💫《博主主頁》:奈斯DB-CSDN博客
🔥《擅長領域》:擅長阿里云AnalyticDB for MySQL(分布式數據倉庫)、Oracle、MySQL、Linux、prometheus監控;并對SQLserver、NoSQL(MongoDB)有了解
💖如果覺得文章對你有所幫助,歡迎點贊收藏加關注💖

? ? 最近公司某個項目組,因為業務擴展所以需要在數據庫中存儲越南語,當前這套Oracle實例由于當時在搭建時使用的是GBK字符集,所以存儲越南語就會存在亂碼,因為 ZHS16GBK字符集只對漢字、英文字符、數字,+-*/等進行了編碼,沒有對越南語進行編碼所以存儲越南語時就會有亂碼 ;而AL32UTF8字符集,基本上對全世界的字符進行了編碼存儲,對于越南語而言支持所有帶聲調的越南文字符(?, ?, ?, ?等)【AL32UTF8不僅僅可以存儲越南語,還可以存儲日文、韓文等等】?,那么就需要將業務用戶由ZHS16GBK字符集轉成AL32UTF8。
? ?小伙伴們都知道數據泵可以完成對全庫、單個生產用戶、生產表、某個表空間的遷移,這些都是難度比較小的操作,如果有一個場景因為業務擴展需要存儲 日文、越南語 ,現在的Oracle字符集是ZHS16GBK,但是,需要將Oracle的字符集改成AL32UTF8去存儲日文、越南語,那么又應該怎么辦呢?
? ? 既然拋出了這個問題就要解決這個問題,我先給出答案——最安全的辦法就是重建一個實例,然后修改char/varchar2數據類型的長度,最后通過expdp/impdp數據泵導入進去,當前數據庫實例上有多個業務用戶,好在只有這一個業務用戶有遷移字符集的需求,那么本篇文章主要是通過數據泵完成對一個業務用戶字符集的遷移,即使是全庫用戶都需要轉換字符集也是一樣的流程。那么帶著這個問題,讓我們開始今天的內容,通過expdp/impdp輕松完成某個生產用戶從GBK到UTF8編碼的遷移。
? ? ? ? ??
特別說明💥:本篇文章部分知識點均來源于 Oracle 公開可查的官方文檔手冊,并結合了我個人的理解和案例演示。如有沖突,請聯系,會立即處理。轉載請標明出處😄
? ? ? ??
官方文檔對于字符集作用的介紹(Oracle 19c):
Choosing a Character Set
? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
官方文檔對于字符集遷移的介紹(Oracle 19c):
Character Set Migration
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
目錄
源生產庫(ZHS16GBK,實例liudbywcs,RAC環境)部分
目標庫(AL32UTF8,實例baj,RAC環境)部分
驗證數據部分
? ? ? ? ? ? ? ? ? ? ??
Oracle字符集的作用:
? ? Oracle數據庫中的字符集(Character Set)是數據庫全球化支持(NLS)的核心組成部分,它的存在和設計源于計算機處理多語言文本的基本需求。以下是Oracle官方文檔中闡述的字符集作用和存在原因:
字符編碼映射
建立二進制數據與人類可讀字符之間的對應關系
例如:在ZHS16GBK中
0xB0A1對應"啊",在AL32UTF8中0xE5958A對應同一個漢字數據存儲規范
定義每個字符占用的存儲空間(單字節/多字節)
例如:US7ASCII每個字符固定1字節,AL32UTF8中文常用字占3字節
排序與比較規則
決定
ORDER BY、WHERE條件比較等操作的排序規則不同字符集對相同字符的排序順序可能不同
? ? ? ? ? ? ? ? ? ? ? ??
Oracle常用字符集:
1.US7ASCII - 基礎ASCII字符集基本特性:
7位編碼標準,共128個字符(0x00-0x7F)
不支持任何擴展字符
每個字符固定占用1字節存儲空間
支持范圍:
英文字母(A-Z, a-z)
數字(0-9)
基本標點符號和特殊字符(!@#$%^&*等)
控制字符(換行、回車等)
典型問題:
-- 嘗試存儲非ASCII字符會報錯或顯示為? INSERT INTO test VALUES ('中文'); -- 結果: ??適用場景:
純英文應用系統
遺留系統維護
需要最小存儲開銷的環境
? ? ? ? ? ?
