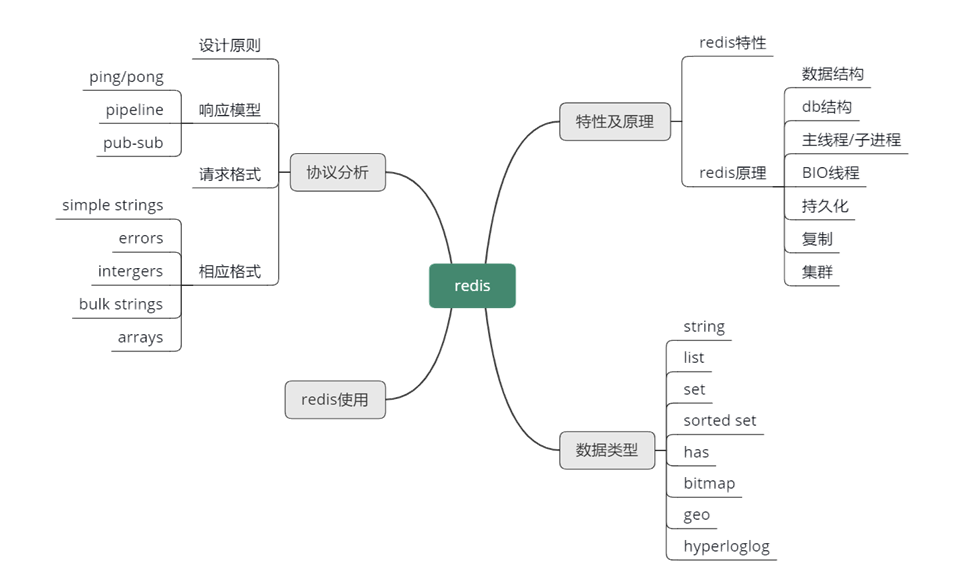
文章目錄
- 緩存全景圖
- Pre
- Redis 整體認知框架
- 一、Redis 簡介
- 二、核心特性
- 三、性能模型
- 四、持久化詳解
- 五、復制與高可用
- 六、集群與分片方案
- Redis 核心數據類型
- 概述
- 1. String
- 2. List
- 3. Set
- 4. Sorted Set(有序集合)
- 5. Hash
- 6. Bitmap
- 7. Geo
- 8. HyperLogLog
- Redis 協議分析
- 1. RESP 設計原則
- 2. 三種響應模型與特殊模式
- 3. 兩種請求格式
- 3.1 Inline 命令格式
- 3.2 Array(數組)格式
- 4. 五種響應格式詳解
- 5. 協議分類概覽
- 6. Redis Client 選型與改進建議
- Redis 的核心組件
- 一、系統架構概覽
- 二、事件處理機制
- 三、數據管理
- 四、功能擴展(Module System)
- 五、系統擴展(Replication & Cluster)
- Redis的事件驅動模型
- 一、事件驅動模型概述
- 二、文件事件處理詳解
- 2.1 Reactor 模式四部分
- 2.2 IO 多路復用的四種實現及選型邏輯
- 2.3 aeProcessEvents:事件收集與派發流程
- 2.4 三類文件事件處理函數
- 三、時間事件機制剖析
- Redis 協議解析及處理
- 一、協議解析
- 二、協議執行
- Redis 內部數據結構
- 一、RedisDb 結構
- 二、redisObject 抽象
- 三、dict 哈希表
- 四、sds 簡單動態字符串
- 五、壓縮列表(ziplist)
- 六、快速列表(quicklist)
- 七、跳躍表(zskiplist)
- 八、數據類型與內部結構映射
- Redis 淘汰策略
- 一、淘汰原理
- 二、淘汰方式
- 三、淘汰策略與 Eviction Pool
- 四、八種淘汰策略詳解
- Redis 的三種持久化方案及崩潰后數據恢復流程
- 一、RDB 持久化
- 二、AOF 持久化
- 三、混合持久化
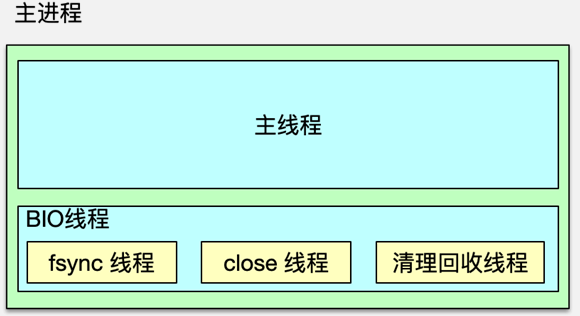
- Redis 后臺異步 IO(BIO)
- 一、BIO 線程設計動機
- 二、BIO 線程模型
- 三、BIO 任務類型
- 四、BIO 處理流程
- Redis 多線程架構
- 一、主線程職責
- 二、IO 線程設計
- 三、命令處理完整流程
- 四、多線程方案優劣
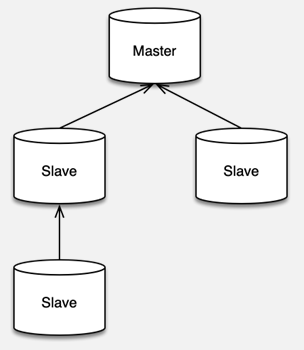
- 復制架構原理
- 一、復制架構原理
- 二、同步方式對比
- 三、psync 與 psync2 優化
- 四、復制連接與授權流程
- 五、復制過程詳析
- 5.1 增量同步流程
- 5.2 全量同步流程
- 六、注意事項
- Redis 集群的分布式方案
- 1. Client 端分區
- 1.1 原理與哈希算法
- 1.2 DNS 動態管理
- 1.3 優缺點
- 2. Proxy 分區方案
- 2.1 架構概覽
- 2.2 典型實現
- 2.3 優缺點
- 3. 原生 Redis Cluster
- 3.1 Slot 與 Gossip 架構
- 3.2 讀寫與重定向
- 3.3 在線擴縮容與數據遷移
- 3.4 優缺點
- 4. 對比與選型建議

緩存全景圖
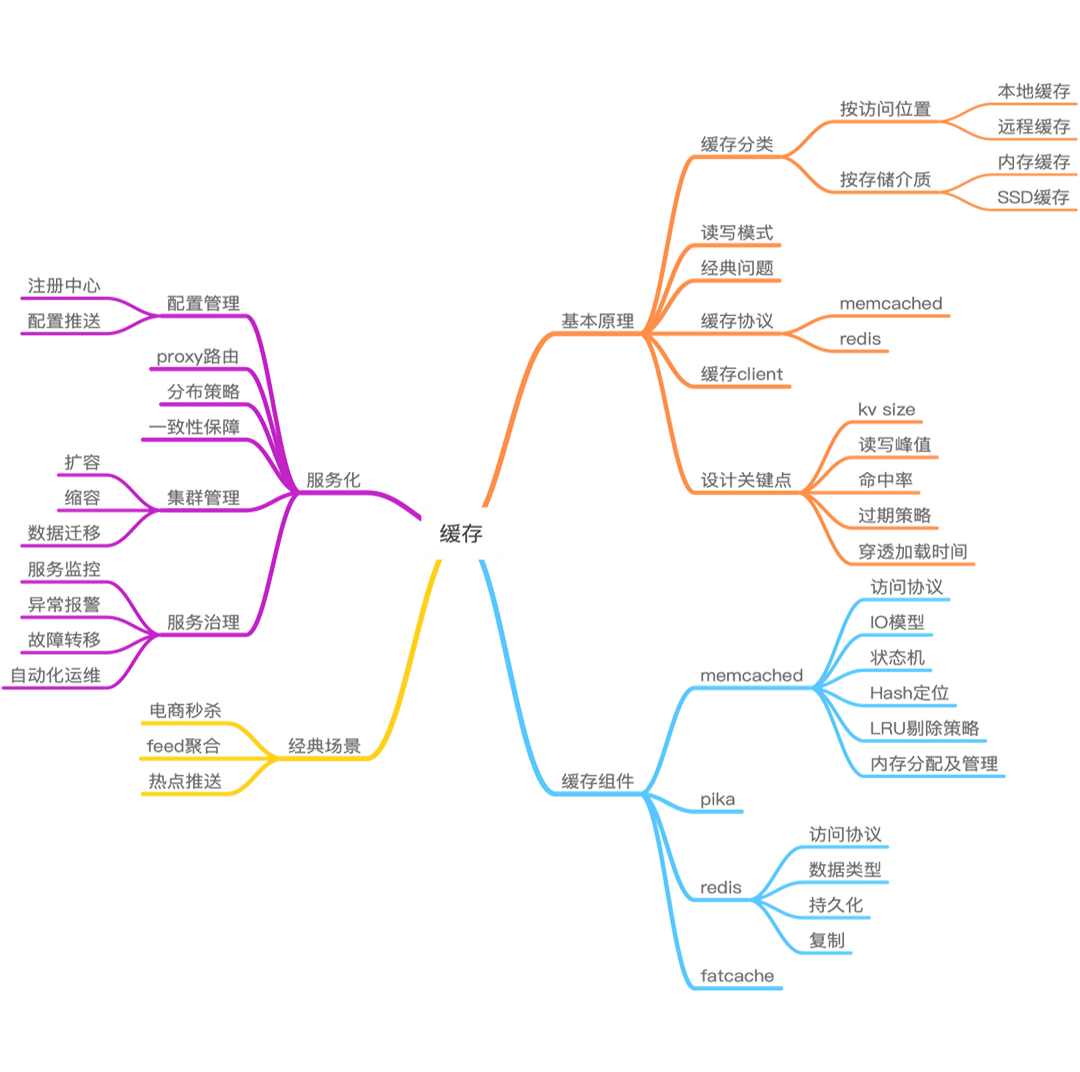
Pre
分布式緩存:緩存設計三大核心思想
分布式緩存:緩存的三種讀寫模式及分類
分布式緩存:緩存架構設計的“四步走”方法
分布式緩存:緩存設計中的 7 大經典問題_緩存失效、緩存穿透、緩存雪崩
分布式緩存:緩存設計中的 7 大經典問題_數據不一致與數據并發競爭
分布式緩存:緩存設計中的 7 大經典問題_Hot Key和Big Key
Redis 整體認知框架
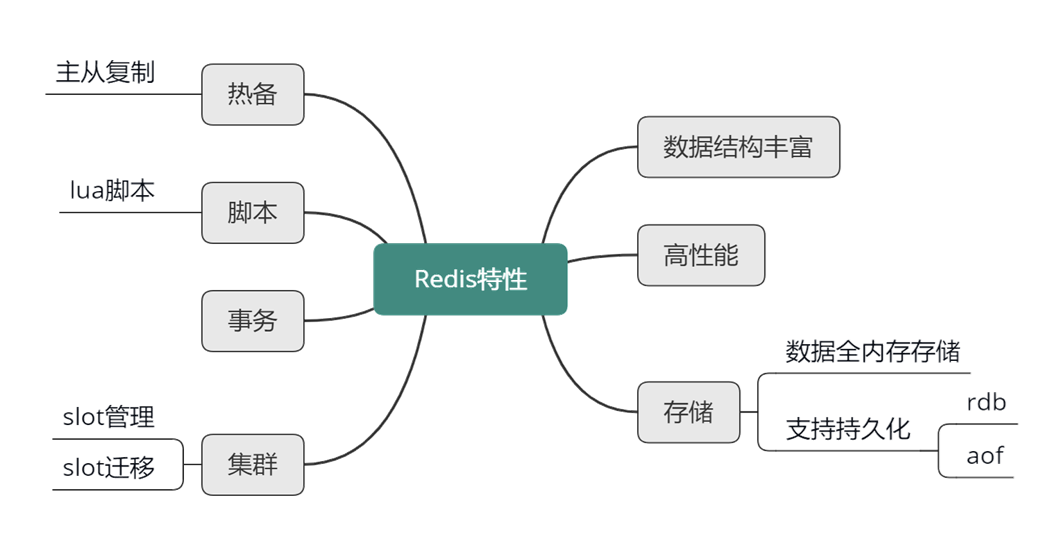
一、Redis 簡介
- 實現與授權:Redis 基于 ANSI C 語言編寫,采用 BSD 許可,代碼輕量、易于嵌入。
- 內存存儲:所有數據均保存在內存中,因此具有極低的讀寫延遲,可做緩存、數據庫、消息中間件等多種角色。
- 多庫支持:Redis 即 Remote Dictionary Server,實例內部維護多個邏輯數據庫(默認為 16 個),通過
SELECT命令切換操作目標。
二、核心特性
-
豐富的數據類型:除基本的字符串(String)外,Redis 還原生支持
List、Set、Sorted Set(ZSet)、Hash;以及Bitmap、HyperLogLog、Geo等特殊結構,一機多用。 -
雙重持久化:
- RDB 快照:定時或達到修改閾值時,將內存全量快照寫入
.rdb文件,適合冷備份; - AOF 追加:將每條寫命令追加到
.aof文件,可配置同步頻率,保障最小數據丟失。
線上系統常用“RDB+ AOF 混合”策略:平時頻繁追加 AOF,低峰期觸發BGSAVE生成新快照;遇到 AOF 文件過大時,用BGREWRITEAOF重寫精簡。
- RDB 快照:定時或達到修改閾值時,將內存全量快照寫入
-
讀寫分離:一主多從架構,將寫請求指向 Master,讀請求分發至多個 Slave,顯著提高讀吞吐。
-
Lua 腳本與事務:
- Lua 腳本:從 Redis 2.6 起支持,腳本內多命令打包,可實現原子性操作并減少網絡往返;
- 事務:通過
MULTI/EXEC打包命令,確保命令序列原子執行,中途出錯則全部丟棄。
-
集群支持:Redis Cluster 原生實現分布式,基于 Slot 哈希機制,無中心節點,實現自動擴縮容與故障轉移。
三、性能模型
-
單線程+事件驅動:網絡 IO 與命令處理均在主線程中完成,基于 epoll(或 kqueue、evport)無阻塞多路復用,避免鎖競爭與上下文切換。
-
高 QPS:單實例可輕松突破 100k QPS,得益于純內存操作與無鎖設計。
-
后臺子進程/線程:
-
BGSAVE/BGREWRITEAOF/全量復制:主進程遇到重負荷持久化或復制任務時,fork 子進程執 行,主進程繼續提供服務;
-
BIO 線程池:三個后臺線程負責文件關閉、AOF 緩沖刷盤、對象釋放,進一步減輕主線程壓力。
-
四、持久化詳解
- RDB:快速生成緊湊快照,恢復速度快;適合冷備份,但數據持久性依賴觸發頻率。
- AOF:按命令追加,能做到每秒或每次寫入同步,重放日志恢復更完整;但文件體積隨命令量增長,需定期重寫。
- 混合策略:推薦生產環境開啟 AOF 并定期重寫,同時在低峰期執行 RDB 快照,以兼顧恢復速度與數據完整性。
五、復制與高可用
- 全量同步:Slave 首次連接或復制緩沖不足時,Master fork 子進程生成 RDB 快照并傳輸,Slave 接收后加載;
- 增量復制:Slave 重連且累積命令量在緩沖區可承載范圍內時,僅傳輸缺失命令,降低復制開銷。
- 故障切換:當 Master 宕機,可手動或通過哨兵(Sentinel)將任意 Slave 提升為 Master,保障業務連續性。
六、集群與分片方案
- Client 分片:客戶端根據一致性哈希或取模自行路由到不同實例,簡單但擴縮容麻煩;
- Proxy 層:如 Twemproxy,在前端做路由與健康檢查,后端實際節點變動只需更新 Proxy 配置;
- Redis Cluster:官方原生集群,使用 16384 個 Slot 管理鍵空間,支持在線遷移、故障轉移與自動均衡。
