本文是實驗設計與分析(第6版,Montgomery著傅玨生譯)第7章2k析因的區組化和混區設計第7.4節的python解決方案。本文盡量避免重復書中的理論,著于提供python解決方案,并與原書的運算結果進行對比。您可以從Detail 下載實驗設計與分析(第6版,Montgomery著傅玨生譯)電子版。本文假定您已具備python基礎,如果您還沒有python的基礎,可以從Detail 下載相關資料進行學習。
許多問題中,在一個區組中進行一析因設計的完全重復是不可能的。混區設計(confounding)是一種設計方法,它將一個完全的析因設計安排在多個區組之內,區組的大小比一次重復中的處理組合的個數要小。這一方法使得關于特定處理效應(通常是高階的交互作用)的信息與來自區組的信息不可區分或者說混雜。本章集中討論2k析因設計的混區設計。即使是由于每一區組不包含所有的處理或處理組合而出現不完全區組設計,但是對于2k析因系統的特殊結構,也將有簡化的分析方法。
我們考慮有2p個不完全區組的2k析因設計的結構和分析方法,其中p<k。因此,這些設計將實在兩個區組內(p=1),4個區組內(p=2)、8個區組內(p=3),等等。
假定要實施一個單次重復的22設計。比如說,22=4個處理組合的每一個需用一定量的原材料,而每批原材料只夠供給兩個處理組合去試驗。這樣一來,就需要兩批原材料。如果把原材料的批次看作區組,則我們必須把這4種處理組合中的兩種分派給每個區組。
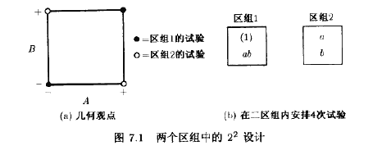
圖7.1表示對此問題的一種可能設計。圖7.1(b)是幾何觀點,表示把相反對角線上的處理組合分派給不同的區組。圖7.1(b)中,區組1包含處理組合(1)和ab。區組2包含a和b。當然,在同一區組內的個處理組合的實施順序是隨機確定的。先實施哪一區組的試驗也是隨機決定的。假定沒有劃分區組而來估計A和B的主效應。由(6.1)式和6.2)式得
![]()
因為每一估計量都有來自每個區組的一個加號的處理組合和一個減號的處理組合,所以A和B都不受劃分區組的影響.也就是說,區組1和區組2之間的差異抵消了。
今考忠AB的交互作用
![]()
因為兩個帶加號的處理組合[ab和(1)]都在區組1,兩個帶減號的處理組合(a和b)都在區組2,所以區組數應和AB的交互作用是一致的,也就是說,AB與區組混雜了。
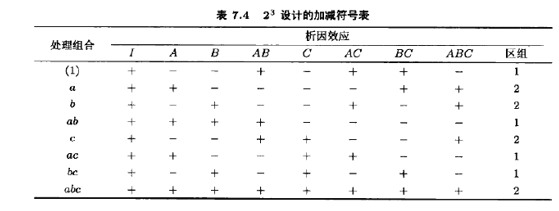
這一點可以從22設計的加減符號表中容易看出。此表原先在表6.2中給出,為方便起見,重列于表7.3。由此表可見,AB上帶加號的處理組合都安排在區組1,而AB上帶減號的處理組合都安排在區組2。這種方式可用來把任一效應(A,B,AB)與區組相混。例如,如果(1)和b安排到區組1,a和ab安排到區組2,則主效應A與區組相混。通常的實踐是把高階交互作用與區組相混。

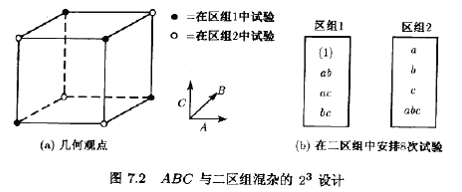
這個方案可用來混雜任意二區組中的2k設計。作為第二個例子,考慮二區組的23設計。設我們想把三因子交互作用ABC與區組相混。由表7.4的加減符號表,我們把ABC中帶堿號的處理組合分在區組1,ABC中帶加號的處理組合分在區組2。所得的設計如圖7.2所示。我們再次強調,在一區組內的處理組合的試驗順序是隨機的
- 構造區組的其他方法
2.誤差的估計
當變量的個數較小時,比方說k=2或3,通常必須進行重復以求得誤差的估計量。例如,假定需要進行有兩個區組的ABC被混雜的23析因實驗,實驗者決定進行4次里復。設計如圖7.3所示。在每次重復中ABC都被混雜。
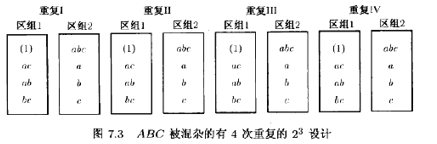
此設計的方差分析見表7.5,有32個觀測值和31個總的自由度。又因為有8個區組,所以和這些區組有關的必須是7個自由度。7個自由度的一種分解如表7.5所示。誤差平方和實際上由重復和每個效應(A,B,C,AB,AC,BC)之間的二因子交互作用所組成。將交互作用看作為零,并把它們的均方值看作為誤差的估計量通常是不會有問題的。主效應和二因子交互作用都是相對均方誤差進行檢驗的。Cochran and Cox(1957)指出,區組或ABC均方可以和由ABC提供的均方誤差進行比較,它實際上是由重復×區組提供的。這一檢驗法通常是很不靈敏的。
如果資源充足,允許混區設計做重復,則一般說來,在每次重復時采用稍有不同的設計區組方法會較好一些。這一處理方法是在各次重復中泡雜不同的效應,以便求得關于所有效應的一些信息。這樣的方法稱為部分混區設計,7.7節會給予討論。如果k適當大,比方說k≥4,則經常只數一次重復就行了,實驗者通常假定高階交互作用可被忽略并將它們的平方和組合起來作為誤差。因子效應的正態概率圖對這一點十分有幫助。
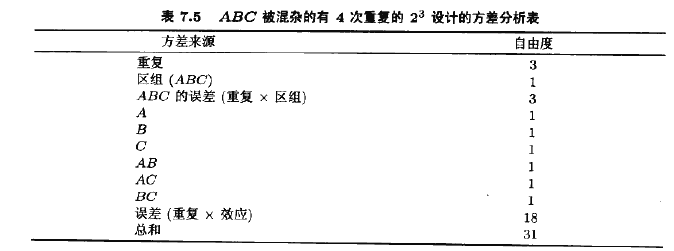
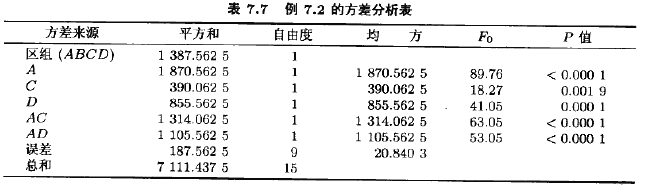
例7,2考忠例6.2描述的情況。回想4個因子:溫度(A),壓強(B)、甲醛的濃度(G)和境排速度(D)。在試驗性工廠中研究這些因子:以確定影響產品滲透率的效應。我們用這個實驗來說明在一個無重復設計中區組化和混雜的思想。我們對最初的實驗作了兩處修改。首先,假定一批原材料不能進行全部24=16個處理組合的試驗。一批原材料只能進行8個處理組合的試驗,所以,采用二區組的2混區設計看來是恰當的。將高階交互作用ABCD與區組混雜也是很自然的,定義對照是