? ? ? ? ??
2. ZHS16GBK - 簡體中文字符集
編碼結構:
擴展GB2312標準,支持21003個漢字
雙字節編碼(0x8140-0xFEFE)
兼容ASCII(0x00-0x7F單字節)
字符范圍:
簡體中文(GB 18030-2000基本集)
常見繁體字
中文標點符號(全角)
部分日文假名和特殊符號
存儲示例:
"中國" -> 0xD6D0 0xB9FA (2個雙字節編碼) "ABC" -> 0x41 0x42 0x43 (單字節ASCII兼容)局限性:
不支持越南語、泰語等東南亞文字
部分生僻字可能無法顯示
? ? ? ?
? ? ? ? ??
3. JA16SJIS - 日文字符集
編碼特點:
基于Shift-JIS編碼標準
混合單字節(ASCII)和雙字節編碼
包含JIS X 0201和JIS X 0208字符集
字符組成:
全角假名(平假名、片假名)
日文漢字(常用約6000字)
半角假名和符號
英數字(半角/全角)
編碼示例:
"日本語" -> 0x93FA 0x967B 0x8CEA (3個雙字節編碼) "ハンカク" -> 0xB1 0xB2 0xB3 0xB4 (半角假名)注意事項:
與EUC-JP編碼不兼容
某些特殊符號可能顯示異常
? ? ?
? ?
4. KO16KSC5601 - 韓文字符集
標準規范:
基于KS C 5601-1987標準
完全雙字節編碼(0xA1A1-0xFEFE)
包含2350個韓文音節和4888個漢字
字符構成:
韓文字母(諺文)
常用漢字
特殊符號和圖形字符
編碼特性:
"??" -> 0xC7D1 0xB1B9 (2個雙字節) "大韓民國" -> 0xB4EB 0xC7D1 0xB9DD 0xB0FA (4個雙字節)使用限制:
不包含部分新造韓文字
漢字數量有限
? ?
? ? ? ??
5. AL32UTF8 - Unicode字符集
核心優勢:
完整Unicode支持(最新版本)
可變長度編碼(1-4字節/字符)
兼容所有語言字符
編碼方式:
ASCII字符:1字節(0x00-0x7F)
歐洲文字:通常2字節(如é: 0xC3A9)
中文/日文/韓文:通常3字節(中: 0xE4B8AD)
特殊符號/罕見字:4字節
存儲對比:
GBK中的"中國":4字節(D6D0 B9FA) UTF8中的"中國":6字節(E4B8AD E59BBD)關鍵特性:
-- 多語言混合存儲示例 INSERT INTO multilingual VALUES ('中文Chinese日本語??語Vi?tNam');實施建議:
字段長度調整:VARCHAR2(100)可能需擴大
排序規則:使用NLS_SORT參數指定
性能考慮:索引大小可能增加
? ? ? ??
比較總結:
特性 US7ASCII ZHS16GBK JA16SJIS KO16KSC5601 AL32UTF8 編碼范圍 128字符 2.1萬漢字 6千日文 7千韓文 全Unicode 存儲效率 最高 高 中 高 可變 多語言支持 僅英文 中/英 日/英 韓/中/英 全球語言 字節/字符 1 1或2 1或2 2 1-4 推薦場景 純英文 簡體中文 日文系統 韓文系統 國際系統 ? ? ? ? ? ? ?
遷移建議:從任何單語言字符集遷移到AL32UTF8時,需特別注意:
字段長度可能不足(UTF8通常需要更多空間)
應用程序可能需要調整字符處理邏輯
導出/導入時明確指定字符集轉換
? ? ? ??
