?
🤵?♂? 個人主頁:@艾派森的個人主頁
?🏻作者簡介:Python學習者
🐋 希望大家多多支持,我們一起進步!😄
如果文章對你有幫助的話,
歡迎評論 💬點贊👍🏻 收藏 📂加關注+
目錄
1.項目背景
2.數據集介紹
3.技術工具
4.實驗過程
4.1導入數據
4.2數據預處理?
4.3數據可視化
4.4snowmlp情感分析
源代碼
1.項目背景
????????在智能手機市場日益繁榮的今天,紅米與華為手機作為國產手機品牌的佼佼者,憑借其各自獨特的品牌魅力和技術實力,贏得了廣泛的用戶群體和高度關注。隨著技術的不斷進步和消費者需求的日益多樣化,用戶對手機的期望已不僅限于基本的通訊功能,更涵蓋了性能、拍照、續航、用戶體驗等多個方面。因此,深入探究紅米與華為手機在用戶長期使用過程中的實際表現,尤其是用戶評論中所反映出的真實反饋,對于理解市場需求、優化產品設計及提升用戶體驗具有重要意義。
????????本實驗的背景正是基于這樣的市場環境和技術發展趨勢。我們旨在通過收集并分析紅米與華為手機的用戶評論,全面、客觀地揭示兩款手機在性能、拍照、續航、用戶體驗等多個維度的真實表現。這些用戶評論來自不同渠道,包括官方網站、社交媒體、電商平臺等,涵蓋了廣泛的用戶群體和多樣化的使用場景,為實驗提供了豐富而真實的數據基礎。
????????通過本次實驗,我們期望能夠解答以下問題:在長期使用過程中,紅米與華為手機在哪些方面表現出色?哪些方面仍有改進空間?用戶對于兩款手機的整體滿意度如何?以及用戶評論中反映出的共同需求和痛點是什么?基于以上背景,本實驗將采用文本挖掘、情感分析等方法,對用戶評論進行深入挖掘和分析,以揭示出隱藏在海量數據背后的有價值信息。通過對比紅米與華為手機的用戶評論,我們可以更加清晰地看到兩款手機在市場上的競爭態勢和用戶需求的差異,為手機廠商提供有益的參考和啟示。同時,本次實驗也將為消費者在選擇手機時提供更加全面、客觀的參考依據,幫助他們根據自己的實際需求和預算做出更加明智的決策。
2.數據集介紹
本次實驗數據集來源于京東網,采用Python爬蟲獲取了紅米和華為手機的用戶評論,共計1570條數據,10個變量,變量含義分別為用戶ID、用戶昵稱、IP屬地、評論時間、產品顏色、產品大小、評分、評論點贊量、評論回復量和評論內容。

3.技術工具
Python版本:3.9
代碼編輯器:jupyter notebook
4.實驗過程
4.1導入數據


查看數據大小

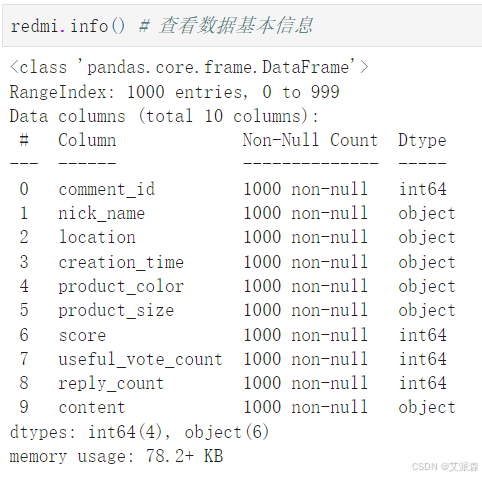
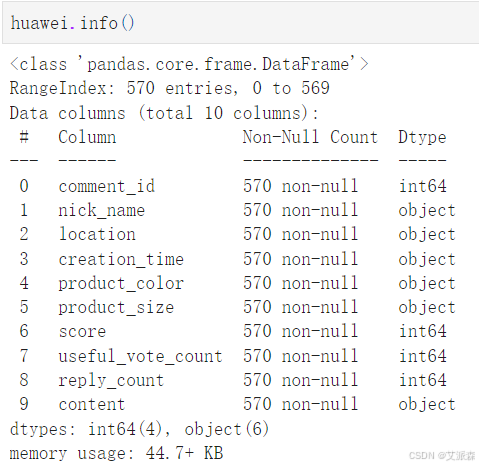
查看數據基本信息
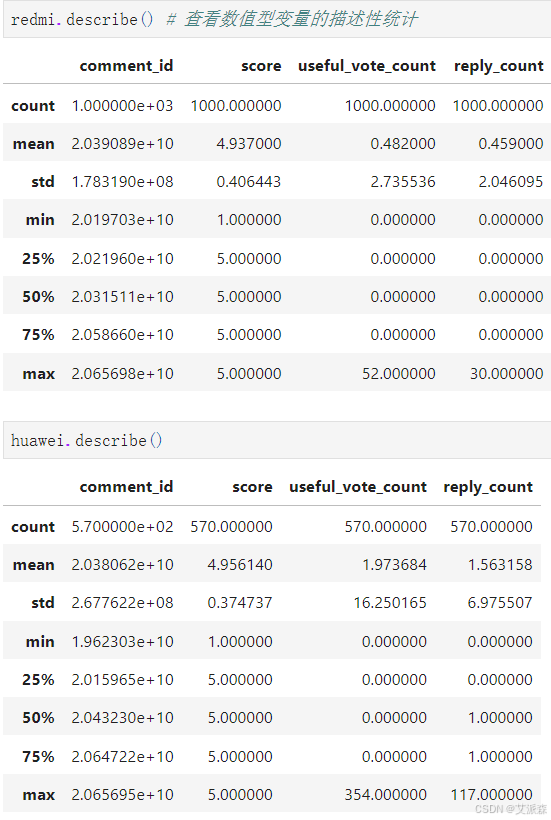
查看數值型變量的描述性統計
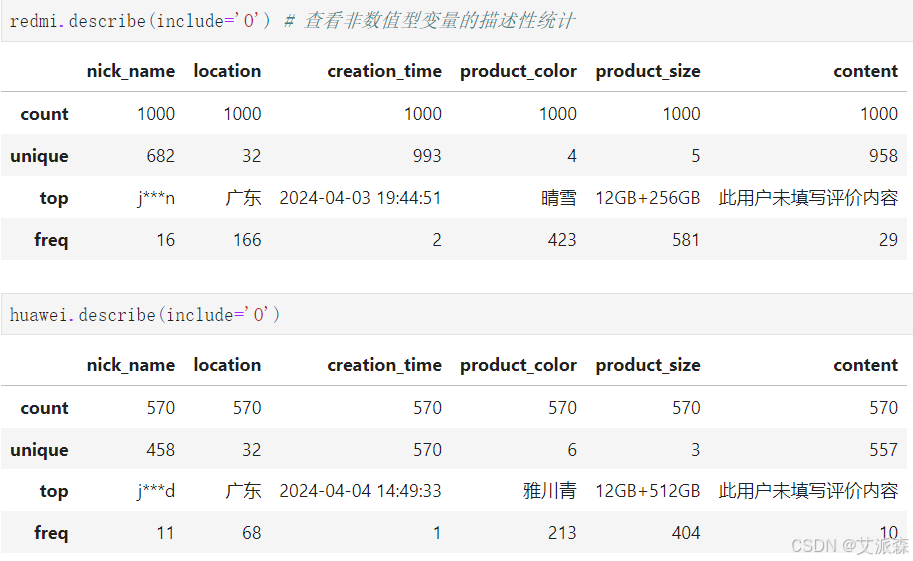
查看非數值型變量的描述性統計
4.2數據預處理?
