摘要
在近期關于多模態模型的研究中,將圖像理解與生成統一起來受到了越來越多的關注。盡管圖像理解的設計選擇已經得到了廣泛研究,但對于具有圖像生成功能的統一框架而言,其最優模型架構和訓練方案仍有待進一步探索。鑒于自回歸和擴散模型在高質量生成和可擴展性方面具有強大潛力,我們對它們在統一多模態環境中的使用進行了全面研究,重點關注圖像表示、建模目標和訓練策略。基于這些研究,我們提出了一種新方法,該方法采用擴散Transformer生成語義豐富的CLIP圖像特征,這與傳統的基于VAE的表示方法不同。這種設計既提高了訓練效率,又提升了生成質量。此外,我們證明了統一模型的順序預訓練策略——先進行圖像理解訓練,再進行圖像生成訓練——具有實際優勢,能夠在發展強大的圖像生成能力的同時,保持圖像理解能力。最后,我們通過使用涵蓋各種場景、物體、人體姿態等的多樣化字幕提示GPT-4o,精心策劃了一個高質量的指令調優數據集BLIP3o-60k,用于圖像生成。基于我們創新的模型設計、訓練方案和數據集,我們開發了BLIP3-o,這是一套最先進的統一多模態模型。BLIP3-o在大多數涵蓋圖像理解和生成任務的流行基準測試中均取得了優異表現。為促進未來的研究,我們完全開源了我們的模型,包括代碼、模型權重、訓練腳本以及預訓練和指令調優數據集。
代碼:https://github.com/JiuhaiChen/BLIP3o
模型:https://huggingface.co/BLIP3o/BLIP3o-Model
預訓練數據:https://huggingface.co/datasets/BLIP3o/BLIP3o-Pretrain
指令調優數據:https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
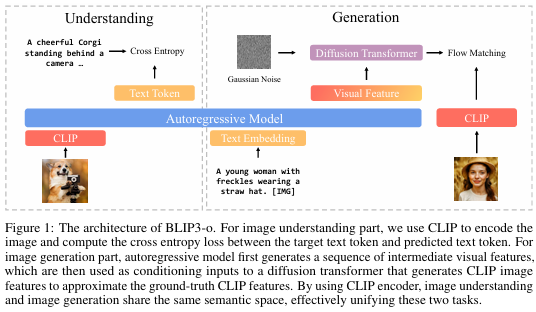
1 引言
近期的研究進展表明,支持圖像理解和圖像生成的統一多模態表示學習在單個模型中具有潛力[7, 31, 38, 35, 4, [33, 23]]。盡管在圖像理解方面已經進行了大量研究,但圖像生成的最優架構和訓練策略仍有待探索。以往的爭論主要集中在兩種方法上:第一種方法將連續的視覺特征量化為離散標記,并將其建模為分類分布[32, 34, 21];第二種方法通過自回歸模型生成中間視覺特征或潛在表示,然后基于這些視覺特征通過擴散模型生成圖像[33, 23]。近期發布的GPT-4o圖像生成功能[1]據稱采用了混合架構,結合了自回歸和擴散模型,遵循第二種方法[1, 40]。因此,我們受到啟發,以類似的方式對設計選擇進行系統研究。具體而言,我們的研究聚焦于三個關鍵設計維度:(1)圖像表示——是將圖像編碼為低層像素特征(例如,來自基于VAE的編碼器)還是高層語義特征(例如,來自CLIP圖像編碼器);(2)訓練目標——均方誤差(MSE)與流匹配[17, 19],以及它們對訓練效率和生成質量的影響;(3)訓練策略——像Metamorph [33]那樣對圖像理解和生成進行聯合多任務訓練,還是像LMFusion [28]和MetaQuery [23]那樣進行順序訓練,即先對模型進行理解訓練,然后擴展用于生成。
我們的研究發現,CLIP圖像特征比VAE特征提供了更緊湊、信息量更大的表示,從而加快了訓練速度并提高了圖像生成質量。流匹配損失被證明比均方誤差(MSE)損失更有效,能夠實現更多樣化的圖像采樣并產生更好的圖像質量。此外,我們發現順序訓練策略——先在圖像理解任務上訓練自回歸模型,然后在圖像生成訓練期間將其凍結——能取得最佳的整體性能。基于這些發現,我們開發了BLIP3-o,這是一系列最先進的統一多模態模型。BLIP3-o在CLIP特征上利用擴散Transformer和流匹配(如圖1所示),并按照順序在圖像理解和圖像生成任務上進行訓練。為了進一步提高視覺美感和指令跟隨能力,我們通過用涵蓋各種場景、物體、人類手勢等的多樣化提示詞提示GPT-4o,精心策劃了一個包含60k高質量指令調優數據集BLIP3o-60k用于圖像生成。我們觀察到,在BLIP3o-60k上進行監督指令調優顯著增強了BLIP3-o與人類偏好的對齊程度,并提高了美學質量。

