你遇到的大部分ubuntu中配置hadoop的問題這里都有解決方法!!!(近10000字)
概要
在Docker虛擬容器環境下,進行Hadoop-3.2.2分布式集群環境的配置與安裝,完成基于Yarn模式的一個Master節點、兩個Slaver(Worker)節點的配置。
1.主要步驟
- 安裝配置啟動Docker虛擬容器
- 配置主機名
- 配置自動時鐘同步
- 配置hosts列表
- 配置免密碼登錄
- 安裝JDK(在三臺節點分別操作此步驟)
- 安裝部署Hadoop集群
2、實驗環境
虛擬機數量:3
系統版本:Centos Stream/Ubuntu 20.4(18.4)
Hadoop版本:Apache Hadoop 3.2.2(3.2.1)
熟悉Linux操作系統
Hadoop原理
常見Linux命令的使用
linux系統基礎配置
配置JDK
配置Hadoop的相關參數
掌握Hadoop操作指令
在安裝Docker之前安裝一些必要的依賴包:
sudo apt install apt-transport-https ca-certificates curl software-properties-common
添加 Docker 的官方 GPG 密鑰
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
添加 Docker 的 APT 源
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
更新 APT 包索引
sudo apt update
安裝 Docker CE
sudo apt install docker-ce
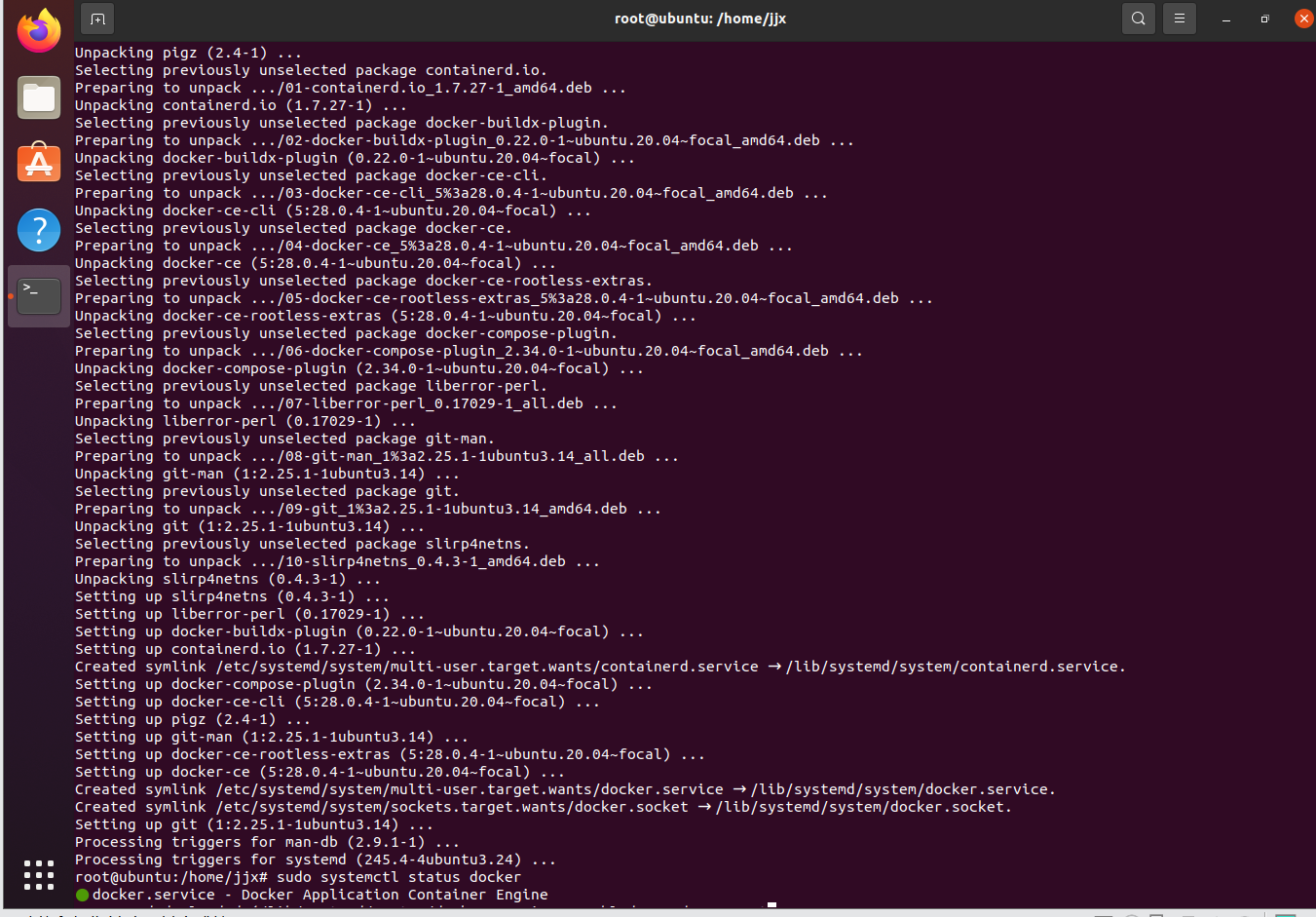
安裝完成后,您可以通過運行以下命令來驗證 Docker 是否成功安裝:
sudo systemctl status docker
下載Docker compose
sudo apt update
sudo apt install docker-compose
docker-compose version 創建Docker-compose.yml

將以下內容放入yml:
version: "3" services: master: image: ubuntu:latest container_name: masternode privileged: true networks: hadoop: ipv4_address: 10.10.0.11 ports: - 9870:9870 - 9000:9000 - 18040:18040 - 18030:18030 - 18025:18025 - 18141:18141 - 18088:18088 - 50070:50070 - 60000:60000 - 16000:16000 - 8080:8080 volumes: - hadoop:/hadoop/master - ./Files:/Files environment: - CLUSTER_NAME=hadoop_cluster_simple stdin_open: true tty: true slave01: image: ubuntu:latest container_name: slave01node privileged: true networks: hadoop: ipv4_address: 10.10.0.12 volumes: - hadoop:/hadoop/slave01 - ./Files:/Files environment: - CLUSTER_NAME=hadoop_cluster_simple stdin_open: true tty: true slave02: image: ubuntu:latest container_name: slave02node privileged: true networks: hadoop: ipv4_address: 10.10.0.13 volumes: - hadoop:/hadoop/slave02 - ./Files:/Files environment: - CLUSTER_NAME=hadoop_cluster_simple stdin_open: true tty: true slave03: image: ubuntu:latest container_name: slave03node privileged: true networks: hadoop: ipv4_address: 10.10.0.14 volumes: - hadoop:/hadoop/slave03 - ./Files:/Files environment: - CLUSTER_NAME=hadoop_cluster_simple stdin_open: true tty: true volumes: hadoop: networks: hadoop: driver: bridge ipam: driver: default config: - subnet: "10.10.0.0/24" 在docker鏡像地址中有已無法進入的地址,需要換源,具體看:完美解決Docker pull時報錯:https://registry-1.docker.io/v2/-CSDN博客
啟動Docker虛擬容器
sudo docker-compose -f docker-compose.yml up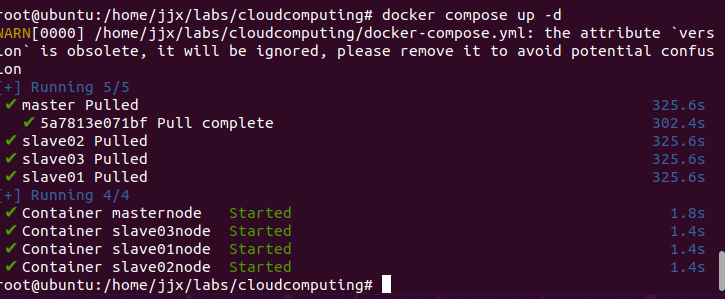
打開三個新的終端窗口,分別登錄master、slave01和slave02節點(按下ctrl + d可以從各節點退出)
sudo docker exec -it masternode /bin/bash
sudo docker exec -it slave01node /bin/bash
sudo docker exec -it slave02node /bin/bash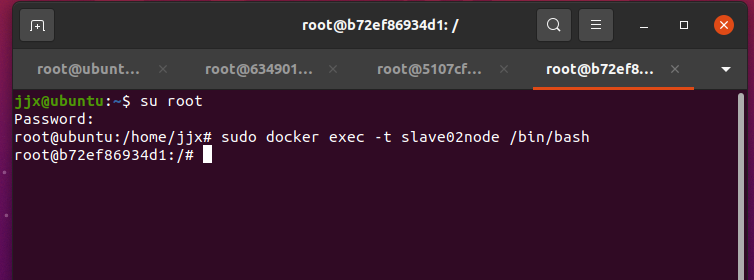
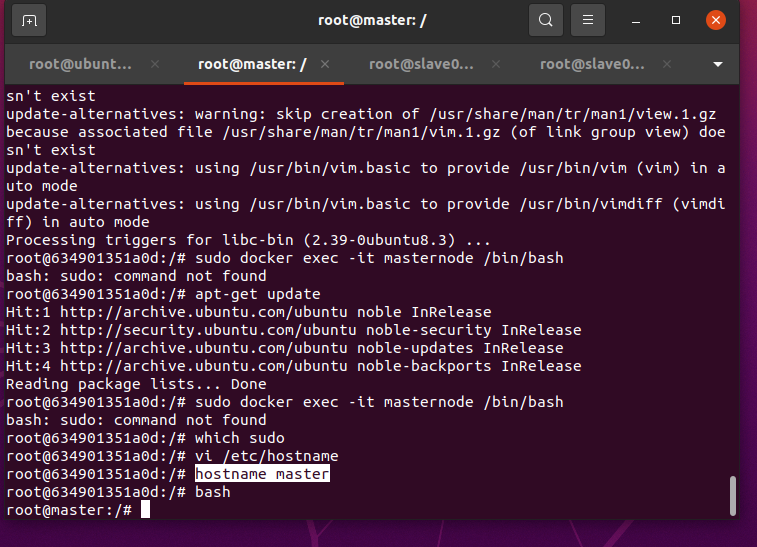
使用vim編輯masternode主機名
vi /etc/hostnamedocker容器中沒有vim包需要下載:
apt-get update
apt-get install -y vim同理將slave01和slave02也改好
使用Linux命令crontab配置定時任務進行自動時鐘同步(分別進入三個節點)
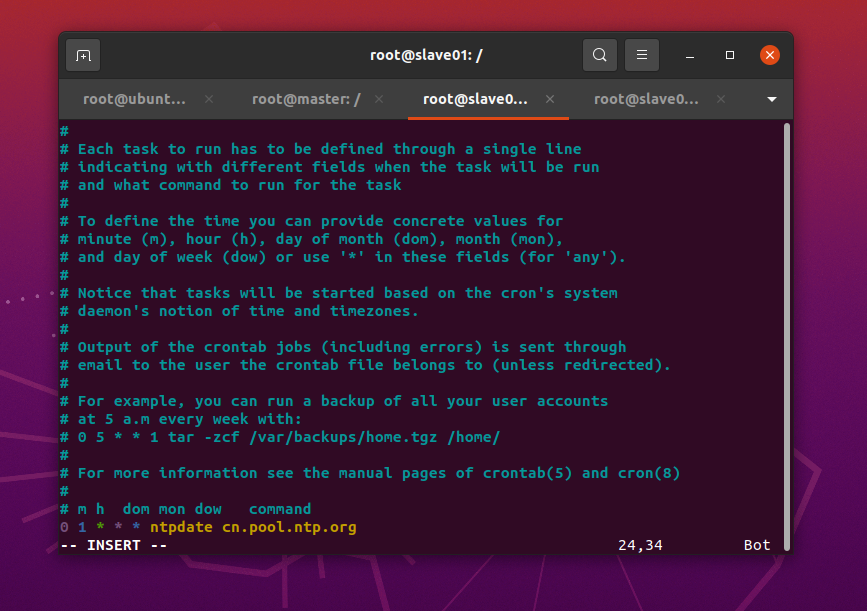
apt install -y croncrontab -e? ? 按”i ”鍵,進入INSERT模式;輸入下面的內容(星號之間和前后都有空格)??