統計缺失值情況
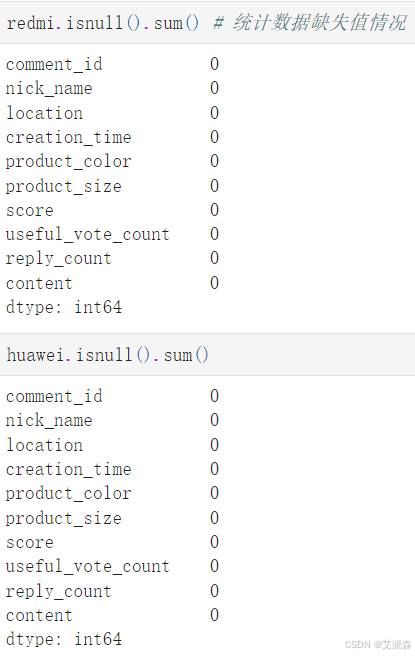
發現沒有缺失值
統計重復值情況

發現紅米數據集中存在7個重復值,刪除即可


4.3數據可視化










因與地圖相關的圖片會被和諧,所有這里自行運行即可!?
因與地圖相關的圖片會被和諧,所有這里自行運行即可!?
import collections
import stylecloud
import re
import jieba
from PIL import Imagedef draw_WorldCloud(df,pic_name,color='white'):data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])# 文本預處理 :去除一些無用的字符只提取出中文出來new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "".join(new_data)# 文本分詞seg_list_exact = jieba.cut(new_data)result_list = []with open('停用詞庫.txt', encoding='utf-8') as f: #可根據需要打開停用詞庫,然后加上不想顯示的詞語con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉讀取每一行數據的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word)word_counts = collections.Counter(result_list)# 詞頻統計:獲取前100最高頻的詞word_counts_top = word_counts.most_common(100)with open(f'{pic_name}詞頻統計.txt','w',encoding='utf-8')as f:for i in word_counts_top:f.write(str(i[0]))f.write('\t')f.write(str(i[1]))f.write('\n')print(word_counts_top)# 繪制詞云圖stylecloud.gen_stylecloud(text=' '.join(result_list), collocations=False, # 是否包括兩個單詞的搭配(二字組)font_path=r'C:\Windows\Fonts\msyh.ttc', #設置字體,參考位置為 size=800, # stylecloud 的大小palette='cartocolors.qualitative.Bold_7', # 調色板background_color=color, # 背景顏色icon_name='fas fa-cloud', # 形狀的圖標名稱 gradient='horizontal', # 梯度方向max_words=2000, # stylecloud 可包含的最大單詞數max_font_size=150, # stylecloud 中的最大字號stopwords=True, # 布爾值,用于篩除常見禁用詞output_name=f'{pic_name}.png') # 輸出圖片# 打開圖片展示img=Image.open(f'{pic_name}.png')img.show()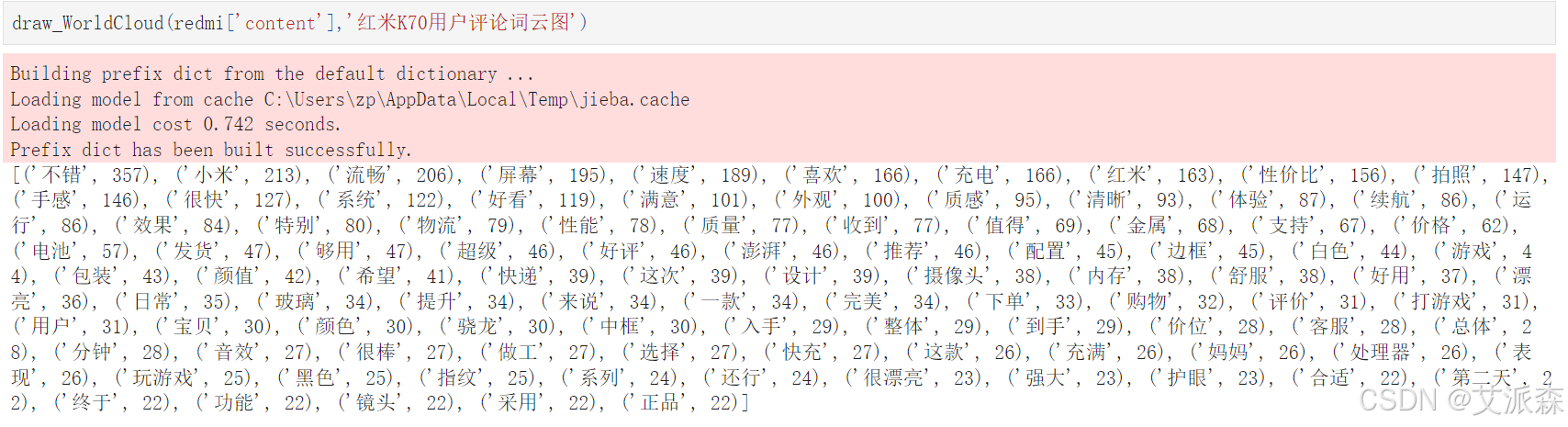



4.4snowmlp情感分析




?



