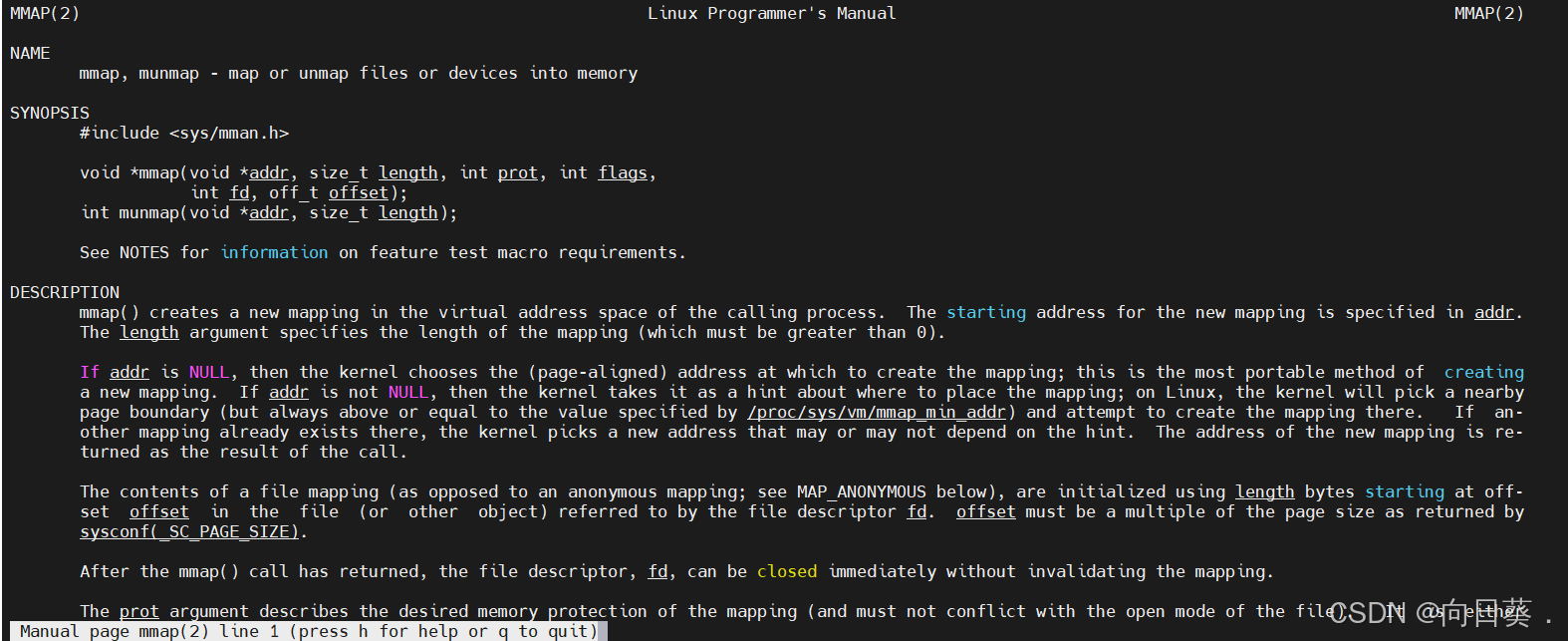
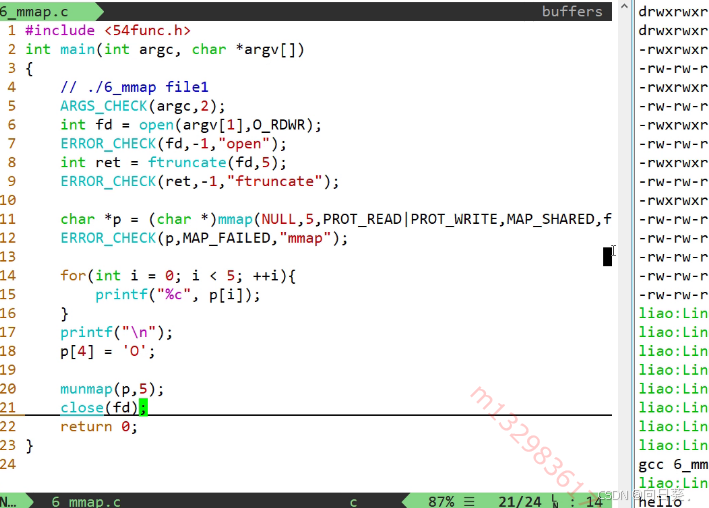
在用戶態申請內存,內存內容和磁盤內容建立一一映射
讀寫內存等價于讀寫磁盤
支持隨機訪問
簡單來說,把磁盤里的數據與內存的用戶態建立一一映射關系,讓讀寫內存等價于讀寫磁盤,支持隨機訪問。
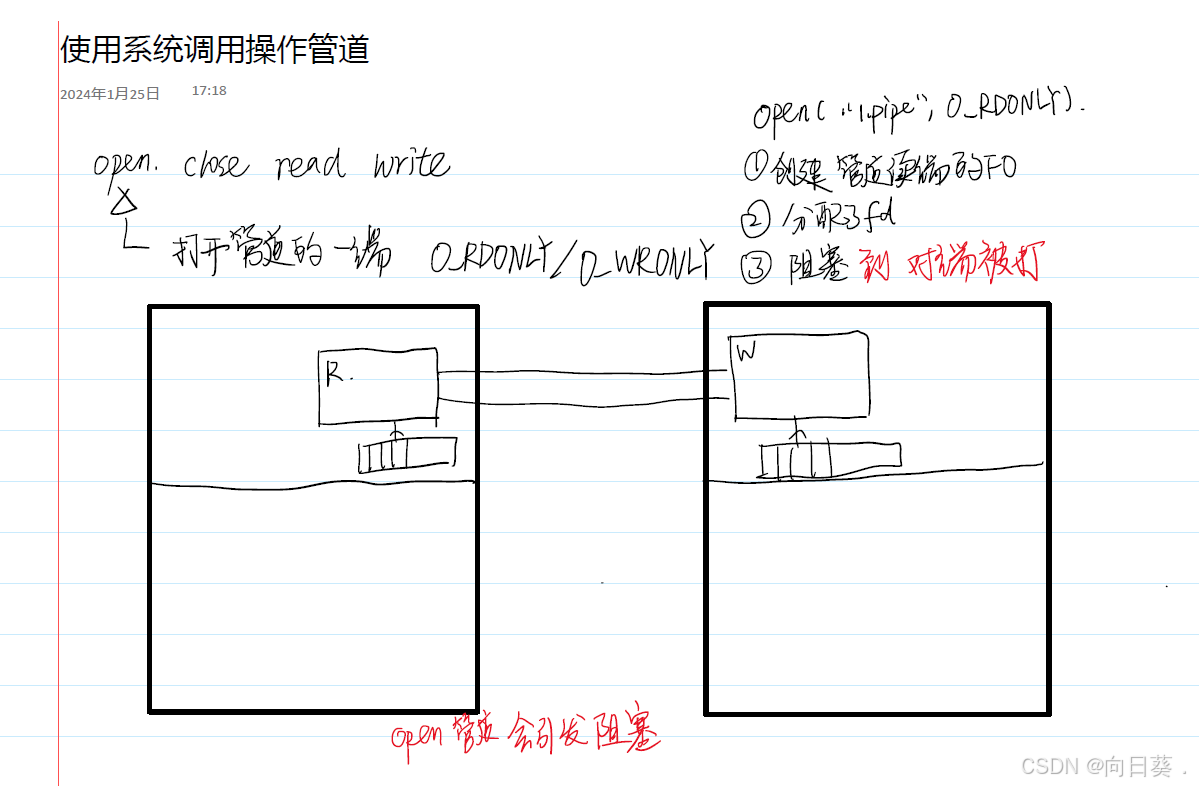
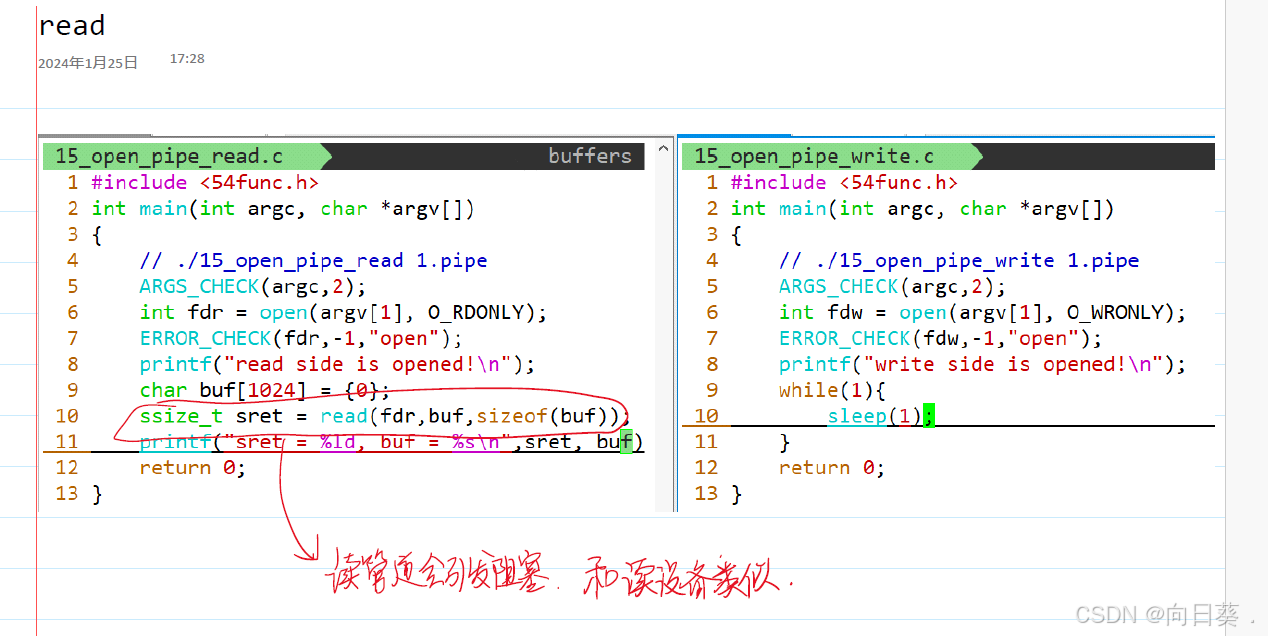
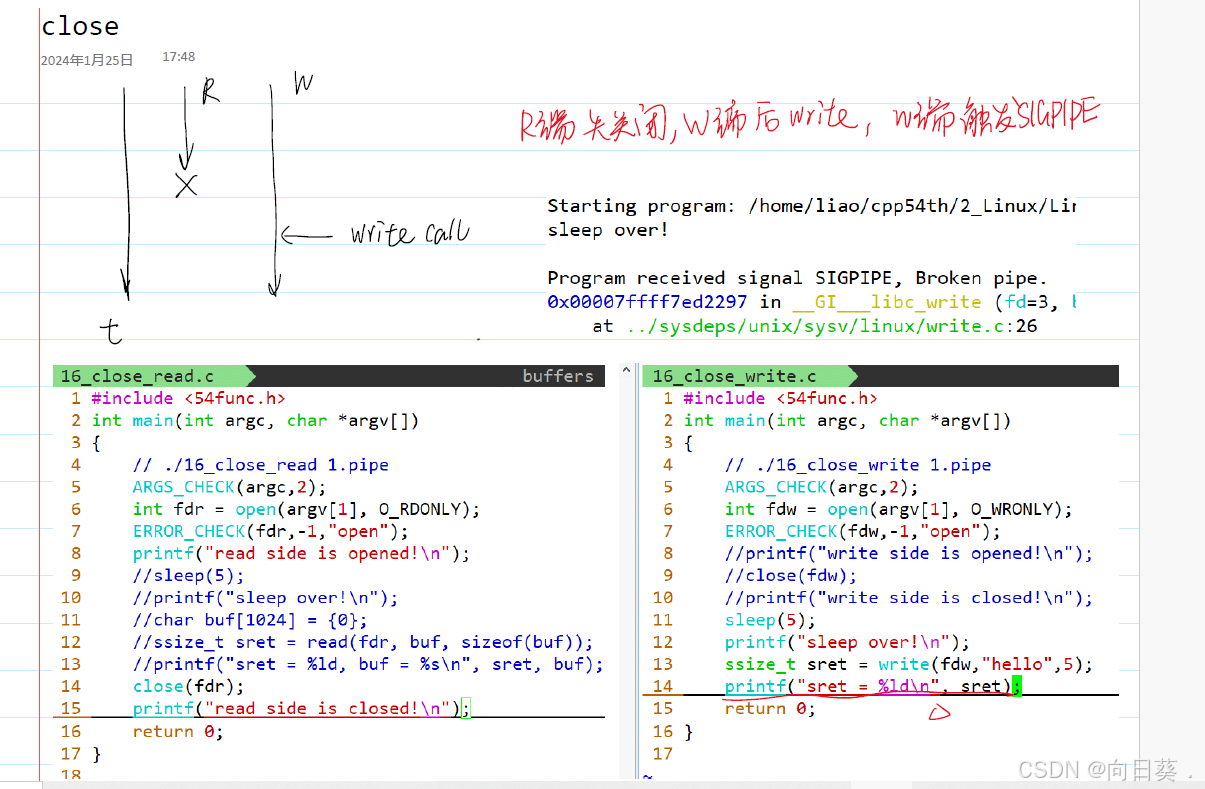
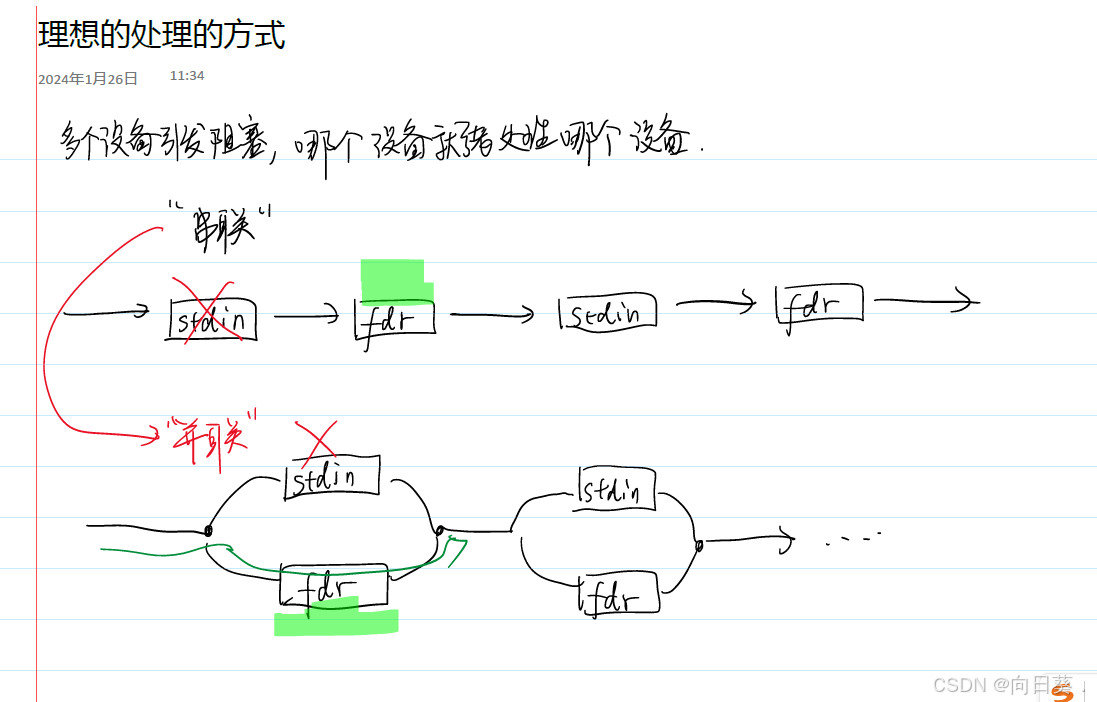
管道文件:進程間通信機制,不占用磁盤空間
named pipe /FIFO 命名管道:在文件系統中存在路徑
進程之間溝通可以通過磁盤文件溝通
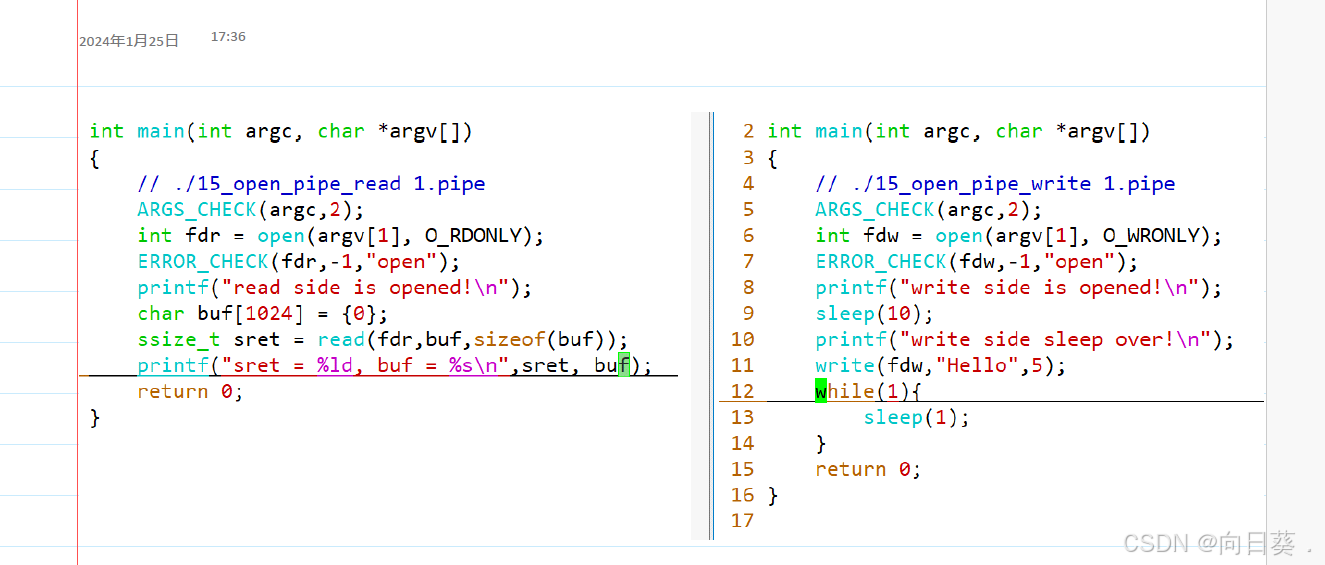
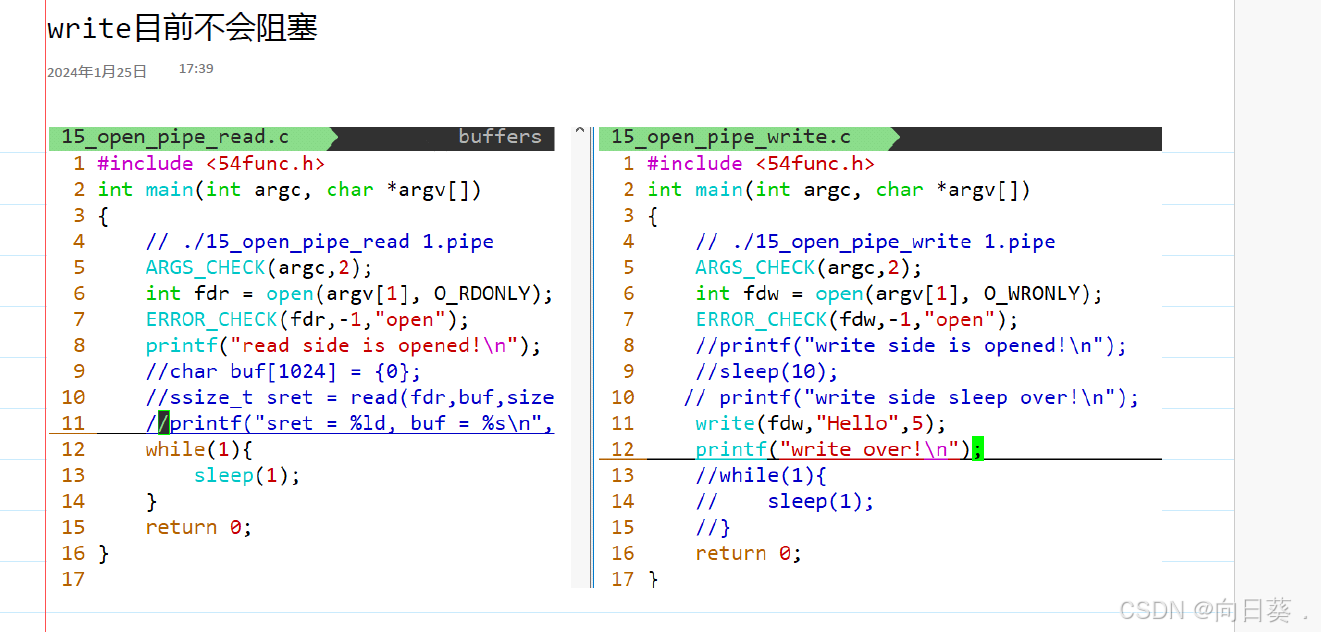
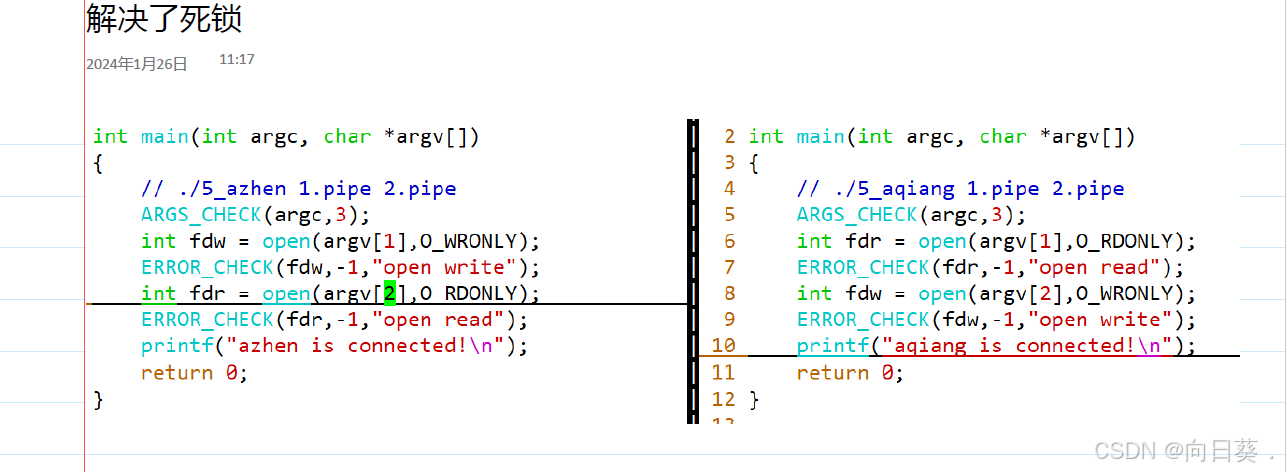
