項目簡介
本項目實現了一個極簡版的 Transformer Encoder 文本分類器,并通過 Streamlit 提供了交互式可視化界面。用戶可以輸入任意文本,實時查看模型的分類結果及注意力權重熱力圖,直觀理解 Transformer 的內部機制。項目采用 HuggingFace 的多語言 BERT 分詞器,支持中英文等多種語言輸入,適合教學、演示和輕量級 NLP 應用開發。
主要功能
- 多語言支持:集成 HuggingFace
bert-base-multilingual-cased分詞器,支持 100+ 語言。 - 極簡 Transformer 結構:自定義實現位置編碼、單層/多層 Transformer Encoder、分類頭,結構清晰,便于學習和擴展。
- 注意力可視化:可實時展示輸入文本的注意力熱力圖和每個 token 被關注的占比,幫助理解模型關注機制。
- 高效演示:訓練時僅用 AG News 數據集的前 200 條數據,并只訓練 10 個 batch,保證頁面加載和交互速度。
代碼結構與核心實現
1. 數據加載與預處理
使用 HuggingFace datasets 庫加載 AG News 數據集,并用 BERT 分詞器對文本進行編碼:
from datasets import load_dataset
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
dataset = load_dataset("ag_news")
dataset["train"] = dataset["train"].select(range(200)) # 只用前200條數據def encode(example):tokens = tokenizer(example["text"],padding="max_length",truncation=True,max_length=64,return_tensors="pt")return {"input_ids": tokens["input_ids"].squeeze(0),"label": example["label"]}encoded_train = dataset["train"].map(encode)
2. Tiny Encoder 模型結構
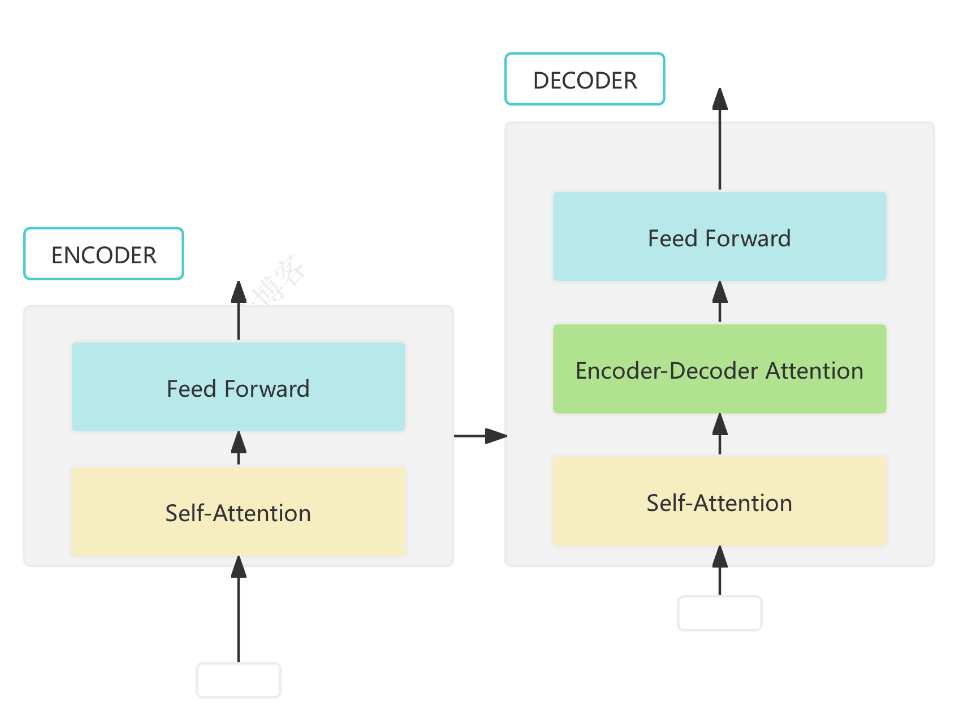
模型包含詞嵌入層、位置編碼、若干 Transformer Encoder 層和分類頭,支持輸出每層的注意力權重:
import torch.nn as nnclass PositionalEncoding(nn.Module):# ... 位置編碼實現,見下文詳細代碼 ...class TransformerEncoderLayerWithTrace(nn.Module):# ... 支持 trace 的單層 Transformer Encoder,見下文詳細代碼 ...class TinyEncoderClassifier(nn.Module):# ... 嵌入、位置編碼、編碼器堆疊、分類頭,見下文詳細代碼 ...