?




源代碼
import pandas as pd
import matplotlib.pylab as plt
import numpy as np
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解決中文顯示
plt.rcParams['axes.unicode_minus'] = False #解決符號無法顯示
import warnings
warnings.filterwarnings('ignore')redmi = pd.read_csv('JD_comment_100075799823--0-時間排序.csv')
huawei = pd.read_csv('JD_comment_100064695864--0-時間排序.csv')
redmi.head(5)
huawei.head()
redmi.shape # 查看數據大小
huawei.shape
redmi.info() # 查看數據基本信息
huawei.info()
redmi.describe() # 查看數值型變量的描述性統計
huawei.describe()
redmi.describe(include='O') # 查看非數值型變量的描述性統計
huawei.describe(include='O')
redmi.isnull().sum() # 統計數據缺失值情況
huawei.isnull().sum()
redmi.duplicated().sum() # 統計數據重復值情況
huawei.duplicated().sum()
redmi.drop_duplicates(inplace=True) # 刪除重復值
# 去除評論為“此用戶未及時填寫評價內容”的數據
redmi = redmi[redmi['content']!='此用戶未填寫評價內容']
huawei = huawei[huawei['content']!='此用戶未填寫評價內容']
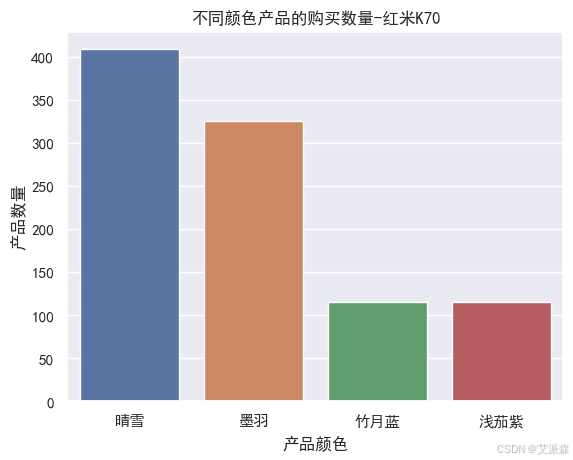
# 不同顏色產品的購買數量
sns.countplot(redmi['product_color'])
plt.xticks()
plt.xlabel('產品顏色')
plt.ylabel('產品數量')
plt.title('不同顏色產品的購買數量-紅米K70')
plt.show()
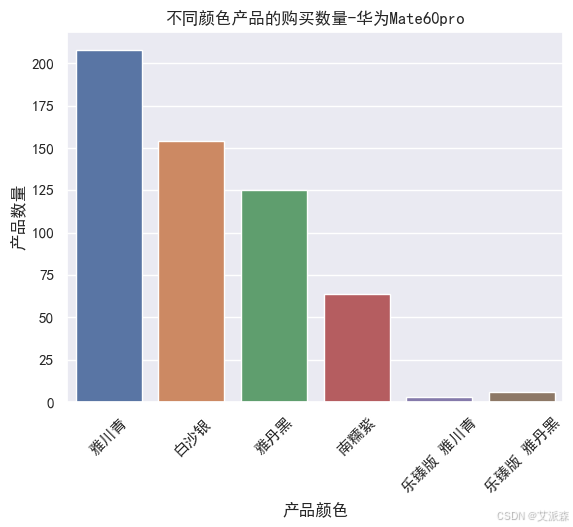
# 不同顏色產品的購買數量
sns.countplot(huawei['product_color'])
plt.xticks(rotation=45)
plt.xlabel('產品顏色')
plt.ylabel('產品數量')
plt.title('不同顏色產品的購買數量-華為Mate60pro')
plt.show()
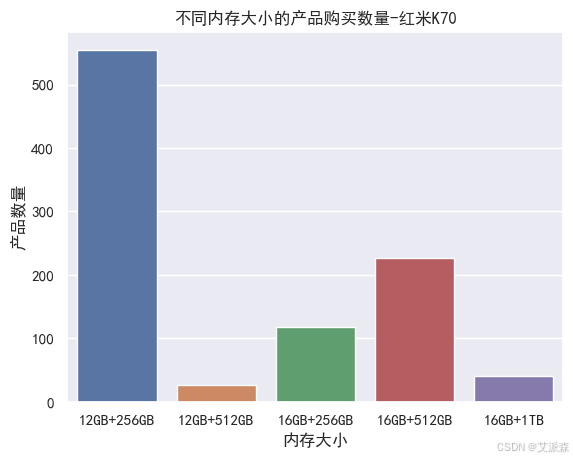
# 不同內存大小的產品購買數量
sns.countplot(redmi['product_size'])
plt.xlabel('內存大小')
plt.ylabel('產品數量')
plt.title('不同內存大小的產品購買數量-紅米K70')
plt.show()
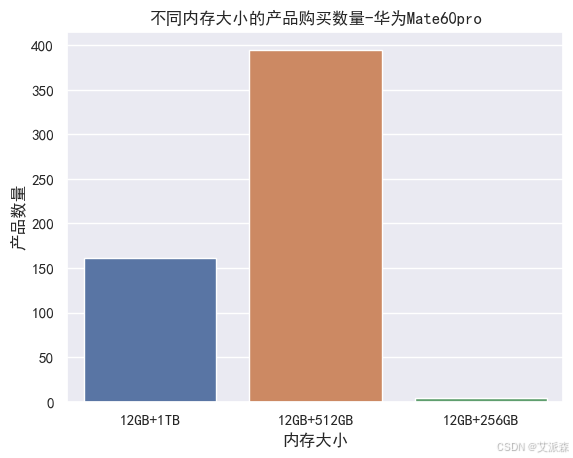
# 不同內存大小的產品購買數量
sns.countplot(huawei['product_size'])
plt.xlabel('內存大小')
plt.ylabel('產品數量')
plt.title('不同內存大小的產品購買數量-華為Mate60pro')
plt.show()
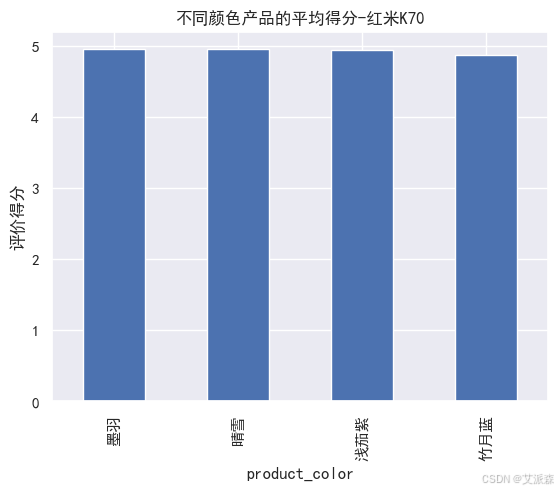
# 不同顏色產品的平均得分-紅米K70
redmi.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks()
plt.ylabel('評價得分')
plt.title('不同顏色產品的平均得分-紅米K70')
plt.show()
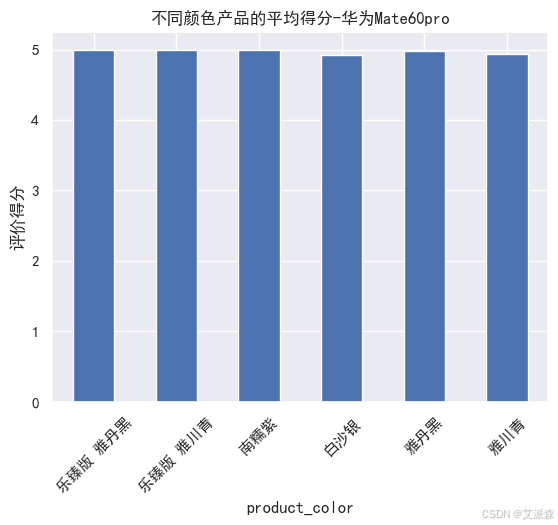