創建管道?mkfifo 1.pipe


管道需要兩個進程通信才能使用






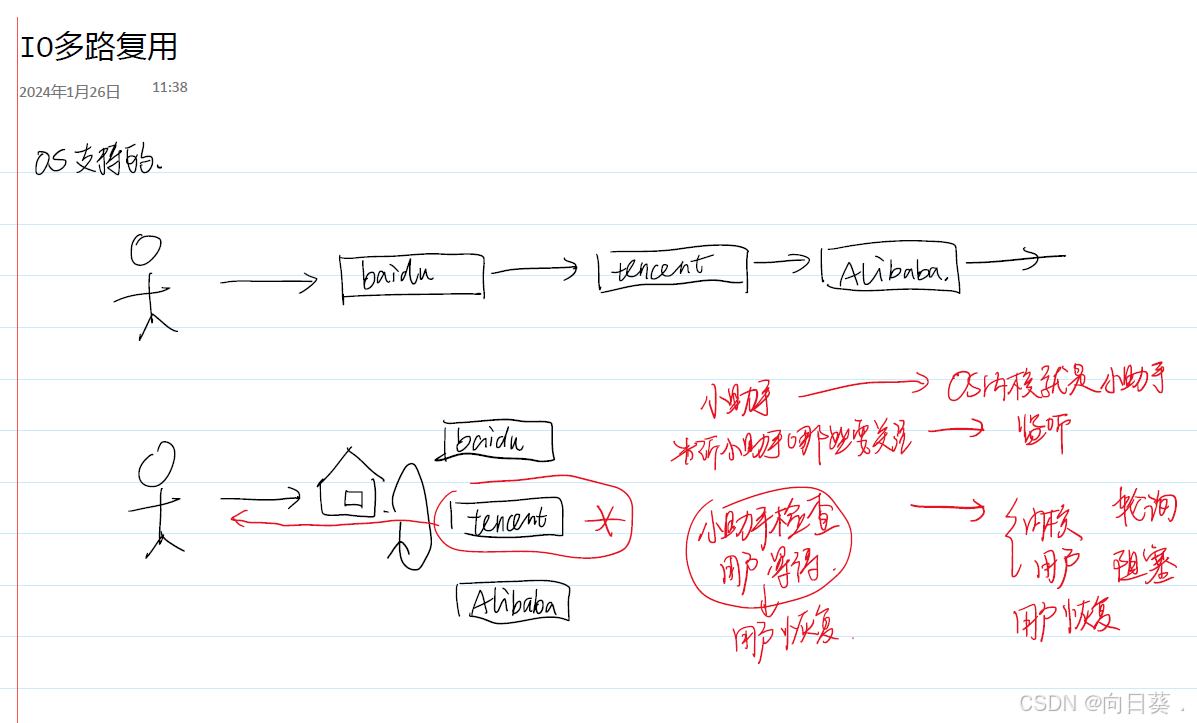
IO多路復用詳解
1.?概念與背景
IO多路復用(I/O Multiplexing)是一種高效的IO處理機制,允許單個進程/線程同時監控多個文件描述符(如套接字)的IO事件(如可讀、可寫、異常)。當任意一個文件描述符的狀態發生變化時,系統通知應用程序進行相應的處理,從而避免阻塞和線程資源的浪費。
背景:
- 在高并發網絡編程中,傳統阻塞IO模型(BIO)需要為每個連接創建一個線程,導致線程數量爆炸式增長,系統資源耗盡。
- 非阻塞IO模型(NIO)雖然避免了線程阻塞,但需要頻繁輪詢所有文件描述符,消耗大量CPU資源。
- IO多路復用通過事件驅動機制,解決了BIO和NIO的缺陷,成為高并發網絡編程的核心技術。
2.?核心機制
IO多路復用的核心是事件通知機制,通過系統調用(如select、poll、epoll等)將多個文件描述符注冊到內核,由內核監控這些描述符的狀態變化。當有事件發生時,內核通知應用程序,應用程序再處理對應的事件。