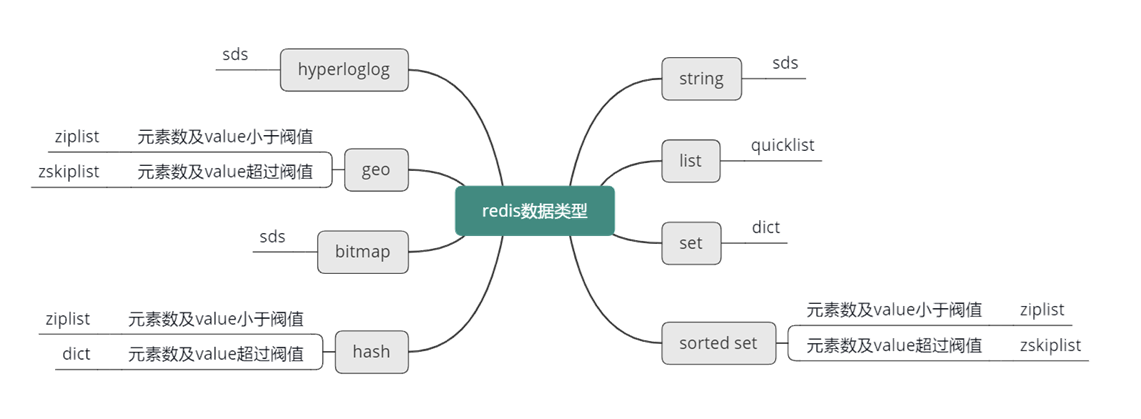
Redis 核心數據類型
概述
Redis 共支持以下 及 種核心數據類型:
- String:二進制安全的字符串類型
- List:按插入順序排列的雙向鏈表
- Set:無序且元素唯一的集合
- Sorted Set(ZSet):帶分值的有序集合
- Hash:字段–值映射表
- Bitmap:基于 String 的位圖封裝
- Geo:地理位置類型,基于 ZSet 實現
- HyperLogLog:基數統計的近似算法
- …
1. String
-
存儲方式:
- 小于 1 MB 時,采用
raw encoding,預分配兩倍長度來減少頻繁擴容; - 超過 1 MB 時,每次額外預分配 1 MB。
- 小于 1 MB 時,采用
-
整型編碼:對于純數字字符串,使用整型編碼,以節省內存并加速算術運算。
-
常用指令:
SET、GET、MSET、INCR、DECR等。 -
典型場景:
-
緩存普通文本、序列化對象;
-
計數器(PV、UV、限流);
-
分布式鎖的簡單實現。
SET user:1001:token "abcd1234" INCR page:views
-
2. List
-
底層實現:快速雙向鏈表,支持頭尾 O(1) 插入/彈出。
-
指令摘要:
- 插入:
LPUSH、RPUSH、LINSERT - 彈出:
LPOP、RPOP、阻塞式BLPOP、BRPOP - 范圍查詢:
LRANGE(支持負索引)
- 插入:
-
時間復雜度:對頭/尾操作為 O(1),隨機訪問或插入為 O(N)。
-
典型場景:
-
消息隊列(工作隊列、發布/訂閱前端緩沖);
-
Feed Timeline(用戶動態按時間順序追加);
-
簡易棧/隊列。
RPUSH queue:tasks task1 task2 BLPOP queue:tasks 0 # 阻塞直到有新任務 LRANGE queue:tasks 0 9 # 獲取前 10 個元素
-
3. Set
-
底層實現:哈希表,保證元素唯一且無序。
-
指令摘要:
SADD、SREM、SISMEMBER、SDIFF、SINTER、SUNION、SPOP、SRANDMEMBER。 -
時間復雜度:插入、刪除、查找均為 O(1)。
-
典型場景:
-
好友關注列表、互關判斷;
-
推薦系統中的離線/在線標簽去重;
-
來源 IP 白名單/黑名單。
SADD user:1001:friends 1002 1003 SISMEMBER user:1001:friends 1003 # 返回 1
-
4. Sorted Set(有序集合)
-
底層實現:跳表 + 哈希,按分值升序排列。
-
指令摘要:
ZADD、ZREM、ZSCORE、ZRANGE、ZINCRBY、ZINTERSTORE、ZUNIONSTORE。 -
特點:元素唯一,分值可重復;快速算分與排名。
-
典型場景:
-
實時排行榜(游戲分數、熱度榜單);
-
按權重排序的數據展示;
-
定時任務系統(利用分值表示時間戳)。
ZADD leaderboard 100 user:1001 ZRANGE leaderboard 0 9 WITHSCORES # TOP10
-
5. Hash
-
底層實現:field–value 映射,內部也是哈希表。
-
指令摘要:
HSET/HMSET、HGET/HMGET、HEXISTS、HINCRBY、HGETALL。 -
時間復雜度:單 field 操作為 O(1)。
-
典型場景:
-
存儲對象屬性,如用戶資料、商品信息;
-
實現類似關系型數據庫表的一行;
-
業務統計字段聚合。
HMSET user:1001 name "Alice" age 30 HINCRBY user:1001:stats login_count 1
-
6. Bitmap
-
底層實現:基于 String 的位操作。
-
指令摘要:
SETBIT、GETBIT、BITCOUNT、BITOP、BITFIELD、BITPOS。 -
特點:按位存儲,內存占用極低;位運算高效。
-
典型場景:
-
用戶活躍打卡(N 天登錄);
-
標簽屬性存儲與多維統計;
-
簡易布隆過濾器原型。
SETBIT login:20250525 1001 1 BITCOUNT login:20250525 # 當天活躍用戶數
-
7. Geo
-
底層實現:封裝于 Sorted Set,通過 GeoHash 將經緯度映射為分值。
-
指令摘要:
GEOADD、GEOPOS、GEODIST、GEORADIUS、GEORADIUSBYMEMBER。 -
特點:支持范圍查詢與距離計算。
-
典型場景:
-
附近的人/店鋪/車輛搜索;
-
地理圍欄告警;
-
實時位置服務(LBS)。
GEOADD restaurants 116.397128 39.916527 "PekingDuck" GEORADIUS restaurants 116.40 39.92 5 km WITHDIST
-
8. HyperLogLog
-
底層實現:近似基數統計算法,稀疏與稠密兩種存儲,自適應切換。
-
指令摘要:
PFADD、PFCOUNT、PFMERGE。 -
特點:固定 ≈12KB 內存;誤差率 ≈0.81%。
-
典型場景:
-
大規模 UV 統計;
-
海量搜索詞匯去重;
-
日志中的獨立源 IP 計數。
PFADD uv:202505 user:1001 user:1002 PFCOUNT uv:202505 # 當月獨立訪客數(近似)
-
Redis 協議分析
1. RESP 設計原則
Redis 序列化協議 RESP 的設計堅持三條原則:
- 實現簡單:協議格式直觀,便于不同語言的客戶端快速實現。
- 可快速解析:結構清晰、前綴標記,使得解析器能夠以最低開銷完成讀寫。
- 便于閱讀:即便用 Telnet 交互,也能通過簡單的符號輕松定位請求與響應邊界。
2. 三種響應模型與特殊模式
Redis 默認使用“Ping-Pong”模型:客戶端發起一個請求,服務端立即返回一個響應,實現一問一答。
此外還有兩種特殊模式:
- Pipeline 模式:客戶端一次性發送多條命令,不等待中間響應,待全部發送完后再按序接收服務端響應,減少網絡往返。
- Pub/Sub 模式:客戶端通過
SUBSCRIBE進入訂閱狀態,此后無需再次發起請求,即可持續接收服務端基于頻道推送的消息;除訂閱相關命令,其他命令均失效。
3. 兩種請求格式
3.1 Inline 命令格式
適用于交互式會話(如 Telnet),命令與參數以空格分隔,結尾以 \r\n:
mget key1 key2\r\n
3.2 Array(數組)格式
更規范的二進制安全格式,也是生產環境客戶端默認使用:
*3\r\n$4\r\nMGET\r\n$4\r\nkey1\r\n$4\r\nkey2\r\n
其中 *3 表示數組長度為 3,每個元素前以 $<字節數> 聲明。
4. 五種響應格式詳解
Redis 響應客戶端請求時,基于 RESP 定義了 5 類格式:
-
Simple String(簡單字符串)
- 前綴
+,不可包含\r或\n,以\r\n結束。 - 用于返回 OK、PONG 等簡短狀態。
+OK\r\n - 前綴
-
Error(錯誤)
- 前綴
-,后跟錯誤類型(ERR/WRONGTYPE 等)及描述,以\r\n結束。
-ERR unknown command 'foo'\r\n - 前綴
-
Integer(整數)
- 前綴
:,后跟整數字符串,以\r\n結束。 - 代表計數、長度或布爾(0/1)等。