# 不同顏色產品的平均得分-華為Mate60pro
huawei.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks(rotation=45)
plt.ylabel('評價得分')
plt.title('不同顏色產品的平均得分-華為Mate60pro')
plt.show()
# 不同型號產品的平均得分-紅米K70
redmi.groupby('product_size').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('評價得分')
plt.title('不同型號產品的平均得分-紅米K70')
plt.show()
# 不同型號產品的平均得分-華為Mate60pro
huawei.groupby('product_size').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('評價得分')
plt.title('不同型號產品的平均得分-華為Mate60pro')
plt.show()
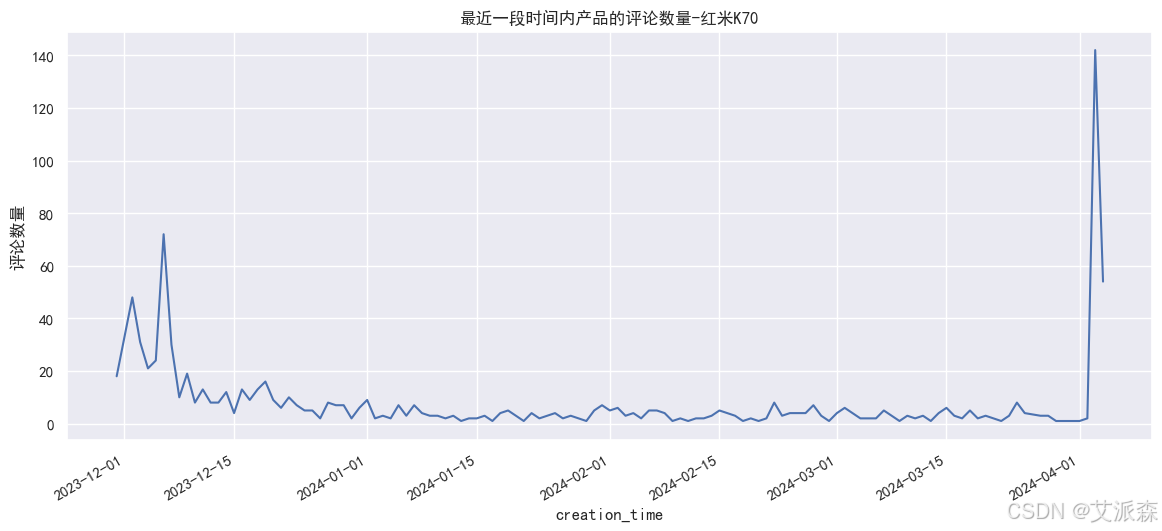
# 最近一段時間內產品的評論數量
redmi['creation_time'] = redmi['creation_time'].astype('datetime64[D]')
plt.figure(figsize=(14,6))
redmi.groupby(redmi['creation_time']).count()['content'].plot()
plt.ylabel('評論數量')
plt.title('最近一段時間內產品的評論數量-紅米K70')
plt.show()
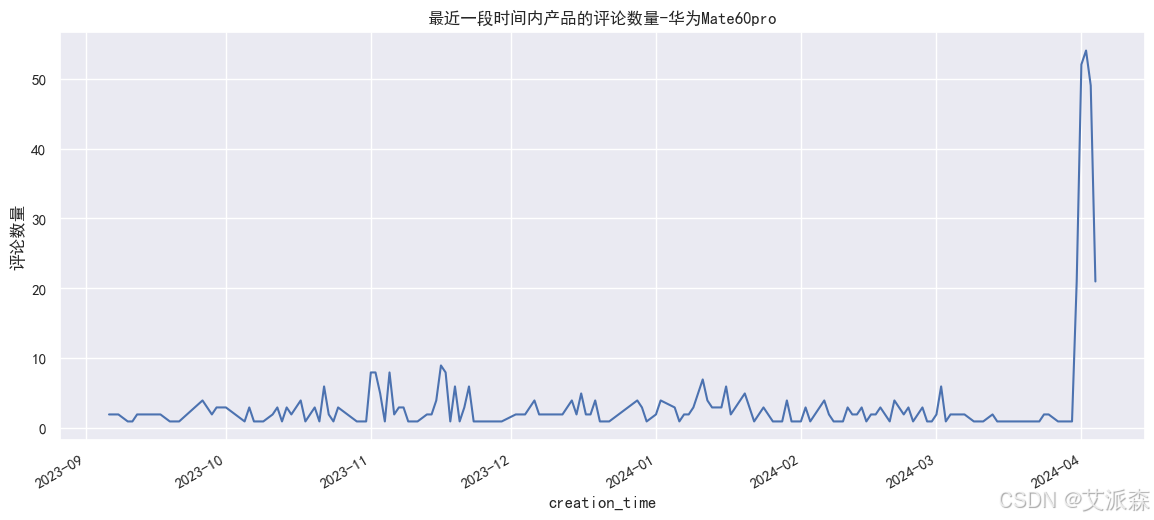
# 最近一段時間內產品的評論數量
huawei['creation_time'] = huawei['creation_time'].astype('datetime64[D]')
plt.figure(figsize=(14,6))
huawei.groupby(huawei['creation_time']).count()['content'].plot()
plt.ylabel('評論數量')
plt.title('最近一段時間內產品的評論數量-華為Mate60pro')
plt.show()
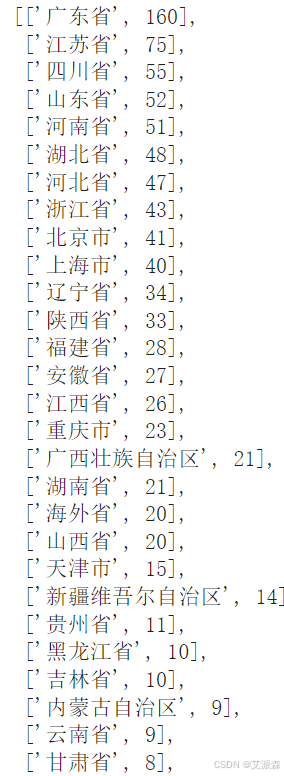
# 處理location變量獲取地圖數據-紅米K70
result = []
for x,y in zip(redmi['location'].value_counts().index.to_list(),redmi['location'].value_counts().values.tolist()):if x == '新疆':result.append(['新疆維吾爾自治區',y])elif x == '西藏':result.append(['西藏自治區',y])elif x == '內蒙古':result.append(['內蒙古自治區',y])elif x == '寧夏':result.append(['寧夏回族自治區',y])elif x in ['重慶','北京','天津','上海']:result.append([x + '市',y])elif x == '廣西':result.append(['廣西壯族自治區',y])elif x == '港澳':result.append(['香港特別行政區',y])else:result.append([x+'省',y])
result
from pyecharts.charts import *
from pyecharts import options as opts
map = Map()
map.add('各省份購買數量-紅米K70',result,maptype='china',is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=100,min_=1)
)
map.render(path='各城市崗位數量分布-紅米K70.html')
map.render_notebook()
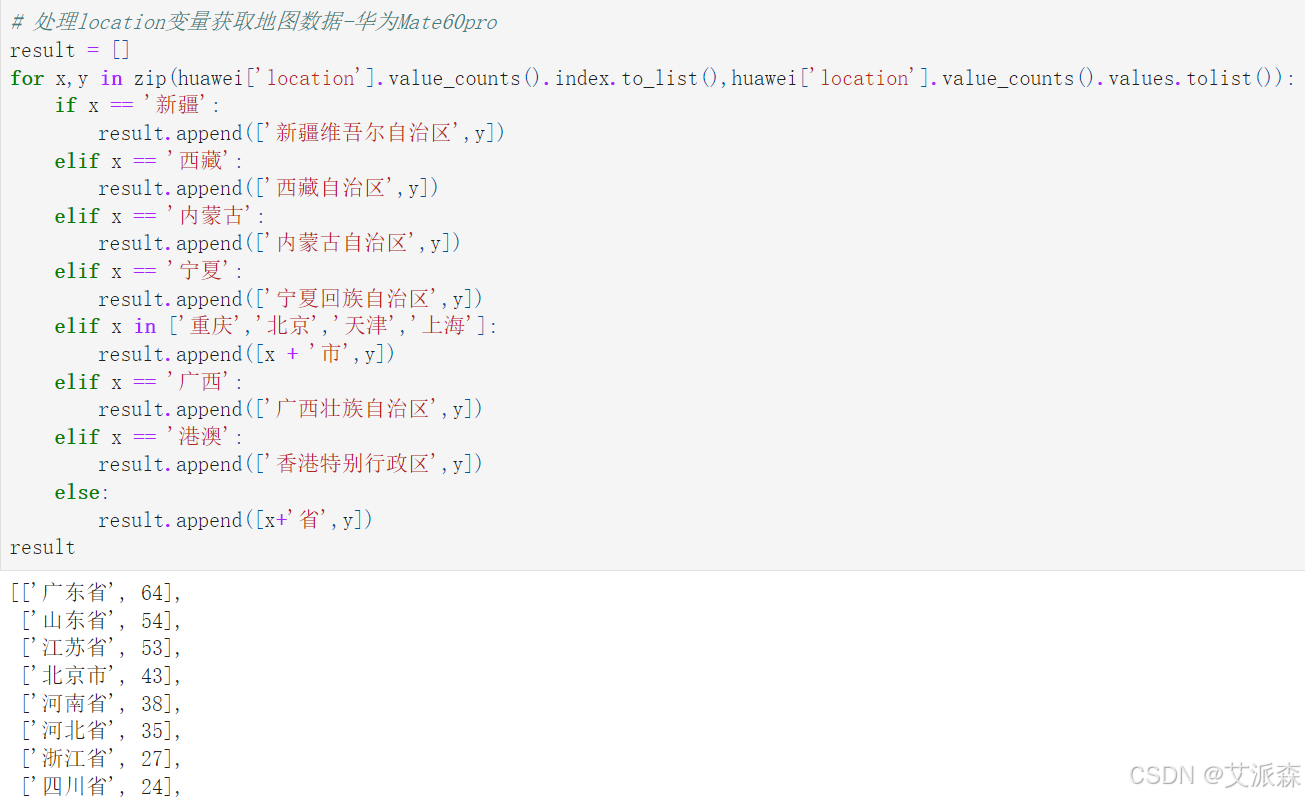