關鍵點:
- 事件驅動:應用程序無需主動輪詢,而是被動等待內核通知。
- 單線程處理:一個線程可以同時處理多個連接,減少線程切換開銷。
- 高效性:內核只通知就緒的文件描述符,避免無效的輪詢。
3.?實現方式
IO多路復用的實現方式主要有以下幾種:
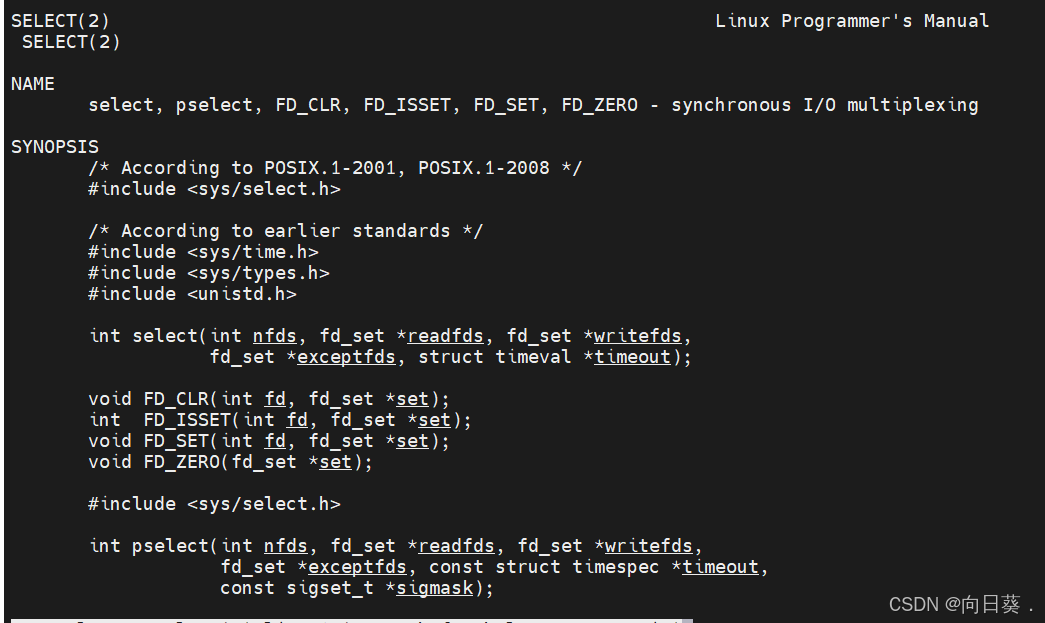
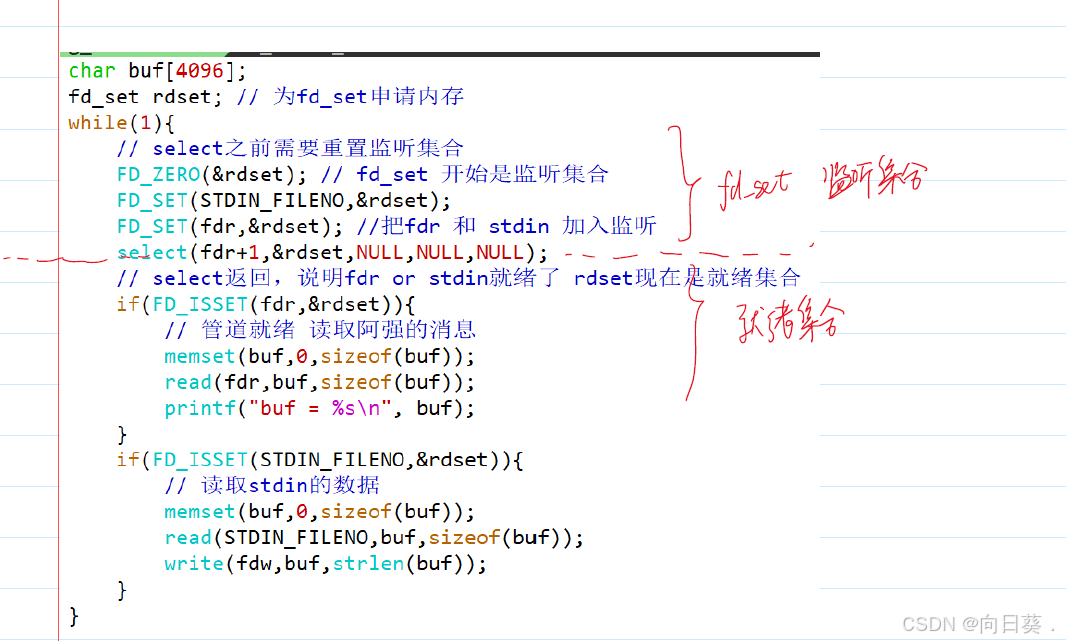
(1)select
- 原理:將文件描述符集合(
fd_set)傳遞給內核,內核遍歷集合,檢查哪些描述符就緒。 - 缺點:
- 文件描述符數量受限(通常為1024)。
- 每次調用都需要重新構造
fd_set,并拷貝到內核空間,開銷較大。 - 內核遍歷整個集合,時間復雜度為O(n)。
- 適用場景:低并發、文件描述符數量較少的場景。
(2)poll
- 原理:使用
pollfd結構體數組替代fd_set,每個元素包含文件描述符和需要監控的事件。 - 改進:
- 取消了文件描述符數量限制。
- 無需每次重新構造集合,只需修改
pollfd數組。
- 缺點:
- 仍然需要內核遍歷整個數組,時間復雜度為O(n)。