:1000\r\n - 前綴
-
Bulk String(字符串塊)
- 前綴
$,后跟內容字節長度,再\r\n;隨后是真實內容,再\r\n。 - 支持二進制安全,最大可達 512MB。
$6\r\nfoobar\r\n- 空字符串:
$0\r\n\r\n;NULL:$-1\r\n。
- 前綴
-
Array(數組)
- 前綴
*,后跟元素個數,再\r\n;隨后依次是各元素(可嵌套上述任何格式)。
*2\r\n$3\r\nGET\r\n$3\r\nkey\r\n- 空數組:
*0\r\n;NULL 數組:*-1\r\n。
- 前綴
5. 協議分類概覽
除了與 8 種數據結構直接對應的命令協議,Redis 還定義了以下 8 類協議:
- Pub/Sub 協議:
SUBSCRIBE/PUBLISH - 事務協議:
MULTI/EXEC/DISCARD - 腳本協議:
EVAL/EVALSHA/SCRIPT - 連接協議:
AUTH/SELECT/QUIT - 復制協議:
REPLICAOF/PSYNC/ROLE - 配置協議:
CONFIG GET/CONFIG SET - 調試統計協議:
INFO/MONITOR/SLOWLOG - 內部命令:
MIGRATE/DUMP/RESTORE
6. Redis Client 選型與改進建議
以 Java 為例,目前主流客戶端有:
- Jedis:輕量、直觀,支持連接池,幾乎覆蓋所有命令,但原生不支持讀寫分離。
- Redisson:基于 Netty 的非阻塞 IO,支持異步調用、讀寫分離、負載均衡及 Spring Session 集成,但實現較為復雜。
- Lettuce:也是基于 Netty,完全非阻塞、線程安全,可在多線程環境中共享同一連接;提供同步、異步(Future)、響應式(Reactive Streams)和 RxJava 風格的多種調用方式;原生支持 Redis Cluster、Sentinel、讀寫分離,自動故障轉移;客戶端實現簡潔,依賴少,適合高并發、低延遲場景。
改進建議:
- 在異常訪問時實現重試與熔斷;
- 動態感知主從切換,自動調整連接;
- 多 Slave 場景下添加負載均衡策略;
- 與配置中心和集群管理平臺集成,實現實時路由和高可用。
Redis 的核心組件
一、系統架構概覽
Redis 的核心組件主要包括以下四大模塊:
- 事件處理(Event Loop):基于作者開發的
ae事件驅動模型,實現高效網絡 IO 和定時任務調度 - 數據存儲與管理:內存數據庫
redisDB,支持多庫、多數據類型、多底層結構 - 功能擴展(Module System):可插拔模塊化設計,無需改動核心即可引入新數據類型與命令
- 系統擴展(Replication & Cluster):主從復制與 Cluster 分片,滿足高可用與橫向擴容需求
二、事件處理機制
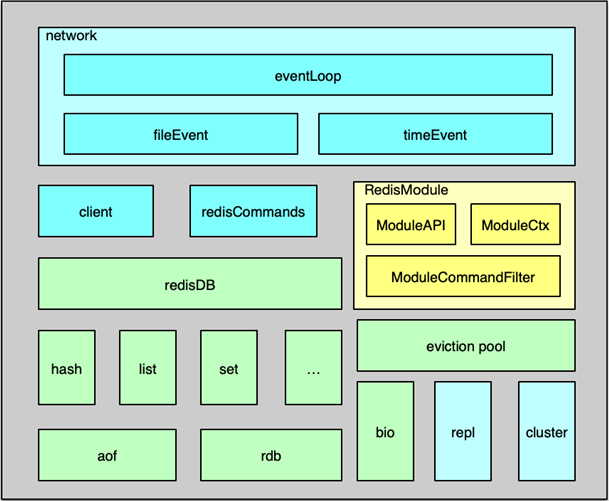
-
ae事件驅動模型概述- 封裝
select/epoll/kqueue/evport,實現 IO 多路復用 - 監聽多個 socket,把網絡讀寫、命令執行、定時任務整合到同一個循環
- 封裝
-
客戶端連接管理
- 收到新連接時,創建
client結構體,維護狀態、讀寫緩沖 - 請求到達后將命令讀取到緩沖區,并解析成參數列表
- 收到新連接時,創建
-
命令處理流程
- 根據命令名稱映射到
redisCommand - 對參數進行進一步解析與校驗
- 執行命令對應的處理函數
- 根據命令名稱映射到
-
時間事件(Time Events)
- 周期性執行
serverCron:包括統計更新、過期鍵清理、AOF/RDB 持久化觸發等
- 周期性執行
三、數據管理
-
內存數據庫結構
- 每個邏輯庫對應一個
redisDB結構,內部通過dict存儲 key/value - 八種數據類型(String、List、Set、Hash、ZSet、Stream、Bitmap、HyperLogLog)各自采用一或多種底層結構
- 每個邏輯庫對應一個
-
持久化策略
- AOF(Append Only File):將每次寫操作追加到緩沖,按策略刷盤
- RDB(Redis DataBase Snapshot):定期將全量數據快照落地,生成緊湊的二進制文件
-
線程模型與非阻塞
- 核心線程為單線程,避免任何內核阻塞
- BIO 線程池:專門處理可能阻塞的文件 close、fsync 等操作,保證主線程性能
-
內存淘汰與過期
- 過期鍵及時清理,空閑掃描或惰性刪除相結合
- 八種淘汰策略(如 LRU、LFU、TTL 優先等),結合
eviction pool高效回收內存
四、功能擴展(Module System)
-
模塊加載:動態鏈接庫,可在啟動時或運行時加載/卸載
-
API 接口:
RedisModule_Init:初始化模塊RedisModule_CreateCommand:注冊新命令
-
應用場景:自定義數據結構、高級功能(例如圖數據庫、機器學習推理)
五、系統擴展(Replication & Cluster)
-
主從復制(Replication)
- 支持全量同步與增量復制
- Slave 重連、主從切換后均可繼續增量復制,提升可用性
- 讀寫分離:將讀請求分攤到多個節點,減輕主節點負載
-
分片集群(Cluster)
- 16384 個 slot,按 Hash 分布到不同節點
- 客戶端計算 slot,根據 slot 定位節點
- 錯誤節點自動重定向(MOVED/ASK)
- 在線擴容:通過遷移 slot 實現節點增減
Redis的事件驅動模型
一、事件驅動模型概述
Redis 作為一個高性能的內存數據庫,充分利用事件驅動模式來處理幾乎所有核心操作。與 Memcached 依賴 libevent/ libev 不同,Redis 作者從零開始,開發了自研的事件循環組件,封裝在 aeEventLoop 及相關結構體中。這樣做的動機是:
- 最小化外部依賴:減少因第三方庫升級或兼容性帶來的不確定性;
- 輕量可控:自研實現更契合 Redis 的業務場景,代碼更簡潔,性能更容易優化;
- 靈活擴展:可在事件模型中無縫接入文件事件與時間事件的統一調度。
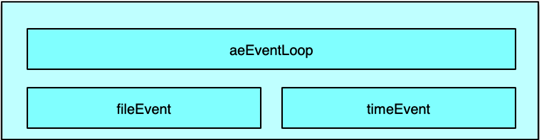
Redis 的事件驅動模型主要處理兩類事件:
- 文件事件:與 socket 讀寫、連接建立/關閉直接相關的 IO 事件;
- 時間事件:周期性或單次需要在指定時間點執行的任務,例如定期統計、Key 淘汰、緩沖寫出等。
二、文件事件處理詳解
Redis 在文件事件處理上采用經典的Reactor 模式,將整個流程拆分為四部分:連接 socket、IO 多路復用、文件事件分派器與事件處理器。
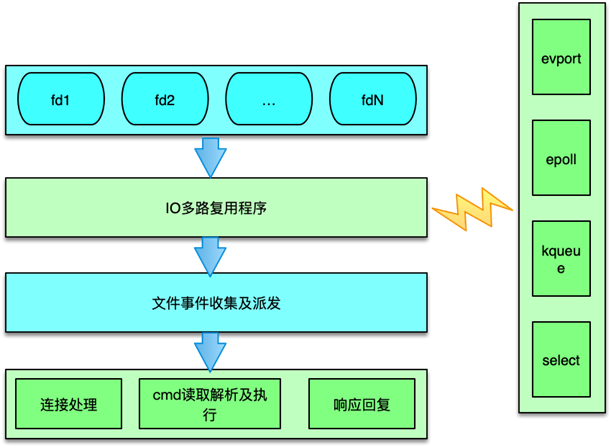
2.1 Reactor 模式四部分
- 連接 Socket:監聽客戶端連接的 TCP 端口與已建立連接的客戶端 Socket;
- IO 多路復用:通過底層操作系統接口同時監控多個描述符的可讀寫狀態;
- 文件事件分派器:調用
aeProcessEvents,從多路復用層獲取觸發的事件; - 事件處理器:根據事件類型(可讀/可寫)調用注冊好的回調函數執行實際邏輯。
2.2 IO 多路復用的四種實現及選型邏輯
Redis 封裝了四種主流的多路復用方案,編譯時按優先級自動選擇:
- evport(Solaris 專有)
- epoll(Linux 最佳選擇)
- kqueue(大多數 BSD 系統)
- select(通用但性能最低)
