概述
2018年,TensorFlow Lite團隊的Pete Warden曾提出:“機器學習的未來在于微型化”。如今,隨著人工智能向高性能視覺強大的視覺語言模型(Vision-language models, VLMs)發展,對高性能計算資源的需求急劇增長。圖形處理器(GPU)的需求達到歷史峰值,引發了對長期可持續性的擔憂。時至2025年,七年后的今天,一個關鍵問題浮現——我們是否已邁入這一微型化未來?本文通過定制的樹莓派集群與Jetson Nano開發板,在邊緣設備上對視覺語言模型展開測試。
在本系列博客中,我們將在多種開發板上進行廣泛實驗,旨在探尋適用于邊緣部署的快速、高效視覺語言模型,同時竭力避免設備過熱損壞。
樹莓派與Jetson Nano集群配置

樹莓派的寬度實則與圓周率值(3.14)無關,前文提及此點僅為戲謔。以下為構建集群所使用的開發板:
- 樹莓派2 Model B(2GB內存,無冷卻裝置)
- 樹莓派4 Model B(4GB內存,無冷卻裝置)
- 樹莓派4 Model B(8GB內存,無冷卻裝置)
- 樹莓派5(8GB內存,無冷卻裝置)
- Jetson Nano開發板(2GB內存,帶散熱片,無風扇)
- Jetson Nano(4GB內存,帶散熱片,無風扇)
- Jetson Orin Nano(8GB內存,256GB SSD,帶散熱片與風扇)
除Jetson Orin Nano外,所有開發板均配備64GB SD卡。集群構建的輔助組件包括以太網交換機與電源模塊。所有設備均采用原廠配置,未作任何硬件修改,旨在首先考察其開箱即用狀態下的性能表現,因此未額外添加散熱片或冷卻風扇。需說明的是,本實驗并非嚴格意義上的設備性能對比測試。
這些開發板能否承受負載而不出現過熱故障?后續內容將揭曉答案。
邊緣設備集群運行VLM的優勢
集群環境為部署前測試各類模型提供了理想平臺,且可根據需求靈活定制。構建集群不僅具有實踐價值,亦充滿探索樂趣。定制化樹莓派與Jetson Nano集群的主要優勢包括:
- 單一交換機實現以太網集中連接
- 便于監控與管理
- 配置簡潔
- 架構可擴展
- 適合實驗場景
我們將進一步通過3D打印外殼、支架、支撐件及端口配件等實現集群的定制化改造,相關完整構建方案與健康監測工具將在后續文章中詳述。

邊緣設備運行VLM的實驗設置
眾多模型宣稱可在低至2GB內存的邊緣設備上高效運行,我們將逐步對這些模型進行測試。本文選取Moondream2與Qwen2.5VL作為測試對象。
實驗通過PC端SSH遠程訪問所有開發板,以便進行設備間的并行對比。本地模型的下載與管理采用Ollama工具,其默認拉取4位量化模型,加載過程中不進行額外量化處理。
主控設備(本實驗中為PC)維護一個包含測試腳本與圖像的GitHub倉庫,所有必要修改均在此完成,隨后按需同步至各邊緣設備。環境配置完成后,即可運行帶輸入參數的測試腳本。
1.1 Ollama工具簡介
Ollama是一款輕量級跨平臺框架,支持在本地設備直接下載、運行和管理視覺語言模型(及大語言模型)。該工具提供命令行界面(CLI)、圖形用戶界面(GUI,截至2025年9月僅支持Windows系統),以及關鍵的Python SDK。Python客戶端庫可通過PyPi獲取,其封裝了Ollama的本地HTTP API,實現與Python環境的直接交互。
Ollama擁有獨立的精選模型庫,支持模型下載功能。這些模型采用GGUF+Modelfile格式:GGUF(GPT生成統一格式)為模型文件格式,Modelfile類似于包含模型運行需求的requirements.txt文件。用戶也可根據這些規范在Ollama中部署自定義模型。
1.2 設備上的Ollama安裝
Ollama可在官方網站獲取,支持Windows、Linux與Mac系統。需注意,Python客戶端需通過PyPi單獨安裝,命令為pip install ollama。本實驗中所有開發板均采用相同方式安裝Ollama。
視覺語言模型評估方法
視覺語言模型的評估較單模態(純視覺或純語言)模型更為復雜,因其需同時在跨模態感知與推理能力上表現優異。評估方法具有任務特異性,本研究從更廣泛視角簡化測試與對比流程,涉及以下任務:

(i) 圖像描述生成(Image Captioning):生成自然語言句子描述圖像的整體內容。
- 輸出形式:單句或段落
- 評估重點:全局理解能力與泛化能力
(ii) 視覺問答(Visual Question Answering, VQA):以自然語言回答關于圖像的問題,輸出可為單個數字、單詞、句子或段落。
(iii) 視覺定位(Visual Grounding):模型在圖像中識別并定位物體的能力,輸出形式包括位置描述句、邊界框坐標或物體掩碼。
(iv) 圖像文本檢索(Image Text Retrieval):模型從圖像中識別并理解文本內容的能力。
注:視覺語言模型的評估任務還包括跨模態檢索、組合與邏輯推理、視頻時序推理等,每項任務均有對應的基準數據集。相關評估方法的詳細討論將在后續文章中展開。
邊緣設備運行VLM的代碼實現
使用以下命令下載模型,本實驗將依次獲取qwen2.5vl:3b與moondream,總下載量約5.5GB,下載時間取決于網絡連接速度。
ollama pull qwen2.5vl:3b
ollama pull moondream
以下代碼片段實現模型加載、圖像與查詢定義功能。代碼中集成參數解析器,支持靈活修改模型、圖像路徑或查詢內容。模型響應通過ollama.chat()函數獲取,該函數接受模型名稱、查詢內容與圖像路徑作為參數。腳本中僅對生成時間進行測量。
# 導入庫
import ollama
import time
import argparse# 定義主函數
def main():# 添加參數解析器parser = argparse.ArgumentParser(description="使用圖像+查詢運行Ollama視覺語言模型")parser.add_argument("--model", type=str, default="qwen2.5vl:3b", help="模型名稱(默認:qwen2.5vl:3b)")parser.add_argument("--image", type=str, default="./tasks/esp32-devkitC-v4-pinout.png", help="輸入圖像路徑")parser.add_argument("--query", type=str, default="用100個字描述這張圖像的內容。", help="模型的查詢字符串")args = parser.parse_args()# 初始化開始時間變量以測量生成時間start_time = time.time()# 獲取模型響應response = ollama.chat(model=args.model,messages=[{"role": "user","content": args.query,"images": [args.image],}])end_time = time.time()print("模型輸出:\n", response["message"]["content"])print("\n生成時間: {:.2f} 秒".format(end_time - start_time))if __name__ == "__main__":main()
Qwen2.5VL(3B)模型推理實驗
Qwen2.5VL(3B)由阿里巴巴達摩院Qwen團隊開發,作為Qwen VL系列的成員于2025年1月發布。該模型性能優于Qwen2VL(7B),后綴"3B"表示其包含30億參數,具有體積小而性能強的特點。
- 內存消耗:約5GB
- 模型大小:3.2GB
4.1 Qwen2.5VL(3B)的核心特性
該模型的主要功能與任務能力包括:
- 多模態感知能力
- 智能體交互性:支持操作桌面或移動界面等工具
- 擴展視頻理解:采用動態幀率采樣與時間編碼,支持長達一小時的視頻分析
- 精確視覺定位:可生成邊界框、JSON格式點坐標等
- 結構化數據提取:能將發票、表單、表格等文檔解析為結構化格式
關于Qwen2.5VL的架構分析及其在視頻分析與內容審核中的應用,可參考相關文章。
4.2 Qwen2.5VL(3B)的視覺問答測試

實驗使用兩張圖像:一張包含坑洼的圖像與一張顯示人員在車間被電纜絆倒的圖像。模型需完成的VQA任務為:
- 圖像中有多少個坑洼?