3. 訓練流程
采用交叉熵損失和 Adam 優化器,僅訓練 10 個 batch,極大提升演示速度:
import torch.optim as optim
from torch.utils.data import DataLoadertrain_loader = DataLoader(encoded_train, batch_size=16, shuffle=True)
model = TinyEncoderClassifier(...)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)model.train()
for i, batch in enumerate(train_loader):if i >= 10: # 只訓練10個batchbreakinput_ids = batch["input_ids"]labels = batch["label"]logits, _ = model(input_ids)loss = criterion(logits, labels)optimizer.zero_grad()loss.backward()optimizer.step()
4. Streamlit 可視化界面
- 提供文本輸入框,用戶可輸入任意文本。
- 實時推理并展示分類結果。
- 可視化 Transformer 第一層各個注意力頭的權重熱力圖和每個 token 被關注的占比(條形圖)。
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as pltuser_input = st.text_input("請輸入文本:", "We all have a home called China.")
if user_input:# ... 推理與注意力可視化代碼,見下文詳細代碼 ...
訓練與推理流程詳解
-
數據加載與預處理
- 加載 AG News 數據集,僅取前 200 條樣本。
- 用多語言 BERT 分詞器編碼文本,填充/截斷到 64 長度。
-
模型結構
- 詞嵌入層將 token id 映射為向量。
- 位置編碼為每個 token 添加可區分的位置信息。
- 堆疊若干 Transformer Encoder 層,支持輸出注意力權重。
- 分類頭對第一個 token 的輸出做分類(類似 BERT 的 [CLS])。
-
訓練流程
- 損失函數為交叉熵,優化器為 Adam。
- 只訓練 1 個 epoch,且只訓練 10 個 batch,保證演示速度。
-
推理與可視化
- 用戶輸入文本,模型輸出預測類別編號。
- 可視化注意力熱力圖和每個 token 被關注的占比,直觀展示模型關注點。
適用場景
- Transformer 原理教學與可視化演示
- 注意力機制理解與分析
- 多語言文本分類任務的快速原型開發
- NLP 課程、講座、實驗室演示
完整案例說明:
Tiny Encoder
1. 代碼主要功能
該腳本實現了一個基于 Transformer Encoder 的文本分類模型,并通過 Streamlit 提供了可視化界面,
支持輸入一句話并展示模型的分類結果及注意力權重熱力圖。
2. 主要模塊說明
- Tokenizer 初始化:
- 使用 HuggingFace 的多語言 BERT Tokenizer 對輸入文本進行分詞和編碼。
- 模型結構:
- 包含詞嵌入層、位置編碼、若干 Transformer Encoder 層(帶注意力權重 trace)、分類器。
- 數據處理與訓練:
- 加載 AG News 數據集,編碼文本,訓練模型并保存。
- 若已存在訓練好的模型則直接加載。
- Streamlit 可視化:
- 提供文本輸入框,實時推理并展示分類結果。
- 可視化 Transformer 第一層各個注意力頭的權重熱力圖。
3. 數據流向說明
- 輸入:
- 用戶在 Streamlit 網頁輸入一句英文(或多語言)文本。
- 分詞與編碼:
- Tokenizer 將文本轉為固定長度的 token id 序列(input_ids)。
- 模型推理:
- input_ids 輸入 TinyEncoderClassifier,經過嵌入、位置編碼、若干 Transformer 層,輸出 logits(分類結果)和注意力權重(trace)。
- 分類輸出:
- 取 logits 最大值作為類別預測,顯示在網頁上。
- 注意力可視化:
- 取第一層注意力權重,分別繪制每個 head 的熱力圖,幫助理解模型關注的 token 關系。
4. 適用場景
- 適合教學、演示 Transformer 注意力機制和文本分類原理。
- 可擴展用于多語言文本分類任務。
import math
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from transformers import AutoTokenizer
from datasets import load_dataset
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as plt# ============================
# 位置編碼模塊
# ============================
class PositionalEncoding(nn.Module):"""位置編碼模塊:為輸入的 token 序列添加可區分位置信息。使用正弦和余弦函數生成不同頻率的編碼。"""def __init__(self, d_model, max_len=512):super().__init__()# 創建一個 (max_len, d_model) 的全零張量,用于存儲位置編碼pe = torch.zeros(max_len, d_model)# 生成位置索引 (max_len, 1)position = torch.arange(0, max_len).unsqueeze(1)# 計算每個維度對應的分母項(不同頻率)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))# 偶數位置用 sin,奇數位置用 cospe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)# 增加 batch 維度,形狀變為 (1, max_len, d_model)pe = pe.unsqueeze(0)# 注冊為 buffer,模型保存時一同保存,但不是參數self.register_buffer('pe', pe)def forward(self, x):"""輸入:x,形狀為 (batch, seq_len, d_model)輸出:加上位置編碼后的張量,形狀同輸入"""return x + self.pe[:, :x.size(1)]# ============================
# 單層 Transformer Encoder,支持輸出注意力權重
# ============================
class TransformerEncoderLayerWithTrace(nn.Module):"""單層 Transformer Encoder,支持輸出注意力權重。包含多頭自注意力、前饋網絡、殘差連接和層歸一化。"""def __init__(self, d_model, nhead, dim_feedforward):super().__init__()# 多頭自注意力層self.self_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)# 前饋網絡第一層self.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(0.1)# 前饋網絡第二層self.linear2 = nn.Linear(dim_feedforward, d_model)# 層歸一化self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)# Dropout 層self.dropout1 = nn.Dropout(0.1)self.dropout2 = nn.Dropout(0.1)def forward(self, src, trace=False):"""前向傳播。