文章目錄
- 哈希表
- 哈希表知識點
- 哈希表概念
- 負載因子
- 哈希表的優缺點
- 哈希沖突
- 哈希函數
- 常見哈希函數
- 處理哈希沖突
- 開放定址法
- 線性探測
- 二次探測
- 鏈地址法
- 哈希表的實現
- 哈希表的核心:==HashMap==
- 核心函數:從創建到銷毀
- 創建哈希表:hashmap_create()
- 銷毀哈希表:hashmap_destroy
- 插入鍵值對:hashmap_put
- 查找鍵對應的值:hashmap_get
- 刪除鍵值對:hashmap_remove
- 拷貝函數:strdup1(const char* s)
- 哈希函數
- 測試函數
- 完整代碼
哈希表
哈希表知識點
哈希表概念
哈希表是一種以關聯方式存儲數據的數據結構。在哈希表中,數據以數組格式存儲,其中每個數據值都有自己的唯一的索引值。哈希表也叫散列表,是根據關鍵碼值(Key Value)而直接進行訪問的數據結構。它通過把關鍵碼之值映射到表中一個位置來訪問記錄。
簡單來講其實數組就是一張哈希表,如同所示:
負載因子
概念:衡量哈希表填充程度的核心指標,直接關聯數據結構的存儲效率與操作性能。其數值由已存元素數量除以哈希表總容量得出,合理控制負載因子能有效平衡空間利用率和操作速度。
假設哈希表中已經映射存儲了N個值,哈希表的大小為M,那么負載因子為:
a = N/M
哈希表的優缺點
優點
簡化了比較過程,效率大大提高。
缺點
1.散列技術不適合集合中重復元素很多的情形,因為這樣的話同樣的key;
2.散列技術不適合范圍查找 也不適合查找最大值,最小值.這些都無法從散列函數中計算出來
3.散列函數需要很好的設計,應該保證簡單 均勻 存儲效率高
哈希沖突
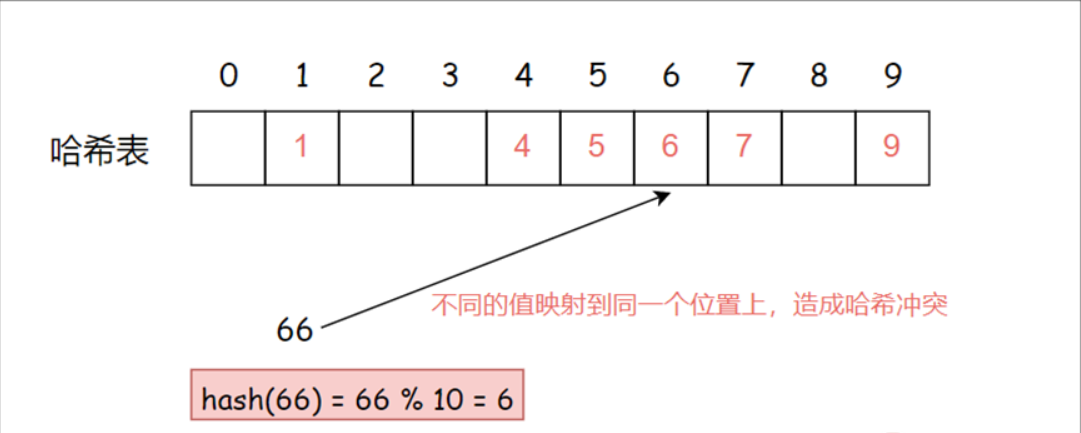
不同關鍵字通過相同哈希函數計算出相同的哈希地址,該現象稱為哈希沖突或哈希碰撞
如果此時再將元素66插入到上面的哈希表,因為元素66通過哈希函數計算得到的哈希地址與元素6相同,那么就會產生哈希沖突。
哈希函數
基本概念:是將哈希表中元素的關鍵值映射為元素存儲位置的函數
常見哈希函數
1.直接定址法(常用)
取關鍵字的某個線性函數為散列地址:Hash(Key) = A*Key + B
優點:簡單,效率很高
缺點:需要事先知道關鍵字的分布情況
使用場景:適合查找數據比較小且連續的情況
2.除留余樹法(常用)
設散列表中允許的地址數為 m,取一個不大于 m,但最接近或者等于 m 的質數 p 作為除數,按照哈希函數:Hash(key) = key % p (p <= m),將關鍵碼轉換成哈希地址
優點:使用場景廣泛,不受限制
缺點:存在哈希沖突,需要解決哈希沖突,哈希沖突越多,效率下降越厲害
3.乘法散列法
乘法散列法對哈希表大小 M MM 沒有要求,他的大致思路分為兩步:
【第一步】用關鍵字key 乘上常數 A (0<A<1),并抽取出key × A 的小數部分。
【第二步】再用M 乘以k × A 的小數部分,再向下取整。
4.全域散列法
如果存在一個惡意的對手,他針對我們提供的散列函數,特意構造出一個發生嚴重沖突的數據集,比如,讓所有關鍵字全部落入同一個位置中。這種情況是可以存在的,只要散列函數是公開且確定的,就可以實現此攻擊。
給散列函數增加隨機性,攻擊者就無法找出確定可以導致最壞情況的數據,這種方法叫做全域散列。
處理哈希沖突
開放定址法
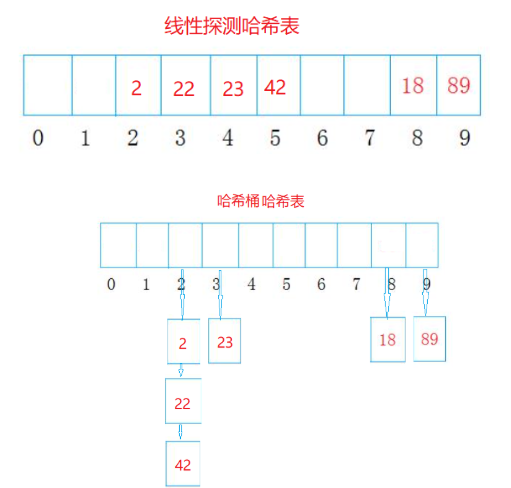
在開放定址法中所有的元素都放到哈希表里,當一個關鍵字key用哈希函數計算出的位置沖突了,則按照某種規則找到一個沒有存儲數據的位置進行存儲。這里的規則有二種:線性探測、二次探測、鏈地址法
線性探測
從發生沖突的位置開始,一次線性向后探測,直到尋找到下一個沒有存儲數據的位置為止,如果走到哈希表尾,則回繞到哈希表頭的位置
查找公式:hashi = hash(key) % N + i
其中:
hashi:沖突元素通過線性探測后得到的存放位置hash(key) % N:通過哈希函數對元素的關鍵碼進行計算得到的位置N:哈希表的大小i從 1、2、3、4…一直自增