字符集存儲數據相關參數:
SQL> show parameter NLS_LENGTH_SEMANTICSNLS_LENGTH_SEMANTICS:用于指定長度語義,有兩個值BYTE、CHAR。mysql的字符集轉換不同于oracle,因為oracle是字節byte所以涉及到列長度的轉換,但mysql是存儲是用char,所以不涉及到列的轉換。但是Oracle可以通過NLS_LENGTH_SEMANTICS參數設置用BYTE還是CHAR存儲數據,默認是BYTE字節存儲。這個參數主要是針對char和varchar2這兩種數據類型,數據存儲是使用字節byte還是字符char設計的。對于NCHAR、NVARCHAR2、CLOB和NCLOB列始終基于char字符。
- BYTE:以字節的形式存儲數據,默認值。gbk遷移到utf8就會涉及到char和varchar2數據類型的長度轉換。
- CHAR:以字符的形式存儲數據,gbk遷移到utf8不會涉及到長度轉換。
注意:Oracle強烈建議不要在運行的實例中將參數設置為CHAR,因為可能導致許多現有安裝腳本或者表數據意外地創建具有字符長度語義的列,從而導致運行時錯誤,包括緩沖區溢出。可以考慮在新實例中修改,新實例修改參考下面的案例一,修改長度語義只對后續手動創建的表生效,現有表還是原byte
? ? ? ? ? ? ? ? ? ??
? ? 首先了解為什么遷移字符集需要修改char/varchar2數據類型的長度,而不需要修改數值、日期等數據類型的長度。下面我們先看案例——漢字和字符在char/varchar2/nchar/nvarchar2數據類型中的占用的字節:
-
char(n)存放定長的字符串,最大存放2000 bytes
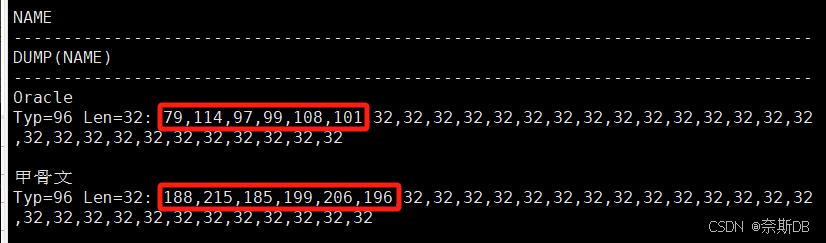
AMERICAN_AMERICA.ZHS16GBK(一個字符1字節,一個漢字為2字節)
SQL> create table liu_oracleoltp_ywcs_t1_gbk (name char(32)); ###創建字段為char32數據類型的liu_oracleoltp_ywcs_t1_gbk表,數據類型的字符串長度一般是16的倍數,例32,64,128等 SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t1_gbk values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t1_gbk values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t1_gbk; ###dump為展現這個行(name)的詳細內容 ###插入數據的詳細內容,數字代表字碼,79代表字母O,空格用32代碼表示
? ? ? ? ? ? ? ? ?
AMERICAN_AMERICA.AL32UTF8(一個字符1字節,一個漢字為3字節)
SQL> create table liu_oracleoltp_ywcs_t2_utf8 (name char(32)); ###創建字段為char32數據類型的liu_oracleoltp_ywcs_t2_utf8表,數據類型的字符串長度一般是16的倍數,例32,64,128等 SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t2_utf8 values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t2_utf8 values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t2_utf8; ###dump為展現這個行(name)的詳細內容 ###插入數據的詳細內容,數字代表字碼,79代表字母O,空格用32代碼表示
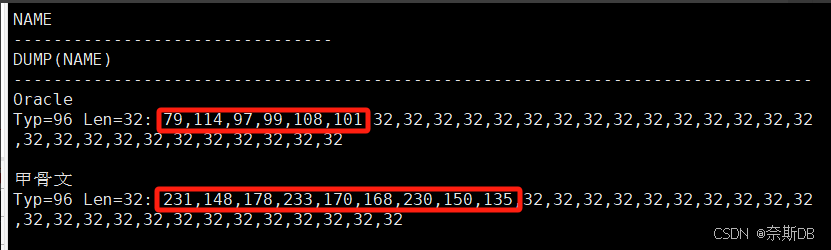
? ? ? ? ? ? ? ? ?
