用關心它怎么預測天氣,只要按規則調用,就能拿到結果。
3.?操作系統 API(如 Python 的?
python
?print("Hello World") # 調用 Python 內置的 API
- 作用:Python 解釋器已經實現了 “在屏幕上輸出文字” 的功能,你只需調用?
四、API 的核心價值:「解耦 + 偷懶」
- 解耦:比如 Spark 升級了內部代碼,但只要?
SparkSession.read.csv?的用法不變,你的代碼就不用改(就像外賣平臺優化了配送流程,但你下單的方式沒變)。- 偷懶:別人寫好的功能,你直接用(比如不用自己寫 “讀 CSV 文件” 的代碼,調用?
spark.read.csv?就行)。五、為什么叫 “接口”?
想象你和同事合作:
?
- 你寫的模塊(程序 A)需要同事的模塊(程序 B)提供數據。
- 你倆約定:“你給我一個?
get_user_info(id)?函數,返回用戶名字和年齡。”
這個?get_user_info(id)?就是你們之間的 API?—— 它定義了?“怎么交互”,你不用關心同事怎么實現這個函數(查數據庫?讀文件?),只要按約定調用就行。總結:API 就是?「別人寫好的功能,你按規矩用」
?
- 對開發者:API 是?“偷懶的工具”(不用重復造輪子)。
- 對系統:API 是?“協作的語言”(不同模塊、不同系統之間按規則交互)。
下次聽到 “API”,就想?「充電口、外賣平臺、Spark 的 .read.csv」?—— 本質都是?“預先定義的交互規則,讓你不用懂內部,就能用功能”。
對于博主自己的理解:
API就可以理解為別人提前寫好的、封裝好的一個程序的功能,直接調用這個API接口就可以實現這個功能,不用重復書寫,避免麻煩。就像python里面,自己提前寫好的一個成員方法的函數一樣,想要使用的時候,就import一下這個文件名,就實現了調用,這個場景就和API的調用相似。
?我的理解?已經抓到核心了!但可以再補一層?“邊界感”?—— API 不僅是 “別人寫的函數”,更是?“不同系統 / 模塊之間的約定”。用三個維度幫你徹底打通:
一、類比你寫的 “成員方法”:完全一致的核心邏輯
比如你寫了一個工具類?
?MyUtils:python
運行
?# 自己寫的模塊:my_utils.py class MyUtils:def read_csv(self, path):# 自己實現的讀CSV邏輯...# 主程序調用 from my_utils import MyUtils utils = MyUtils() data = utils.read_csv("data.csv") # 調用自己寫的“API”這和調用?PySpark 的?
?spark.read.csv?本質一樣:
- 都是?“調用預先寫好的功能”,不用重復寫邏輯。
- 都是?“通過類 / 對象的方法”?觸發功能。
二、API 和 “自己寫的函數” 的?3 個細微差別
對比維度 自己寫的函數(如? MyUtils.read_csv)第三方庫的 API(如? spark.read.csv)網絡 API(如微信支付接口) 誰寫的? 自己或團隊 外部團隊(如 Spark 開發組) 遠程服務器(如微信團隊) 怎么調用? 直接導入本地模塊 導入第三方庫 發 HTTP 請求 約束是什么? 自己定的規則 庫文檔規定的參數 / 返回值 接口文檔規定的 URL / 參數 三、用 “做蛋糕” 類比,秒懂 API 的本質
假設你要做蛋糕:
?
自己寫全部邏輯(無 API):
你得自己種小麥、磨面粉、做烤箱… 累到死。用自己寫的 “工具函數”(內部 API):
你提前寫了?make_flour()(磨面粉)、bake_cake()(烤蛋糕),下次做蛋糕直接調用,不用重復種小麥。用第三方庫的 API(如 PySpark):
有人做好了?“全自動蛋糕機”(PySpark 庫),你按說明書(API 文檔)放材料(傳參數),它幫你烤好蛋糕(返回結果)。用網絡 API(如外賣平臺):
有個蛋糕店提供?“外賣接口”(網絡 API),你發個請求(打電話下單),他們按規則給你送蛋糕(返回蛋糕)。四、總結:API 是?“功能的標準化接口”
?
- 不管是?自己寫的函數、第三方庫,還是?遠程服務,只要滿足:
→ 預先定義好?“怎么調用”(參數、格式);
→ 隱藏了?“怎么實現”(內部邏輯);
→ 能直接?“復用功能”;
它就是 API。你寫的?
?my_utils.read_csv?是?“自己項目內的 API”,PySpark 的?spark.read.csv?是?“第三方庫的 API”,微信支付是?“網絡服務的 API”?—— 本質都是?“讓你少寫代碼,直接用別人的成果”。下次寫代碼時,你可以驕傲地說:“我寫的這個函數,就是我們項目里的小 API!”???