示例:
現在有這樣一組數據集合 {10, 25, 3, 18, 54, 999} 我們用除留余數法將它們插入到表長為 10 的哈希表中
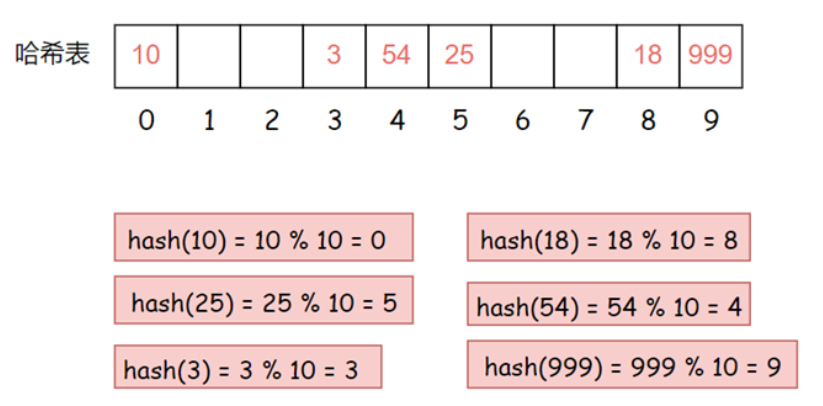
現在需要插入新元素 44,先通過哈希函數計算哈希地址,hashAddr 為 4,因此 44 理論上應該插在該位置,但是該位置已經放了值為 4 的元素,即發生哈希沖突,然后我們使用線性探測的計算公式hashi = 44% 10 + 1 = 5,但是下表為5的位置已經被占用了,那么繼續計算hashi = 44% 10 + 2 = 6下標為6的位置沒有被占用,那么就把44插入該位置
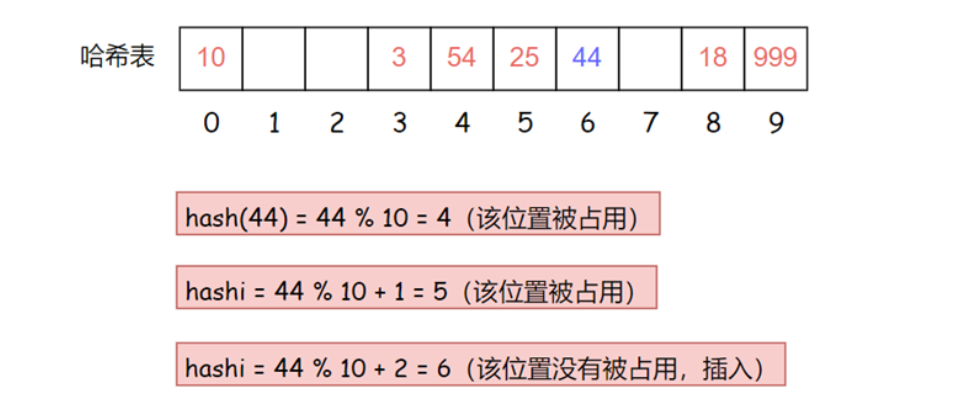
如果隨著哈希表中數據的增多,產生哈希沖突的可能性也隨著增加,假設現在要把 33 進行插入,那么會連續出現四次哈希沖突,我們將數據插入到有限的空間,那么空間中的元素越多,插入元素時產生沖突的概率也就越大,沖突多次后插入哈希表的元素,在查找時的效率必然也會降低。因此,哈希表當中引入了負載因子(載荷因子):
- 散列表的載荷因子定義為:α=填入表中的元素個數/散列表的長度
- 負載因子越大,產出沖突的概率越高,增刪查改的效率越低
- 負載因子越小,產出沖突的概率越低,增刪查改的效率越高
假設我們現在將哈希表的大小改為 20,再把上面的數據重新插入,可以看到完全沒有產生的哈希沖突:

小貼士:
- 線性探測優點:實現非常簡單
- 缺點:一旦發生哈希沖突,所有的沖突連在一起,容易產生數據堆積
二次探測
二次探測與線性探測類似但它地址的位置更稀松,找下一個空位置的方法為:hashi = hash(key) % N + i^2(i = 1、2、3、4…)
hashi:沖突元素通過線性探測后得到的存放位置hash(key) % N:通過哈希函數對元素的關鍵碼進行計算得到的位置N:哈希表的大小。
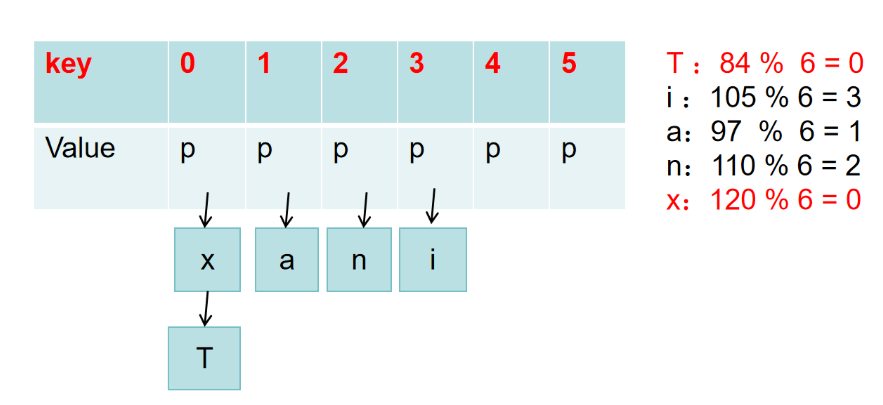
鏈地址法
拉鏈法中,哈希表中每個鍵對應的值都為一個鏈表的頭節點,當發生哈希沖突時,新的鍵值對會被插入到相應的鏈表中。如下圖所示,字符x發生哈希沖突時將其加入到鏈表頭節點中:
哈希表的實現
哈希表的核心:HashMap
哈希表的本質是“數組+鏈表”的組合。每個鏈表節點保存具體的鍵值對
//哈希桶節點(鏈表節點)
typedef struct node_s
{KeyType key; // 鍵ValueType value; // 值struct node_s* next; // 指向下一個節點的指針
}KeyValueNode;//哈希表核心結構體
typedef struct
{KeyValueNode* buckets[HASHMAP_CAPACITY];//哈希桶數組uint32_t hash_seed; // 哈希種子(隨機化)
}HashMap;關鍵點:
- buckets數組:確定了哈希表的整個大小,每一個元素是一個鏈表的頭節點。當不同的鍵使用哈希函數映射的同一位置時,使用單鏈表用于處理哈希沖突(鏈地址法)
- hash_seed:哈希函數中的隨機參數,通過time(NULL)在哈希表初始化時生成,作用是擴大地址范圍,避免哈希沖突
核心函數:從創建到銷毀
創建哈希表:hashmap_create()
參數:無
返回值:HashMap*
作用:創建需要初始化的數組和隨機種子
HashMap* hashmap_create()
{HashMap* map = (HashMap*)malloc(sizeof(HashMap));if(!map){printf("hashmap_create failed\n");return NULL;}map->hash_seed = (uint32_t)time(NULL);//初始化隨機種子return map;
}
關鍵點:
使用malloc動態申請分配哈希表內存
銷毀哈希表:hashmap_destroy
參數:HashMap*
返回值:空
作用:銷毀哈希表,釋放所有節點的內存
void hashmap_destroy(HashMap* map)