參數:src: 輸入序列,形狀為 (batch, seq_len, d_model)trace: 是否返回注意力權重返回:src: 輸出序列attn_weights: 注意力權重(如果 trace=True)"""# 多頭自注意力,attn_weights 形狀為 (batch, nhead, seq_len, seq_len)attn_output, attn_weights = self.self_attn(src, src, src, need_weights=trace)# 殘差連接 + 層歸一化src2 = self.dropout1(attn_output)src = self.norm1(src + src2)# 前饋網絡src2 = self.linear2(self.dropout(torch.relu(self.linear1(src))))# 殘差連接 + 層歸一化src = self.norm2(src + self.dropout2(src2))# 返回輸出和注意力權重(可選)return src, attn_weights if trace else None# ============================
# Tiny Transformer 分類模型
# ============================
class TinyEncoderClassifier(nn.Module):"""Tiny Transformer 分類模型:包含嵌入層、位置編碼、若干 Transformer 編碼器層和分類頭。支持輸出每層的注意力權重。"""def __init__(self, vocab_size, d_model, n_heads, d_ff, num_layers, max_len, num_classes):super().__init__()# 詞嵌入層,將 token id 映射為向量self.embedding = nn.Embedding(vocab_size, d_model)# 位置編碼模塊self.pos_encoder = PositionalEncoding(d_model, max_len)# 堆疊多個 Transformer 編碼器層self.layers = nn.ModuleList([TransformerEncoderLayerWithTrace(d_model, n_heads, d_ff) for _ in range(num_layers)])# 分類頭,對第一個 token 的輸出做分類self.classifier = nn.Linear(d_model, num_classes)def forward(self, input_ids, trace=False):"""前向傳播。參數:input_ids: 輸入 token id,形狀為 (batch, seq_len)trace: 是否輸出注意力權重返回:logits: 分類輸出 (batch, num_classes)traces: 每層的注意力權重(可選)"""# 詞嵌入x = self.embedding(input_ids)# 加位置編碼x = self.pos_encoder(x)traces = []# 依次通過每一層 Transformer 編碼器for layer in self.layers:x, attn = layer(x, trace=trace)if trace:traces.append({"attn_map": attn})# 只取第一個 token 的輸出做分類(類似 BERT 的 [CLS])logits = self.classifier(x[:, 0])return logits, traces if trace else None# ============================
# 模型構建與訓練函數,顯式使用CPU
# ============================
@st.cache_resource(show_spinner=False)
def build_and_train_model(d_model, n_heads, d_ff, num_layers):device = torch.device('cpu') # 顯式指定使用CPUtokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")dataset = load_dataset("ag_news")dataset["train"] = dataset["train"].select(range(200)) # 只用前200條數據MAX_LEN = 64def encode(example):tokens = tokenizer(example["text"], padding="max_length", truncation=True, max_length=MAX_LEN, return_tensors="pt")return {"input_ids": tokens["input_ids"].squeeze(0), "label": example["label"]}encoded_train = dataset["train"].map(encode)encoded_train.set_format(type="torch")train_loader = DataLoader(encoded_train, batch_size=16, shuffle=True)model = TinyEncoderClassifier(vocab_size=tokenizer.vocab_size,d_model=d_model,n_heads=n_heads,d_ff=d_ff,num_layers=num_layers,max_len=MAX_LEN,num_classes=4).to(device) # 模型放到CPUcriterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=1e-3)model.train()for epoch in range(1): # 訓練1個epochfor i, batch in enumerate(train_loader):if i >= 10: # 只訓練10個batchbreakinput_ids = batch["input_ids"].to(device) # 輸入轉到CPUlabels = batch["label"].to(device)logits, _ = model(input_ids)loss = criterion(logits, labels)optimizer.zero_grad()loss.backward()optimizer.step()return model, tokenizer# ============================
# Streamlit 頁面設置
# ============================
st.set_page_config(page_title="TinyEncoder")
st.title("🌍 Tiny Encoder Transformer")# 固定模型參數
# d_model: 隱藏層維度,
# n_heads: 注意力頭數,
# d_ff: 前饋層維度,
# num_layers: Transformer 層數
d_model = 64
n_heads = 2
d_ff = 128
num_layers = 1# 構建并訓練模型
with st.spinner("模型構建中..."):model, tokenizer = build_and_train_model(d_model, n_heads, d_ff, num_layers)# ============================
# 推理與注意力權重可視化
# ============================
model.eval()
device = torch.device('cpu')
model.to(device)user_input = st.text_input("請輸入文本:", "We all have a home called China.")