在我們的實驗中,BLIP3-o在大多數流行的圖像理解和生成基準測試中均取得了優異表現,其中8B模型在MME-P上得分為1682.6,在MMMU上得分為50.6,在GenEval上得分為0.84。為了支持進一步的研究并秉承像BLIP-3 [39]這樣的開源基礎模型研究的使命,我們完全開源了我們的模型,包括模型權重、代碼、預訓練和指令調優數據集以及評估流程。我們希望我們的工作能夠支持研究社區,并推動統一多模態領域的持續進步。
2 圖像生成與理解的統一多模態模型
2.1 動機
近期研究表明,開發能夠同時支持圖像理解和生成的統一多模態架構是一個有前景的研究方向。Janus [4]、Show-o [38]、MetaMorph [33]、Janus-Pro [4]和LMFusion [28]等模型是早期在單一框架內實現圖像理解和生成融合的嘗試。近期OpenAI的GPT-4o [1]進一步展示了這種架構在高質量圖像生成和多模態理解方面的強大能力。然而,實現這種統一能力的底層設計原則和訓練策略仍有待深入研究。本研究旨在系統探討并推動統一模型的發展,并明確了構建統一多模態模型的關鍵動機。
推理與指令遵循? 將圖像生成能力集成到自回歸模型(如多模態大語言模型(MLLMs))中,有望繼承這些模型的預訓練知識、推理能力和指令遵循能力。例如,我們的模型能夠直接解讀諸如“一種長鼻子的動物”這樣的提示,而無需對提示進行重寫。這展示了傳統圖像生成模型難以企及的推理能力和世界知識水平。除了推理能力之外,當MLLMs的指令遵循能力被整合到統一架構中時,預計這種能力也會延續到圖像生成過程中。
上下文學習? 同時支持圖像理解和生成的統一模型自然促進了上下文學習能力。在這樣的模型中,之前生成的多模態輸出可以作為后續生成的上下文,從而為迭代圖像編輯、視覺對話以及逐步視覺推理提供無縫支持。這消除了模式切換或依賴外部處理流程的需要,使模型能夠保持一致性和任務連續性。
邁向多模態通用人工智能? 隨著人工智能向通用人工智能(AGI)邁進,未來的系統需要超越基于文本的能力,以無縫地感知、解釋和生成多模態內容。實現這一目標需要從僅支持文本的架構轉向能夠跨不同模態進行推理和生成的統一多模態架構。這樣的模型對于構建能夠以全面、類人的方式與世界交互的通用智能至關重要。
在這些動機的驅動下,我們在接下來的章節中探索開發一種統一模型,該模型能夠同時支持圖像理解和生成任務。
2.2 結合自回歸與擴散模型
近期,OpenAI的GPT-4o [1] 在圖像理解、生成和編輯任務中展現了最先進的性能。關于其架構的新興假設 [40] 提出了一種混合流程,結構如下:
標記(Tokens) ? \longrightarrow ? [自回歸模型(Autoregressive Model)] ? \longrightarrow ? [擴散模型(Diffusion Model)] ? \longrightarrow ? 圖像像素(Image Pixels)
這表明,自回歸模型和擴散模型可以聯合使用,以結合這兩個模塊的優勢。受這種混合設計的啟發,我們在研究中采用了自回歸 + 擴散的框架。然而,該框架下的最優架構仍不明確。自回歸模型生成連續的中間視覺特征,旨在近似真實圖像表示,這引發了兩個關鍵問題。首先,什么應作為真實嵌入(ground-truth embeddings):我們應該使用變分自編碼器(VAE)還是對比語言-圖像預訓練模型(CLIP)將圖像編碼為連續特征?其次,一旦自回歸模型生成了視覺特征,我們如何最優地將它們與真實圖像特征對齊,或者更一般地,我們應該如何建模這些連續視覺特征的分布:是通過簡單的均方誤差(MSE)損失,還是采用基于擴散的方法?因此,我們在下一節中對各種設計選擇進行了全面探索。
3 統一多模態框架中的圖像生成
在本節中,我們將討論在統一多模態框架內構建圖像生成模型時所涉及的設計選擇。我們首先探討如何通過編碼器 - 解碼器架構將圖像表示為連續嵌入,這種架構在學習效率和生成質量方面發揮著基礎性作用。
3.1 圖像編碼與重建
圖像生成通常始于使用編碼器將圖像編碼為連續的潛在嵌入,隨后由解碼器從該潛在嵌入重建圖像。這種編碼 - 解碼流程可以有效降低圖像生成中輸入空間的維度,從而促進高效訓練。接下來,我們將討論兩種廣泛使用的編碼器 - 解碼器范式。