0 1 * * * ntpdate cn.pool.ntp.org? ?按Esc鍵退出INSERT模式,按下“shift+:”鍵,輸入wq保存修改并退出
? 手動同步時間,直接在Terminal運行下面的命令
??
apt install -y ntpdatentpdate cn.pool.ntp.org
分別在三個節點配置hosts列表
在各虛擬機中運行ifconfig命令,獲得當前節點的ip地址
apt install -y net-toolsifconfig分別獲得三個結點的ip地址
編輯主機名列表文件
vi /etc/hosts將下面三行添加到/etc/hosts文件中,保存退出
#master節點對應IP地址是10.10.0.11,slave01對應的IP是10.10.0.12,slave02對應的IP是10.10.0.13
10.10.0.11 master
10.10.0.12 slave01
10.10.0.13 slave02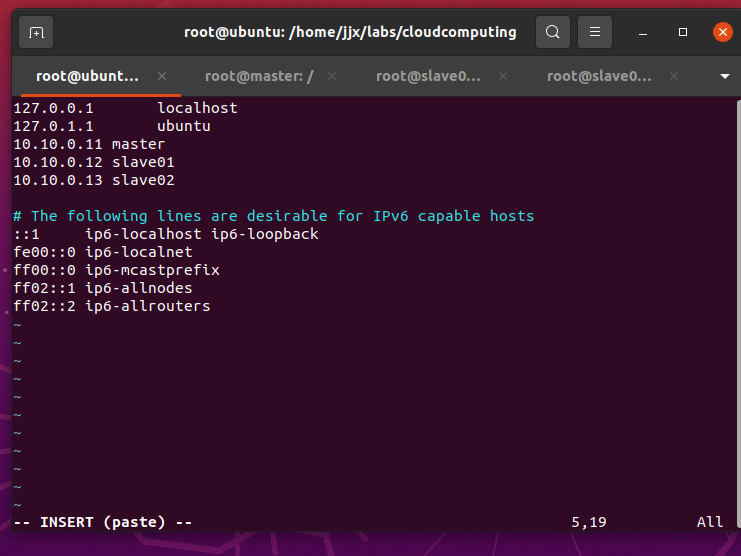
Ping主機名,按“Ctrl+C”終止命令
ping master
ping slave01
ping slave02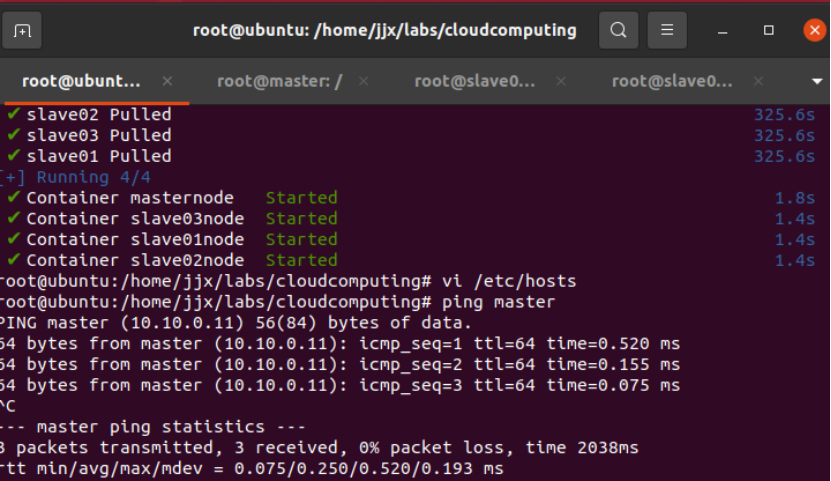
三個虛擬節點的免密碼登錄配置
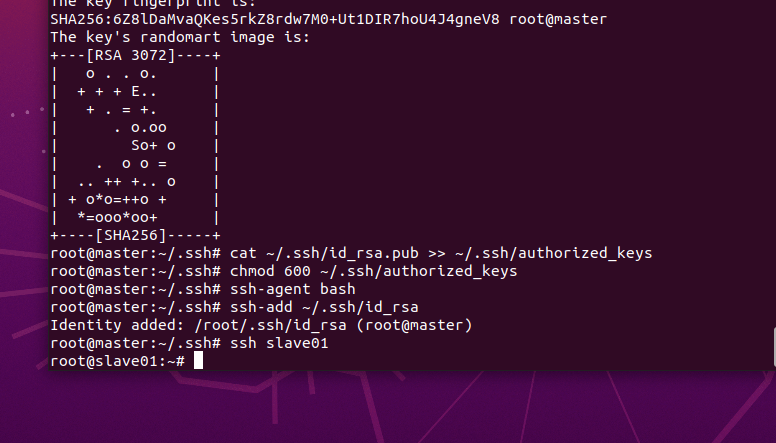
先在master節點上進行配置,生成rsa的SSH公鑰
apt install -y openssh-clientssh-keygen -t rsa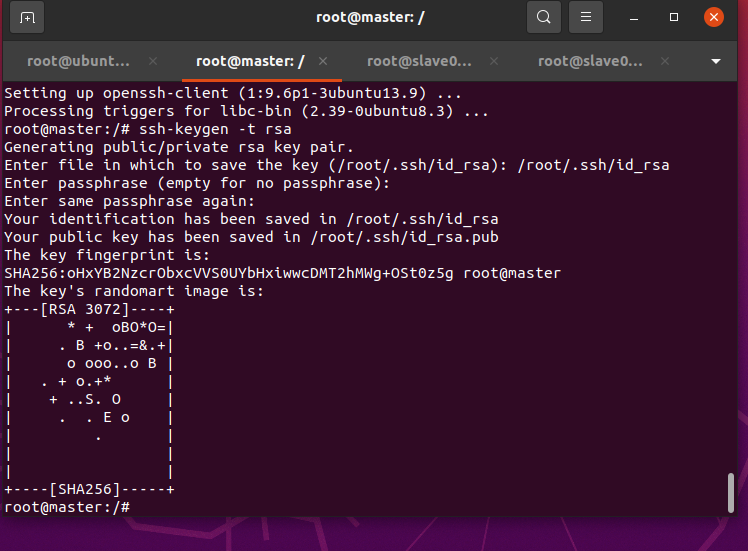
生成的密鑰在用戶根目錄中的.ssh子目錄中,進入.ssh目錄,查看目錄文件
cd ~/.ssh/ls
將id_rsa.pub 文件追加到authorized_keys文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys修改authorized_keys文件的權限,命令如下:
chmod 600 ~/.ssh/authorized_keys將專用密鑰添加到 ssh-agent 的高速緩存中
ssh-agent bashssh-add ~/.ssh/id_rsa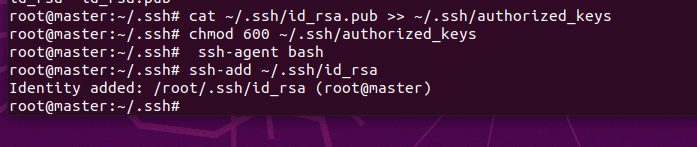