- 該人員為何摔倒?
點擊圖像可查看放大視圖。實驗表明,內存低于4GB的設備無法運行該模型。盡管可通過增加SWAP分區大小解決此問題,但本實驗旨在考察模型在開箱即用狀態下的性能。
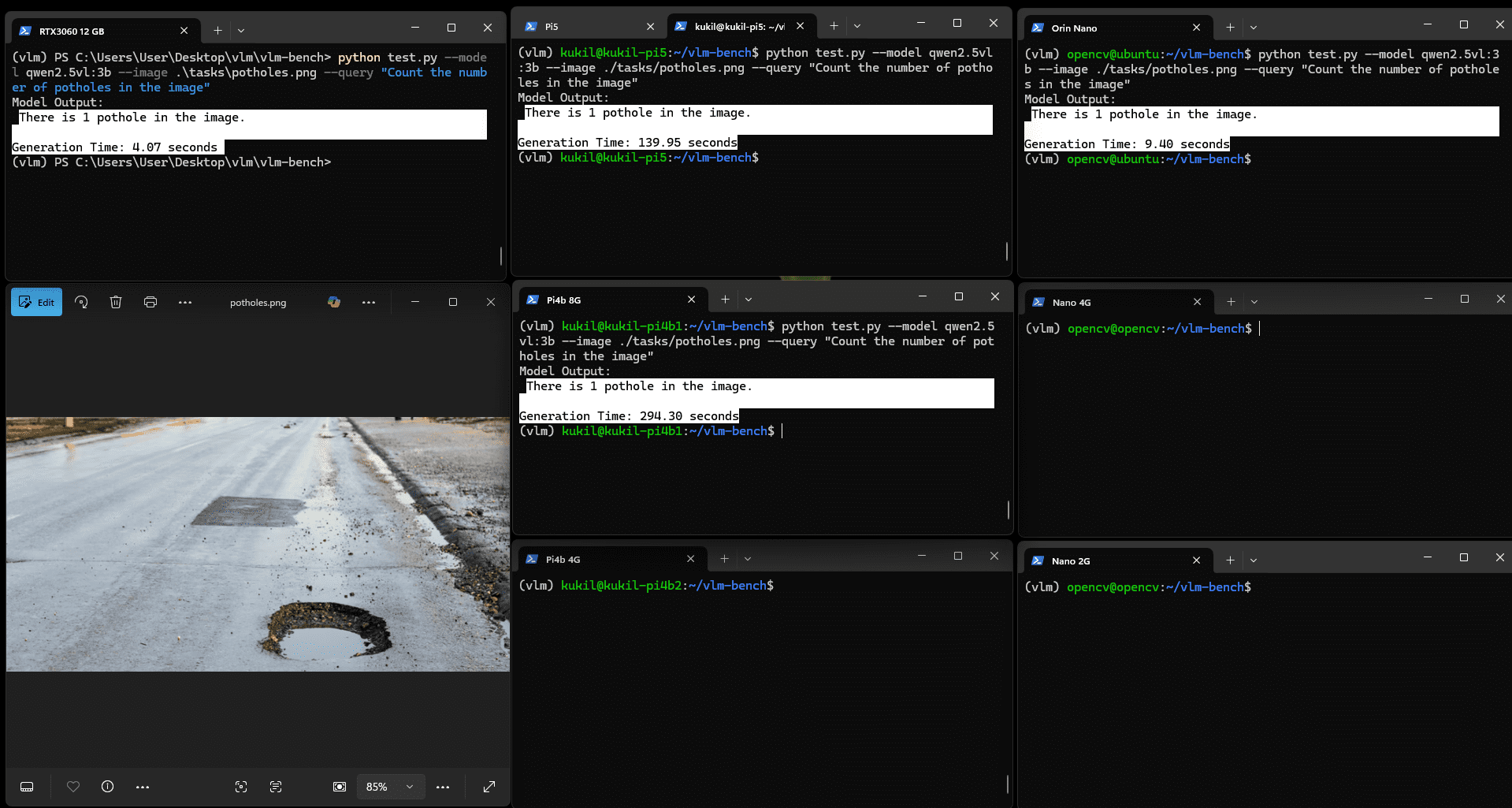
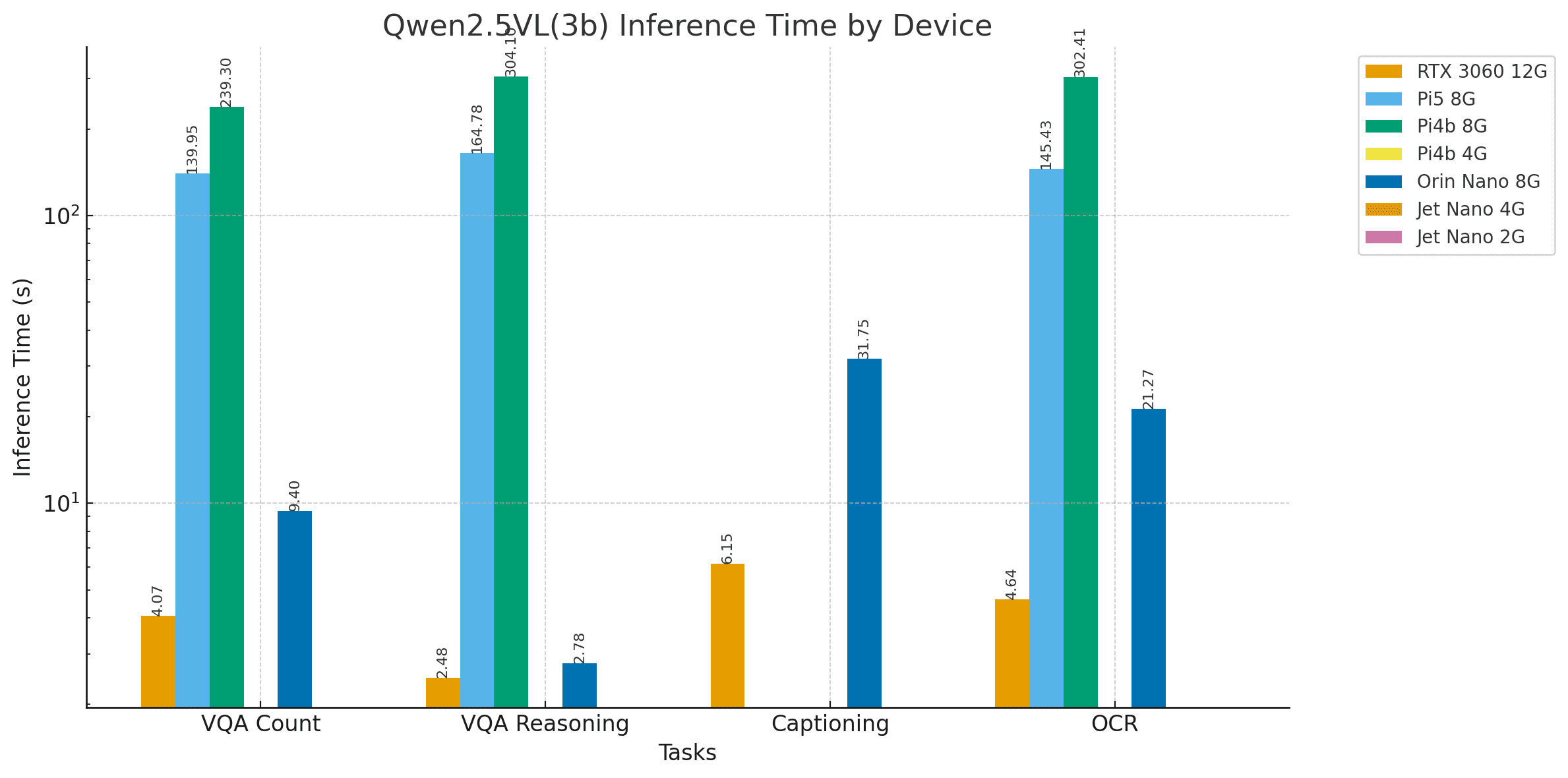
圖:Qwen2.5VL(3b)坑洼計數VQA任務結果
該模型在所有適用開發板上均能精確計數坑洼數量,但推理時間差異顯著。實驗中加入RTX 3060 12GB GPU作為參考設備(固定于左上角),結果顯示Jetson Orin Nano 8G與RTX 3060的推理時間分別為4秒與9.4秒,性能相當;而樹莓派設備則分別需要約2分鐘與5分鐘。
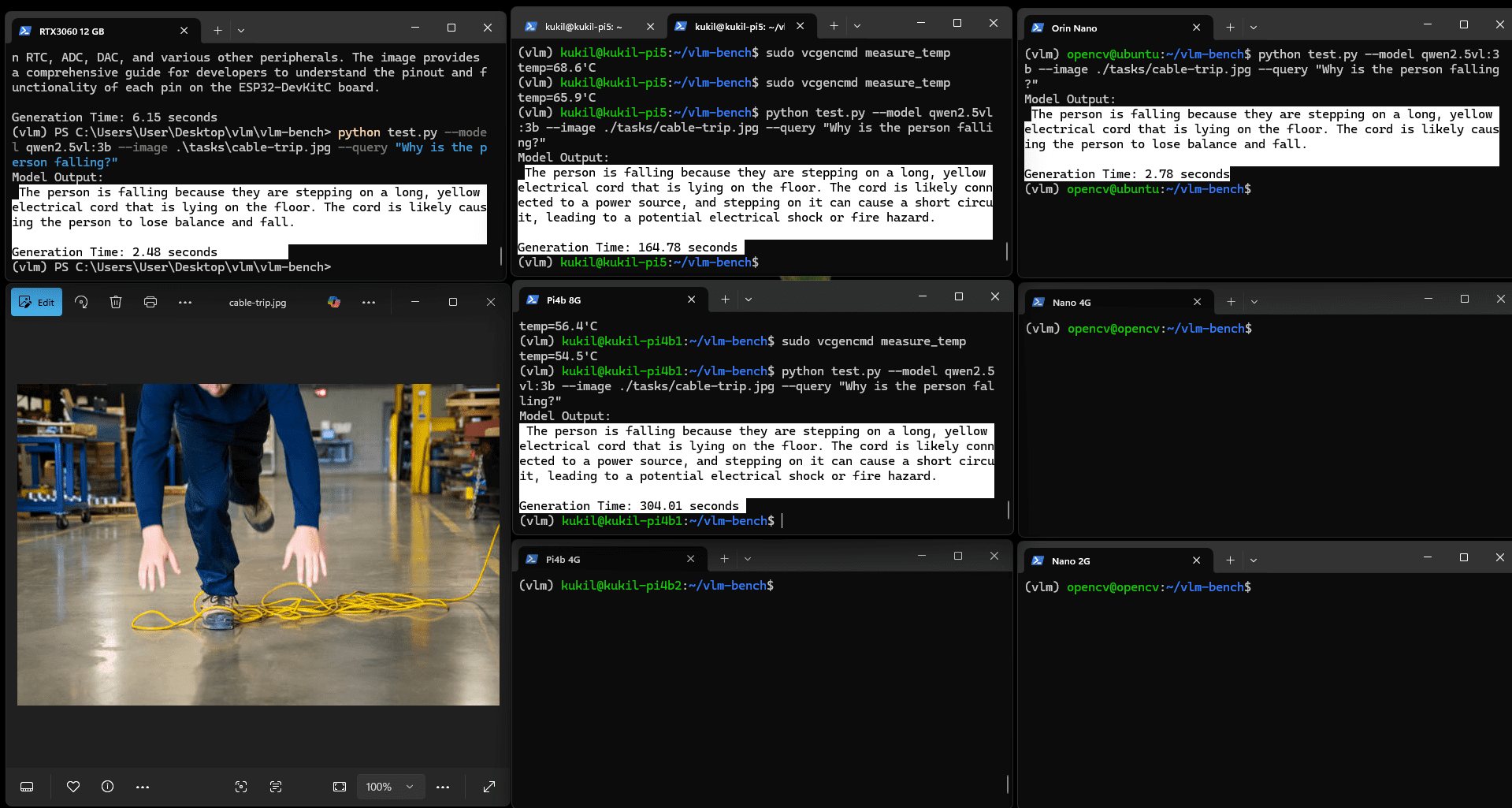
圖:Qwen2.5VL(3b)推理VQA任務結果