變分自編碼器 變分自編碼器(Variational Autoencoders,VAEs)[12, 27] 是一類生成模型,它們學習將圖像編碼到一個結構化的連續潛在空間中。編碼器在給定輸入圖像的情況下近似潛在變量的后驗分布,而解碼器則從該潛在分布中抽取的樣本重建圖像。潛在擴散模型在此框架的基礎上進行構建,通過學習對壓縮后的潛在表示的分布進行建模,而非直接對原始圖像像素進行建模。這些模型通過在 VAE 的潛在空間中運行,顯著降低了輸出空間的維度,從而降低了計算成本,并實現了更高效的訓練。在去噪步驟之后,VAE 解碼器將生成的潛在嵌入映射到原始圖像像素。
帶擴散解碼器的 CLIP 編碼器 由于 CLIP [26] 模型通過在大規模圖像 - 文本對上進行對比訓練,具備從圖像中提取豐富高層語義特征的強大能力,因此已成為圖像理解任務 [18] 的基礎編碼器。然而,將這些特征用于圖像生成仍然是一個非平凡的挑戰,因為 CLIP 最初并非為重建任務而設計。Emu2 [31] 提出了一種實用的解決方案,即將基于 CLIP 的編碼器與基于擴散的解碼器配對使用。具體而言,它使用 EVA-CLIP 將圖像編碼為連續的視覺嵌入,并通過從 SDXL-base [24] 初始化的擴散模型重建圖像。在訓練過程中,擴散解碼器經過微調,以使用來自 EVA-CLIP 的視覺嵌入作為條件,從高斯噪聲中恢復原始圖像,而 EVA-CLIP 保持凍結狀態。這一過程有效地將 CLIP 和擴散模型結合為一個圖像自編碼器:CLIP 編碼器將圖像壓縮為語義豐富的潛在嵌入,而基于擴散的解碼器則從這些嵌入重建圖像。值得注意的是,盡管解碼器基于擴散架構,但它是使用重建損失而非概率采樣目標進行訓練的。因此,在推理過程中,該模型執行確定性重建。
討論? 這兩種編碼器 - 解碼器架構,即變分自編碼器(VAEs)和 CLIP-擴散(CLIP-Diffusion),代表了圖像編碼與重建的不同范式,各自具有特定的優勢和權衡。VAEs 將圖像編碼為低層級的像素特征,并提供更好的重建質量。此外,VAEs 作為現成模型廣泛可用,可直接集成到圖像生成訓練流程中。相比之下,CLIP-擴散需要額外的訓練來使擴散模型適應各種 CLIP 編碼器。然而,CLIP-擴散架構在圖像壓縮比方面提供了顯著優勢。例如,在 Emu2 [31] 和我們的實驗中,無論圖像分辨率如何,每張圖像都可以編碼為固定長度為 64 的連續向量,從而提供緊湊且語義豐富的潛在嵌入。相比之下,基于 VAE 的編碼器往往對更高分辨率的輸入產生更長的潛在嵌入序列,這增加了訓練過程中的計算負擔。
3.2 潛在圖像表示建模
在獲得連續圖像嵌入后,我們繼續使用自回歸架構對它們進行建模。給定一個用戶提示(例如,“一位戴著草帽、有雀斑的年輕女子”),我們首先使用自回歸模型的輸入嵌入層將提示編碼為一組嵌入向量 C \mathbf{C} C,并向 C \mathbf{C} C 追加一個可學習的查詢向量 Q \mathbf{Q} Q,其中 Q \mathbf{Q} Q 隨機初始化并在訓練過程中進行優化。當組合序列 [ C ; Q ] [\mathbf{C} ; \mathbf{Q}] [C;Q] 通過自回歸變換器處理時, Q \mathbf{Q} Q 學會關注并從提示 C \mathbf{C} C 中提取相關語義信息。由此得到的 Q \mathbf{Q} Q 被解釋為自回歸模型生成的中間視覺特征或潛在表示,并被訓練以逼近真實圖像特征 X \mathbf{X} X(從 VAE 或 CLIP 獲得)。接下來,我們介紹兩種訓練目標:均方誤差(Mean Squared Error,MSE)和流匹配(Flow Matching),用于學習使 Q \mathbf{Q} Q 與真實圖像嵌入 X \mathbf{X} X 對齊。
MSE 損失? 均方誤差(MSE)損失是一種簡單且廣泛用于學習連續圖像嵌入的目標函數 [7, 31]。給定自回歸模型預測的視覺特征 Q \mathbf{Q} Q 和真實圖像特征 X \mathbf{X} X,我們首先應用一個可學習的線性投影來對齊 Q \mathbf{Q} Q 和 X \mathbf{X} X 的維度。然后,MSE 損失表示為:
L M S E = ∥ X ? W Q ∥ 2 2 \mathcal{L}_{\mathrm{MSE}}=\|\mathbf{X}-\mathbf{W Q}\|_{2}^{2} LMSE?=∥X?WQ∥22?
