代碼:https://github.com/stepfun-ai/Step1X-Edit
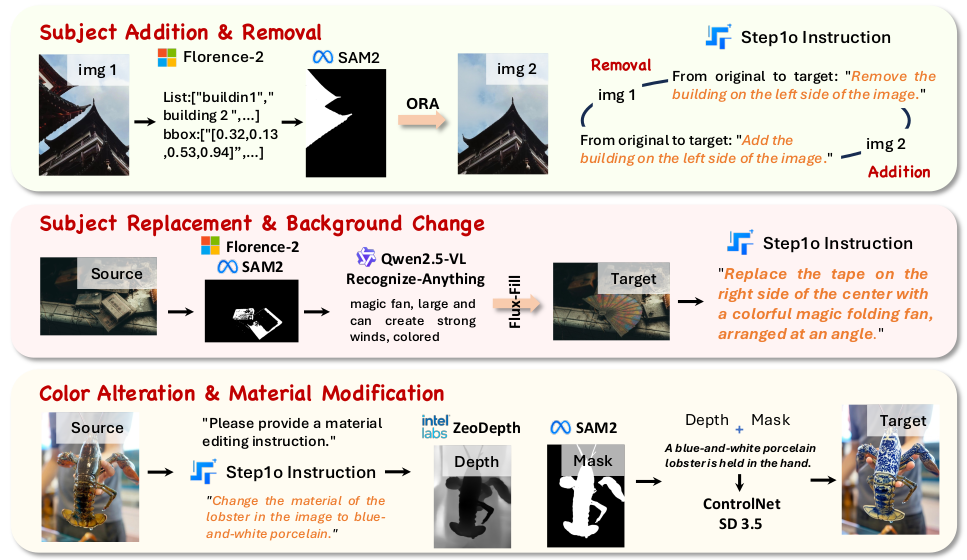
開源了Step1X-Edit模型,以減少開源和閉源圖像編輯系統之間的性能差距,并促進圖像編輯領域的進一步研究。 數據生成管道旨在生產高質量的圖像編輯數據。它確保數據集多樣化、具有代表性,并且質量足以支持有效圖像編輯模型的開發。此類管道的可用性為從事類似項目的研究人員和開發者提供了寶貴的資源。 為了支持更真實、更全面的評估,開發了一個基于實際使用的新基準,名為GEdit-Bench。該基準經過精心策劃,旨在反映實際用戶編輯需求和廣泛的編輯場景,從而能夠對圖像編輯模型進行更真實、更全面的評估。 從網絡上爬取大量的圖片,2000萬張; 通過多模態大模型(SAM2、Qwen2.5-VL、 GPT-4o等)、傳統深度學習模型(OCR)等對圖片進行處理; 用算法處理后,用GPT4進行美學評分,最后再進行人工審查,最終保留了100萬訓練數據。 算法處理流程示例
獲得的訓練數據是一個三元組,包含:原始圖片、編輯指令、修改后的圖片。
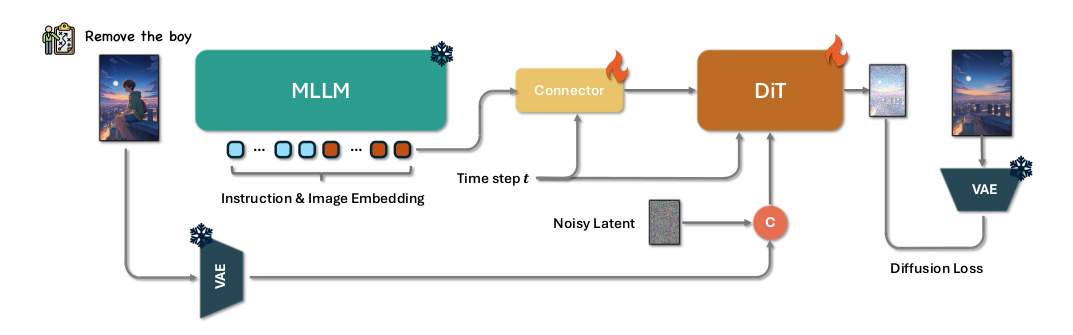
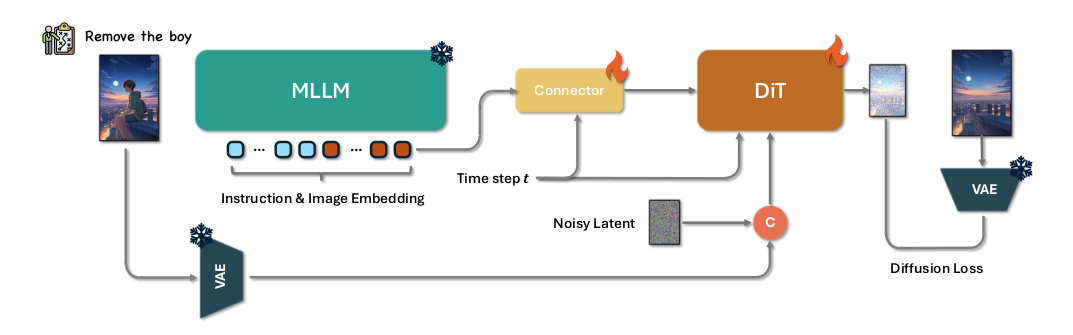
Step1X-Edit框架。Step1X-Edit利用MLLMs的圖像理解能力來解析編輯指令并生成編輯標記,然后使用基于DiT的網絡將這些標記解碼為圖像。
如上圖所示,Step1X-Edit框架主要包含三個部分:**多模態大語言模型(MLLM)**、**連接模塊(Connector)**、**擴散模型(DIT)**。 輸入編輯指令及其參考圖像首先被引入到MLLM(QwenVL)中,這些輸入通過MLLM的一次前向傳遞共同處理,使模型能夠捕捉指令與視覺內容之間的語義關系。