pollfd數組需要用戶態和內核態之間的拷貝。
- 適用場景:中低并發、文件描述符數量較多的場景。
(3)epoll(Linux特有)
- 原理:基于事件通知機制,內核維護一個就緒隊列,當文件描述符就緒時,直接將其加入就緒隊列。
- 改進:
- 邊緣觸發(ET):只通知一次狀態變化,減少通知次數。
- 水平觸發(LT):持續通知,直到狀態變化被處理。
- 就緒隊列:內核直接返回就緒的文件描述符,無需遍歷。
- 優點:
- 支持大量文件描述符(理論上無上限)。
- 時間復雜度為O(1),高效處理高并發。
- 適用場景:高并發、海量連接的場景。
4.?工作原理
以epoll為例,其工作原理如下:
- 創建epoll實例:調用
epoll_create創建一個epoll對象,返回一個文件描述符。 - 注冊文件描述符:調用
epoll_ctl將需要監控的文件描述符和事件類型(如可讀、可寫)注冊到epoll對象中。 - 等待事件:調用
epoll_wait阻塞等待,直到有文件描述符就緒。 - 處理事件:內核將就緒的文件描述符和事件類型返回給應用程序,應用程序處理對應的事件。
5.?優勢
- 高效性:通過事件通知機制,避免無效的輪詢和阻塞。