所有內存4GB以上的開發板均能正確運行模型,時間分布模式相似。RTX 3060與Orin Nano的推理時間分別降至2.48秒與2.78秒,考慮到Jetson Orin Nano的物理尺寸,其性能表現值得肯定。
4.3 Qwen2.5VL(3B)的OCR能力測試
實驗向模型輸入包含Gemma 2論文標題與段落的圖像,任務指令為"讀取圖像中的文本并解釋"。所有內存4GB以上的設備均能良好運行。關于Gemma模型的詳細分析可參考Gemma 3論文解讀。
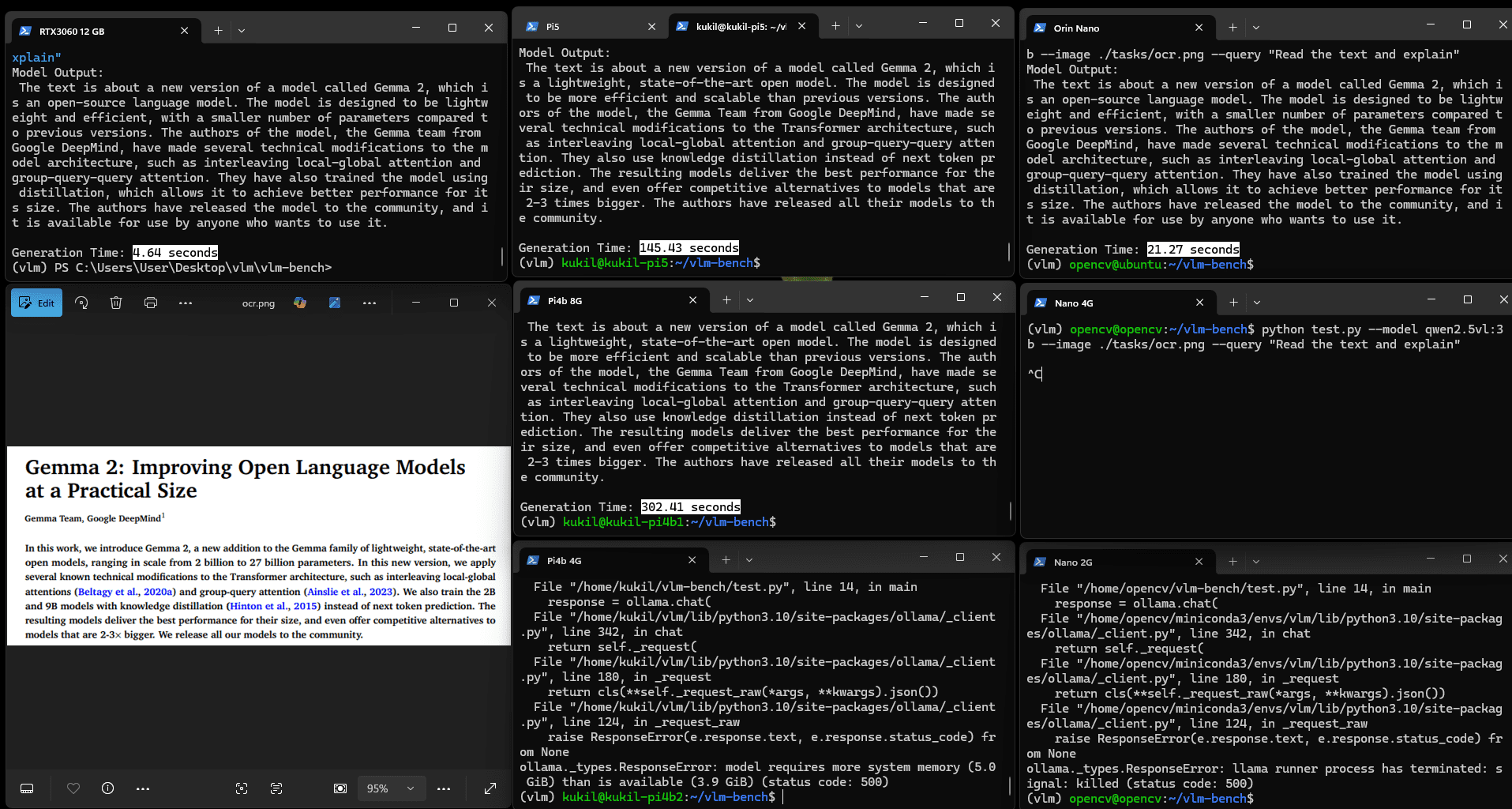
圖:Qwen2.5VL(3b)的OCR與解釋結果
OCR任務的耗時略長于計數或非文本推理類VQA任務:Orin Nano耗時21.27秒,Pi5耗時145.43秒,Pi4b 8G耗時302.41秒,其余設備則出現"內存不足"錯誤。這一結果在多數實際場景中仍可接受,因現實應用通常無需毫秒級的頁面讀取速度。