# 處理location變量獲取地圖數據-華為Mate60pro
result = []
for x,y in zip(huawei['location'].value_counts().index.to_list(),huawei['location'].value_counts().values.tolist()):if x == '新疆':result.append(['新疆維吾爾自治區',y])elif x == '西藏':result.append(['西藏自治區',y])elif x == '內蒙古':result.append(['內蒙古自治區',y])elif x == '寧夏':result.append(['寧夏回族自治區',y])elif x in ['重慶','北京','天津','上海']:result.append([x + '市',y])elif x == '廣西':result.append(['廣西壯族自治區',y])elif x == '港澳':result.append(['香港特別行政區',y])else:result.append([x+'省',y])
result
from pyecharts.charts import *
from pyecharts import options as opts
map = Map()
map.add('各省份購買數量-華為Mate60pro',result,maptype='china',is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=50,min_=1)
)
map.render(path='各城市崗位數量分布-華為Mate60pro.html')
map.render_notebook()
import collections
import stylecloud
import re
import jieba
from PIL import Imagedef draw_WorldCloud(df,pic_name,color='white'):data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])# 文本預處理 :去除一些無用的字符只提取出中文出來new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "".join(new_data)# 文本分詞seg_list_exact = jieba.cut(new_data)result_list = []with open('停用詞庫.txt', encoding='utf-8') as f: #可根據需要打開停用詞庫,然后加上不想顯示的詞語con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉讀取每一行數據的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word)word_counts = collections.Counter(result_list)# 詞頻統計:獲取前100最高頻的詞word_counts_top = word_counts.most_common(100)with open(f'{pic_name}詞頻統計.txt','w',encoding='utf-8')as f:for i in word_counts_top:f.write(str(i[0]))f.write('\t')f.write(str(i[1]))f.write('\n')print(word_counts_top)# 繪制詞云圖stylecloud.gen_stylecloud(text=' '.join(result_list), collocations=False, # 是否包括兩個單詞的搭配(二字組)font_path=r'C:\Windows\Fonts\msyh.ttc', #設置字體,參考位置為 size=800, # stylecloud 的大小palette='cartocolors.qualitative.Bold_7', # 調色板background_color=color, # 背景顏色icon_name='fas fa-cloud', # 形狀的圖標名稱 gradient='horizontal', # 梯度方向max_words=2000, # stylecloud 可包含的最大單詞數max_font_size=150, # stylecloud 中的最大字號stopwords=True, # 布爾值,用于篩除常見禁用詞output_name=f'{pic_name}.png') # 輸出圖片# 打開圖片展示img=Image.open(f'{pic_name}.png')img.show()