將authorized_keys文件復制到slave01、slave02節點root用戶的根目錄,命令(在宿主機終端下執行)如下:
sudo docker cp masternode:/root/.ssh/authorized_keys .sudo docker cp authorized_keys slave01node:/root/.ssh/sudo docker cp authorized_keys slave02node:/root/.ssh/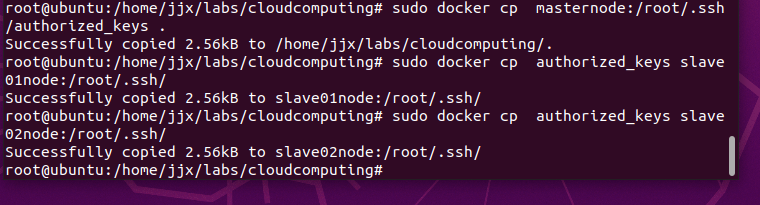
打開主機和三個節點的防火墻
apt install ufw -y驗證免密登陸
ssh slave01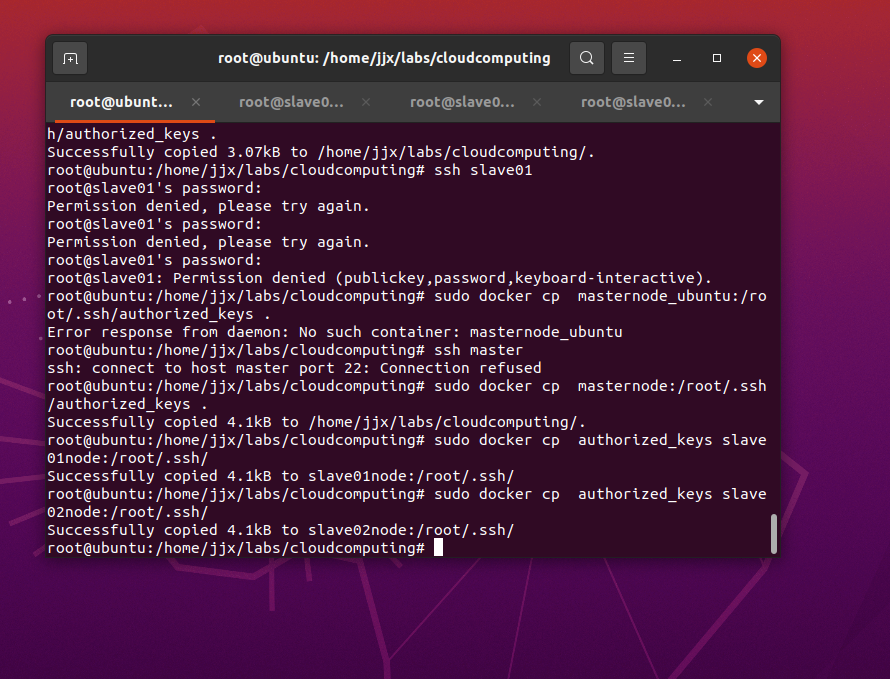
退出slave01遠程登錄
exit
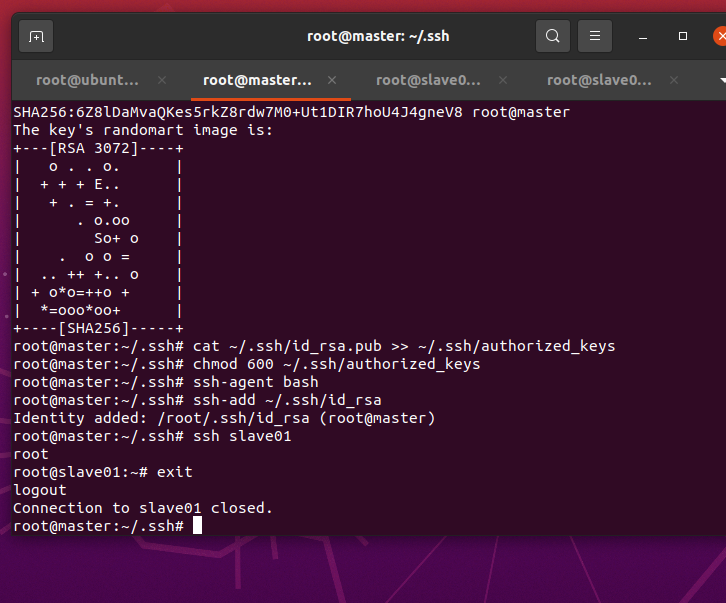
通過apt-get安裝JDK
apt-get install openjdk-8-jdk使用vim修改“.bashrc”
vi ~/.bashrc 復制粘貼以下內容添加到到上面vim打開的文件中:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$JAVA_HOME/bin:$PATH
使環境變量生效,查看Java版本
source ~/.bashrcjava -version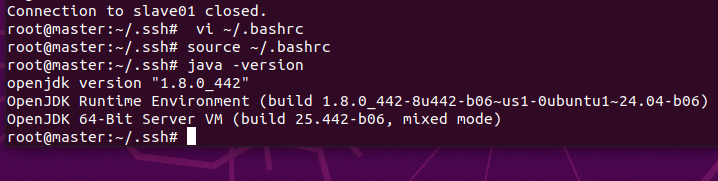
安裝部署Hadoop集群
說明:每個節點上的Hadoop配置基本相同,在master節點操作,然后復制到slave01、slave02兩個節點。
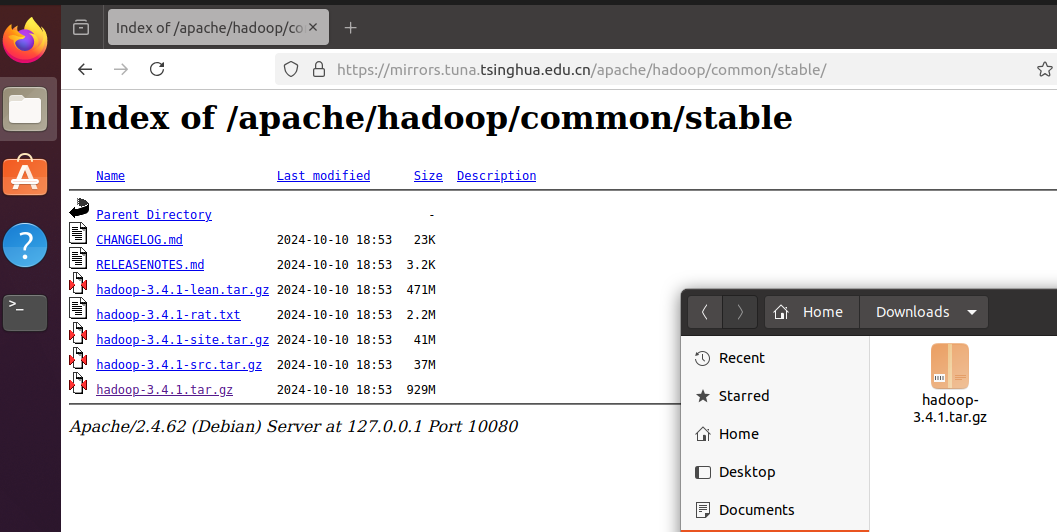
hadoop用Ubuntu自帶的火狐瀏覽器下載,鏡像地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
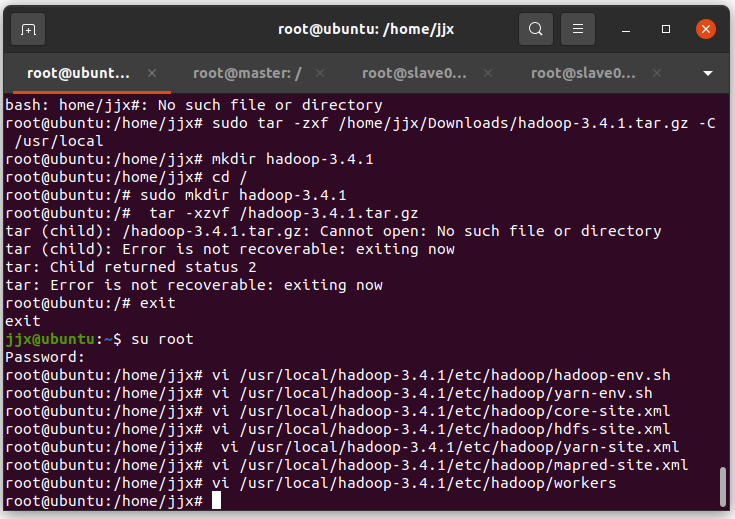
將/目錄下的hadoop-3.4.1.tar.gz壓縮包解壓到/hadoop-3.4.1目錄下:
sudo tar -zxf /home/Downloads/hadoop-3.4.1.tar.gz -C /usr/local-zxf后面的是剛才下載的壓縮包路徑,如果沒安裝輸入法打不了中文的可以直接找到剛才下載的那個壓縮包點復制然后粘貼到命令行就是路徑了
配置hadoop-env.sh文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/hadoop-env.sh在hadoop-env.sh文件中添加JAVA環境變量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
配置yarn-env.sh文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/yarn-env.sh在yarn-env.sh文件中添加JAVA環境變量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
配置core-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/core-site.xml復制粘貼以下內容,添加到上面vim打開的core-site.xml 文件中:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
</configuration>配置hdfs-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/hdfs-site.xml復制粘貼以下內容,添加到到上面vim打開的hdfs-site.xml 文件中:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>配置yarn-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/yarn-site.xml復制粘貼以下內容,添加到到上面vim打開的yarn-site.xml 文件中:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>配置mapred-site.xml 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/mapred-site.xml復制粘貼以下內容,添加到到上面vim打開的mapred-site.xml 文件中:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置workers 文件
vi /usr/local/hadoop-3.4.1/etc/hadoop/workers復制粘貼以下內容,添加到到上面vim打開的workers文件中:
slave01slave02
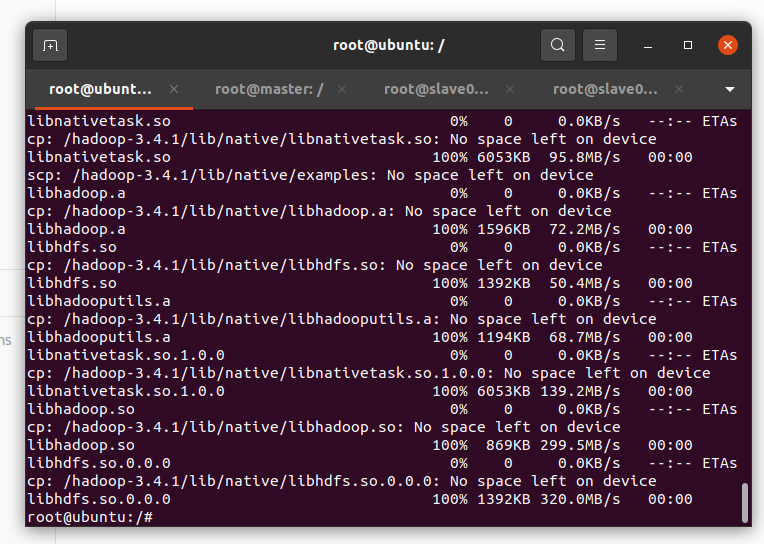
將配置好的hadoop-3.4.1文件夾復制到從節點
scp -r /usr/local/hadoop-3.4.1/ root@master:/
scp -r /usr/local/hadoop-3.4.1/ root@slave01:/
scp -r /usr/local/hadoop-3.4.1/ root@slave02:/如果輸入密碼錯誤:需要在從節點用 passwd root命令設置密碼
如果顯示無法連接錯誤:
?安裝 OpenSSH 服務端
apt update && apt install -y openssh-server啟動 SSH 服務
service ssh start 配置 SSH
vi /etc/ssh/sshd_config添加:
PermitRootLogin yes # 允許 root 登錄(僅測試環境)
PasswordAuthentication yes重啟ssh服務:
?
service ssh restart 結果如下:
配置Hadoop環境變量(在三臺節點分別操作此步驟)
vi ~/.bashrc在.bashrc末尾添加如下內容:
##HADOOP
export HADOOP_HOME=/hadoop-3.4.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH使環境變量生效
source ~/.bashrc 格式化Hadoop文件目錄(在master上執行)
說明:格式化后首次執行此命令,提示輸入y/n時,輸入y。
hdfs namenode -format 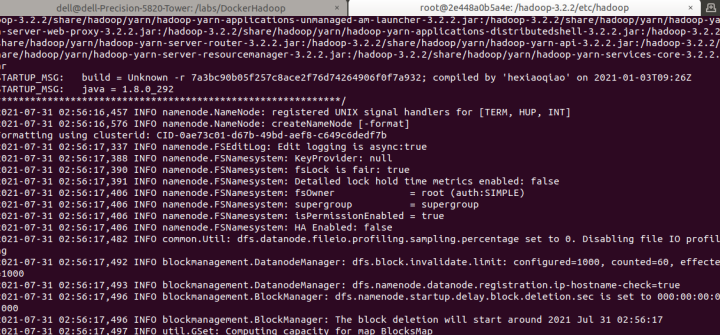
啟動Hadoop集群(在master上執行):
start-all.sh查看Hadoop進程是否啟動,在master的終端執行jps命令,出現下圖效果