4.4 Qwen2.5VL(3b)的圖像描述生成測試
實驗使用Espressif的ESP32開發板引腳圖圖像,任務為"用100字生成圖像的整體描述"。默認視圖下細節可能不清晰,點擊圖像可放大查看。
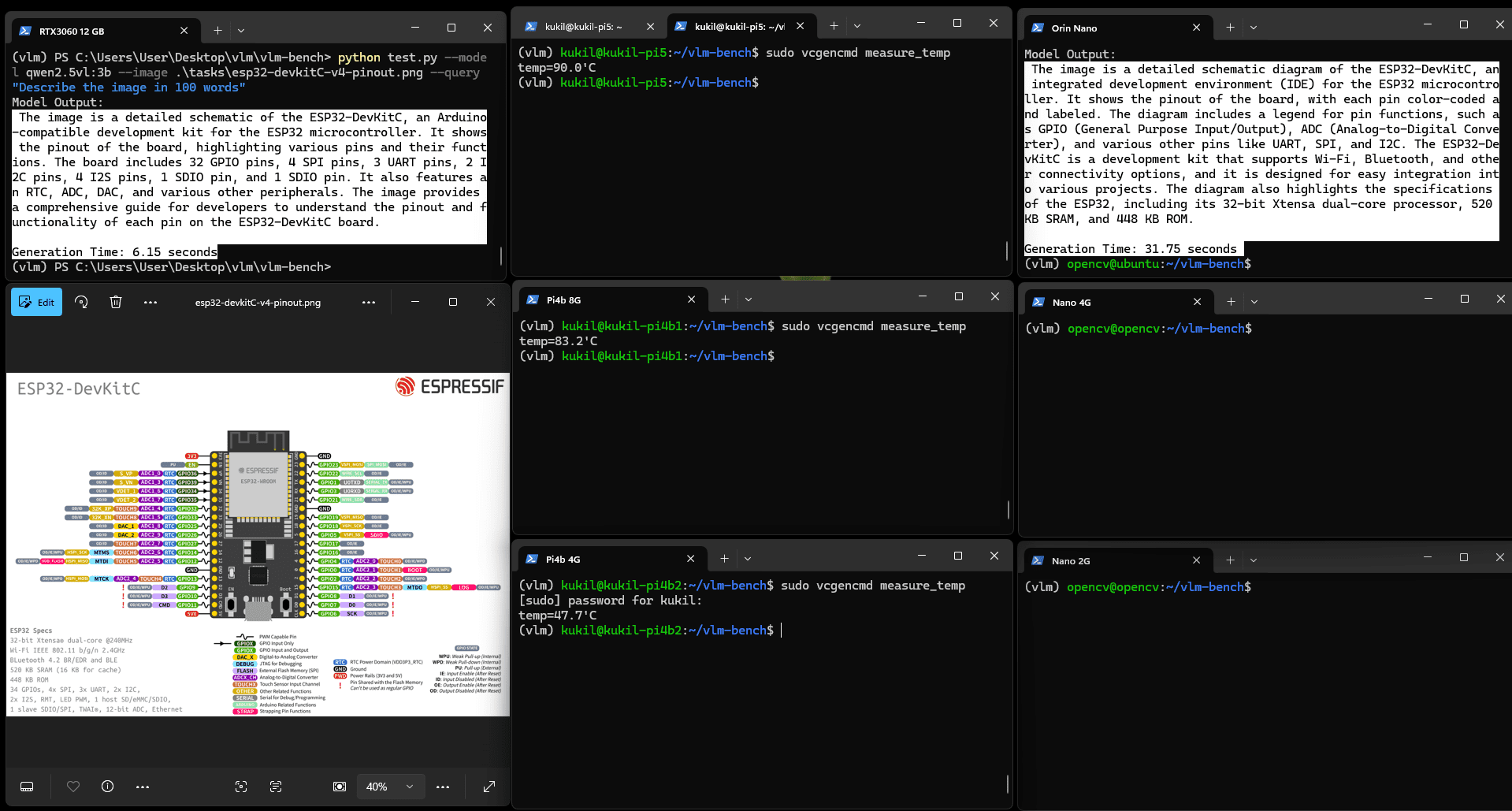
圖:Qwen2.5VL(3b)圖像描述生成示例
該圖像包含文本、繪圖、圖表與符號等復雜元素,Orin Nano的生成結果質量優良,能清晰理解技術細節。
然而,樹莓派設備的表現不佳。在進行描述生成測試時,樹莓派出現性能下降:當溫度達到90攝氏度時,設備開始降頻,其中兩臺樹莓派在10分鐘后仍未生成輸出。
未運行任務的Pi4b 4G溫度為47攝氏度,而嘗試運行描述生成任務的Pi5與Pi4b溫度升至90攝氏度。顯然,在邊緣設備上運行VLM至少需要配備散熱片進行被動冷卻。
4.5 結果討論