前三者直接調用內核機制,能同時服務數十萬文件描述符;select 則每次需掃描全部描述符,時間復雜度 O(n),且受描述符數量上限(默認 1024/2048)限制,不適合線上高并發場景。對應實現分布在 ae_evport.c、ae_epoll.c、ae_kqueue.c、ae_select.c 四個代碼文件中。
2.3 aeProcessEvents:事件收集與派發流程
aeProcessEvents 是 Redis 文件事件的核心分派器,執行流程大致如下:
- 計算下一次阻塞等待的超時時間(兼顧時間事件);
- 調用
aeApiPoll(內置封裝)阻塞或非阻塞等待文件事件; - 收集觸發的事件,將它們封裝到
aeFiredEvents數組中,每項記錄文件描述符與事件類型; - 將底層事件類型(如 EPOLLIN/EPOLLOUT/EPOLLERR)映射為 Redis 事件標志(AE_READABLE/AE_WRITABLE);
- 依次遍歷
aeFiredEvents,先讀后寫地 dispatch 到注冊在aeEventLoop中的具體事件處理器。
2.4 三類文件事件處理函數
Redis 對文件事件的注冊與處理主要分為:
-
連接處理:
acceptTcpHandler- 在
initServer階段注冊監聽 socket 的讀事件; - 有新連接時,接受連接、創建
client結構,獲取遠端 IP/端口; - 單次循環最多處理 1000 個新連接請求;
- 在
-
請求讀取:
readQueryFromClient- 為每個 client socket 注冊讀事件;
- 讀取客戶端發來的命令數據,填充到
client->query_buf; - 按 inline 或 multibulk 格式解析命令,校驗參數及當前實例狀態后,執行對應的
redisCommand; - 將執行結果寫入
client->reply_buf;
-
回復發送:
sendReplyToClient- 在命令執行完將結果放入寫緩沖后,注冊寫事件;
- 當 socket 可寫時,將緩沖區數據發送給客戶端。
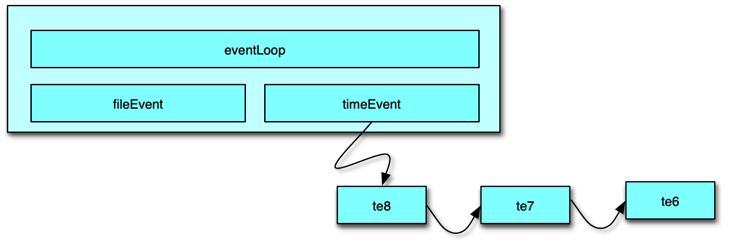
三、時間事件機制剖析
與文件事件并行,Redis 的時間事件在同一個 aeEventLoop 內作為鏈表管理。每個時間事件包含五個核心屬性:
- 事件 ID:全局唯一自增;
- 執行時間:
when_sec與when_ms,精確到毫秒; - 處理器:
timeProc函數指針; - 關聯數據:
clientData傳遞給處理器使用; - 雙向鏈表指針:
prev、next,便于插入與遍歷。
時間事件分為:
- 單次事件:執行一次后即標記刪除;
- 周期事件:執行后更新下一次執行時間,保持循環。
在 aeProcessEvents 中,文件事件處理前后都會遍歷一次時間事件鏈表,執行所有到期的事件:
- 逐一比較事件時間與當前時鐘;
- 對可執行事件調用
timeProc(clientData); - 若周期事件,更新
when_sec/when_ms;若單次事件,標記id=-1,下一輪清除。
Redis 默認主要的時間事件包括:
serverCron:定期執行統計、淘汰、維護緩沖等任務;moduleTimerHandler:模塊化擴展的定時回調。
Redis 協議解析及處理
當事件循環檢測到客戶端有請求到來時,Redis 如何從網絡讀入原始數據、解析成命令與參數,最終執行并返回結果。
一、協議解析
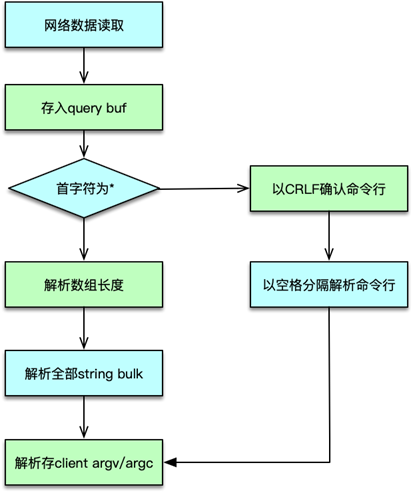
-
讀取請求到 Query Buffer
- 當 socket 可讀事件觸發,Redis 會調用
readQueryFromClient,從客戶端連接的文件描述符讀取數據到client->querybuf。 - 默認讀緩沖大小為 16 KB;若單次請求長度超過 1 GB,Redis 會報錯并關閉連接,防止惡意或異常請求耗盡內存。
- 當 socket 可讀事件觸發,Redis 會調用
-
判斷協議類型:MULTIBULK vs INLINE
-
MULTIBULK(以
*開頭)-
首字節為
*,表示后續是一個塊數組。格式為:*<參數個數>\r\n $<第1個參數字節數>\r\n <參數1內容>\r\n … -
逐行讀取,根據
$指示讀取固定長度數據,直到完整填充所有參數。
-
-
INLINE(單行字符串)
-
首字節非
*,整個請求以\r\n結尾。命令和參數用空格分隔:set mykey hello\r\n -
Redis 會將整行切分,再按空格拆分命令及參數。
-
-
-
填充
client->argc與client->argv- 解析結束后,將參數個數寫入
client->argc。 - 對于每個參數,創建一個
robj(Redis 對象),存入client->argv數組,以便后續命令執行使用。
- 解析結束后,將參數個數寫入
二、協議執行
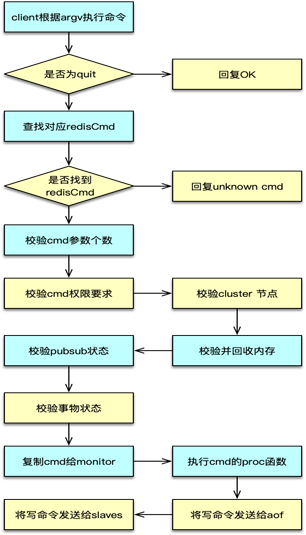
Redis 協議解析及處理
-
處理特殊命令:
QUIT- 若
argv[0]為quit,Redis 直接返回+OK\r\n并將CLIENT_CLOSE_AFTER_REPLY標記置位,表示回復后關閉連接。
- 若
-
查找并執行命令
-
使用
lookupCommand在全局命令表(server.commands)中查找argv[0]對應的redisCommand結構。 -
若找不到,則調用
addReplyErrorFormat(c,"ERR unknown command '%s'",c->argv[0]->ptr),向客戶端返回未知命令錯誤。 -
找到后,進入命令執行階段:
c->cmd = cmd; c->cmd->proc(c);proc是命令對應的函數指針,如setCommand、getCommand等。
-
-
寫入響應與副作用
-
命令執行完成后,依照命令邏輯通過
addReply*系列函數將響應數據寫入client->buf(寫緩沖區)。 -
若該命令為寫操作,且開啟了 AOF 或者當前角色為主節點,還需將寫命令推送給 AOF 線程與所有從節點:
- 調用
feedAppendOnlyFile(c, ...); - 調用
replicationFeedSlaves(c, ...);
- 調用
-
同時,更新命令統計,如
server.stat_numcommands++。
-
Redis 內部數據結構
Redis 的內存數據結構層——Redis 如何在內存中組織和管理各種對象,才能在單線程模型下實現高性能與高擴展性。
一、RedisDb 結構
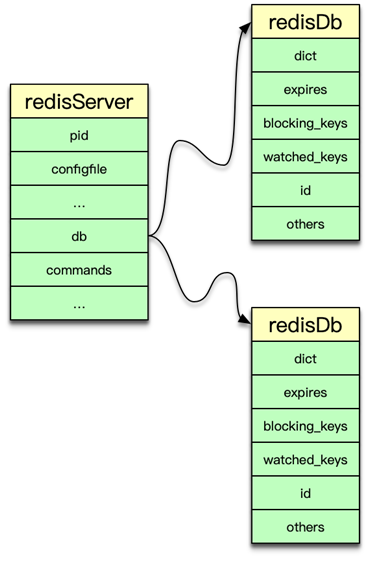
-
多庫支持:每個實例默認可配置 16 個邏輯庫(
db0~db15),通過命令SELECT $dbID切換。 -
核心字典
dict(主字典):存儲 key → value 映射expires:存儲 key → 過期時間
-
非核心字典
blocking_keys:記錄 BLPOP/BRPOP 等阻塞列表的 key → client 列表ready_keys:當元素入隊觸發喚醒時,將 key 加入此字典與全局server.read_keys列表中watched_keys:用于事務 WATCH 監控的 key → client 列表
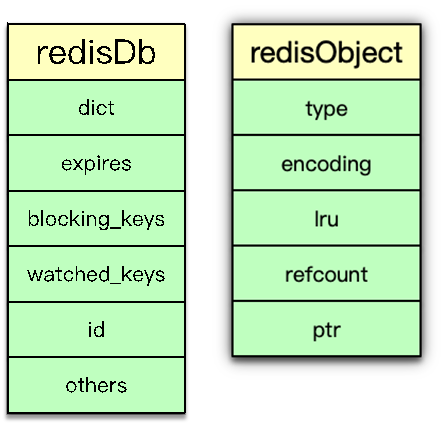
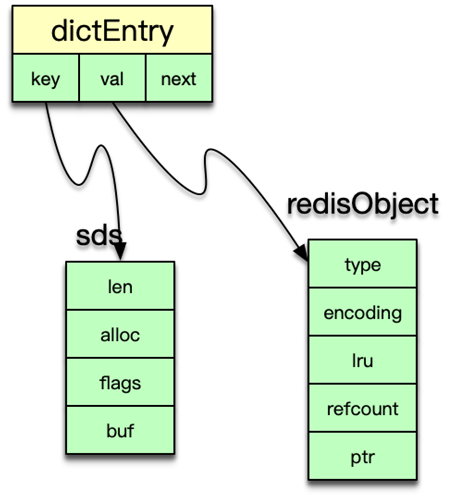
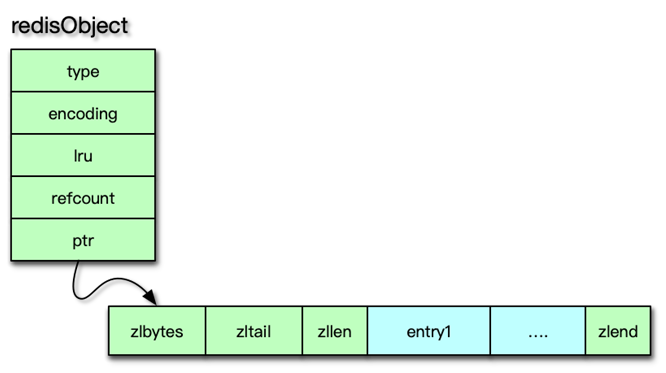