jps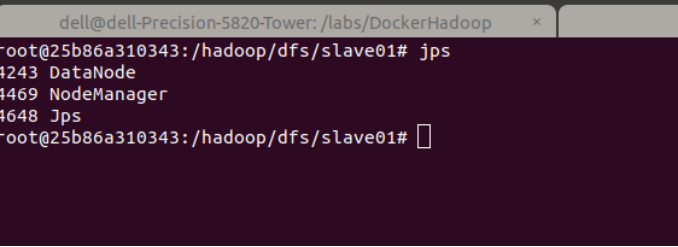
瀏覽器地址欄中輸入http://127.0.0.1:9870/,檢查namenode 和datanode 是否正常,如下圖所示:
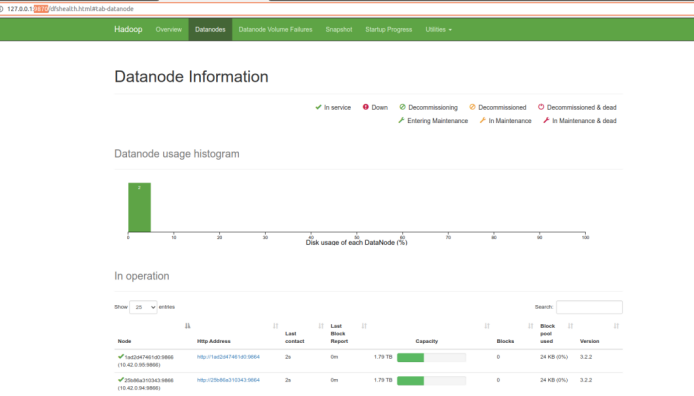
在瀏覽器地址欄中輸入http://127.0.0.1:18088/,檢查Yarn是否正常,如下圖所示:
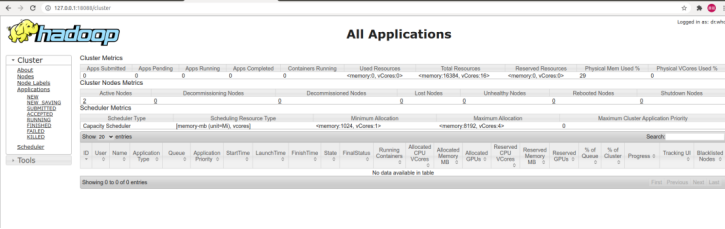
運行PI實例檢查集群是否成功,成功如下圖所示:
hadoop jar /hadoop-3.4.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar pi 10 10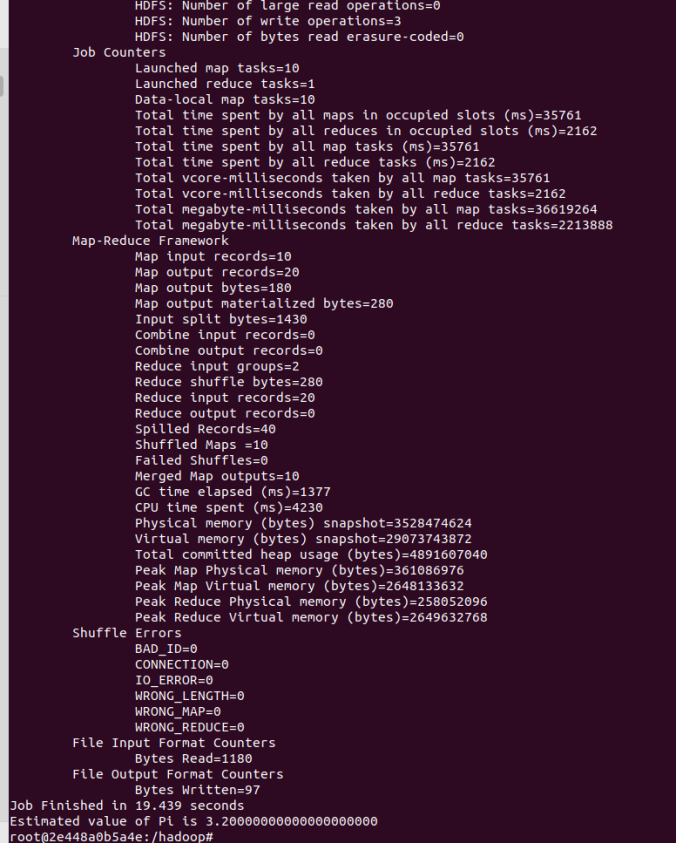
其他細節事項:
首先打開VMware虛擬機,進入Ubuntu操作系統,進入終端:
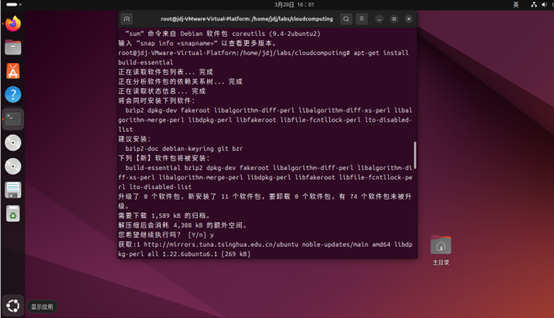
然后在終端切換到root用戶:
設置 root 用戶的密碼:
sudo passwd root輸入密碼后切換到root模式:
su root在Linux安裝軟件時需要用到yum命令,也可以是apt-get命令,以下介紹如何在ubtuntu中安裝配置yum
接下來是安裝build-essential程序包和yum:
apt-get install build-essential
apt-get install yum在安裝yum后可能會遇到以下報錯:
E: Unable to locate package?yum
這時候需要手動下載yum:
- 備份sources.list文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup
? ? ?2.更換源
sudo vim /etc/apt/sources.list如果這個時候報錯無法發現vim
sudo apt-get update
sudo apt-get install vim
按照上述方式下載vim
? ? ?3.vim編輯
接下來會進入到sources.list的內容里進行編輯
- 點擊insert進入編輯模式
- 將下面網站文本復制粘貼并覆蓋,粘貼的命令是 shift + insert。記得選擇相應的Linux版本,此處為Ubuntu 20.04