-
varchar2(n):存放可變長長度的字符集,最大可以存放4000 bytes
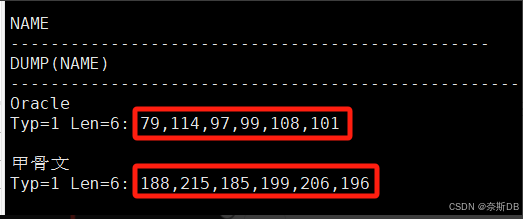
AMERICAN_AMERICA.ZHS16GBK(一個字符1字節,一個漢字為2字節)
SQL> create table liu_oracleoltp_ywcs_t3_gbk (name varchar2(16)); SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t3_gbk(name) values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t3_gbk(name) values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t3_gbk; ###1、存放了‘Oracle’的6個字符,實際存放數據庫中,就只占用了6個(‘Oracle’),其余的剩下的字符就被回收了。 ###2、如果插入數據是固定長度的,比如手機號碼(11位)、身份證號(18位),則應當使用char來存放,這樣的好處是查詢與檢索速度較快。原因為查詢char類型的字段時,作為整體進行查詢,而varchar2是一個個數據進行比對的。而如果存放的字符串的長度不固定,則建議使用varchar2(size)
? ? ? ? ? ? ? ? ? ? ? ? ? ?
AMERICAN_AMERICA.AL32UTF8(一個字符1字節,一個漢字為3字節)
SQL> create table liu_oracleoltp_ywcs_t4_utf8 (name varchar2(16)); SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t4_utf8(name) values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t4_utf8(name) values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t4_utf8; ###1、存放了‘Oracle’的6個字符,實際存放數據庫中,就只占用了6個(‘Oracle’),其余的剩下的字符就被回收了。 ###2、如果插入數據是固定長度的,比如手機號碼(11位)、身份證號(18位),則應當使用char來存放,這樣的好處是查詢與檢索速度較快。原因為查詢char類型的字段時,作為整體進行查詢,而varchar2是一個個數據進行比對的。而如果存放的字符串的長度不固定,則建議使用varchar2(size)
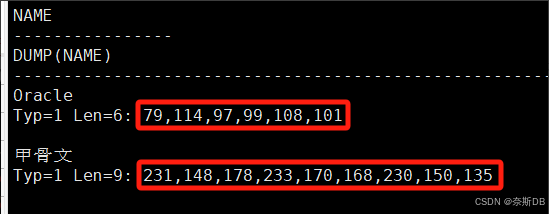
? ? ? ? ?
-
nchar(n):根據字符集而定的固定長度字符集,nchar(n)最大存放2000 bytes
AMERICAN_AMERICA.ZHS16GBK(一個字符2字節,一個漢字為2字節)
SQL> create table liu_oracleoltp_ywcs_t5_gbk (name nchar(16)); SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t5_gbk(name) values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t5_gbk(name) values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t5_gbk;
? ? ? ? ? ? ? ? ? ? ? ?
AMERICAN_AMERICA.AL32UTF8(一個字符2字節,一個漢字為2字節)
SQL> create table liu_oracleoltp_ywcs_t7_utf8 (name nchar(16)); SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t7_utf8(name) values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t7_utf8(name) values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t7_utf8;
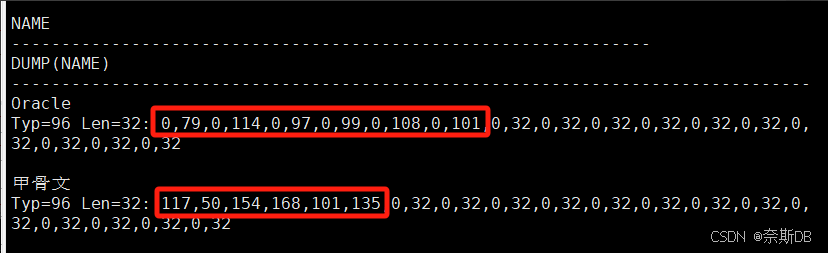
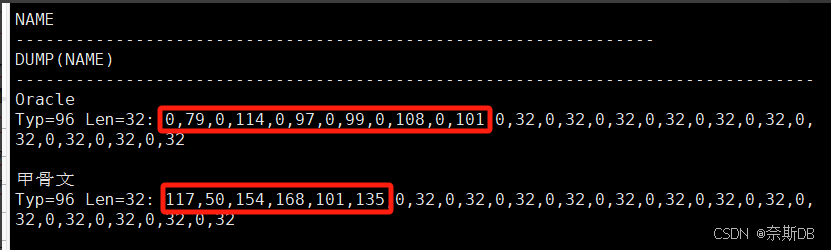
? ? ? ? ? ? ? ? ? ??