其中, W \mathbf{W} W 表示可學習的投影矩陣。
流匹配? 需要注意的是,僅使用 MSE 損失只能使預測的圖像特征 Q \mathbf{Q} Q 與目標分布的均值對齊。理想的訓練目標應該對連續圖像表示的概率分布進行建模。我們提出使用流匹配(Flow Matching)[16],這是一種擴散框架,可以通過從先驗分布(例如,高斯分布)迭代傳輸樣本來從目標連續分布中采樣。給定一個真實圖像特征 X 1 \mathbf{X}_{1} X1? 和由自回歸模型編碼的條件 Q \mathbf{Q} Q,在每個訓練步驟中,我們采樣一個時間步 t ~ U ( 0 , 1 ) t \sim \mathcal{U}(0,1) t~U(0,1) 和噪聲 X 0 ~ N ( 0 , 1 ) \mathbf{X}_{0} \sim \mathcal{N}(0,1) X0?~N(0,1)。然后,擴散變換器學會在 Q \mathbf{Q} Q 的條件下,預測在時間步 t t t 沿著 X 1 \mathbf{X}_{1} X1? 方向的“速度” V t = d X t d t \mathbf{V}_{t}=\frac{d \mathbf{X}_{t}}{d t} Vt?=dtdXt??。根據之前的工作 [19],我們通過 X 0 \mathbf{X}_{0} X0? 和 X 1 \mathbf{X}_{1} X1? 之間的簡單線性插值來計算 X t \mathbf{X}_{t} Xt?:
X t = t X 1 + ( 1 ? t ) X 0 \mathbf{X}_{t}=t \mathbf{X}_{1}+(1-t) \mathbf{X}_{0} Xt?=tX1?+(1?t)X0?
而 V t \mathbf{V}_{t} Vt? 的解析解可表示為:
V t = d X t d t = X 1 ? X 0 \mathbf{V}_{t}=\frac{d \mathbf{X}_{t}}{d t}=\mathbf{X}_{1}-\mathbf{X}_{0} Vt?=dtdXt??=X1??X0?
最后,訓練目標定義為:
L Flow? ( θ ) = E ( X 1 , Q ) ~ D , t ~ U ( 0 , 1 ) , X 0 ~ N ( 0 , 1 ) [ ∥ V θ ( X t , Q , t ) ? V t ∥ 2 ] \mathcal{L}_{\text {Flow }}(\theta)=\mathbb{E}_{\left(\mathbf{X}_{1}, \mathbf{Q}\right) \sim \mathcal{D}, t \sim \mathcal{U}(0,1), \mathbf{X}_{0} \sim \mathcal{N}(0,1)}\left[\left\|\mathbf{V}_{\theta}\left(\mathbf{X}_{t}, \mathbf{Q}, t\right)-\mathbf{V}_{t}\right\|^{2}\right] LFlow??(θ)=E(X1?,Q)~D,t~U(0,1),X0?~N(0,1)?[∥Vθ?(Xt?,Q,t)?Vt?∥2]
其中, θ \theta θ 是擴散變換器的參數, V θ ( X t , Q , t ) \mathbf{V}_{\theta}\left(\mathbf{X}_{t}, \mathbf{Q}, t\right) Vθ?(Xt?,Q,t) 表示基于實例( X 1 , Q \mathbf{X}_{1}, \mathbf{Q} X1?,Q)、時間步 t t t 和噪聲 X 0 \mathbf{X}_{0} X0? 預測的速度。
討論? 與離散標記(token)不同,離散標記本質上支持基于采樣的策略來探索多樣化的生成路徑,而連續表示則不具備這一特性。具體而言,在基于均方誤差(MSE)的訓練目標下,對于給定的提示(prompt),預測的視覺特征 Q \mathbf{Q} Q 幾乎變為確定性的。因此,無論視覺解碼器是基于變分自編碼器(VAEs)還是 CLIP + 擴散(CLIP + Diffusion)架構,在多次推理運行中,輸出的圖像幾乎完全相同。這種確定性凸顯了 MSE 目標的一個關鍵局限性:它限制了模型為每個提示生成單一、固定的輸出,從而限制了生成的多樣性。