L=x1十x2+x3+x4
容易證明,此設計如圖7.4所示。另外,可以檢在表6.12。觀測被安排到區組1的ABCD列中的標為“+”的處理組合,以及區組2的ABCD列中的標為“一”的處理組合。
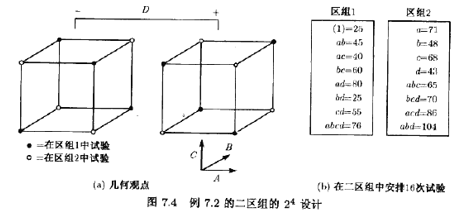
我們作的第二處修改是引入區組效應,以說明區組的作用。假定我們選擇兩批原材料來進行實驗,其中之一質量較差,因此,用這批材料得到的平均啊應低于那些用好的質量的材料20個單位。質量差的批次為區組L,質量好的批次為區組2(哪個批次為區組1,哪個批次為區組2無關緊要)。先做區組1的試驗(當然,區組里的8個試驗是按隨機次序進行的),但是,響應低于那些用好的質量材料的20個單位,圖7.4b顯示了響應的結果--注意到它們是可以由例6.2給出的原始觀測減去區組效應得到的。即,處理組合(1)的原始響應為45,圖7.4b中報告為(1)=25(=45-20)。該區組的其地響應也可以類似得到。做完區組1的試驗后,接著做區組2的8個試驗,這個批次的原材料沒有問題,所以,響應和它們最初在例6.2中的非常一致。
表7.6所列的是例6.2的“修改”觀點的效應估計。注意到4個主效應,6個二因子交互作用、4個三因子交互作用的估計和沒有區組效應的例6.2得到的效應估計一樣。計算效應估計的通常比例后,可以看出因子A,C,D和AC交互作用以及AD交互作用是重要效應,與原始實驗一樣。(讀者應當確認這一點)
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import pandas as pd
import?statsmodels.api?as?sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
import mistat
from scipy import special
from scipy.stats import ncx2
x5 = [1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1]
x1 = [-1,-1,-1,-1,1,1,1,1, -1,-1,-1,-1,1,1,1,1]
x2 = [-1,-1,1,1,-1,-1,1,1,-1,-1,1,1,-1,-1,1,1]
x3 = [-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1]
x4 = [1,-1,-1,1,-1,1,1,-1,-1,1,1,-1,1,-1,-1,1]
y1 = [43,68,48,70,71,86,104,65,25,55,25,60,80,40,45,76]
data = {"y1":y1,"x1":x1,"x2":x2,"x3":x3,"x4":x4,"x5":x5}
data=pd.DataFrame(data)
model1 = smf.ols(formula='data.y1 ~ C(data.x5)+data.x1+data.x2+data.x3+data.x4+data.x1*data.x2+data.x1*data.x3+data.x1*data.x4+data.x2*data.x3+data.x2*data.x4+data.x3*data.x4+data.x1*data.x2*data.x3+data.x1*data.x2*data.x4+data.x1*data.x3*data.x4+data.x2*data.x3*data.x4', data=data).fit()
print(model1.summary2())
???????????????? Results: Ordinary least squares
====================================================================
Model:??????????????? OLS????????????? Adj. R-squared:???? nan
Dependent Variable:?? data.y1????????? AIC:????? ??????????-920.6635
Date:???????????????? 2024-04-25 10:16 BIC:??????????????? -908.3021
No. Observations:???? 16?????????????? Log-Likelihood:???? 476.33
Df Model:???????????? 15?????????????? F-statistic:??????? nan
Df Residuals:???????? 0?????????????? ?Prob (F-statistic): nan
R-squared:??????????? 1.000??????????? Scale:????????????? inf
--------------------------------------------------------------------