-
nvarchar2(n):根據字符集而定的固定長度字符集,nvarchar2(n)最大存放4000?bytes。
AMERICAN_AMERICA.ZHS16GBK(一個字符2字節,一個漢字為2字節)
SQL> create table liu_oracleoltp_ywcs_t6_gbk (name nvarchar2(16)); SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t6_gbk(name) values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t6_gbk(name) values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t6_gbk;
? ? ? ? ? ? ? ??
AMERICAN_AMERICA.AL32UTF8(一個字符2字節,一個漢字為2字節)
SQL> create table liu_oracleoltp_ywcs_t8_utf8 (name nvarchar2(16)); SQL> show parameter NLS_LENGTH_SEMANTICS; ###首先確定存放字符的類型,默認是字節byte存儲,有char、byte兩個值。 SQL> insert into liu_oracleoltp_ywcs_t8_utf8(name) values('Oracle'); SQL> insert into liu_oracleoltp_ywcs_t8_utf8(name) values('甲骨文');SQL> select name,dump(name) from liu_oracleoltp_ywcs_t8_utf8;
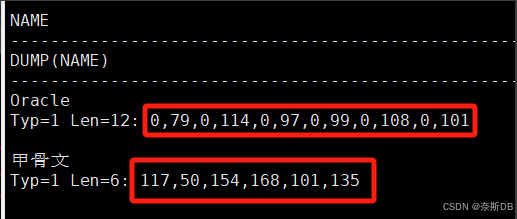
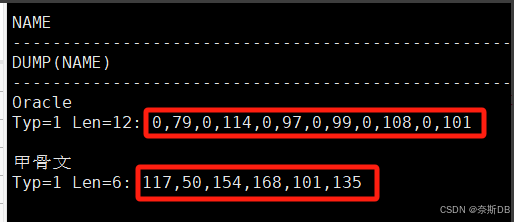
? ? ? ? ? ? ? ? ? ? ? ? ?
? ? 那么現在明白了為什么修改字符集時需要增加 char/varchar2數據類型 長度了吧!對于NCHAR、NVARCHAR2、CLOB和NCLOB列始終基于char字符,CLOB和NCLOB大字段的數據類型一般是不會指定長度的,所以也就不會涉及到長度的增加了,所以這里我就不演示了。
那么總結一下:
? ? Oracle字符集的修改不要在現有的實例上直接去修改,因為oracle默認是 字節byte 所以涉及到列長度的轉換,轉換涉及到 char和varchar2 兩種數據類型,其他數據類型不涉及到轉換,也有通過 在線修改單機或者rac的字符集 ,但是會有很大的風險,所以通過expdp/impdp數據泵是最有效的方案。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ??
源生產庫(ZHS16GBK,實例liudbywcs,RAC環境)部分
1、字符集存儲數據參數
SQL> show parameter NLS_LENGTH_SEMANTICS;
###BYTE:以字節的形式存儲數據,默認值。gbk遷移到utf8就會涉及到char和varchar2數據類型的長度轉換。
2、創建數據泵的dmp文件存放目錄
[root@rac1 ~]# mkdir /liu [root@rac1 ~]# chown oracle:oinstall /liu ###文件liu(路徑/liu)在/dev/sdb3下掛載,將文件的所屬用戶和目錄改為oracle:oinstall[root@rac1 ~]# sqlplus / as sysdba SYS@orcl> create directory BACKUP20200328 as '/liu'; SYS@orcl> grant all on directory BACKUP20200328 to system ; ###創建數據泵的轉儲路徑(在使用expdp時,指定到liu目錄時,數據文件就會生成在/liu路徑下)。賦予給所有用戶目錄liu的所有執行權限,為了以后普通用戶使用expdp時有權限將dmp數據文件導入到/liu下。
3、導出的數據庫為ZHS16GBK,只導出生產baj這個用戶
[oracle@rac1 ~]$ export ORACLE_SID=liudbywcs1
[oracle@rac1 ~]$ echo $ORACLE_SID[oracle@rac1 ~]$ expdp baj/baj directory=BACKUP20200328 dumpfile=expdp_liudbywcs_baj_%U.dmp logfile=expdp_orcl_baj.log schemas=baj parallel=4 cluster=n4、生成生產庫的業務表空間SQL語句:
ps:排查掉SYSAUX、SYSTEM、TEMP、UNDOTBS1、USERS這些系統表空間的創建
SQL> set linesize 500 set pagesize 99col file_name for a70 col file_id for 9999999 col status for a10 col ts_name for a25 col cur_mb for 99999 select status, file_id, file_name, tablespace_name ts_name,blocks/128 tolal_mb, maxblocks/128 max_mb,AUTOEXTENSIBLE,status,online_status from dba_data_files order by file_name;SQL> SET LONG 2000000 PAGESIZE 0 head off verify off feedback off linesize 180 SQL> select dbms_metadata.get_ddl('USER','BAJ') from dual; ###查看創建用戶的語句,需要確定默認的表空間和默認的臨時表空間
SQL> select dbms_metadata.get_ddl('TABLESPACE','NNC_DATA01') from dual; ###查看創建表空間的語句
SQL> select dbms_metadata.get_ddl('TABLESPACE','NNC_INDEX01') from dual;? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ??