- 可擴展性:支持大量并發連接,適用于高并發場景。
- 資源節省:減少線程數量,降低線程切換和內存占用。
6.?應用場景
- Web服務器:如Nginx、Lighttpd,使用
epoll處理海量HTTP連接。 - 網絡庫:如libuv(Node.js底層)、Boost.Asio,基于IO多路復用實現異步IO。
- 實時通信:如IM系統、游戲服務器,處理大量長連接。
- 數據庫連接池:管理多個數據庫連接,避免阻塞。
高并發IO(Input/Output)?是指系統在?短時間內需要處理大量的輸入輸出請求?的場景。它通常出現在需要同時服務大量用戶或設備的應用中,例如網站、數據庫、消息隊列、分布式存儲系統等。
一、核心概念解析
- 高并發
- 定義:系統在同一時間需要處理大量并發請求(如每秒數千次甚至上百萬次)。
- 挑戰:資源(CPU、內存、網絡、磁盤)的競爭,可能導致性能瓶頸。
- IO(輸入輸出)
- 定義:系統與外部設備(如磁盤、網絡)的數據交互。
- 特點:IO操作通常比CPU計算慢幾個數量級,因此容易成為性能瓶頸。
- 高并發IO的挑戰
- 傳統IO模型:每個請求需要等待IO操作完成,導致線程阻塞,資源利用率低。