draw_WorldCloud(redmi['content'],'紅米K70用戶評論詞云圖')
draw_WorldCloud(huawei['content'],'華為Mate60pro用戶評論詞云圖')
snowmlp情感分析
#加載情感分析模塊
from snownlp import SnowNLP
# 遍歷每條評論進行預測
values=[SnowNLP(i).sentiments for i in redmi['content']]
#輸出積極的概率,大于0.5積極的,小于0.5消極的
#myval保存預測值
myval=[]
good=0
mid=0
bad=0
for i in values:if (i>=0.7):myval.append("積極")good=good+1elif 0.2<i<0.7:myval.append("中性")mid+=1else:myval.append("消極")bad=bad+1
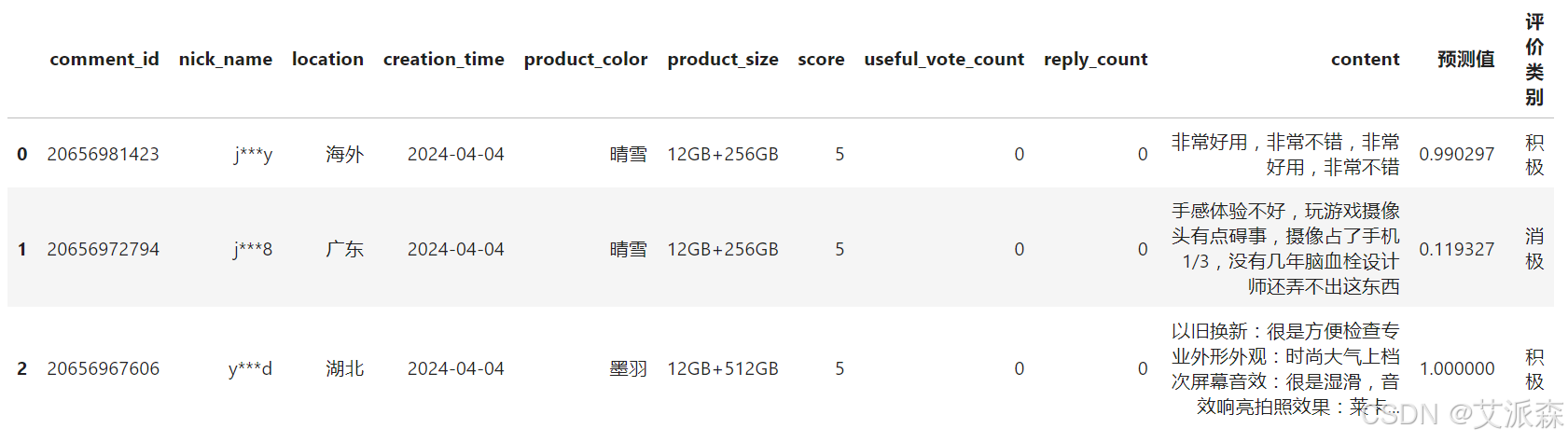
redmi['預測值']=values
redmi['評價類別']=myval
redmi.head(3)
rate=good/(good+bad+mid)
print('好評率','%.f%%' % (rate * 100)) #格式化為百分比
#作圖
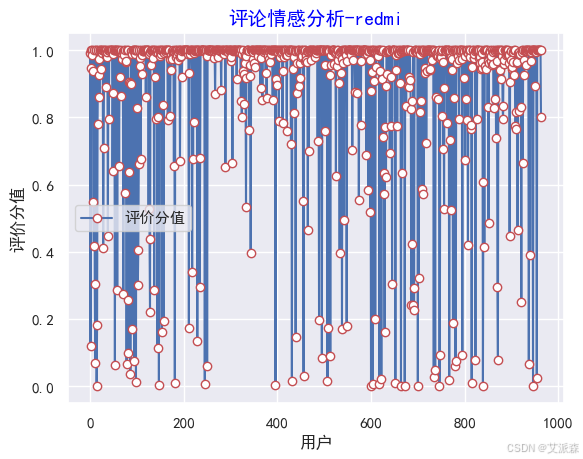
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'評價分值')
plt.xlabel('用戶')
plt.ylabel('評價分值')
# 讓圖例生效
plt.legend()
#添加標題
plt.title('評論情感分析-redmi',family='SimHei',size=14,color='blue')
plt.show()
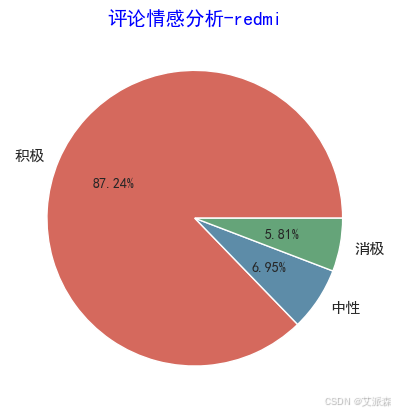
y = redmi['評價類別'].value_counts().values.tolist()
plt.pie(y,labels=['積極','中性','消極'], # 設置餅圖標簽colors=["#d5695d", "#5d8ca8", "#65a479"], # 設置餅圖顏色autopct='%.2f%%', # 格式化輸出百分比)
plt.title('評論情感分析-redmi',family='SimHei',size=14,color='blue')
plt.show()
draw_WorldCloud(redmi[redmi['評價類別']=='積極']['content'],'紅米K70用戶評論詞云圖-好評')
draw_WorldCloud(redmi[redmi['評價類別']=='消極']['content'],'紅米K70用戶評論詞云圖-差評')
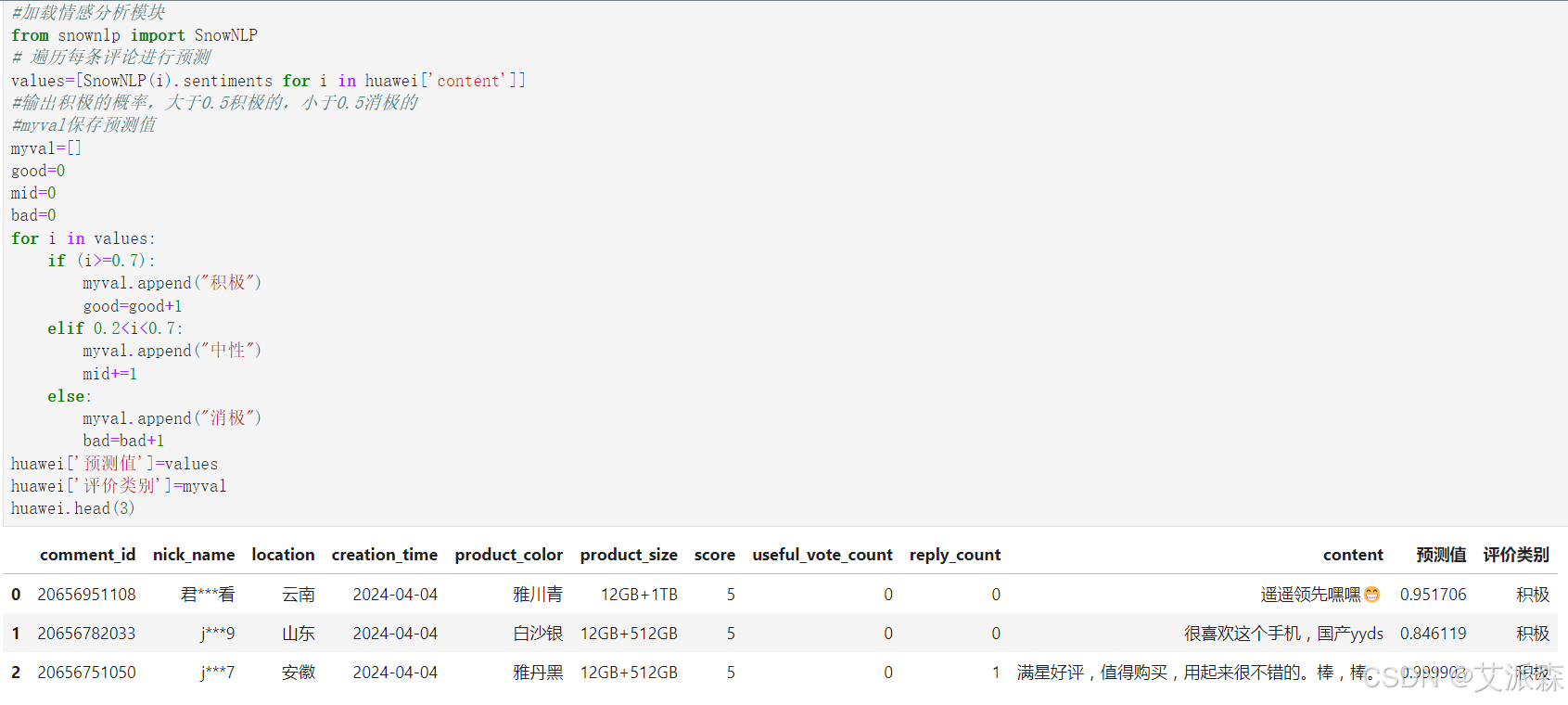
#加載情感分析模塊
from snownlp import SnowNLP
# 遍歷每條評論進行預測
values=[SnowNLP(i).sentiments for i in huawei['content']]
#輸出積極的概率,大于0.5積極的,小于0.5消極的
#myval保存預測值
myval=[]
good=0
mid=0
bad=0
for i in values:if (i>=0.7):myval.append("積極")good=good+1elif 0.2<i<0.7:myval.append("中性")mid+=1else:myval.append("消極")bad=bad+1
huawei['預測值']=values
huawei['評價類別']=myval
huawei.head(3)
rate=good/(good+bad+mid)