為了隔離并強調與編輯任務相關的語義元素,我們選擇性地丟棄了與前綴相關的詞嵌入。這個過濾過程只保留與編輯信息直接對齊的標記嵌入,確保后續處理精確地關注編輯要求。 提取的嵌入向量隨后被輸入到一個輕量級連接模塊,該模塊將嵌入向量重組為更緊湊的多模態特征表示,之后作為下游DiT網絡的多模態嵌入輸入使用。 模型不僅保留了跨模態的理解能力,還增強了圖像細節的提取。通過在一個統一框架內結合結構化的視覺語言指導、詳細的視覺條件和強大的預訓練骨干網絡,該方法顯著提升了系統執行高保真、語義對齊的圖像編輯的能力,能夠處理各種用戶指令。在訓練過程中,僅使用擴散損失聯合優化連接器和下游的DiT。 ### 3. 模型評估 作者還建立了一套評估系統對模型進行了評估,評估結果達到開源的SOTA水平,接近閉源的Gemini和Doubao水平。如下表所示: 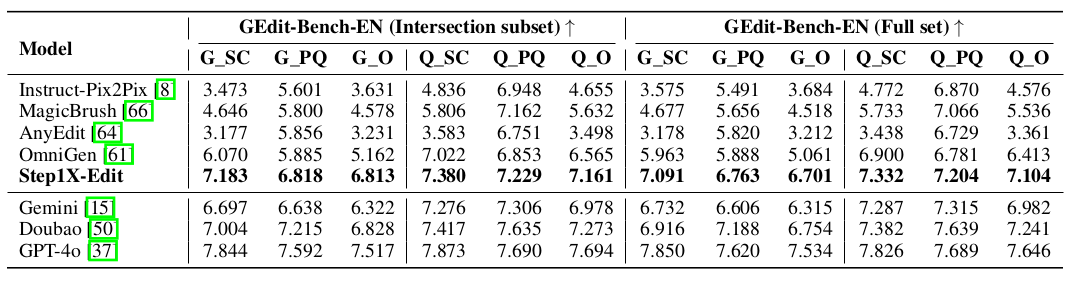 ## 三. 效果與總結 ### 1. 算法效果  ### 2. 總結 作者介紹了一種新的通用圖像編輯算法,稱為Step1X-Edit,該算法將公開發布,以促進圖像編輯社區內的進一步創新和研究。為了有效訓練模型,作者提出了一種新的數據生成管道,能夠生成大規模高質量的圖像編輯三元組,每個三元組包含一張參考圖像、一條編輯指令和一張相應的目標圖像。基于收集的數據集,通過無縫集成強大的多模態大語言模型與基于擴散的圖像解碼器來訓練Step1X-Edit模型。在收集的GEdit-Bench上的評估,該算法在性能上顯著優于現有的開源圖像編輯算法。
謝謝各位看官,如果喜歡,點贊+收藏~











)

實戰:如何通過 HTML 報告識別潛在問題)
PCB設計時如何避免EMI)