???????????????????????? Coef.? Std.Err.??? t??? P>|t| [0.025 0.975]
--------------------------------------------------------------------
Intercept?????????????? 50.7500????? inf? 0.0000?? nan??? nan??? nan
C(data.x5)[T.1]???????? 18.6250????? inf? 0.0000?? nan??? nan??? nan
data.x1???????????????? 10.8125????? inf? 0.0000?? nan??? nan??? nan
data.x2?? ???????????????1.5625????? inf? 0.0000?? nan??? nan??? nan
data.x3????????????????? 4.9375????? inf? 0.0000?? nan??? nan??? nan
data.x4????????????????? 7.3125????? inf? 0.0000?? nan??? nan??? nan
data.x1:data.x2????????? 0.0625????? inf? 0.0000?? nan??? nan??? nan
data.x1:data.x3???????? -9.0625????? inf -0.0000?? nan??? nan??? nan
data.x1:data.x4????????? 8.3125????? inf? 0.0000?? nan??? nan??? nan
data.x2:data.x3????????? 1.1875????? inf? 0.0000?? nan??? nan??? nan
data.x2:data.x4???????? -0.1875????? inf -0.0000?? nan??? nan??? nan
data.x3:data.x4???????? -0.5625????? inf -0.0000?? nan??? nan??? nan
data.x1:data.x2:data.x3? 0.9375????? inf? 0.0000?? nan??? nan??? nan
data.x1:data.x2:data.x4? 2.0625????? inf? 0.0000?? nan??? nan??? nan
data.x1:data.x3:data.x4 -0.8125????? inf -0.0000?? nan??? nan??? nan
data.x2:data.x3:data.x4 -1.3125????? inf -0.0000?? nan??? nan??? nan
--------------------------------------------------------------------
Omnibus:??????????????? 4.847???????? Durbin-Watson:?????????? 1.389
Prob(Omnibus):????????? 0.089???????? Jarque-Bera (JB):??????? 2.523
Skew:?????????????????? -0.927??????? Prob(JB):??????????????? 0.283
Kurtosis:?????????????? 3.589???????? Condition No.:?????????? 3
====================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors
is correctly specified.
anova_table = sm.stats.anova_lm(model1, typ=2)
anova_table
model1 = smf.ols(formula='data.y1 ~ C(data.x5)+data.x1*data.x2*data.x3*data.x4', data=data).fit()
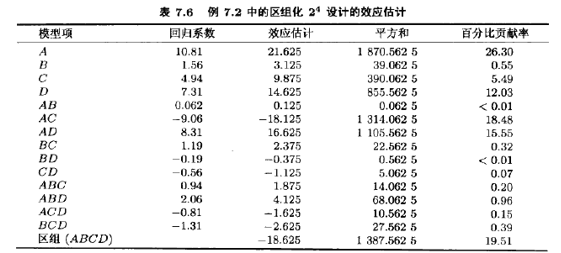
ABCD的交互效應是怎樣的用?原始實驗(例6.2)中該效應估計為ABCD=1.375。而在目前的例子中,ABCD交互效應的估計為ABCD=-18.625。因為ABCD與區組混雜了,用原始交互五效應(1.375)加上區組效應(-20)估計ABCD交互作用。所以ABCD=1.375+(-20)=-18.625。(你是否明白,為什么區組效應為-20?)區組效應可以用兩區組平均響應間的差直接計算。即
![]()
當然,這個效應確實估計了區組十ABCD
表7.7描述了該實驗的方差分析表。模型中包含了大的估計的效應。區組平方和為
![]()
該實驗的結論十分符合沒有區組效應的例6.2的結論。如果沒有在區組中進行實驗,且如果大小為-20的效應影響了前面的8個試驗(它們可能按照隨機方式進行的,因為16個試驗在區組設計中是按照隨機次序進行的),結果可能就不同。