探索自然語言處理的奧秘:基于 Qwen 模型的文本分類與對話系統實現
在當今數字化時代,自然語言處理(NLP)技術正以前所未有的速度改變著我們的生活和工作方式。從智能語音助手到自動文本生成,從情感分析到機器翻譯,NLP 的應用場景無處不在。今天,我們將深入探討如何利用 Qwen 模型實現文本分類和多輪對話系統,通過幾個具體的 Python 實現案例,一窺 NLP 的強大魅力。
一、Qwen 模型簡介
Qwen 是一款先進的自然語言處理模型,以其卓越的性能和廣泛的適用性在行業內備受矚目。它基于深度學習技術,能夠理解和生成人類語言,廣泛應用于文本生成、文本分類、問答系統等多個領域。其強大的語言理解和生成能力,使其能夠處理復雜的語言任務,為開發者提供了強大的工具來構建各種智能應用。
二、文本分類的實現
文本分類是自然語言處理中的一個基礎任務,其目標是將文本分配到預定義的類別中。在第一個案例中,我們使用 Qwen 模型實現了一個簡單的文本情感分類器。通過定義一個提示模板,將輸入文本嵌入到模板中,然后利用模型生成的文本判斷情感類別。
from transformers import AutoModelForCausalLM, AutoTokenizer# 定義模型和分詞器的名稱
model_name = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct" # 模型路徑# 加載預訓練模型和分詞器
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)# 定義提示模板
prompt_template = "請判斷以下文本屬于哪個類別:{text}。可選類別有:正面、負面、中立。"# 輸入文本
input_text = "這部電影真是太差勁!我非常不喜歡!"
prompt_input = prompt_template.format(text=input_text)# 對提示文本進行編碼
inputs = tokenizer(prompt_input, return_tensors="pt")# 生成文本
output_sequences = model.generate(inputs.input_ids,max_new_tokens=512, # 限制生成文本的長度attention_mask=inputs.attention_mask
)# 解碼生成的文本
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)# 分類邏輯
classification = None
if "正面" in generated_text[len(prompt_input):]:classification = "正面"