Jetson Orin Nano在速度與準確性方面表現優異,但需注意該開發板配備大型散熱片與主動風扇(原廠配置),因此此對比并非完全公平。再次強調,本實驗并非嚴格的設備性能比較。

Moondream2——邊緣設備優化型VLM推理實驗
Moondream號稱世界上最小的視覺語言模型,僅含18億參數,可在僅2GB內存的設備上運行,幾乎適用于所有邊緣設備。
- 內存需求:小于2GB
- 模型大小:1.7GB
- 基礎模型:基于sigLIP
- 投影器:基于Phi-1.5
該模型通過提取并微調SigLIP(一種基于sigmoid的對比損失模型)與微軟Phi-1.5語言模型的組件構建而成。關于DeepMind SigLIP的更多信息可參考相關文章。
實驗中,Moondream2模型接受與上述相同的測試,結果記錄如下。
5.1 Moondream2的視覺問答測試
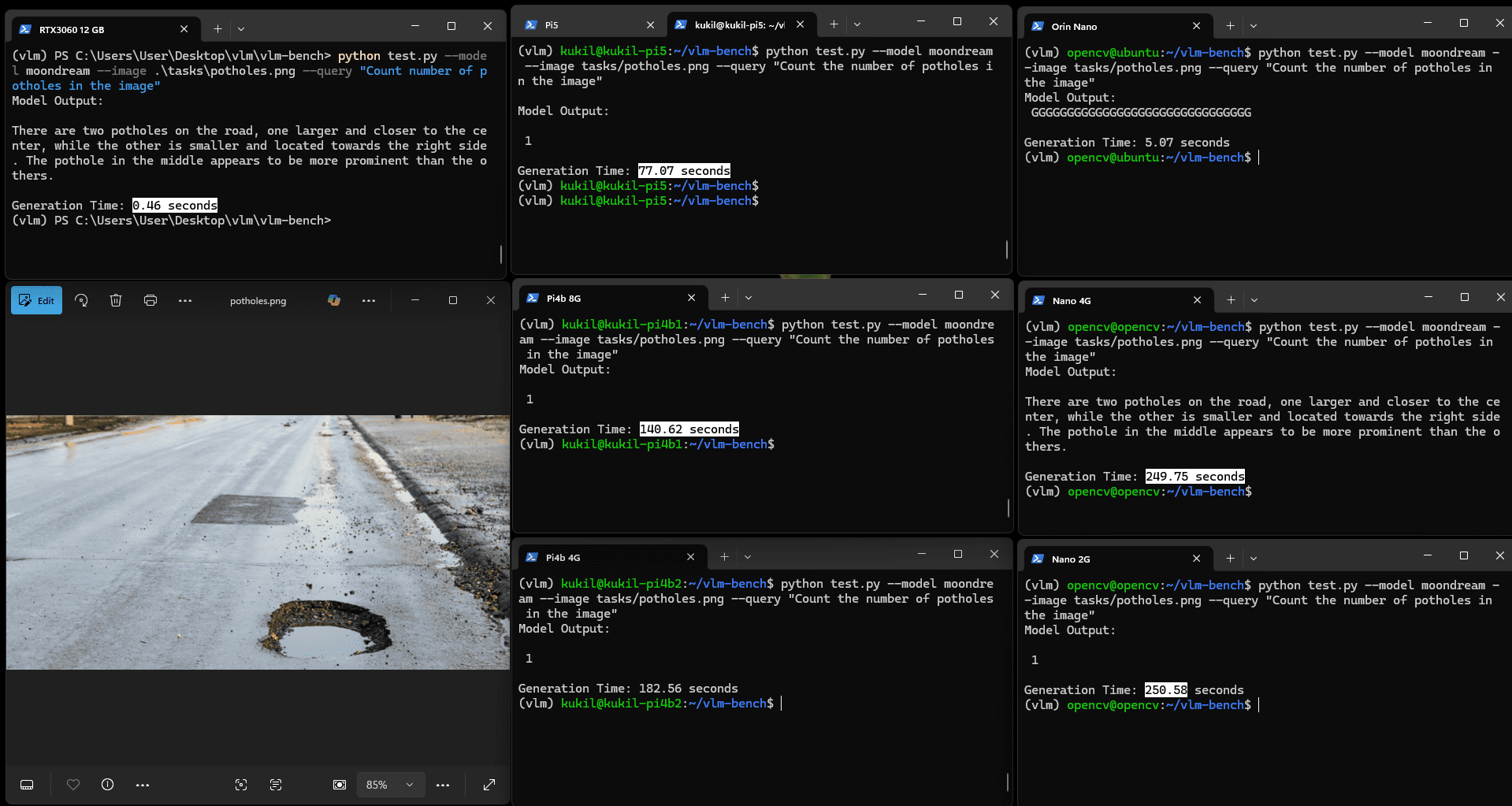