- 目標:在保證高并發的同時,優化IO性能,減少延遲。
二、高并發IO的典型場景
- Web應用
- 大量用戶同時訪問網站,服務器需要快速響應HTTP請求,讀取數據庫或文件系統中的數據。
- 數據庫
- 高并發讀寫操作,例如電商平臺的秒殺活動,大量用戶同時查詢或更新商品庫存。
- 消息隊列
- 生產者和消費者同時發送和接收消息,系統需要高效處理消息的存儲和分發。
- 分布式存儲
- 大量客戶端同時讀寫存儲節點,例如云存儲服務需要處理海量文件上傳和下載請求。
三、高并發IO的核心技術
- 異步IO(Asynchronous IO)
- 原理:線程發起IO請求后,無需等待操作完成,可以繼續處理其他任務。
- 優勢:減少線程阻塞,提高資源利用率。
- 實現:
- Linux的
epoll、kqueue等事件驅動模型。 - Java的
NIO(Non-blocking IO)和AIO(Asynchronous IO)。
- Linux的
- 多路復用(IO Multiplexing)
- 原理:單個線程可以同時監控多個IO通道,當某個通道準備好時,再處理該通道的請求。
- 工具:
select、poll、epoll(Linux)、kqueue(BSD)。
- 非阻塞IO(Non-blocking IO)
- 原理:IO操作不會阻塞線程,而是立即返回一個狀態(如“未完成”),線程可以繼續執行其他任務。
- 應用:結合事件循環(Event Loop)實現高效IO處理。
- 緩存
- 原理:將頻繁訪問的數據存儲在內存中,減少對磁盤或網絡的訪問。
- 工具:Redis、Memcached等內存數據庫。
- 分布式系統
- 原理:將IO負載分散到多個節點上,避免單點瓶頸。
- 技術:分片(Sharding)、復制(Replication)、負載均衡(Load Balancing)。
四、高并發IO的優化策略
- 減少IO操作
- 合并小IO請求為批量請求。
- 使用批量寫入(Batch Write)減少磁盤訪問次數。
- 異步化
- 將耗時的IO操作異步化,避免阻塞主線程。
- 例如:使用異步HTTP客戶端(如
aiohttp)處理網絡請求。
- 資源隔離
- 為不同類型的請求分配獨立的資源池,避免資源爭用。
- 例如:為數據庫連接、線程池設置合理的上限。
- 監控與調優
- 使用監控工具(如Prometheus、Grafana)實時觀察系統性能。