print('好評率','%.f%%' % (rate * 100)) #格式化為百分比
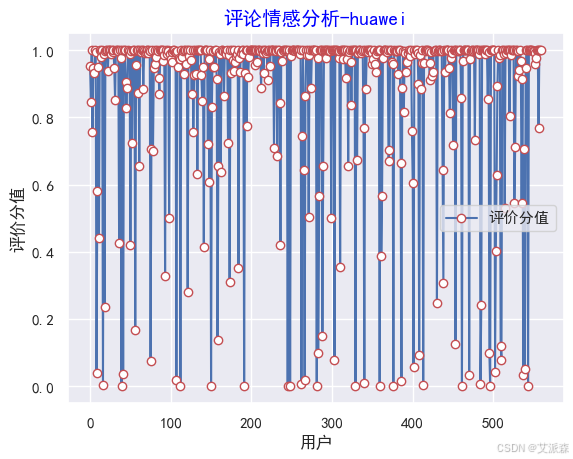
#作圖
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'評價分值')
plt.xlabel('用戶')
plt.ylabel('評價分值')
# 讓圖例生效
plt.legend()
#添加標題
plt.title('評論情感分析-huawei',family='SimHei',size=14,color='blue')
plt.show()
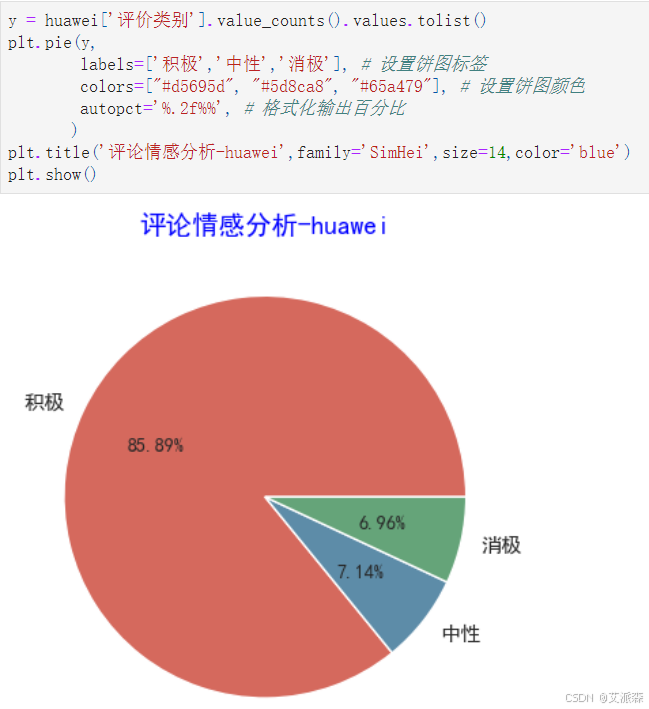
y = huawei['評價類別'].value_counts().values.tolist()
plt.pie(y,labels=['積極','中性','消極'], # 設置餅圖標簽colors=["#d5695d", "#5d8ca8", "#65a479"], # 設置餅圖顏色autopct='%.2f%%', # 格式化輸出百分比)
plt.title('評論情感分析-huawei',family='SimHei',size=14,color='blue')
plt.show()
draw_WorldCloud(huawei[huawei['評價類別']=='積極']['content'],'華為Mate60pro用戶評論詞云圖-好評')
draw_WorldCloud(huawei[huawei['評價類別']=='消極']['content'],'華為Mate60pro用戶評論詞云圖-差評')
LDA主題分析
import re
import jiebadef chinese_word_cut(mytext):# 文本預處理 :去除一些無用的字符只提取出中文出來new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)new_data = " ".join(new_data)# 文本分詞seg_list_exact = jieba.cut(new_data)result_list = []with open('停用詞庫.txt', encoding='utf-8') as f: # 可根據需要打開停用詞庫,然后加上不想顯示的詞語con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉讀取每一行數據的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word) return " ".join(result_list)test = '在這里選購安全方便快捷💜,快遞小哥態度非常好,這個價格非常給力💪,十分推薦,會繼續回購😃大品牌!值得信賴!效果超級好!貴有貴的道理!很棒的商品!'
chinese_word_cut(test)
# 中文分詞
redmi["content_cutted"] = redmi.content.apply(chinese_word_cut)
redmi.head()
# 中文分詞
huawei["content_cutted"] = huawei.content.apply(chinese_word_cut)
huawei.head()
import tomotopy as tpdef find_k(docs, min_k=1, max_k=20, min_df=2):# min_df 詞語最少出現在2個文檔中scores = []for k in range(min_k, max_k):mdl = tp.LDAModel(min_df=min_df, k=k, seed=555)for words in docs:if words:mdl.add_doc(words)mdl.train(20)coh = tp.coherence.Coherence(mdl)scores.append(coh.get_score())plt.plot(range(min_k, max_k), scores)plt.xlabel("number of topics")plt.ylabel("coherence")plt.show()