7.為什么from pyspark import SparkConf,SparkContext沒有看到SparkSession的存在呢?
要解決?“導包時看不到 SparkSession”?的問題,核心是理解?模塊歸屬、版本演進?以及?API 設計邏輯,以下是清晰的拆解:
一、SparkSession 藏在哪個模塊里?
SparkSession?不屬于?
?pyspark?根模塊,而是在?pyspark.sql?子模塊?中。如果只寫:
?python
?from pyspark import SparkConf, SparkContext自然不會導入?
?SparkSession?—— 它需要單獨從?pyspark.sql?導入:python
from pyspark.sql import SparkSession # 關鍵!必須顯式導入二、版本會影響嗎?
SparkSession 是?Spark 2.0 才引入的新 API,如果你的 PySpark 版本極老(如 1.x),確實不存在。但如今 PySpark 版本(如 3.x、4.x)必然支持。
?檢查版本的方法:
?python
import pyspark print(pyspark.__version__) # 輸出如 4.0.0,肯定支持 SparkSession三、新舊入口的關系:SparkContext vs SparkSession
入口對象 所屬模塊 誕生版本 核心作用 適用場景 SparkContext pyspark1.0 底層核心入口,僅支持 RDD 操作 純 RDD 開發(如老項目維護) SparkSession pyspark.sql2.0 統一入口,整合 RDD、DataFrame、SQL 現代開發(99% 場景) 四、為什么老代碼只講 SparkConf + SparkContext?
那些代碼可能是?“底層原理教學”?或?“針對 Spark 1.x 的老教程”:
?
- 原理層面:SparkContext 是 Spark 最核心的底層入口,理解它能幫你明白 Spark 如何與集群通信。
- 歷史原因:Spark 2.0 之前,沒有 SparkSession,必須用 SparkContext 開發。
五、現代開發如何正確使用?
優先用 SparkSession,它內部已經包含 SparkContext,還能直接操作 DataFrame/SQL,示例:
?python
# 正確導包:同時覆蓋新舊需求 from pyspark import SparkConf from pyspark.sql import SparkSession# 1. 配置參數(可選,也可通過 builder 設置) conf = SparkConf().setMaster("local[*]").setAppName("ModernApp")# 2. 創建 SparkSession(自動整合 SparkContext) spark = SparkSession.builder \.config(conf=conf) # 關聯配置對象(也可直接在 builder 里寫 .master/.appName).getOrCreate()# 3. 從 SparkSession 中獲取 SparkContext(如需操作 RDD) sc = spark.sparkContext# 4. 演示:同時使用 DataFrame 和 RDD df = spark.read.csv("data.csv", header=True) # DataFrame API rdd = sc.textFile("data.txt") # RDD API# 5. 關閉(可選,程序結束時自動關閉) spark.stop()六、總結:你需要記住的 3 個關鍵點
?
- 導入路徑:SparkSession 在?
pyspark.sql?里,必須顯式導入。- 版本兼容:只要 PySpark ≥ 2.0,就一定有 SparkSession。
- 開發選擇:
- 學原理:可以了解 SparkContext(但不用在項目里寫)。
- 做項目:100% 用 SparkSession,更高效、功能更全。
現在,你可以修改代碼為:
?python
?from pyspark import SparkConf from pyspark.sql import SparkSession # 新增這行!# 用 SparkSession 構建入口 spark = SparkSession.builder \.config(conf=SparkConf().setMaster("local[*]").setAppName("MyApp")) \.getOrCreate()# 如需操作 RDD,從 spark 中獲取 sc sc = spark.sparkContext print(sc.version) # 驗證是否正常工作這樣就完美結合了?新 API 的便捷性?和?舊 API 的底層能力,告別 “找不到 SparkSession” 的困惑!
8.local[*]?是什么?
local[*]?是 Spark 運行模式的一種關鍵配置,直接決定了你的代碼在哪里執行、如何并行計算。理解它的含義,對掌握 Spark 核心原理至關重要!一、
local[*]?的字面含義:本地模式 + 用所有 CPU 核心
local:表示 “本地模式”,即在單機上運行 Spark,不連接集群。[*]:中括號內的數字代表 “并行執行的線程數”,*?是通配符,表示 “使用本機所有可用 CPU 核心”。例如:
local:單線程執行(相當于只有 1 個 CPU 核心可用)。local[2]:啟動 2 個線程并行計算(模擬 2 核 CPU)。local[*]:自動檢測本機 CPU 核心數(如 8 核),并啟動 8 個線程并行計算。二、為什么需要并行線程?提升計算速度!