二、redisObject 抽象
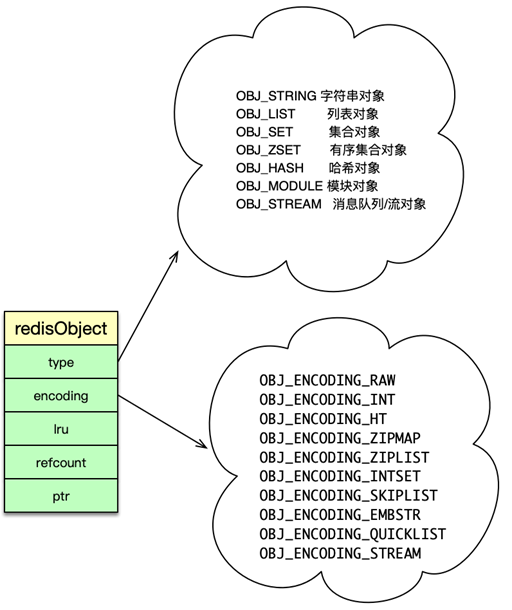
Redis 中任何存儲的值都封裝為 redisObject,包含五個核心字段:
- type:對象類型(
OBJ_STRING、OBJ_LIST、OBJ_SET、OBJ_ZSET、OBJ_HASH、OBJ_MODULE、OBJ_STREAM) - encoding:底層編碼(如
RAW、INT、HT、ZIPLIST等) - LRU:用于 LRU/LFU 淘汰策略的訪問記錄
- refcount:引用計數,支持對象共享與內存自動回收
- ptr:指向具體底層數據結構(如
sds、dict、ziplist、quicklist、zskiplist等)
三、dict 哈希表
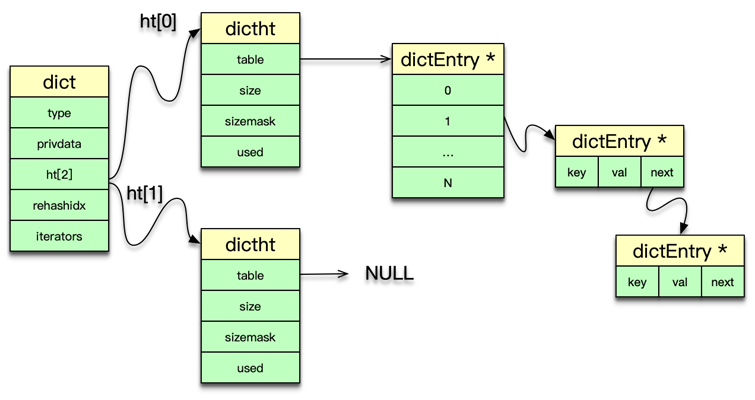
-
雙表設計:
dict結構內維護長度為 2 的哈希表數組ht[0]、ht[1] -
漸進式 rehash
- 當
ht[0]裝載因子超閾值,分配ht[1](容量為ht[0]的兩倍) - 每次哈希操作順帶遷移部分桶,使用
rehashidx記錄遷移進度
- 當
-
沖突解決:每個桶為
dictEntry的單向鏈表
-
靈活可擴展:
dict可用于主字典、過期字典,也可作為 Set、Hash 類型的內部存儲
四、sds 簡單動態字符串
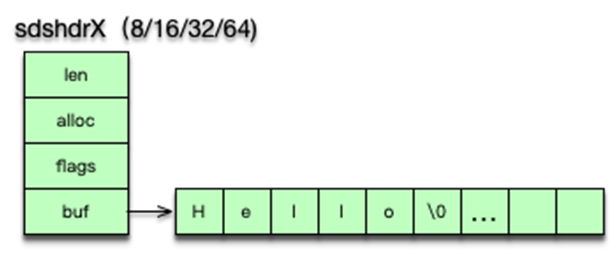
-
基本結構:底層為
sdshdr+char buf[]len:當前字符串長度alloc:已分配空間大小flags:類型與子類型標志buf:字符數據(二進制安全,允許包含\0)
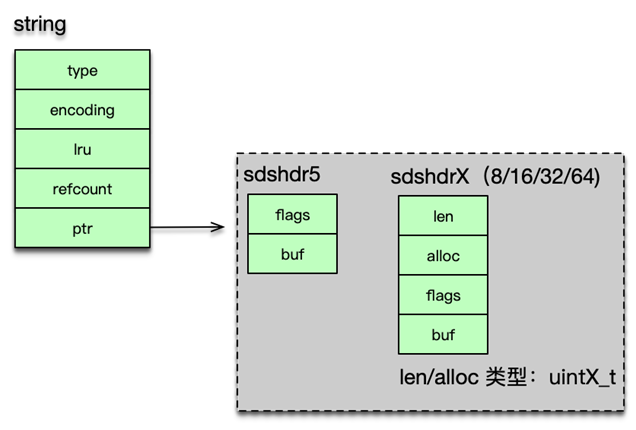
-
多種子類型(從 Redis 3.2 起)
sdshdr5:極短字符串,僅flags+bufsdshdr8/16/32/64:根據長度選擇合適的整型字段,節省內存
-
優勢
- O(1) 獲取長度,無需遍歷
- 動態擴展與收縮,二進制安全
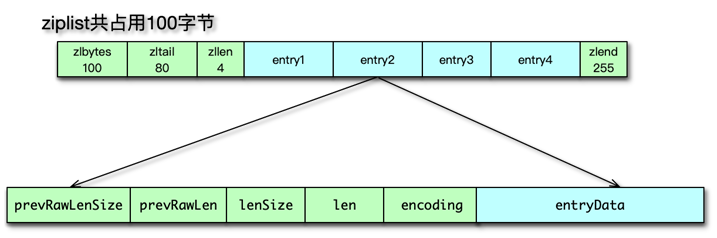
五、壓縮列表(ziplist)
為了節約內存,并減少內存碎片,Redis 設計了 ziplist 壓縮列表內部數據結構。壓縮列表是一塊連續的內存空間,可以連續存儲多個元素,沒有冗余空間,是一種連續內存數據塊組成的順序型內存結構。
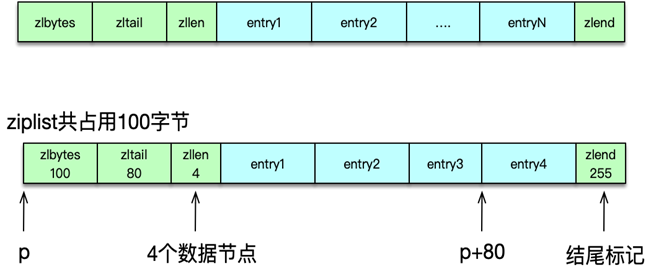
-
連續內存布局,減少指針開銷與碎片
-
結構字段
zlbytes:總字節數zltail:尾節點距起始偏移zllen:節點數量entry…entry…:各節點數據zlend:結束標志(255)
-
節點格式
- 前驅長度、編碼長度、實際數據長度、編碼類型、數據
-
適用場景
- 小型 Hash(默認 ≤512 項、值 ≤64B)
- 小型 ZSet(默認 ≤128 項、值 ≤64B)
六、快速列表(quicklist)
Redis 在 3.2 版本之后引入 quicklist,用以替換 linkedlist。因為 linkedlist 每個節點有前后指針,要占用 16 字節,而且每個節點獨立分配內存,很容易加劇內存的碎片化。而 ziplist 由于緊湊型存儲,增加元素需要 realloc,刪除元素需要內存拷貝,天然不適合元素太多、value 太大的存儲。
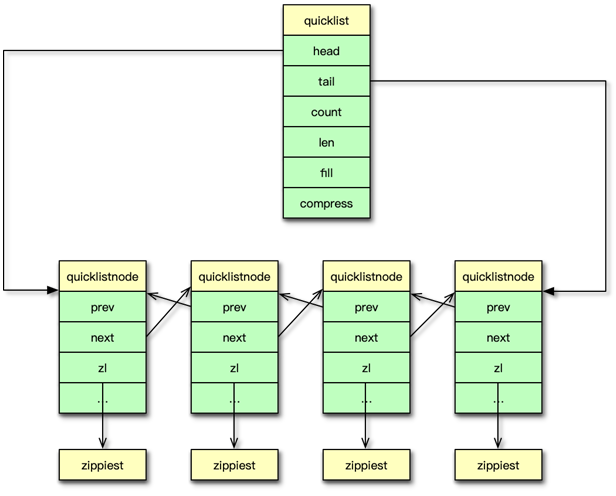
-
設計目標:結合 ziplist 的緊湊與 linkedlist 的靈活
-
結構
- 雙向鏈表節點
quicklistNode,每節點包含一個 ziplist head、tail指針;count(總元素數);len(節點數);compress(LZF 壓縮深度)
- 雙向鏈表節點
-
優點
- 頭尾操作 O(1)
- 避免過多內存碎片
- 支持中間位置操作(O(n))
七、跳躍表(zskiplist)
跳躍表 zskiplist 是一種有序數據結構,它通過在每個節點維持多個指向其他節點的指針,從而可以加速訪問。跳躍表支持平均 O(logN) 和最差 O(n) 復雜度的節點查找。在大部分場景,跳躍表的效率和平衡樹接近,但跳躍表的實現比平衡樹要簡單,所以不少程序都用跳躍表來替換平衡樹。
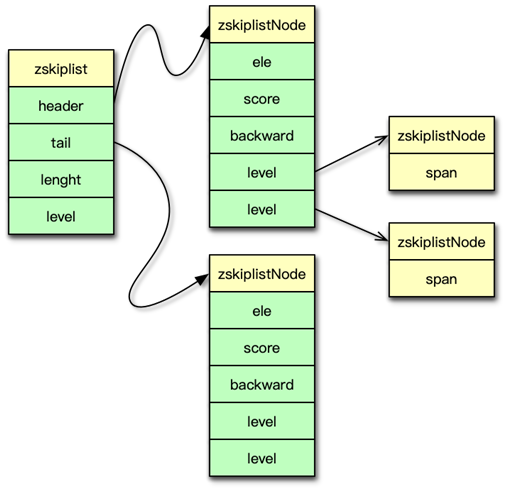
-
多級索引:在每個節點維護多層前進指針與跨度,近似平衡樹性能
-
結構
zskiplist:header、tail、length、levelzskiplistNode:ele(sds)、score、backward、多級level[i](forward+span)
-
性能
- 平均 O(log N) 查找/插入/刪除
- 同分數元素按字典序排序
-
適用場景
- 大型 Sorted Set、Geo 類型(超出 ziplist 閾值)
八、數據類型與內部結構映射
| 數據類型 | 內部存儲結構 |
|---|---|
| String | sds / 整數對象 |
| List | quicklist |
| Set | dict |
| Hash | ziplist(小型)/ dict(大型) |
| Sorted Set | ziplist(小型)/ zskiplist(大型) |
| Stream | radix tree + listpacks |
| HyperLogLog | sds |
| Bitmap | sds |
| Geo | ziplist(小型)/ zskiplist(大型) |
Redis 淘汰策略
當 Redis 內存到達或超過 maxmemory 限制時,系統如何精確、高效地清理無用或不活躍的數據,保障緩存的命中率與訪問性能。
一、淘汰原理
-
內存閾值與觸發條件
- 通過配置
maxmemory設置 Redis 可用的最大內存。 - 當內存使用量超過閾值,或在定期過期檢查時發現過期 key,均觸發淘汰動作。
- 通過配置
-
場景一:定期過期掃描(serverCron)
-
周期性執行
serverCron,對每個redisDb的expires過期字典進行采樣:- 隨機取 20 個帶過期時間的 key 樣本;
- 若其中超過 5 個已過期(比例 >25%),繼續取樣并清理,直至過期比例 ≤25% 或 時間耗盡;
-
若某 DB 的過期字典填充率 <1%,則跳過采樣。
-
為避免阻塞主線程,清理時限:
- Redis 5.0 及之前:慢循環策略,默認 25ms;
- Redis 6.0:快循環策略,限時 1ms。
-
-
場景二:命令執行時檢查
- 在每次執行命令前,檢查當前內存占用是否已超限;
- 若超限,則立即依據所選
maxmemory-policy進行 key 淘汰,釋放內存后再繼續執行寫命令。
二、淘汰方式
Redis 提供兩種刪除方式,以平衡主線程響應和內存回收的及時性:
-
同步刪除
- 直接在主線程中刪除 key 及其 value,并同步回收內存;
- 適用于簡單值或復合類型元素數 ≤64 的情況。
-
異步刪除(Lazy Free)
-
依賴 BIO 線程池異步回收內存,避免主線程因大對象刪除而阻塞;
-
觸發條件:
lazyfree-lazy-expire:延遲過期清理;lazyfree-lazy-eviction:延遲淘汰時;
-
對象類型:list、set、hash、zset 中,元素數 >64 時使用。
-
三、淘汰策略與 Eviction Pool
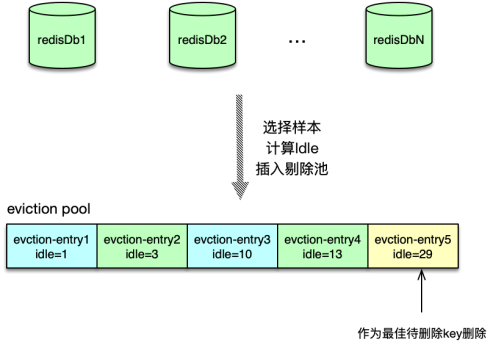