find_k(docs=redmi['content_cutted'], min_k=1, max_k=10, min_df=2)
find_k(docs=huawei['content_cutted'], min_k=1, max_k=10, min_df=2)
# 初始化LDA
mdl = tp.LDAModel(k=2, min_df=2, seed=555)
for words in redmi['content_cutted']:#確認words 是 非空詞語列表if words:mdl.add_doc(words=words.split())#訓 練
mdl.train()
# 查看每個topic feature words
for k in range(mdl.k):print('Top 20 words of topic #{}'.format(k))print(mdl.get_topic_words(k, top_n=20))print('\n')
# 查看話題模型信息
mdl.summary()
import pyLDAvis
import numpy as np# 在notebook顯示
pyLDAvis.enable_notebook()# 獲取pyldavis需要的參數
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freqprepared_data = pyLDAvis.prepare(topic_term_dists, doc_topic_dists, doc_lengths, vocab, term_frequency,start_index=0, # tomotopy話題id從0開始,pyLDAvis話題id從1開始sort_topics=False # 注意:否則pyLDAvis與tomotopy內的話題無法一一對應。
)# 可視化結果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis-redmi.html')# notebook中顯示
pyLDAvis.display(prepared_data)
# 初始化LDA
mdl = tp.LDAModel(k=5, min_df=2, seed=555)
for words in huawei['content_cutted']:#確認words 是 非空詞語列表if words:mdl.add_doc(words=words.split())#訓 練
mdl.train()
# 查看每個topic feature words
for k in range(mdl.k):print('Top 20 words of topic #{}'.format(k))print(mdl.get_topic_words(k, top_n=20))print('\n')
# 查看話題模型信息
mdl.summary()
import pyLDAvis
import numpy as np# 在notebook顯示
pyLDAvis.enable_notebook()# 獲取pyldavis需要的參數
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freqprepared_data = pyLDAvis.prepare(topic_term_dists, doc_topic_dists, doc_lengths, vocab, term_frequency,start_index=0, # tomotopy話題id從0開始,pyLDAvis話題id從1開始sort_topics=False # 注意:否則pyLDAvis與tomotopy內的話題無法一一對應。
)# 可視化結果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis-huawei.html')# notebook中顯示
pyLDAvis.display(prepared_data)
資料獲取,更多粉絲福利,關注下方公眾號獲取





![[面試精選] 0076. 最小覆蓋子串](http://pic.xiahunao.cn/[面試精選] 0076. 最小覆蓋子串)




)

)






課堂 1--5,這五節主要講解 mysql 的概念,定義,下載安裝與卸載)