圖:Moondream2坑洼計數VQA任務結果
Moondream2的推理速度顯著更快,但實驗發現Jetson Orin Nano出現錯誤輸出。此問題僅在Moondream模型上觀察到,在測試LlaVA 7b、Llava-llama3、Gemma2:4b、Gemma3n等其他模型時未出現,且已有用戶報告類似問題。我們將深入調查并在后續更新中說明原因及解決方案。此外,RTX 3060與Jetson Nano 4GB也出現了部分計數錯誤。
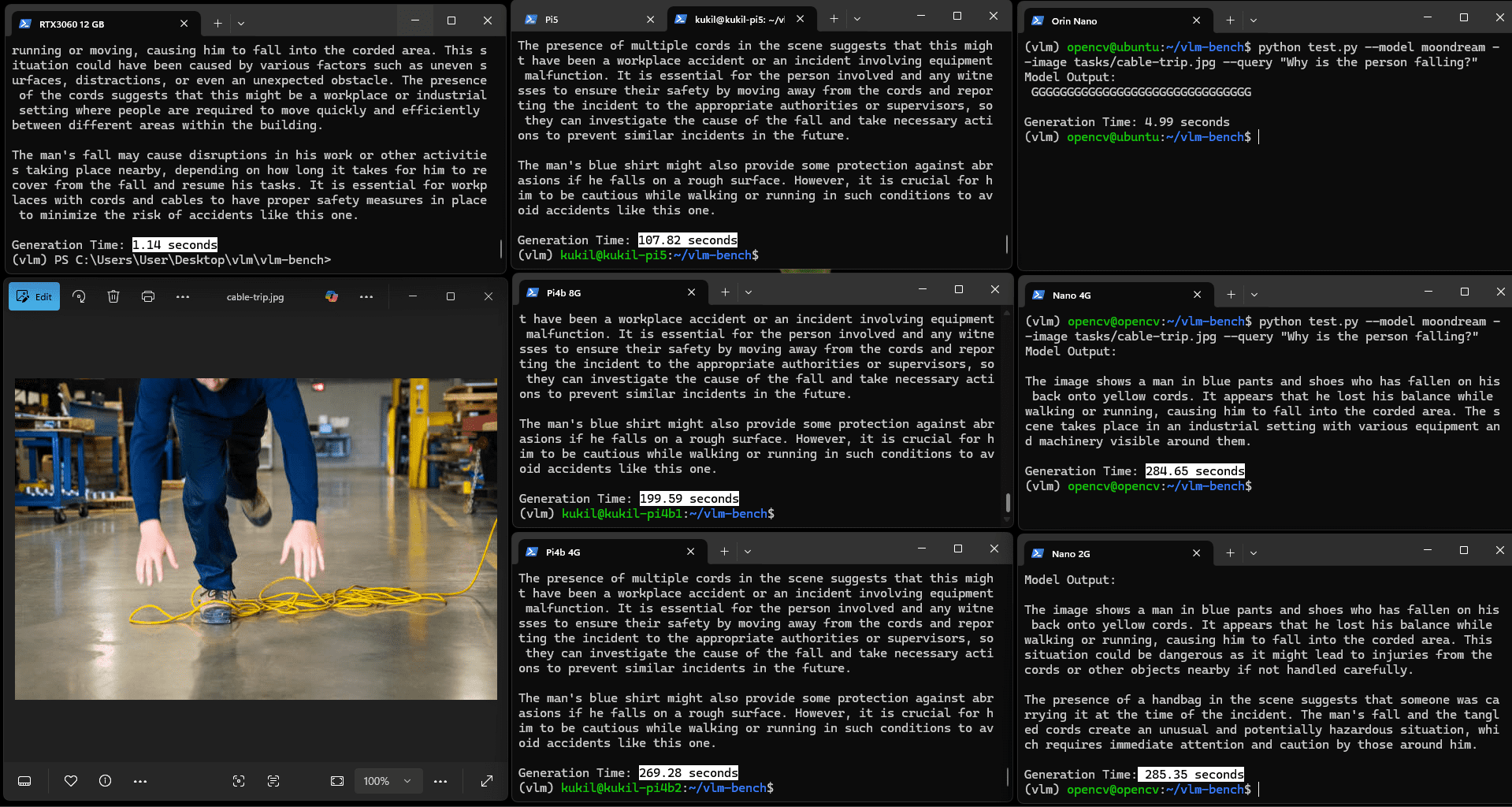
圖:Moondream推理VQA任務結果
Moondream2認為圖中人員可能因跑步摔倒,同時檢測到了纏繞的電纜,但未能建立摔倒與電纜纏繞之間的因果關系。相比之下,Qwen2.5VL能清晰識別原因,僅耗時略長。
5.2 Moondream2的OCR能力測試