{//判斷哈希表是否已經創建,如果沒有創建就直接返回,不需要釋放內存if(!map) return;for(int i = 0;i < HASHMAP_CAPACITY;i++){KeyValueNode* current = map->buckets[i];while(current){KeyValueNode* next = current->next;//保存下一個節點free(current->key);//釋放鍵free(current->value);//釋放值free(current);//釋放當前節點的內存current = next;//移動下一個節點}}free(map);//釋放哈希表本身的內存
}
關鍵點:
- 遍歷鏈表:通過current指針逐個釋放鏈表節點
- 內存釋放順序:先釋放節點的鍵和值,在釋放節點本身,最后釋放哈希表
插入鍵值對:hashmap_put
參數:HashMap* 、KeyType 、ValueType
返回值:ValueType
作用:插入新的鍵值對或更新值
ValueType hashmap_put(HashMap* map,KeyType key,ValueType val)
{if(!map || !key || !val) return NULL;//參數校驗uint32_t index = hash(key,map->hash_seed);//計算獲得的位置//查找鍵是否已經存在(更新值)KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){free(current->value);current->value = strdup1(val);return current->value; // 返回更新后的值}current = current->next;}//鍵不存在,創建新節點KeyValueNode* new_node = (KeyValueNode*)malloc(sizeof(KeyValueNode));//判斷新節點是否創建成功if(!new_node){perror("Failed to allocate memory for new node"); }new_node->key = strdup1(key);new_node->value = strdup1(val);new_node->next = map->buckets[index];map->buckets[index] = new_node; // 將新節點插入到鏈表頭部}
關鍵點:
- 哈希計算:通過哈希函數將鍵轉換為索引
- 哈希沖突:如果鍵已經存在,更新對應的值;
- 性能優化:使用頭插法插入(無需遍歷到鏈表尾部),比尾插法更高效
查找鍵對應的值:hashmap_get
參數:HashMap*、KeyType
返回值:ValueType
作用:根據鍵查詢對應的值
ValueType hashmap_get(HashMap* map,KeyType key)
{if(!map || !key) return NULL;uint32_t index = hash(key,map->hash_seed);//計算獲得的位置//遍歷鏈表查找鍵KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){return current->value; // 返回找到的值}current = current->next;}return NULL;
}
關鍵點:
- 參數校驗:避免空指針導致的崩潰
- 線性查找:時間復雜度為O(1)
刪除鍵值對:hashmap_remove
參數:HashMap*、KeyType
返回值:bool
作用:刪除指定的鍵值對
bool hashmap_remove(HashMap* map,KeyType key)