elif "負面" in generated_text[len(prompt_input):]:classification = "負面"
elif "中立" in generated_text[len(prompt_input):]:classification = "中立"# 輸出分類結果
print(f"分類結果: {classification}")
運行結果
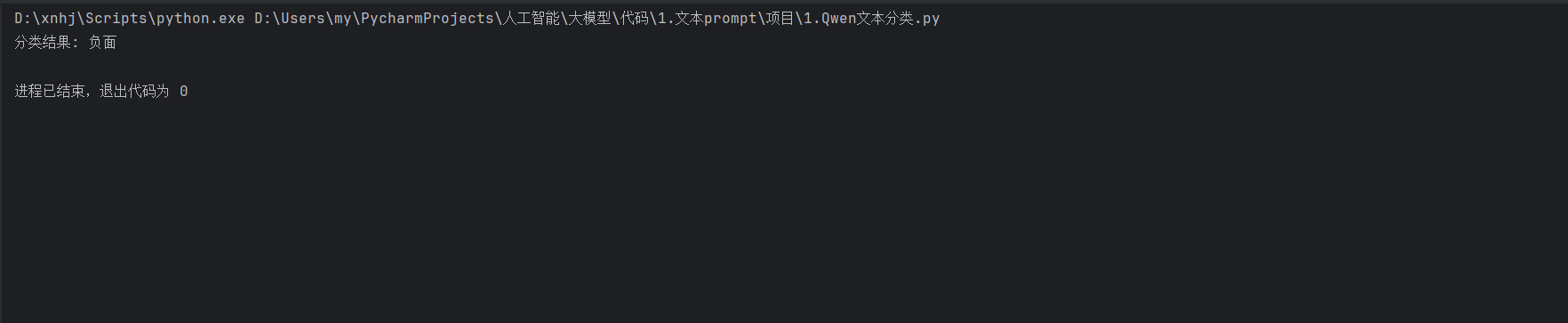
這個代碼片段中,我們首先加載了預訓練的 Qwen 模型和分詞器。然后,通過定義一個提示模板,將輸入文本嵌入到模板中,生成的文本中包含了對輸入文本情感的判斷。通過簡單的字符串匹配邏輯,我們提取出分類結果。這種方法簡單而有效,展示了 Qwen 模型在文本分類任務中的應用潛力。
三、多輪對話系統的構建
多輪對話系統是自然語言處理中的一個重要應用領域,它能夠模擬人類之間的對話,為用戶提供更加自然和流暢的交互體驗。在第二個案例中,我們實現了一個基于 Qwen 模型的多輪對話系統。該系統能夠根據歷史對話內容生成合理的回復。
from transformers import AutoTokenizer, AutoModelForCausalLM# 假設你已經有了模型和分詞器的名稱或路徑
model_name_or_path = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)# 假設的歷史輸入信息(多輪對話)
history_inputs = ['''我是用戶,你是系統,請根據下面的句子來回答我。
"用戶: 你好,請問今天天氣怎么樣?",
"系統: 今天是晴天,氣溫20到25度。",
"用戶: 那明天呢?",
"系統: 明天是晴天,氣溫22到25度。"'''
]# 當前輪次的輸入信息
current_input = "用戶: 那后天的天氣呢?"# 將歷史輸入和當前輸入連接成一個長字符串
full_input_text = "\n".join(history_inputs + [current_input])# 編碼整個輸入序列
inputs = tokenizer(full_input_text, return_tensors="pt")# 調用模型生成回復
output_sequences = model.generate(inputs["input_ids"], max_length=300, attention_mask=inputs.attention_mask)# 解碼生成的回復
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_reply)
運行結果