圖:Moondream2的OCR與解釋結果
所有設備的字符識別效果良好,除Jetson Orin Nano在特定情況下生成了"GGGG"等錯誤內容。
5.3 Moondream2的圖像描述生成測試
盡管耗時存在差異,所有設備均按預期完成任務,能清晰描述圖像中包含ESP32開發板引腳圖及相關信息,但存在輕微的"幻覺"現象。
問:生成模型中的"幻覺"指什么?
正如其名,幻覺是指模型自信地生成虛假信息并將其呈現為真實內容,即模型編造信息——類似前文虛構樹莓派寬度為3.4英寸的情況。
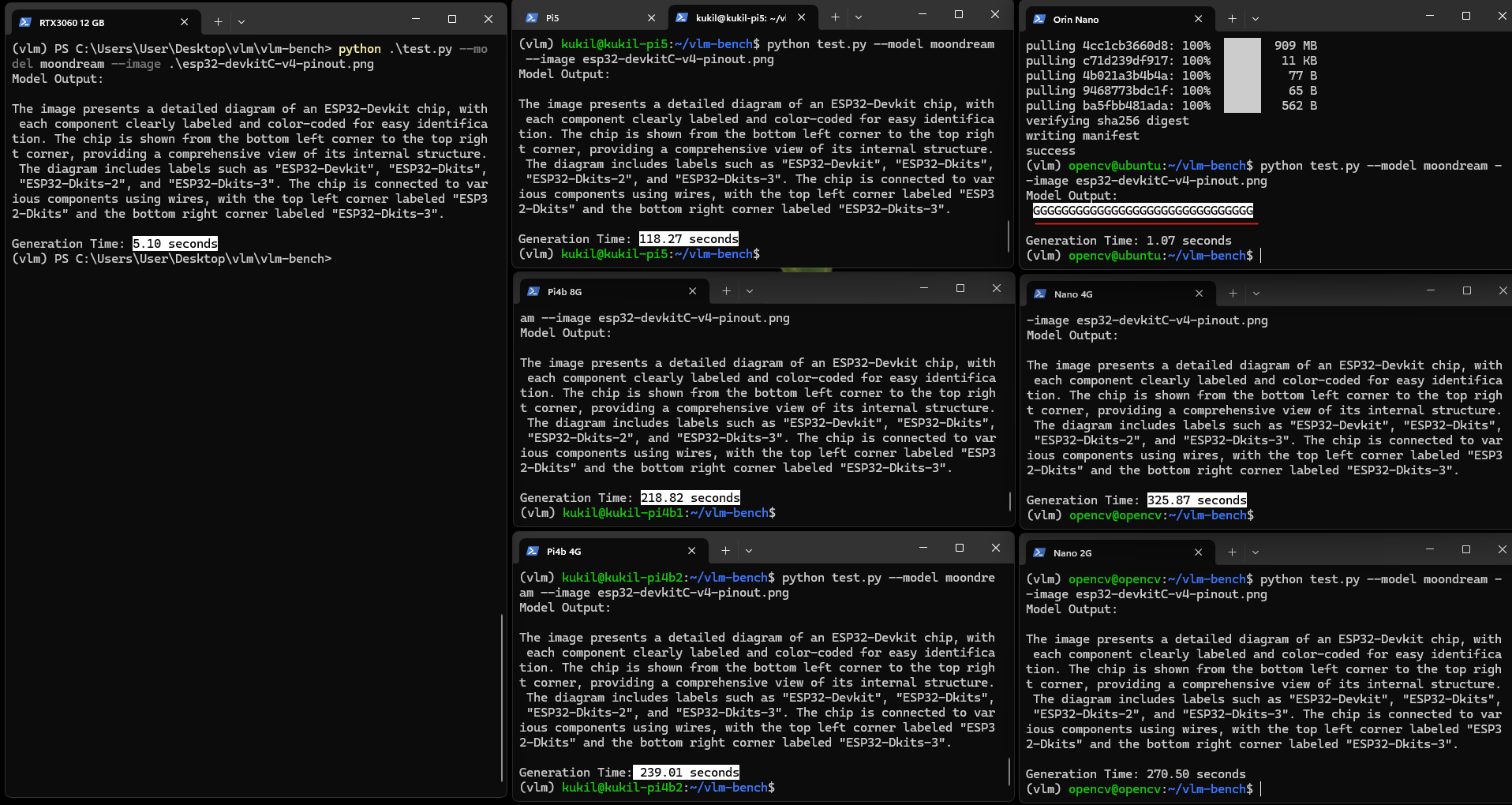
圖:Moondream2圖像描述生成示例
盡管設備耗時存在差異,但所有設備均按預期運行,能清晰描述圖像中包含ESP32開發板引腳圖及相關信息,同時觀察到輕微的幻覺現象。
5.4 結果討論

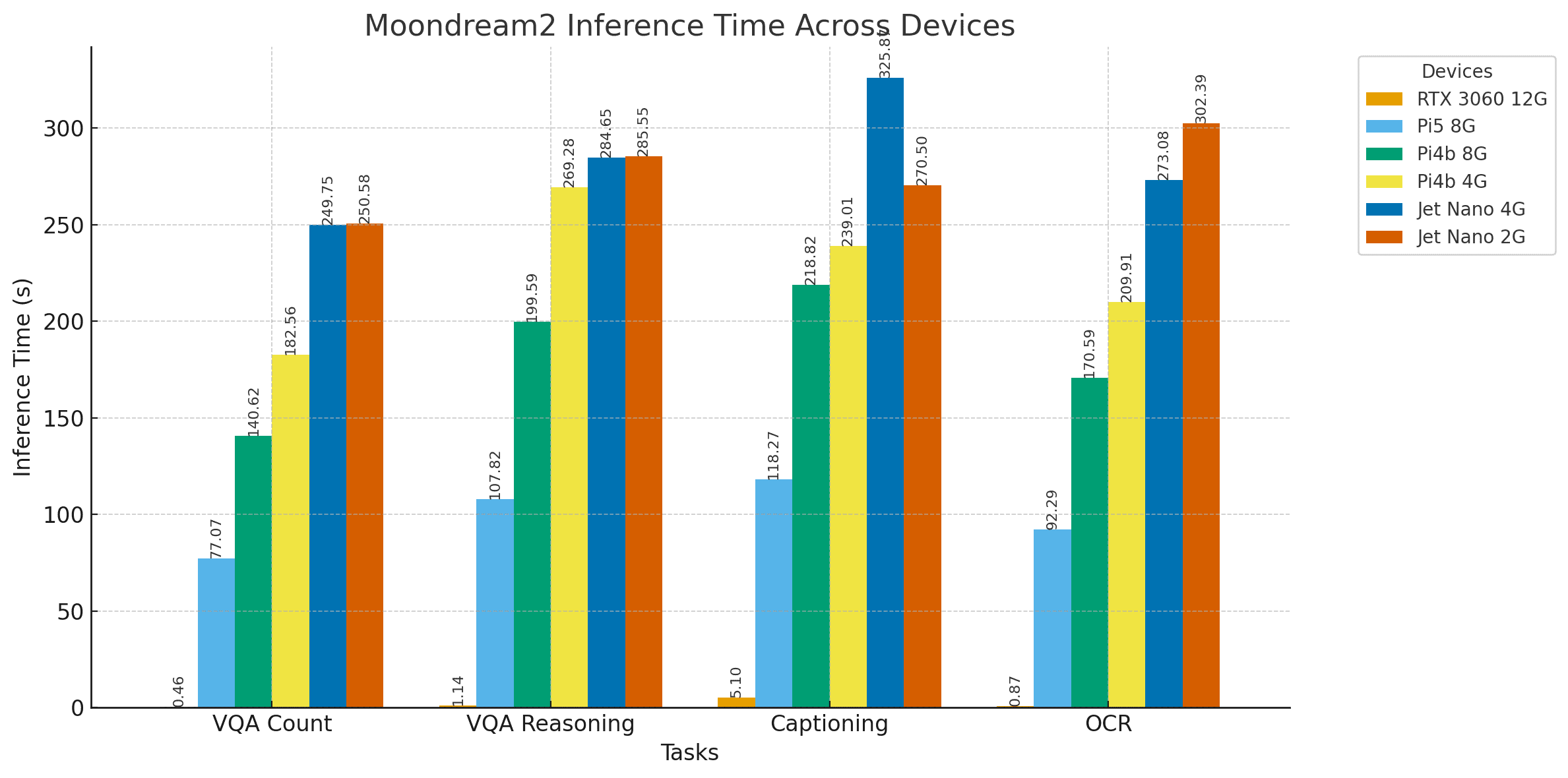
結論
本研究完成了在開箱即用狀態下邊緣設備運行VLM的實驗。Moondream2專為緊湊的邊緣友好型推理設計,在約1000個令牌的有限上下文窗口下運行,適用于受限硬件上的快速多模態任務。
Qwen2.5-VL(3B)是功能更強的多模態模型,支持長達125K令牌的超長上下文窗口,能夠處理大型文檔、視頻、多圖像序列及智能體管道。
本文僅搭建了基礎測試框架,后續研究將添加散熱片、冷卻風扇與SSD以提升性能,并通過安裝transformers庫測試更多來自Hugging Face的模型。






)

_280)





![[Dify實戰]插件編寫- 如何讓插件直接輸出文件對象(支持 TXT、Excel 等)](http://pic.xiahunao.cn/[Dify實戰]插件編寫- 如何讓插件直接輸出文件對象(支持 TXT、Excel 等))
)



基本操作第41題)