{if(!map || !key) return false;uint32_t index = hash(key,map->hash_seed);KeyValueNode* current = map->buckets[index];KeyValueNode* prev = NULL;while(current){if(strcmp(current->key,key) == 0){//處理鏈表鏈接if(prev){prev->next = current->next;}else{map->buckets[index] = current->next;//刪除頭節點}//釋放內存free(current->key);free(current->value);free(current);return true;}prev = current; //記錄前一個節點current = current->next; //移動到下一個節點}return false; //未找到鍵
}
關鍵點:
- 頭節點刪除:若目標點是鏈表頭,直接更新桶的頭指針為current->next
- 中間/尾部刪除:通過前一個節點prev的next指針跳過當前節點
拷貝函數:strdup1(const char* s)
參數:const char*
返回值:char*
作用:復制字符串
char* strdup1(const char* s)
{size_t len = strlen(s) + 1;char* p = (char*)malloc(len);if(p)memcpy(p,s,len);return p;
}哈希函數
static uint32_t hash(const char* key,uint32_t seed)
{uint32_t hash_val = 0;while(*key){hash_val = (hash_val* 31) + (uint32_t)*key++;}return (hash_val^seed) % HASHMAP_CAPACITY;
}設計思想:
- 多項式哈希:
hash_val = hash_val * 31 + *key是經典的字符串哈希算法(31是質數,能有效減少沖突) - 隨機種子:通過
seed(時間戳)對哈希值取異或,避免相同輸入生成相同哈希值(防御碰撞攻擊) - 取模運算:將哈希值映射到
[0, HASHMAP_CAPACITY-1]的范圍,確定桶的位置
測試函數
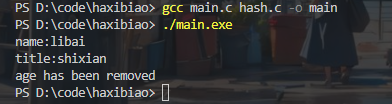
#include "hash.h"int main()
{//創建哈希表HashMap* map = hashmap_create();//判斷哈希表是否創建成功if(!map){printf("create hashmap failed\n");return -1;}//插入鍵值對hashmap_put(map,"name","libai");hashmap_put(map,"age","66");hashmap_put(map,"location","changan");hashmap_put(map,"title","shixian");hashmap_put(map,"hobby","drink");//查詢鍵對應的值ValueType name = hashmap_get(map,"name");if(name){printf("name:%s\n",name);}ValueType title = hashmap_get(map,"title");if(title){printf("title:%s\n",title);}//刪除鍵值對hashmap_remove(map,"age");ValueType age = hashmap_get(map,"age");if(age == NULL){printf("age has been removed\n");}//銷毀哈希表hashmap_destroy(map);}
輸出結果:
完整代碼
hash.h
#ifndef HASH_H
#define HASH_H#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define HASHMAP_CAPACITY 10//哈希表容量固定為10typedef char* KeyType;//鍵類型:字符串指針