相比之下,流匹配(Flow Matching)框架使模型能夠繼承擴散過程的隨機性。這使得模型能夠在相同提示的條件下生成多樣化的圖像樣本,從而促進對輸出空間的更廣泛探索。然而,這種靈活性是以增加模型復雜度為代價的。與 MSE 相比,流匹配引入了額外的可學習參數。在我們的實現中,我們使用了擴散變換器(Diffusion Transformer,DiT),并從經驗上發現,擴大其容量能夠帶來顯著的性能提升。
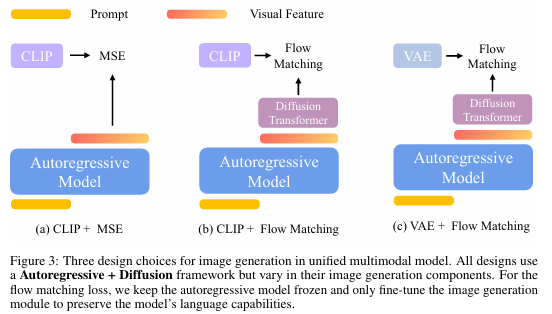
3.3 設計選擇
不同圖像編碼器 - 解碼器架構與訓練目標的組合為圖像生成模型帶來了一系列設計選擇。這些設計選擇如圖3所示,對生成圖像的質量和可控性有著顯著影響。在本節中,我們將總結并分析不同編碼器類型(例如,變分自編碼器(VAEs)與CLIP編碼器)和損失函數(例如,均方誤差(MSE)與流匹配(Flow Matching))所帶來的權衡。
CLIP + MSE? 遵循Emu2 [31]、Seed-X [7]和Metamorph [33]的方法,我們使用CLIP將圖像編碼為64個固定長度且語義豐富的視覺嵌入。自回歸模型被訓練以最小化預測視覺特征 Q \mathbf{Q} Q與真實CLIP嵌入 X X X之間的均方誤差(MSE)損失,如圖3(a)所示。在推理過程中,給定文本提示 C \mathbf{C} C,自回歸模型預測潛在視覺特征 Q \mathbf{Q} Q,隨后將其傳遞給基于擴散的視覺解碼器以重建真實圖像。
CLIP + Flow Matching? 作為MSE損失的替代方案,我們采用流匹配損失來訓練模型以預測真實CLIP嵌入,如圖3(b)所示。給定提示 C C C,自回歸模型生成一系列視覺特征 Q Q Q。這些特征用作條件來引導擴散過程,從而產生預測的CLIP嵌入以逼近真實CLIP特征。本質上,推理流程包含兩個擴散階段:第一階段使用條件視覺特征 Q \mathbf{Q} Q迭代去噪為CLIP嵌入;第二階段則通過基于擴散的視覺解碼器將這些CLIP嵌入轉換為真實圖像。這種方法在第一階段實現了隨機采樣,從而允許圖像生成具有更大的多樣性。
VAE + Flow Matching? 我們還可以使用流匹配損失來預測圖3?中所示的真實VAE特征,這與MetaQuery [23]類似。在推理時,給定提示 C C C,自回歸模型生成視覺特征 Q \mathbf{Q} Q。然后,在 Q \mathbf{Q} Q的條件下,并在每一步迭代去噪,真實圖像由VAE解碼器生成。
VAE + MSE? 由于我們的重點是自回歸 + 擴散框架,因此我們排除了VAE + MSE方法,因為它們沒有包含任何擴散模塊。
實現細節? 為了比較各種設計選擇,我們使用Llama-3.2-1B-Instruct作為自回歸模型。我們的訓練數據包括CC12M [3]、SA-1B [13]和JourneyDB [30],總計約2500萬個樣本。對于CC12M和SA-1B,我們利用LLaVA生成的詳細標題;而對于JourneyDB,我們使用原始標題。使用流匹配損失的圖像生成架構的詳細描述在5.1節中給出。
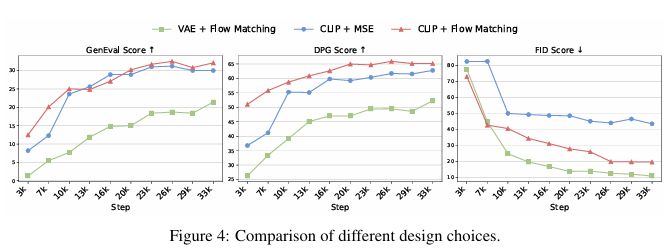
結果? 我們在MJHQ-30k [15]數據集上報告了用于評估視覺美學質量的FID分數[10],以及用于評估提示對齊度的GenEval [8]和DPG-Bench [11]指標。我們大約每3200個訓練步驟繪制一次每種設計選擇的結果。圖4顯示,CLIP + Flow Matching在GenEval和DPG-Bench上均取得了最佳的提示對齊度分數,而VAE + Flow Matching則產生了最低(最佳)的FID分數,表明其美學質量更高。然而,FID存在固有局限性:它量化了與目標圖像分布的風格偏差,并常常忽視真實的生成質量和提示對齊度。事實上,我們在MJHQ-30k數據集上對GPT-4o的FID評估產生了約30.0的分數,這凸顯了FID在圖像生成評估中可能具有誤導性。總體而言,我們的實驗表明CLIP + Flow Matching是最有效的設計選擇。