為在維持高性能的同時,盡可能剔除最“冷”的數據,Redis 在淘汰前會:
-
隨機采樣 N 個 key(默認為 5)
-
計算每個樣本的“Idle”值
- 對于 LRU,用空閑時間;LFU 則用
255 – 頻率;TTL 策略以UINT_MAX – 過期時間;
- 對于 LRU,用空閑時間;LFU 則用
-
維護大小為 N 的 Eviction Pool
- 按 Idle 從小到大插入,始終保留 Idle 最大的樣本;
-
最終剔除 Pool 中 Idle 最大的 key
四、八種淘汰策略詳解
| 策略名稱 | 作用范圍 | 算法原理 | 適用場景 |
|---|---|---|---|
| noeviction | 不淘汰任何 key | 達到內存上限后,對寫命令返回錯誤,讀命令正常 | 小規模數據,Redis 作為持久存儲而非緩存 |
| volatile-lru | 帶過期時間的 key | 基于 LRU,從 expires 中隨機 N 樣本,剔除空閑時間最長的 key | 熱點數據明顯,且淘汰對象均已設置過期時間的緩存場景 |
| volatile-lfu | 帶過期時間的 key | 基于 LFU,從 expires 隨機 N 樣本,剔除使用頻率最低的 key(Idle = 255–freq) | 訪問頻率具有明顯冷熱區分的業務,且僅淘汰已設置過期時間的對象 |
| volatile-ttl | 帶過期時間的 key | 剔除最近到期的 key(Idle = UINT_MAX–TTL) | 按剩余生命周期冷熱分區,優先清理即將過期的數據 |
| volatile-random | 帶過期時間的 key | 從 expires 隨機選一個 key 直接剔除 | 無明顯訪問熱點,且僅對帶過期時間的對象進行隨機清理 |
| allkeys-lru | 所有 key | 與 volatile-lru 類似,但樣本來自主字典 dict | 全局范圍的 LRU 淘汰,適合全量緩存且有熱點區分的場景 |
| allkeys-lfu | 所有 key | 與 volatile-lfu 類似,樣本來自主字典 dict | 訪問頻率冷熱明顯,需要對所有 key 進行頻率淘汰的場景 |
| allkeys-random | 所有 key | 從主字典 dict 隨機選一個 key 直接剔除 | 隨機訪問場景,無明顯熱點,全局隨機淘汰 |
Redis 的三種持久化方案及崩潰后數據恢復流程
Redis 持久化是一個將內存數據轉儲到磁盤的過程。Redis 目前支持 RDB、AOF,以及混合存儲三種模式。
一、RDB 持久化
-
原理概述
- 以快照方式將內存全量數據序列化為二進制格式,包含:過期時間、數據類型、key 與 value;
- 重啟時(
appendonly關閉),直接加載 RDB 文件恢復數據。
-
觸發場景
- 手動執行
SAVE(阻塞主進程)或BGSAVE(子進程異步); - 配置
save <秒> <次數>:在指定時間內寫操作次數達到閾值自動觸發; - 主從復制全量同步時,主庫為了生成同步快照會執行
BGSAVE; - 執行
FLUSHALL或優雅SHUTDOWN時,自動觸發快照。
- 手動執行
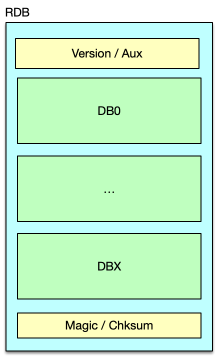
-
RDB 文件結構
- 頭部:版本信息、Redis 版本、生成時間、內存占用等;
- 數據區:按 DBID 分塊,依次寫入每個
redisDb的主字典與過期字典條目,記錄過期時間及 LRU/LFU 元數據; - 尾部:Lua 腳本等附加信息、EOF 標記(255)、校驗和(cksum)。
-
優缺點
- 優點:文件緊湊、加載快;
- 缺點:全量快照只能反映觸發時刻數據,之后變更丟失;子進程構建仍消耗 CPU,不能頻繁在高峰期執行;格式二進制,可讀性差,跨版本兼容性需謹慎。
二、AOF 持久化

-
原理概述
- 將每條寫命令以 Redis 協議的 MULTIBULK 格式追加到 AOF 文件;
- 重啟時,按序加載并重放寫命令,恢復到最近狀態。
-
落地流程
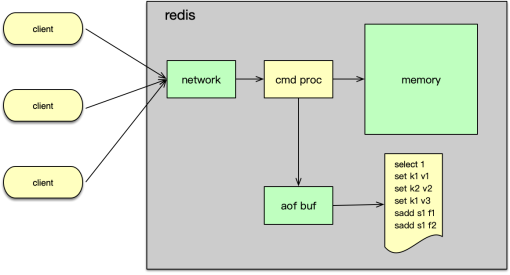
- 寫命令執行后寫入 AOF 緩沖;
serverCron周期將緩沖寫入文件系統緩沖;- 按
appendfsync策略fsync同步到磁盤。
-
同步策略
no:不主動fsync,依賴操作系統(約 30s 同步),風險大;always:每次寫緩沖后都fsync,最安全但性能和磁盤壽命受影響;everysec:每秒一次異步fsync(BIO 線程),在安全性與性能間折中。
-
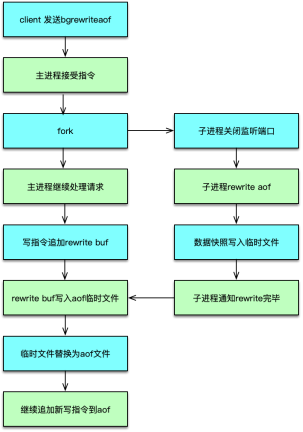
AOF 重寫(Rewrite)
-
通過
BGREWRITEAOF或自動觸發,fork子進程生成精簡命令集:- 子進程掃描每個
redisDb,將內存快照轉為寫命令寫入臨時文件; - 主進程繼續處理請求,并將寫命令同時寫入舊 AOF 與 rewrite 緩沖;
- 子進程完成后,主進程合并 rewrite 緩沖并替換舊文件;舊文件由 BIO 異步關閉。
- 子進程掃描每個
-
-
優缺點
- 優點:記錄所有寫操作,最多丟失 1–2 秒;兼容性好、可讀;
- 缺點:文件隨時間增大,包含大量中間狀態;恢復時需重放命令,速度相對較慢。
三、混合持久化
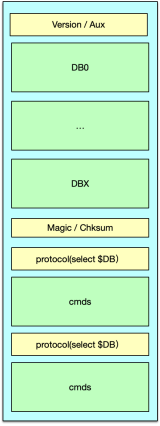
-
原理與配置
- 自 Redis 4.0 引入,5.0 默認開啟;配置
aof-use-rdb-preamble yes。 BGREWRITEAOF時,子進程先將全量內存數據以 RDB 格式寫入 AOF 臨時文件,再追加期間新增寫命令;
- 自 Redis 4.0 引入,5.0 默認開啟;配置
-
流程
fork子進程;- 子進程將內存快照寫為 RDB 格式到臨時文件;
- 追加子進程運行期間主進程緩沖的寫命令;
- 通知主進程替換 AOF,舊文件異步關閉。
-
優缺點
- 優點:兼具 RDB 加載快與 AOF 新數據保留特性;恢復速度快且幾乎無數據丟失;
- 缺點:頭部 RDB 部分依然為二進制,不易閱讀;跨版本兼容需測試。
- RDB:全量快照,文件小、加載快,但存在數據丟失窗口;
- AOF:命令追加,幾乎無丟失,兼容性高,但文件大、重放慢;
- 混合:RDB+AOF,一體化折中方案。
Redis 后臺異步 IO(BIO)
Redis 核心線程單線程模型雖能高效處理多數操作,但對文件關閉、磁盤同步、以及大對象的逐一回收等系統調用依然容易導致短時阻塞,從而影響整體吞吐和響應延遲。接下來深入介紹 Redis 如何通過后臺 IO(BIO)線程,將這些“慢任務”異步化,保證主線程的高可用性與低延遲。
一、BIO 線程設計動機
-
單線程模型的挑戰
- 主線程需處理所有客戶端請求、過期清理、淘汰等,性能極高;
- 若再執行如
close()、fsync()、大對象釋放等系統調用,短則數毫秒、長則上百毫秒,都將阻塞請求處理,造成卡頓;
-
異步化解決思路
- 將這些“慢任務”提交給后臺線程異步執行;
- 主線程僅需快速入隊并繼續服務,顯著降低響應延遲波動。
二、BIO 線程模型
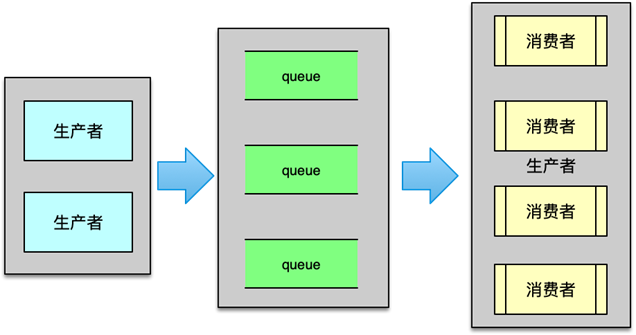
Redis 采用經典的生產者-消費者模式:
- 生產者:主線程在檢測到慢任務時,構建相應的 BIO 任務結構并入隊;
- 消費者:專屬的 BIO 線程阻塞等待隊列中的新任務,一旦被喚醒即取出并執行;
- 同步機制:使用互斥鎖保護隊列,條件變量實現高效喚醒/等待,確保線程安全與低開銷。
三、BIO 任務類型
Redis 啟動時,為三類任務分別創建獨立的任務隊列與線程:
| BIO 線程名稱 | 任務隊列 | 主要用途 |
|---|---|---|
| close | closeQ | 關閉舊 AOF/客戶端/其他文件描述符,避免主線程被 close() 阻塞 |
| fsync | fsyncQ | 將內核文件緩沖區的內容強制同步到磁盤(fsync()),保障數據持久化 |
| lazyfree | lazyfreeQ | 異步回收大對象(元素數 >64 的 list/set/hash/zset),避免主線程長時間釋放 |
四、BIO 處理流程
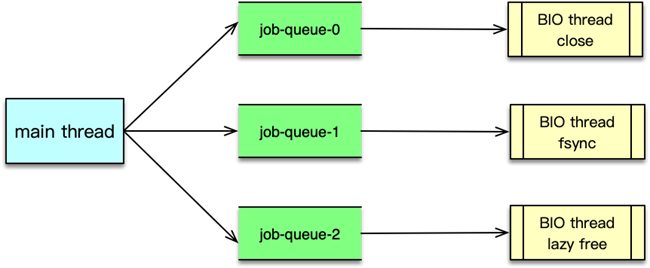
-
任務提交(主線程)
- 根據任務類型分配 BIO 任務;
- 加鎖后將任務追加到對應隊列尾部;
- 通過條件變量喚醒等待的 BIO 線程;
-
任務消費(BIO 線程)
- 阻塞等待新任務到來;
- 取出并執行對應系統調用或對象釋放;
- 任務完成后釋放任務結構,繼續等待;
通過引入專門的 BIO 后臺線程隊列,Redis 將所有可能導致短時阻塞的系統調用與大對象回收異步化處理,從而最大限度地保障主線程的低延遲和高吞吐能力。
Redis 多線程架構
Redis 自身單進程單線程模型極大簡化了并發控制、保證了命令執行的原子性,但也限制了吞吐能力。相比 Memcached 能夠通過多線程輕松跑出百萬級 TPS,Redis 單實例 TPS 往往在 10–12 萬左右,線上峰值也多在 2–4 萬,難以充分利用現代 16+ 核服務器。為解決這一痛點,Redis 6.0 在不改動現有核心執行邏輯的前提下,引入了可選的 IO 多線程模型,以并行化網絡讀寫與協議解析,從而在保留主線程執行安全的同時,實現 1–2 倍的性能提升。
一、主線程職責
- 事件驅動 Loop(
ae):監聽客戶端連接、讀寫事件與定時任務,不變; - 命令執行:所有實際的業務命令處理邏輯繼續在單一主線程中運行,保持原子性與簡單的調度;
- 核心任務分發:在網絡 IO 上,主線程將讀寫請求委派給 IO 線程;在命令執行完畢后,將回復操作同樣回交給 IO 線程處理。
二、IO 線程設計
- 目標:并行化耗時主要集中在三處:網絡讀取、協議解析與響應寫入;
- 配置:可通過
io-threads和io-threads-do-reads參數開啟與設置線程數(典型 4–8 個); - 模型:主線程負責將待讀或待寫的
client對象加入對應隊列,IO 線程異步批量拉取并行處理,處理完后主線程再繼續后續邏輯。
三、命令處理完整流程
Redis 6.0 的多線程處理流程如圖所示。主線程負責監聽端口,注冊連接讀事件。當有新連接進入時,主線程 accept 新連接,創建 client,并為新連接注冊請求讀事件。
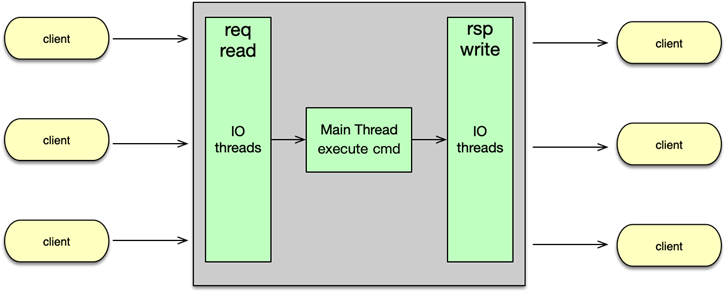
-
連接與讀事件注冊
- 主線程
accept()新連接,創建client,注冊可讀事件;
- 主線程
-
并行讀取與解析
- 讀事件觸發時,主線程不直接讀取,而將
client加入待讀取隊列; - 當一輪事件循環結束,發現待讀取鏈表非空,主線程將所有待讀
client分派給 IO 線程; - IO 線程并行讀取各自
client->fd,將原始數據填入client->querybuf,并執行協議解析,填充client->argc/argv; - IO 線程處理完所有任務后更新待處理計數,主線程自旋等待計數歸零。
- 讀事件觸發時,主線程不直接讀取,而將
-
命令執行
- 主線程依次取出已解析的命令,調用原有
redisCommand處理函數執行;
- 主線程依次取出已解析的命令,調用原有
-
并行響應寫入
- 執行結束后,主線程通過
addReply*系列將結果填入client->buf,并將client加入待寫隊列; - 將隊列再次分派給 IO 線程并自旋等待;
- IO 線程并行將
client->buf寫回各自連接,完成響應; - 主線程檢測所有寫入完成后,繼續下一輪事件循環。
- 執行結束后,主線程通過
四、多線程方案優劣
| 優點 | 缺點與瓶頸 |
|---|---|
| - 并行化網絡 IO 和協議解析,減少主線程阻塞,整體 TPS 提升 1–2 倍 | - 命令執行與事件調度仍集中于單一主線程,難以突破核心邏輯瓶頸 |
| - 利用多核 CPU 優化網絡吞吐,客戶端連接并發性能更好 | - IO 批量處理模式需要“先讀完再寫回”,客戶端間相互等待,增加延遲抖動 |
| - 保留原子性與簡潔性,無需改動現有命令實現 | - 主線程自旋等待 IO 線程完成,若任務少也會高頻自旋,浪費 CPU 資源 |
| - 部分場景下性能提升有限,無法替代真正的多線程命令處理模型 |
整體來看,Redis 6.0 的 IO 多線程是一次低侵入式的性能優化,能在不破壞兼容性與原子性的前提下帶來可觀提升。但要實現數量級躍升,還需將命令處理、事件調度等核心邏輯多線程化,解耦互斥等待,并逐步演進為真正的全棧并行模型。
復制架構原理
為了避免單點故障、提高可用性與讀性能,必須對數據進行多副本存儲。Redis 作為高性能的內存數據庫,從一開始就內建了主從復制功能,并在各個版本迭代中不斷優化復制策略。
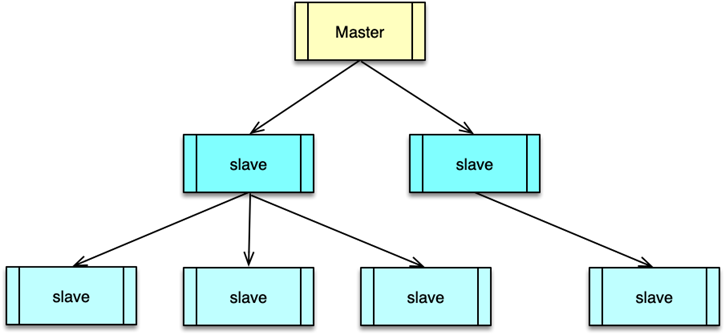
一、復制架構原理
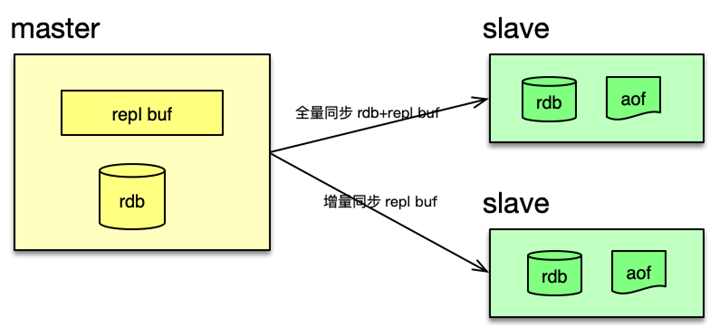
- 多層嵌套復制:一個 Master 可以掛載多個 Slave,Slave 也可繼續掛載更多下游 Slave,形成樹狀層級結構。
- 寫操作分發:所有寫命令僅在 Master 節點執行,執行完后即時分發給下游所有 Slave,保證數據一致。
- 讀寫分離:Master 只負責寫請求,所有讀請求由 Slave 處理。這種架構既消除了單點故障風險,又通過 N 倍 Slave 并發提升了讀 TPS。
此外,Master 在向 Slave 分發寫命令的同時,會將寫指令保存到復制積壓緩沖區(replication backlog),以便短時斷連的 Slave 重連后增量同步。
二、同步方式對比
| 同步類型 | 描述 | 優勢 | 劣勢 |
|---|---|---|---|
| 全量同步 | Master 生成 RDB 快照并傳輸給 Slave,同時發送緩沖區積壓命令,Slave 全量重建數據。 | 數據完整,適用于首次同步 | 構建 RDB 和網絡傳輸壓力大,耗時長 |
| 增量同步 | Master 僅發送自上次同步位置之后的寫命令,無需生成 RDB。 | 輕量、帶寬占用極低、無 RDB 構建延遲 | 依賴緩沖區容量和斷連時長,容易導致全量重試 |
三、psync 與 psync2 優化
-
psync(Redis 2.8+)
- 引入復制積壓緩沖區
- Slave 重連時上報 runid 與偏移量
- 若 runid 一致且偏移仍在緩沖區,則返回
CONTINUE,進行增量同步;否則觸發全量同步
-
psync2(Redis 4.0+)
- runid 升級為 replid 與 replid2
- RDB 文件中存儲 replid 作為 aux 信息,重啟后可保留 replid
- 切主時,通過 replid2 支持跨主機增量同步
相比早期版本,psync2 在短鏈路抖動、Slave 重啟和主庫切換等場景中,均能在更多情況下保持增量同步,顯著降低性能開銷與恢復時間。
四、復制連接與授權流程
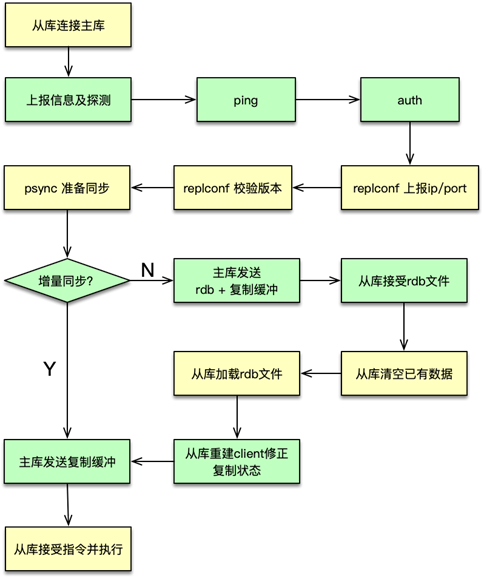
-
連接檢測
- Slave 向 Master 發送
PING→ 收到PONG則可用
- Slave 向 Master 發送