在第一行添加鏡像源如下:
deb http://archive.ubuntu.com/ubuntu/ trusty main universe restricted multiverse
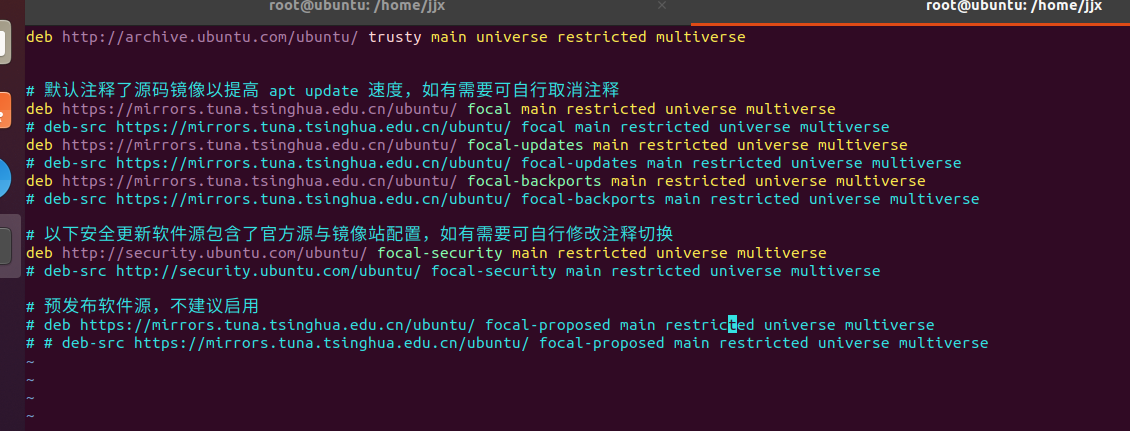
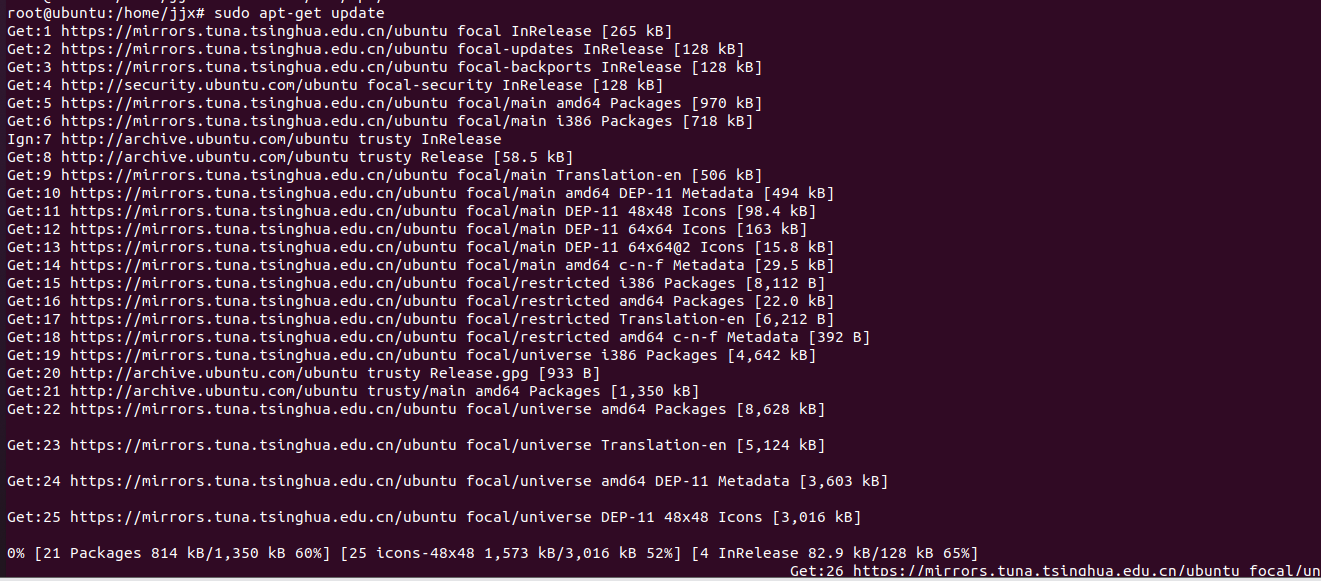 ? ? ? ?4.更新源
? ? ? ?4.更新源
sudo apt-get update
? ? ? 5.安裝yum
sudo apt-get install yum
然后如果有以下提示:
The following packages have unmet dependencies:
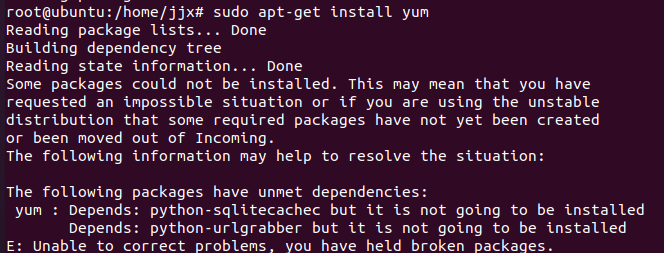
按照提示逐一安裝依賴:
sudo apt-get install python-sqlitecachec
sudo apt-get install python-pycurl
sudo apt-get install python-urlgrabber再次安裝yum:
sudo apt-get install yum
安裝yum成功:
yum --version
最后將自己配置的repo文件用yum-config-manager進行yum軟件源添加:
yum-config-manager --add-repo /etc/yum.repo.d/my.repo
?通過使用yum repolist命令查看時,由于剛下載yum,顯示庫的軟件信息為0
這時需要配置yum源
參考這篇博主的文章:
# ubuntu 系統使用 yum命令報錯 There are no enabled repos.Run “yum repolist all“ to see the repos you have..._there are no enabled repos. run "yum repolist all"-CSDN博客
好了之后就可以安裝了
yum upgradeyum install net-tools
設置root密碼
在docker容器內,初始化root密碼,用于下一步的登錄。
passwd root


)
筆記250407)




:進階應用篇——Python 腳本自動化與三維可視化)




)
)
)