討論? 在本節中,我們對統一多模態框架內圖像生成的各種設計選擇進行了全面評估。我們的結果清楚地表明,與VAE特征相比,CLIP的特征產生了更緊湊且語義更豐富的表示,從而提高了訓練效率。與像素級特征相比,自回歸模型能更有效地學習這些語義級特征。此外,流匹配被證明是建模圖像分布的更有效訓練目標,從而產生了更大的樣本多樣性和更高的視覺質量。

4 統一多模態模型的訓練策略
基于我們的圖像生成研究,下一步是開發一個能夠同時執行圖像理解和圖像生成的統一模型。對于圖像生成模塊,我們采用CLIP + 流匹配(Flow Matching)方法。由于圖像理解也在CLIP的嵌入空間中運作,我們將這兩個任務對齊到同一個語義空間中,從而實現它們的統一。在此背景下,我們討論兩種實現這種集成的訓練策略。
4.1 聯合訓練與順序訓練
聯合訓練? 圖像理解和圖像生成的聯合訓練在最近的一些工作中已成為常見做法,例如Metamorph [33]、Janus-Pro [4]和Show-o [38]。盡管這些方法在圖像生成方面采用了不同的架構,但它們都通過混合圖像生成和理解的數據來進行多任務學習。
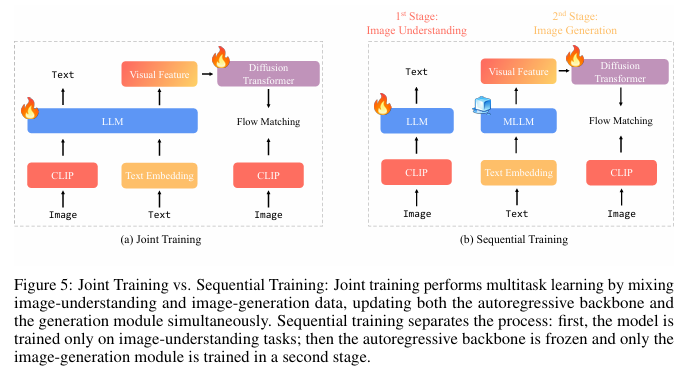
順序訓練? 與同時訓練圖像理解和生成不同,我們采用兩階段的方法。在第一階段,我們僅訓練圖像理解模塊。在第二階段,我們凍結多模態大型語言模型(MLLM)的主干網絡,并僅訓練圖像生成模塊,類似于LMFusion [28]和MetaQuery [23]的做法。
4.2 討論
在聯合訓練設置中,盡管如Metamorph [33]所示,圖像理解和生成任務可能相互受益,但有兩個關鍵因素會影響它們的協同效應:(i)總數據量,以及(ii)圖像理解數據與生成數據之間的數據比例。相比之下,順序訓練提供了更大的靈活性:它允許我們凍結自回歸主干網絡,并保持圖像理解能力。我們可以將所有訓練能力專門用于圖像生成,避免聯合訓練中可能存在的任務間影響。此外,受LMFusion [28]和MetaQuery [23]的啟發,我們將選擇順序訓練來構建我們的統一多模態模型,并將聯合訓練留待未來工作。
5 BLIP3-o:我們最先進的統一多模態模型
基于我們的研究發現,我們采用CLIP + 流匹配(Flow Matching)和順序訓練策略,開發了我們自己最先進的統一多模態模型BLIP3-o。
5.1 模型架構
我們開發了兩種不同規模的模型:一種是在專有數據上訓練的80億參數模型,另一種是僅使用開源數據訓練的40億參數模型。考慮到存在強大的開源圖像理解模型,如Qwen 2.5 VL [2],我們跳過了圖像理解訓練階段,并直接在Qwen 2.5 VL上構建了我們的圖像生成模塊。在80億參數模型中,我們凍結了Qwen2.5-VL-7B-Instruct主干網絡,并訓練了擴散變換器(Diffusion Transformers,DiT),總共有14億可訓練參數。40億參數模型采用了相同的圖像生成架構,但使用Qwen2.5-VL-3B-Instruct作為主干網絡。
擴散變換器(Diffusion Transformer, DiT)架構? 我們采用了Lumina-Next模型[44]的架構作為我們的DiT。Lumina-Next模型基于改進的Next-DiT架構構建,這是一種可擴展且高效的擴散變換器,專為文本到圖像和通用多模態生成而設計。它引入了三維旋轉位置嵌入(3D Rotary Position Embedding),以在不依賴可學習位置標記的情況下,對時間、高度和寬度上的時空結構進行編碼。每個變換器塊都采用了夾層歸一化(注意力/多層感知機前后均使用RMSNorm)和分組查詢注意力(Grouped-Query Attention)來增強穩定性和減少計算量。基于經驗結果,這種架構能夠實現快速、高質量的生成。
5.2 訓練方案
階段1:圖像生成的預訓練? 對于80億參數模型,我們將約2500萬開源數據(CC12M [3]、SA-1B [13]和JourneyDB [30])與額外的3000萬張專有圖像相結合。所有圖像標題均由Qwen2.5-VL-7B-Instruct生成,提供詳細的描述,平均長度為120個標記。為了提高對不同提示長度的泛化能力,我們還從CC12M [3]中包含了約10%(600萬)的較短標題(約20個標記)。對于完全開源的40億參數模型,我們使用了來自CC12M [3]、SA-1B [13]和JourneyDB [30]的2500萬公開圖像,每張圖像都配有相同的詳細標題。我們還混合了來自CC12M [3]的約10%(300萬)的短標題。為了支持研究社區,我們發布了2500萬條詳細標題和300萬條短標題。