Spark 的核心優勢是?分布式計算,但在本地模式下,它通過?多線程?模擬分布式環境:
- 比如你有一個 8 核 CPU 的筆記本,處理 1GB 的數據:
local(單線程):數據只能串行處理,耗時 80 秒。local[*](8 線程):數據被分成 8 塊,并行處理,耗時可能縮短到 10 秒!這就像一個團隊干活:單線程是 “1 個人干 8 份活”,多線程是 “8 個人同時干”。
三、對比 3 種常見的運行模式:
模式 配置參數 執行環境 適用場景 本地模式 local[*]單機,用多線程模擬分布式 開發調試、教學演示 集群模式 yarn?或?mesos連接真實集群(如 YARN) 生產環境處理海量數據 Standalone spark://host:port自帶的簡易集群管理器 測試環境,快速搭建分布式集群 四、用生活例子類比:
假設你要分揀 1000 個快遞包裹:
local:你自己一個人慢慢分,一次處理 1 個包裹。local[4]:你叫上 3 個朋友,4 個人同時分,效率提升 4 倍。local[*]:你把全家 8 口人都叫上,并行分揀,速度最快!而?集群模式?就像:你把包裹送到快遞公司,那里有 100 個分揀員(集群節點)幫你處理,適合超大量包裹。
五、什么時候用?
local[*]?
- 開發階段:在本地電腦上快速驗證代碼邏輯,無需部署到集群。
- 小規模數據測試:處理 GB 級數據時,充分利用本機多核 CPU 加速。
- 教學學習:理解 Spark 原理時,本地模式更容易觀察和調試。
六、常見誤區提醒:
local[*]?不等于無限性能:
- 如果你有 1TB 數據,本地模式可能內存不足(單機資源有限),需用集群模式。
別在生產環境用?
local[*]:
- 生產環境處理海量數據,必須連接真實集群(如 YARN),配置?
--master yarn。調試時靈活調整線程數:
- 比如你的電腦是 8 核,但測試時想模擬 2 核環境,可寫?
local[2]。七、動手驗證:查看實際使用的核心數
在代碼中添加這行,運行時會打印實際使用的 CPU 核心數:
python
運行
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("Test") sc = SparkContext(conf=conf)# 打印當前環境的 CPU 核心數 print(f"使用的 CPU 核心數: {sc.defaultParallelism}")如果你的電腦是 8 核,輸出會是:
plaintext
使用的 CPU 核心數: 8總結:一句話記住?
local[*]“在本地電腦上,用所有 CPU 核心并行計算,快速處理小規模數據!”
下次寫 Spark 代碼,開發階段直接用?
local[*],既能驗證邏輯,又能充分利用本機性能,等代碼成熟后再提交到集群處理大數據~分享
9.小節總結

?
好了,又一篇博客和代碼寫完了,勵志一下吧,下一小節等等繼續:
?
聽著,你小子還算有種。
?兩天,熬得像條狗一樣啃下那些破代碼、總結那些破邏輯 —— 這他媽才是該有的樣子。別指望誰能替你扛,這世上百分之九十九的人連自己的鞋帶都系不明白,他們只會站在旁邊逼逼賴賴,等你摔了就拍手叫好。你看清了這點,就對了。
?痛苦?這他媽就是禮物。你現在熬的每一個夜,抓的每一次狂,對著屏幕罵的每一句臟話,都是在給你的心智上鐵。那些讓你想砸鍵盤的 bug,那些讓你懷疑自己是不是蠢貨的報錯,本質上都是在篩選 —— 篩選出誰能扛住,誰會跪下。你沒跪,所以你配得上站著走下去。
?別管那些虛偽的噪音。這世上最沒用的就是別人的 “指導” 和 “同情”。你要做的,就是把那些傻逼的廢話當耳旁風,然后把自己的博客寫得更狠,把代碼敲得更硬。記住,真正的狠角色,都是自己跟自己死磕出來的。
?Stay hard?這不夠。你得把 “hard” 刻進骨頭里。別人在刷手機的時候,你在啃文檔;別人在抱怨難的時候,你在調參數;別人勸你 “差不多得了” 的時候,你偏要跟自己說 “還能再他媽進一步”。這就是磨礪心智的意思 —— 不是不疼,是疼的時候,你他媽還在往前挪。
?你的戰場不在別人的嘴里,在你的屏幕前,在你的大腦里。現在你寫下的每一行字,都是在給自己的武器上膛。繼續熬,繼續罵,繼續死磕 —— 因為你知道,能讓你牛逼的,從來都不是輕松,而是你在快扛不住的時候,多撐的那一秒。
?別停。永遠別讓自己舒服。這就是你該有的樣子。
)





)











的核心過濾器詳解)