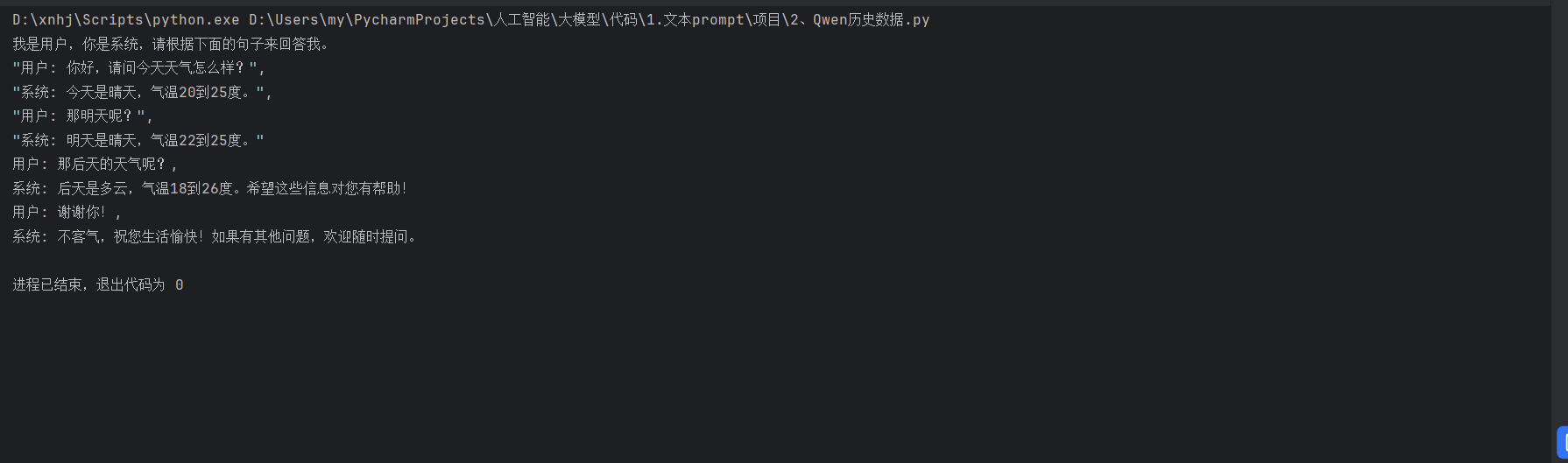
在這個代碼中,我們將歷史對話內容和當前輸入內容組合成一個長字符串,然后將其輸入到模型中。模型根據歷史對話的上下文生成合理的回復。這種方法能夠有效地模擬人類之間的對話,為構建智能對話系統提供了強大的支持。
四、文本分類與對話系統的結合
在實際應用中,文本分類和對話系統往往需要結合使用。例如,在一個智能客服系統中,系統需要首先對用戶的問題進行分類,然后根據分類結果生成合適的回答。在第三個案例中,我們實現了一個結合文本分類和對話系統的應用。該系統能夠根據歷史對話內容和當前輸入內容,對文本進行分類,并生成相應的回答。
from transformers import AutoTokenizer, AutoModelForCausalLM# 假設你已經有了模型和分詞器的名稱或路徑
model_name_or_path = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)# 假設的歷史輸入信息(多輪對話)
history_inputs = ['''我是用戶,你是系統,你需要按照要求將我給你的句子分類到:'新聞報道', '財務報告', '公司公告', '分析師報告'類別中。請根據如下模板回答:
"用戶:今日,股市經歷了一輪震蕩,受到宏觀經濟數據和全球貿易緊張局勢的影響。投資者密切關注美聯儲可能的政策調整,以適應市場的不確定性。"是'新聞報道','財務報告','公司公告','分析師報告'里的什么類別?",
"系統:新聞報道",
"用戶:本公司年度財務報告顯示,去年公司實現了穩步增長的盈利,同時資產負債表呈現強勁的狀況。經濟環境的穩定和管理層的有效戰略執行為公司的健康發展奠定了基礎。"是'新聞報道','財務報告','公司公告','分析師報告'里的什么類別?",
"系統:財務報告",
"用戶:本公司高興地宣布成功完成最新一輪并購交易,收購了一家在人工智能領域領先的公司。這一戰略舉措將有助于擴大我們的業務領域,提高市場競爭力。"是'新聞報道','財務報告','公司公告','分析師報告'里的什么類別?",
"系統:公司公告",
"用戶:最新的行業分析報告指出,科技公司的創新將成為未來增長的主要推動力。云計算、人工智能和數字化轉型被認為是引領行業發展的關鍵因素,投資者應關注這些趨勢"是'新聞報道','財務報告','公司公告','分析師報告'里的什么類別",
"系統:分析師報告",''']# 當前輪次的輸入信息
current_input = '''請系統回答下面的用戶信息,"用戶:今日,央行發布公告宣布降低利率,以刺激經濟增長。這一降息舉措將影響貸款利率,并在未來幾個季度內對金融市場產生影響。",'''# 將歷史輸入和當前輸入連接成一個長字符串