階段2:圖像生成的指令微調? 在圖像生成預訓練階段之后,我們觀察到模型存在以下一些弱點:
- 生成復雜的人類手勢,例如“一個人正在拉弓射箭”。
- 生成常見物體,如各種水果和蔬菜。
- 生成地標,例如“金門大橋”。
- 生成簡單文本,例如“在街道表面上寫有‘Salesforce’這個詞”。
盡管這些類別本應在預訓練期間被涵蓋,但由于我們預訓練語料庫的規模有限,它們并未得到充分處理。為了解決這一問題,我們針對這些特定領域進行了指令微調。對于每個類別,我們提示GPT-4o生成大約10,000個提示-圖像對,從而創建一個有針對性的數據集,以提高模型處理這些情況的能力。為了提高視覺美學質量,我們還從JourneyDB [30]和DALL-E 3中提取提示來擴展數據。這一過程產生了大約60,000個高質量提示-圖像對的精選集合。我們還發布了這60,000個指令微調數據集。
5.3 結果
為了進行基線比較,我們包括了以下統一模型:EMU2 Chat [31]、Chameleon [32]、Seed-X [7]、VILA-U [36]、LMfusion [28]、Show-o [38]、EMU3 [34]、MetaMorph [33]、TokenFlow [25]、Janus [35]和Janus-Pro [4]。
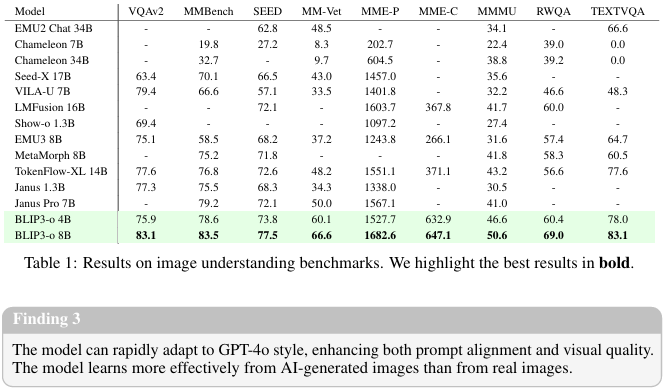
圖像理解?:在圖像理解任務中,我們在VQAv2 [9]、MMBench [20]、SeedBench [14]、MM-Vet [41]、MME-Perception和MME-Cognition [6]、MMMU [42]、TextVQA [29]和RealWorldQA [37]等基準上評估了模型性能。如表1所示,我們的BLIP3-o 8B在大多數基準測試中取得了最佳性能。
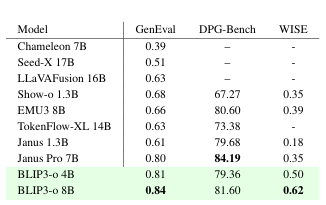
圖像生成?:在圖像生成基準測試中,我們報告了GenEval [8]和DPG-Bench [11]來衡量提示對齊度,以及WISE [22]來評估世界知識推理能力。如表2所示,BLIP3-o 8B在GenEval上取得了0.84的分數,在WISE上取得了0.62的分數,但在DPG-Bench上的分數較低。由于基于模型的DPG-Bench評估可能不可靠,我們在下一節中通過人工研究補充了所有DPG-Bench提示的結果。此外,我們還發現指令微調數據集BLIP3o-60k能立即帶來提升:僅使用60k提示-圖像對,提示對齊度和視覺美學均顯著提高,許多生成瑕疵也迅速減少。盡管該指令微調數據集無法完全解決一些復雜情況(如復雜人類手勢生成),但它顯著提升了整體圖像質量。
5.4 人工研究
在本節中,我們進行了一項人工評估,比較了BLIP3-o 8B和Janus Pro 7B在約1000個來自DPG-Bench的提示上的表現。對于每個提示,標注員根據兩個指標對圖像對進行并排比較:
- 視覺質量?:指示為“所有圖像均使用不同方法從同一文本輸入生成。請根據視覺吸引力(如布局、清晰度、物體形狀和整體整潔度)選擇您最喜歡的圖像。”
- 提示對齊度?:指示為“所有圖像均使用不同方法從同一文本輸入生成。請選擇圖像與文本內容對齊度最高的圖像。”
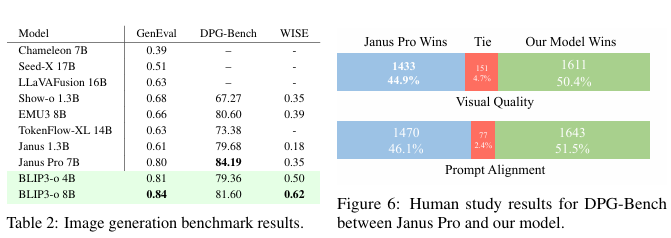
每個指標分別在兩輪中進行評估,每個標準產生約3000個判斷。如圖6所示,盡管Janus Pro在表2中取得了更高的DPG分數,但BLIP3-o在視覺質量和提示對齊度方面均優于Janus Pro。視覺質量和提示對齊度的p值分別為5.05e-06和1.16e-05,表明我們的模型在統計上顯著優于Janus Pro。
6 未來工作
目前,我們正在將我們的統一多模態模型擴展到下游任務,如圖像編輯、多輪視覺對話以及交錯生成等。作為第一步,我們將重點關注圖像重建:
將圖像輸入到圖像理解視覺編碼器中,然后通過圖像生成模型進行重建,以無縫銜接圖像理解和生成。基于這一能力,我們將收集指令微調數據集,以使模型適應各種下游應用。
7 相關工作
近期的研究強調了統一多模態模型(既能進行圖像理解又能進行圖像生成)作為一種有前景的研究方向。例如,SEED-X [7]、Emu-2 [31]和MetaMorph [33]通過回歸損失來訓練圖像特征,而Chameleon [32]、Show-o [38]、EMU3 [34]和Janus [35, 4]則采用了自回歸離散標記預測范式。與此同時,DreamLLM [5]和Transfusion [43]利用擴散目標進行視覺生成。據我們所知,我們對自回歸和擴散框架中的設計選擇進行了首次系統性研究。
關于統一模型訓練策略,LMFusion [28]基于凍結的多模態大語言模型(MLLM)主干網絡,同時結合了使用Transfusion [43]進行圖像生成的變換器模塊。我們的方法與LMFusion的一個關鍵相似之處在于,兩種方法都凍結了MLLM主干網絡,并僅訓練圖像特定的組件。然而,LMFusion結合了并行的變換器模塊用于圖像擴散,顯著擴大了模型規模。相比之下,我們的方法引入了一個相對輕量級的擴散頭以實現圖像生成,從而保持了更易于管理的整體模型規模。同時期的工作MetaQuery [23]也使用可學習的查詢來橋接凍結的預訓練MLLM和預訓練的擴散模型,但擴散模型采用的是變分自編碼器(VAE)+流匹配(Flow Matching)策略,而不是我們BLIP3-o中更高效的CLIP+流匹配策略。
8 結論
總之,我們對混合自回歸和擴散架構在統一多模態建模中的設計選擇進行了首次系統性探索,評估了三個關鍵方面:圖像表示(CLIP特征與VAE特征)、訓練目標(流匹配與均方誤差)以及訓練策略(聯合訓練與順序訓練)。我們的實驗表明,CLIP嵌入與流匹配損失的結合既提高了訓練效率,又提升了輸出質量。基于這些見解,我們引入了BLIP3-o,這是一系列最先進的統一模型,并輔以一個包含60k指令微調數據集BLIP3o-60k,顯著提高了提示對齊度和視覺美學效果。我們正在積極研究統一模型在迭代圖像編輯、視覺對話以及逐步視覺推理等應用中的潛力。
附錄A 圖2中使用的提示詞
- 一輛藍色寶馬汽車停在一堵黃色磚墻前。
- 一名女子在陽光明媚的小巷中旋轉,小巷兩旁是色彩斑斕的墻壁,她的夏日連衣裙在旋轉中閃耀著光芒。
- 一群朋友正在野餐。
- 一片茂密的熱帶瀑布,在反光的金屬路標上寫著“深度學習”。
- 一只藍松鴉站在一大籃彩虹色馬卡龍上。
- 一只海龜在珊瑚礁上方游動。
- 一名年輕的紅發女子戴著草帽,站在金色的麥田里。
- 三個人。
- 一名男子在電話中興奮地交談,嘴巴快速動著。
- 日出時的野花草地,“BLIP3o”投影在霧蒙蒙的表面上。
- 一個彩虹色的冰洞,在潮濕的沙灘上畫著“Salesforce”。
- 一個巨大的玻璃瓶,里面裝著一片微型的夏日森林。
- 漫步在紐約市曼哈頓冰凍的街道上——冰凍的樹木和冰凍的帝國大廈。
- 一座燈塔孤獨地矗立在暴風雨的海面上。
- 一只孤獨的狼在閃爍的北極光下。
- 一只發光的鹿在霓虹燈照亮的未來叢林中行走。
- 一對情侶手牽手漫步在充滿活力的秋日公園中,落葉輕輕地在他們周圍飄落。
- 一艘好奇的船,形狀像一只巨大的綠色西蘭花,在明亮的陽光下漂浮在波光粼粼的海面上。
- 路上寫著“Transformer”。
- 藍色T恤上寫著“Diffusion”。
- 一只金毛尋回犬平靜地躺在木制門廊上,周圍散落著秋天的落葉。
- 一只浣熊戴著偵探帽,用放大鏡解謎。
- 一位賽博朋克風格的女子,身上散發著發光的紋身,機械手臂在全息天空下。
- 雪山山頂在清澈的高山湖泊中的倒影,形成了一個完美的鏡像。
- 一名男子在陽光明媚的陽臺上喝咖啡,陽臺上擺滿了盆栽植物,他穿著亞麻衣服和太陽鏡,沐浴在晨光中。





![[面試精選] 0076. 最小覆蓋子串](http://pic.xiahunao.cn/[面試精選] 0076. 最小覆蓋子串)




)

)






課堂 1--5,這五節主要講解 mysql 的概念,定義,下載安裝與卸載)