-
鑒權(若啟用密碼)
- Slave 發送
AUTH <masterauth>
- Slave 發送
-
能力協商
- Slave 通過
REPLCONF上報自身 IP、端口及支持的eof、psync2能力
- Slave 通過
-
同步請求
- Slave 發送
PSYNC <replid> <offset> - Master 根據 replid、replid2 與復制積壓緩沖,決定全量或增量
- Slave 發送
五、復制過程詳析
5.1 增量同步流程
- Master 返回
CONTINUE <replid> - Slave 將自身 replid 更新為 Master 返回的 replid,將原 replid 存為 replid2
- Master 從偏移量繼續推送寫命令
5.2 全量同步流程
- Master 返回
FULLRESYNC <replid> <offset> - Master 執行
BGSAVE生成新的 RDB 快照 - 將 RDB 與復制緩沖區命令一起推送給 Slave
- Slave 關閉下游子 Slave 連接,清空本地緩沖
- Slave 寫入臨時 RDB 文件(每 8MB fsync)→ 重命名 → 清庫 → 加載 RDB
- 重建與 Master 的命令推送通道,并開啟 AOF 持久化
六、注意事項
- 緩沖區大小:過大會占用過多內存;過小易導致緩沖刷出,觸發全量復制
- 網絡穩定性:長連接抖動或丟包會影響復制效率
- 監控復制延遲:及時預警和擴容,避免生產環境中讀數據不一致或延遲過高
- 主庫切換策略:在切換 Master 前保證所有 Slave 與當前 Master 完成同步
Redis 集群的分布式方案
Redis 的分布式方案主要分為三類:
- Client 端分區
- Proxy 分區
- 原生 Redis Cluster
下面將逐一介紹它們的設計思路、實現方式及各自優缺點
1. Client 端分區
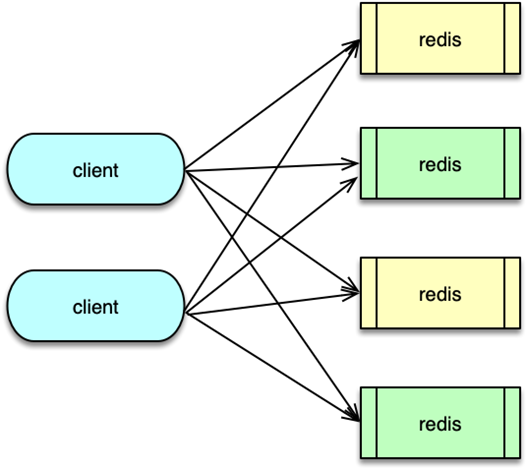
1.1 原理與哈希算法
客戶端通過哈希算法決定某個 key 應存儲在哪個分片(Shard)上,常見算法包括:
- 取模哈希:
hash(key) % N - 一致性哈希:在哈希環上分配虛擬節點,實現動態擴縮容的平滑性
- 區間分布哈希:實際是取模的變種,將 Hash 輸出映射到固定區間,再由區間決定分片
對于單 key 請求,客戶端直接計算哈希并路由;對于包含多個 key 的請求,客戶端先對 key 按分片分組,再拆分成多條請求并發執行。
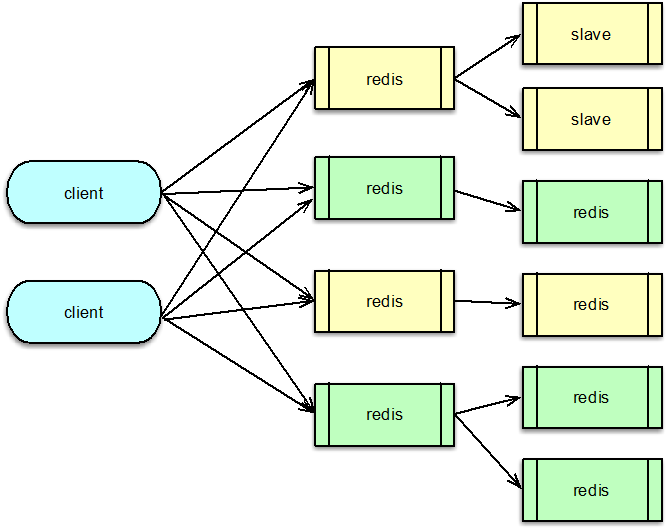
1.2 DNS 動態管理
由于每個 Redis 分片的 Master/Slave 都有獨立 IP:Port,當發生故障切換或新增 Slave 時,客戶端需更新連接列表。
- DNS 管理:為每個分片的主/從分別配置不同域名,客戶端定時異步解析域名、更新連接池
- 負載均衡:按權重將請求在各 Slave 之間輪詢,既可分散讀壓,又無需業務側改動
1.3 優缺點
- 優點:無中心依賴、邏輯簡單、性能最優(無額外代理),客戶端可靈活控制
- 缺點:擴展不夠平滑(新增分片需修改客戶端邏輯并重啟)、業務端分片邏輯耦合
2. Proxy 分區方案
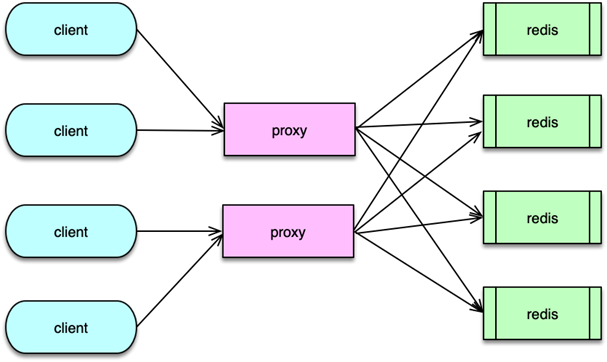
2.1 架構概覽
客戶端只需連接到統一的 Proxy 層,由 Proxy 完成路由、拆分及聚合:
- 接收請求 → 解析命令 → 哈希計算 → 路由到對應 Redis → 聚合響應 → 返回客戶端
這樣,客戶端免維護分片信息,真正的分布式邏輯都隱藏在 Proxy 之下。
2.2 典型實現
| 方案 | 特點 | 擴縮容 | 性能損耗 |
|---|---|---|---|
| Twemproxy | 單進程單線程;實現簡單、穩定;不支持平滑擴縮 | 重啟 Proxy | ~5–15% |
| Codis | 支持在線數據遷移;豐富的 Dashboard;多實例 | Dashboard+ZK/etcd | 略高于 Twemproxy |
- Twemproxy:適合小規模、幾乎不擴縮容的場景;但單線程模型對多 key 請求性能有限
- Codis:基于 Redis 擴展的 Slot 方案,提供 dashboard 管理,支持在線擴縮容
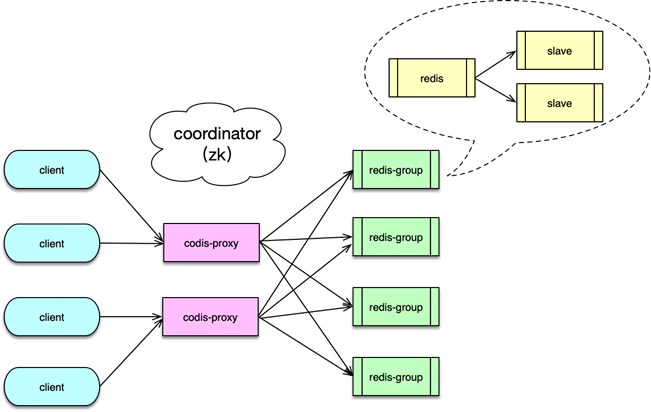
2.3 優缺點
- 優點:客戶端無需感知分片;擴縮容僅改 Proxy,運維便利
- 缺點:增加訪問中間層,帶來約 5–15% 的性能開銷;系統更復雜
3. 原生 Redis Cluster
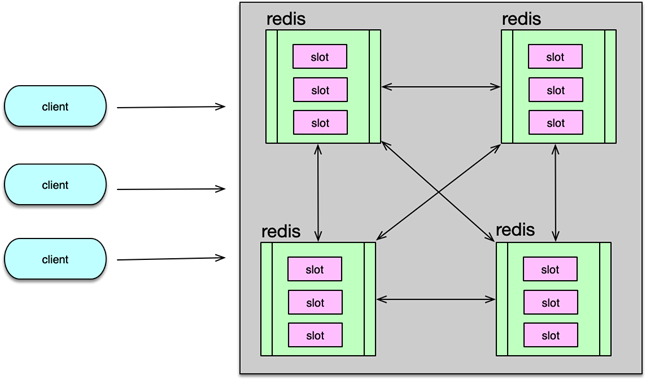
3.1 Slot 與 Gossip 架構
- 16384 個 Slot:啟動時通過
CLUSTER ADDSLOTS將 Slot 分配到各節點,key 經 CRC16 哈希后落在具體 Slot - Gossip 協議:節點間去中心化通信,更新拓撲無需中心節點,操作通過
cluster meet等命令擴散
3.2 讀寫與重定向
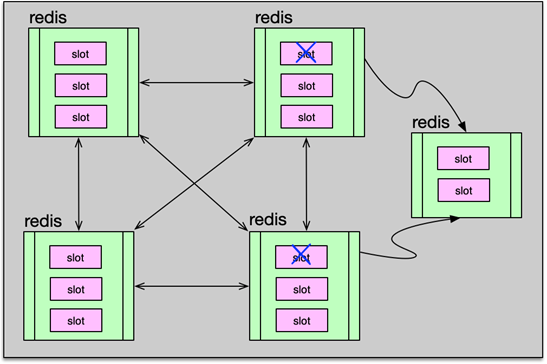
- Smart Client 緩存 Slot→節點映射
- 若請求到錯節點,返回
MOVED或ASK,包含正確節點信息,客戶端解析后重定向 - 遷移過程中,新舊節點返回
ASK并引導客戶端臨時訪問遷移節點
3.3 在線擴縮容與數據遷移
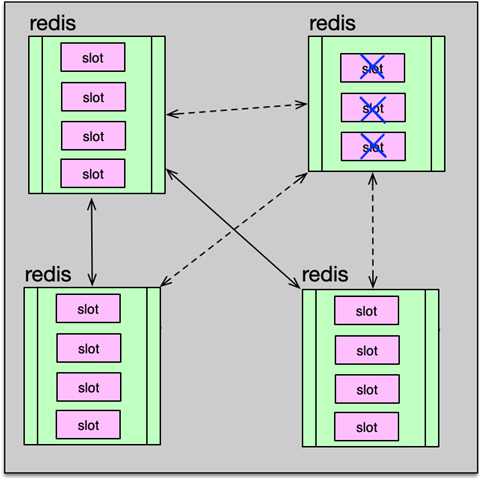
cluster meet加入新節點(無 Slot,不可讀寫)- 源節點
cluster setslot slot migrating,目標節點… importing cluster getkeysinslot+migrate遷移 key 數據;遷移期間阻塞該進程cluster setslot slot nodeid分配 Slot- 為新主節點添加 Slave:使用
cluster replicate,Slave 只能掛到 Master
縮容則相反:先遷移 Slot,再 cluster forget 下線節點(并加入禁止列表)。
3.4 優缺點
- 優點:社區官方實現;在線擴縮容;無中心依賴;自動故障轉移
- 缺點:Slot 與 key 映射占內存;遷移阻塞導致卡頓;復制鏈路單層限制了讀擴展
4. 對比與選型建議
| 維度 | Client 分區 | Proxy 分區 | Redis Cluster |
|---|---|---|---|
| 客戶端維護 | 高 | 無 | 需 Smart Client |
| 擴縮容平滑度 | 低 | 中(Proxy 重啟) | 高(在線遷移) |
| 性能開銷 | 最小 | 中等(5–15%) | 較低 |
| 運維復雜度 | 業務側 | Proxy 層 | 集群管理 |
| 成熟度 | 通用方案 | Codis、Twemproxy | 官方支持 |
- 讀密集場景:若對擴縮容需求不強,且對性能最敏感,可考慮 Client 分區。
- 寫擴展與在線遷移:需平滑擴縮容,且可接受少量代理層開銷,推薦 Codis 或 Redis Cluster。
- 大規模復雜部署:傾向官方 Redis Cluster,享受社區生態和原生工具支持。
三種方案各有側重:Client 分區最輕量、性能最高;Proxy 分區運維便利;Redis Cluster 原生、彈性最佳。實際生產中,可根據業務特性和運維成本做權衡。







JVM彈性內存管理)








)