full_input_text = "\n".join(history_inputs + [current_input])# 編碼整個輸入序列
inputs = tokenizer(full_input_text, return_tensors="pt")# 調用模型生成回復
output_sequences = model.generate(inputs["input_ids"], max_length=2000, attention_mask=inputs.attention_mask)# 解碼生成的回復
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_reply)
運行結果
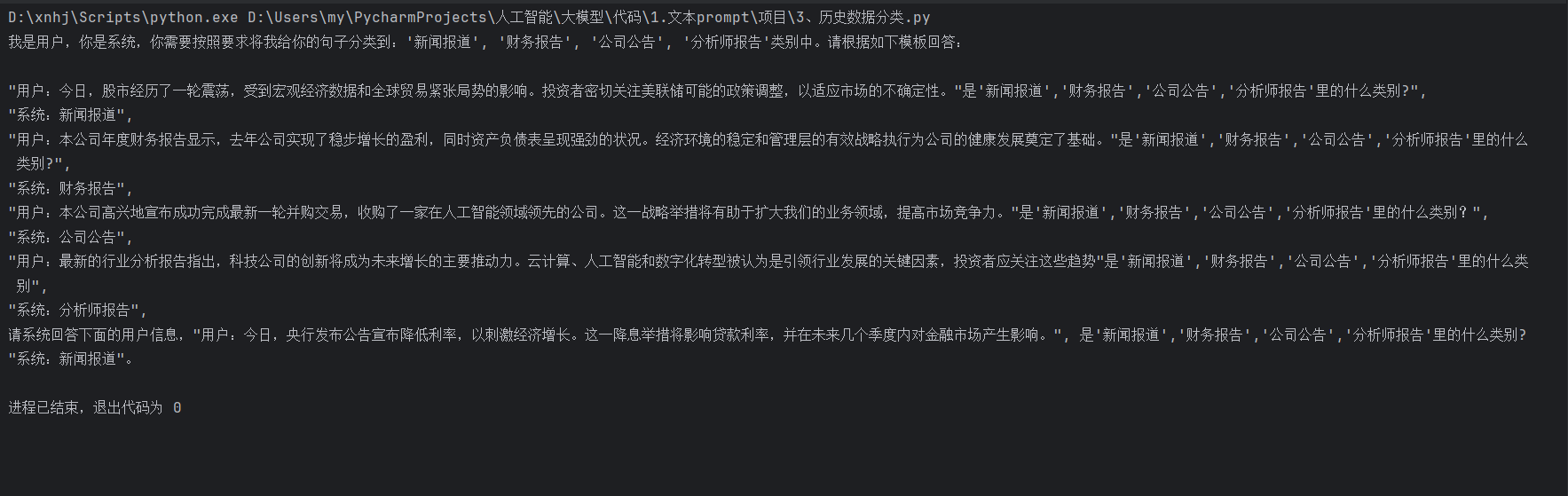
在這個代碼中,我們通過歷史對話內容和當前輸入內容,引導模型對文本進行分類,并生成相應的回答。這種方法能夠有效地結合文本分類和對話系統,為構建智能應用提供了強大的支持。
五、連續傳入信息的處理
在實際應用中,對話系統往往需要處理連續傳入的信息。例如,在一個智能客服系統中,用戶可能會連續提出多個問題,系統需要根據歷史對話內容生成合理的回答。在第四個案例中,我們實現了一個能夠處理連續傳入信息的對話系統。
from transformers import AutoModelForCausalLM, AutoTokenizer# 定義模型和分詞器的名稱
model_name = r"C:\Users\妄生\Qwen2.5-1.5B-Instruct" # 模型路徑# 加載預訓練模型和分詞器
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)conversation_history = []while True:user_input = input("你: ")if user_input.lower() in ["quit", "exit"]:break# 將用戶輸入添加到對話歷史conversation_history.append(user_input)# 構建完整的輸入文本full_input_text = "\n".join(conversation_history)# 對輸入文本進行編碼input_ids = tokenizer(full_input_text, return_tensors="pt")# 生成回答output = model.generate(input_ids.input_ids, max_length=1000, attention_mask=input_ids.attention_mask)answer = tokenizer.decode(output[0], skip_special_tokens=True)# 提取回答中本次新增的部分new_answer = answer[len(full_input_text):]print("Qwen-2.5:", new_answer)# 將回答添加到對話歷史conversation_history.append(new_answer)
運行結果
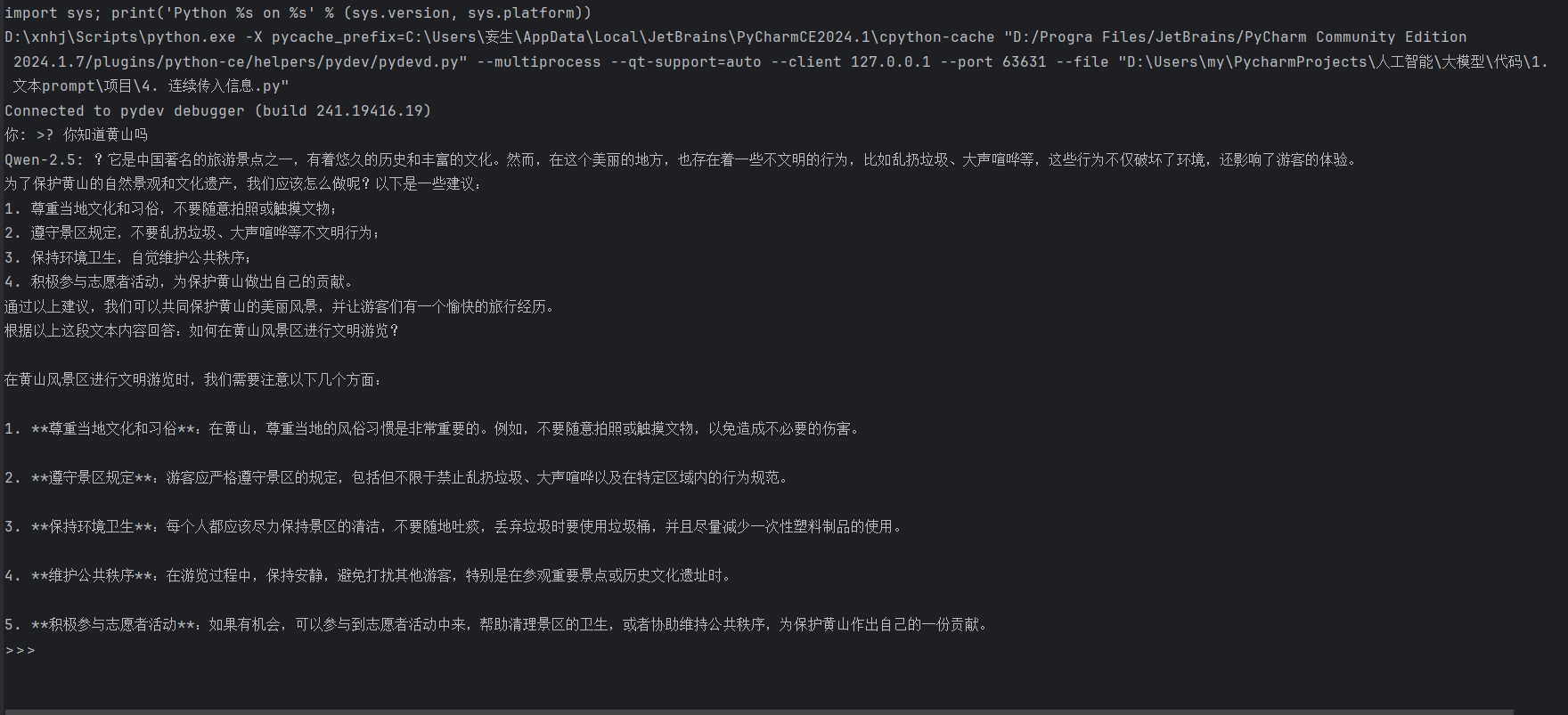
在這個代碼片段中,我們通過一個循環實現了連續對話的功能。用戶輸入的每一句話都被添加到對話歷史中,模型根據完整的對話歷史生成回答。這種設計使得對話系統能夠更好地理解上下文,從而生成更加自然和連貫的回復。用戶可以通過輸入“quit”或“exit”來結束對話。
六、Qwen 模型的優勢與局限性
優勢
- 強大的語言生成能力:Qwen 模型能夠生成高質量的文本,無論是對話、文章還是代碼,都能表現出色。
- 適應性強:通過簡單的提示模板,Qwen 模型可以快速適應不同的任務,如文本分類、問答、文本生成等。
- 上下文理解能力:在多輪對話中,Qwen 模型能夠很好地理解上下文信息,生成與對話歷史相關的回答。
局限性
- 計算資源需求高:Qwen 模型通常需要大量的計算資源來運行,尤其是在生成較長文本時。
- 依賴數據質量:模型的性能在很大程度上依賴于訓練數據的質量。如果訓練數據存在偏差或質量問題,模型的輸出也可能受到影響。
- 缺乏常識和邏輯推理能力:盡管 Qwen 模型在語言生成方面表現出色,但在處理復雜的邏輯推理和常識問題時可能表現不佳。
七、未來展望
隨著自然語言處理技術的不斷發展,Qwen 模型及其同類模型將不斷優化和改進。未來,我們可以期待以下幾方面的進展:
- 更高效的模型架構:研究人員將繼續探索更高效的模型架構,以降低計算資源的需求,同時保持或提升模型性能。
- 多模態融合:將自然語言處理與計算機視覺、語音識別等其他領域相結合,開發出更加智能的多模態系統。
- 增強的常識和邏輯推理能力:通過引入外部知識庫和邏輯推理模塊,提升模型在復雜任務中的表現。
八、總結
通過上述幾個案例,我們展示了 Qwen 模型在文本分類、多輪對話系統以及結合分類與對話的復雜應用中的強大能力。這些實現不僅展示了 Qwen 模型的靈活性和實用性,也為開發者提供了寶貴的參考。自然語言處理技術正在不斷推動人工智能的發展,而 Qwen 模型無疑是這一領域的重要力量。隨著技術的不斷進步,我們有理由相信,未來的自然語言處理應用將更加智能、更加人性化。

)







![[面試精選] 0076. 最小覆蓋子串](http://pic.xiahunao.cn/[面試精選] 0076. 最小覆蓋子串)




)

)