typedef char* ValueType;//值類型:字符串指針//哈希桶節點(鏈表節點)
typedef struct node_s
{KeyType key; // 鍵ValueType value; // 值struct node_s* next; // 指向下一個節點的指針
}KeyValueNode;//哈希表核心結構體
typedef struct
{KeyValueNode* buckets[HASHMAP_CAPACITY];//哈希桶數組uint32_t hash_seed; // 哈希種子(隨機化)
}HashMap;//初始化哈希表
HashMap* hashmap_create();//銷毀哈希表
void hashmap_destroy(HashMap* map);//插入/更新鍵值對
ValueType hashmap_put(HashMap* map,KeyType key,ValueType val);//查詢鍵對應的值
ValueType hashmap_get(HashMap* map,KeyType key);//刪除鍵值對
bool hashmap_remove(HashMap* map,KeyType key);#endif
hash.c
#include "hash.h"//深拷貝字符串
char* strdup1(const char* s)
{size_t len = strlen(s) + 1;char* p = (char*)malloc(len);if(p)memcpy(p,s,len);return p;
}//創建哈希表
HashMap* hashmap_create()
{HashMap* map = (HashMap*)malloc(sizeof(HashMap));if(!map){printf("hashmap_create failed\n");return NULL;}map->hash_seed = (uint32_t)time(NULL);//初始化隨機種子return map;
}//銷毀哈希表(釋放所有內存)
void hashmap_destroy(HashMap* map)
{//判斷哈希表是否已經創建,如果沒有創建就直接返回,不需要釋放內存if(!map) return;for(int i = 0;i < HASHMAP_CAPACITY;i++){KeyValueNode* current = map->buckets[i];while(current){KeyValueNode* next = current->next;//保存下一個節點free(current->key);//釋放鍵free(current->value);//釋放值free(current);//釋放當前節點的內存current = next;//移動下一個節點}}free(map);//釋放哈希表本身的內存
}//哈希函數
static uint32_t hash(const char* key,uint32_t seed)
{uint32_t hash_val = 0;while(*key){hash_val = (hash_val* 31) + (uint32_t)*key++;}return (hash_val^seed) % HASHMAP_CAPACITY;
}//插入/更新鍵值對
ValueType hashmap_put(HashMap* map,KeyType key,ValueType val)
{if(!map || !key || !val) return NULL;//參數校驗uint32_t index = hash(key,map->hash_seed);//計算獲得的位置//查找鍵是否已經存在(更新值)KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){free(current->value);//防止內存泄漏current->value = strdup1(val);return current->value; // 返回更新后的值}current = current->next;}//鍵不存在,創建新節點KeyValueNode* new_node = (KeyValueNode*)malloc(sizeof(KeyValueNode));//判斷新節點是否創建成功if(!new_node){perror("Failed to allocate memory for new node"); }new_node->key = strdup1(key);new_node->value = strdup1(val);new_node->next = map->buckets[index];map->buckets[index] = new_node; // 將新節點插入到鏈表頭部}//查詢鍵對應的值
ValueType hashmap_get(HashMap* map,KeyType key)
{if(!map || !key) return NULL;uint32_t index = hash(key,map->hash_seed);//計算獲得的位置//遍歷鏈表查找鍵KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){return current->value; // 返回找到的值}current = current->next;}return NULL;
}//刪除鍵值對
bool hashmap_remove(HashMap* map,KeyType key)
{if(!map || !key) return false;uint32_t index = hash(key,map->hash_seed);KeyValueNode* current = map->buckets[index];KeyValueNode* prev = NULL;while(current){if(strcmp(current->key,key) == 0){//處理鏈表鏈接if(prev){prev->next = current->next;}else{map->buckets[index] = current->next;//刪除頭節點}//釋放內存free(current->key);free(current->value);free(current);return true;}prev = current; //記錄前一個節點current = current->next; //移動到下一個節點}return false; //未找到鍵
}main.c
#include "hash.h"int main()
{//創建哈希表HashMap* map = hashmap_create();//判斷哈希表是否創建成功if(!map){printf("create hashmap failed\n");return -1;}//插入鍵值對hashmap_put(map,"name","libai");hashmap_put(map,"age","66");hashmap_put(map,"location","changan");hashmap_put(map,"title","shixian");hashmap_put(map,"hobby","drink");//查詢鍵對應的值ValueType name = hashmap_get(map,"name");if(name){printf("name:%s\n",name);}ValueType title = hashmap_get(map,"title");if(title){printf("title:%s\n",title);}//刪除鍵值對hashmap_remove(map,"age");ValueType age = hashmap_get(map,"age");if(age == NULL){printf("age has been removed\n");}//銷毀哈希表hashmap_destroy(map);}

異常深度攻堅:從底層原理到架構級防御,老司機的實戰經驗)
 視頻教程 - 主頁-評論用戶時間占比環形餅狀圖實現)















)