if user_input:tokens = tokenizer(user_input, return_tensors="pt", max_length=64, padding="max_length", truncation=True)input_ids = tokens["input_ids"].to(device) # 放CPUwith torch.no_grad():logits, traces = model(input_ids, trace=True)pred_class = torch.argmax(logits, dim=-1).item()st.markdown(f"### 🔍 預測類別編號: `{pred_class}`")if traces:attn_map = traces[0]["attn_map"]if attn_map is not None:seq_len = input_ids.shape[1]token_list = tokenizer.convert_ids_to_tokens(input_ids[0])if '[PAD]' in token_list:valid_len = token_list.index('[PAD]')else:valid_len = seq_lentoken_list = token_list[:valid_len]if attn_map.dim() == 4:# [batch, heads, seq_len, seq_len]heads = attn_map.size(1)fig, axes = plt.subplots(1, heads, figsize=(5 * heads, 3))if heads == 1:axes = [axes]for i in range(heads):matrix = attn_map[0, i][:valid_len, :valid_len].cpu().detach().numpy()sns.heatmap(matrix, ax=axes[i], cbar=False, xticklabels=token_list, yticklabels=token_list)axes[i].set_title(f"Head {i}")axes[i].tick_params(labelsize=6)# 顯示每個 token 被關注的占比attn_sum = matrix.sum(axis=0)attn_ratio = attn_sum / attn_sum.sum()fig2, ax2 = plt.subplots(figsize=(5, 2))ax2.bar(range(valid_len), attn_ratio)ax2.set_xticks(range(valid_len))ax2.set_xticklabels(token_list, rotation=90, fontsize=6)ax2.set_title(f"Head {i} Token Attention Ratio")st.pyplot(fig2)st.pyplot(fig)elif attn_map.dim() == 3:# [heads, seq_len, seq_len]heads = attn_map.size(0)fig, axes = plt.subplots(1, heads, figsize=(5 * heads, 3))if heads == 1:axes = [axes]for i in range(heads):matrix = attn_map[i][:valid_len, :valid_len].cpu().detach().numpy()sns.heatmap(matrix, ax=axes[i], cbar=False, xticklabels=token_list, yticklabels=token_list)axes[i].set_title(f"Head {i}")axes[i].tick_params(labelsize=6)# 顯示每個 token 被關注的占比attn_sum = matrix.sum(axis=0)attn_ratio = attn_sum / attn_sum.sum()fig2, ax2 = plt.subplots(figsize=(5, 2))ax2.bar(range(valid_len), attn_ratio)ax2.set_xticks(range(valid_len))ax2.set_xticklabels(token_list, rotation=90, fontsize=6)ax2.set_title(f"Head {i} Token Attention Ratio")st.pyplot(fig2)st.pyplot(fig)elif attn_map.dim() == 2:# [seq_len, seq_len]fig, ax = plt.subplots(figsize=(5, 3))sns.heatmap(attn_map[:valid_len, :valid_len].cpu().detach().numpy(), ax=ax, cbar=False, xticklabels=token_list, yticklabels=token_list)ax.set_title("Attention Map")ax.tick_params(labelsize=6)st.pyplot(fig)# 顯示每個 token 被關注的占比matrix = attn_map[:valid_len, :valid_len].cpu().detach().numpy()attn_sum = matrix.sum(axis=0)attn_ratio = attn_sum / attn_sum.sum()fig2, ax2 = plt.subplots(figsize=(5, 2))ax2.bar(range(valid_len), attn_ratio)ax2.set_xticks(range(valid_len))ax2.set_xticklabels(token_list, rotation=90, fontsize=6)ax2.set_title("Token Attention Ratio")st.pyplot(fig2)else:st.warning("注意力權重維度異常,無法可視化。")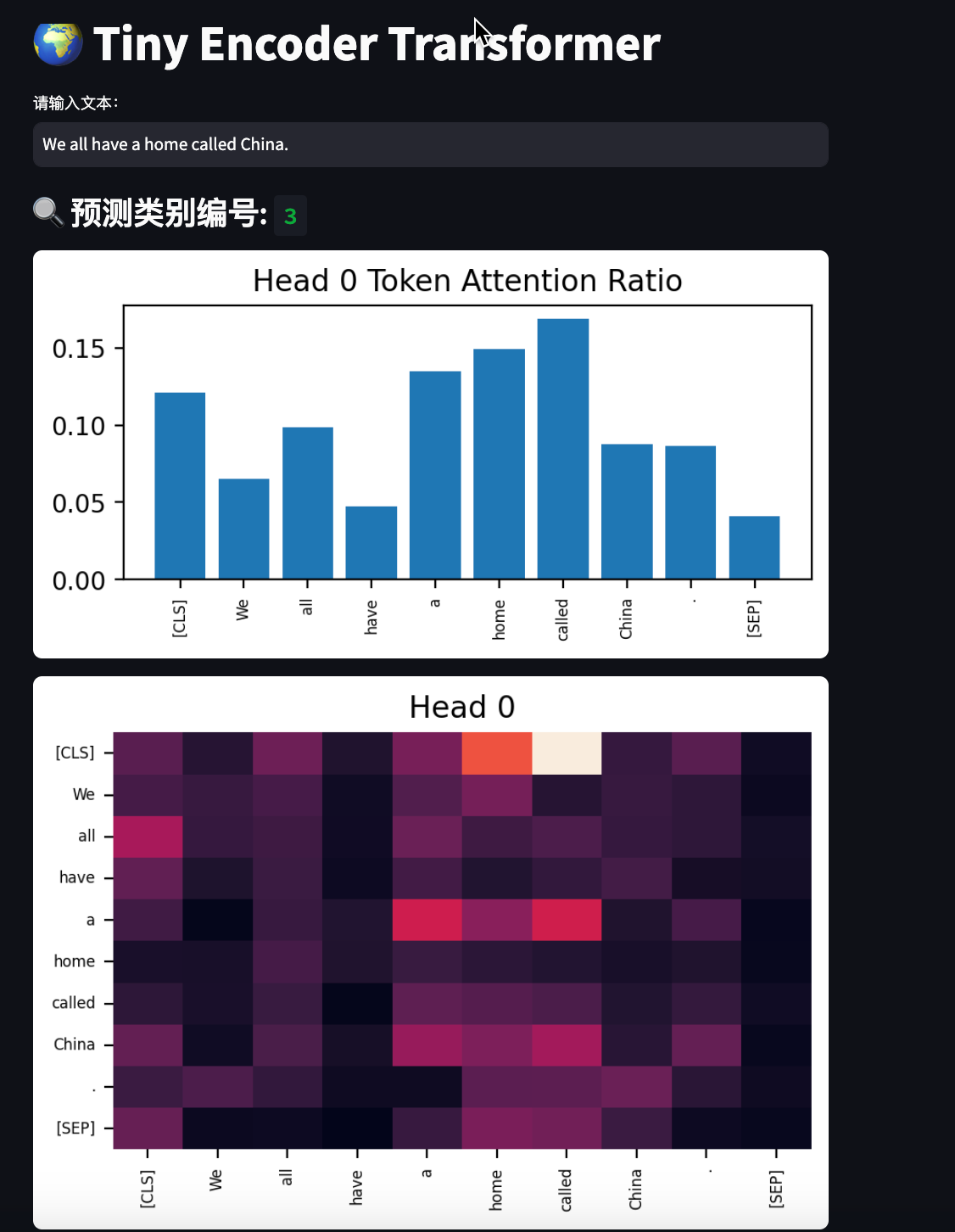










)

實戰:如何通過 HTML 報告識別潛在問題)
PCB設計時如何避免EMI)