- 根據監控數據調整線程池大小、緩存策略等參數。
五、高并發IO的實踐案例
- 電商秒殺系統
- 挑戰:高并發讀寫數據庫,可能導致數據庫崩潰。
- 解決方案:
- 使用Redis緩存商品庫存,減少數據庫壓力。
- 使用消息隊列(如Kafka)異步處理訂單請求。
- 實時日志系統
- 挑戰:大量日志數據需要快速寫入磁盤,同時支持實時查詢。
- 解決方案:
- 使用
epoll實現高效的日志收集。 - 將日志存儲在分布式文件系統(如HDFS)中,支持水平擴展。
- 使用
- 游戲服務器
- 挑戰:大量玩家同時發送和接收游戲狀態更新。
- 解決方案:
- 使用UDP協議進行實時通信,減少延遲。
- 使用狀態同步機制,減少網絡帶寬占用。
六、總結
- 高并發IO的核心:在保證高并發的同時,優化IO性能,減少延遲。
- 關鍵技術:異步IO、多路復用、非阻塞IO、緩存、分布式系統。
- 優化方向:減少IO操作、異步化、資源隔離、監控與調優。
通過合理設計和優化,系統可以在高并發場景下實現高效、穩定的IO處理
)
筆記250407)




:進階應用篇——Python 腳本自動化與三維可視化)




)
)
)