目標庫(AL32UTF8,實例baj,RAC環境)部分
1、生產baj用戶導入前需要注意的事情:
1)關注歸檔目錄,定時進行刪除,避免空間耗盡。可以考慮先關閉歸檔
2)baj數據量有500G以上,導入過程中undo和temp占用很多,適當擴容。
? ? ? ?博主在實際遷移過程中Undo表空間給7個,總大小210G,并且減少undo_retention為300秒
? ? ? ? Temp表空間給3個,總大小90G
3)數據文件看情況增加
2、在服務器上創建一個AL32UTF8字符集的實例baj
這里就不演示安裝實例過程中,需要主要的是字符集需要為AL32UTF8
3、確認字符集調整undo保留時間
[oracle@rac1 ~]# export ORACLE_SID=baj1
[oracle@rac1 ~]# echo $ORACLE_SIDSQL> alter system set undo_retention=300 scope=both sid='*'; --導入完成之后修改回來SQL> select * from nls_database_parameters;
SQL> select * from v$nls_parameters;
SQL> select userenv('language') from dual ;4、創建表空間
SQL>
set linesize 500
set pagesize 99
col file_name for a70
col file_id for 9999999
col status for a10
col ts_name for a25
col cur_mb for 99999
select status, file_id, file_name, tablespace_name ts_name,blocks/128 tolal_mb, maxblocks/128 max_mb,AUTOEXTENSIBLE,status,online_status from dba_data_files order by file_name;alter tablespace UNDOTBS1 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS1 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS1 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS1 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS1 add datafile '+DATADG' size 31G autoextend on;alter tablespace UNDOTBS2 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS2 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS2 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS2 add datafile '+DATADG' size 31G autoextend on;
alter tablespace UNDOTBS2 add datafile '+DATADG' size 31G autoextend on;alter tablespace temp add tempfile '+DATADG' size 31G autoextend on;
alter tablespace temp add tempfile '+DATADG' size 31G autoextend on; CREATE TABLESPACE "NNC_DATA01" DATAFILE
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 5G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend onLOGGING ONLINE PERMANENT BLOCKSIZE 8192EXTENT MANAGEMENT LOCAL AUTOALLOCATE DEFAULTNOCOMPRESS SEGMENT SPACE MANAGEMENT AUTO;
CREATE TABLESPACE "NNC_INDEX01" DATAFILE
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend onLOGGING ONLINE PERMANENT BLOCKSIZE 8192EXTENT MANAGEMENT LOCAL AUTOALLOCATE DEFAULTNOCOMPRESS SEGMENT SPACE MANAGEMENT AUTO;CREATE TABLESPACE "NNC_INDEX01" DATAFILE
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend on,
'+DATADG' SIZE 1G autoextend onLOGGING ONLINE PERMANENT BLOCKSIZE 8192EXTENT MANAGEMENT LOCAL AUTOALLOCATE DEFAULTNOCOMPRESS SEGMENT SPACE MANAGEMENT AUTO;5、創建存放DMP文件夾的引用地址
SQL> create directory baj_dir as '/home/oracle/backup20200328';
SQL> grant all on directory baj_dir to system;6、linux下使用impdp工具導入(只是導入對象):
[oracle@rac1 ~]# export ORACLE_SID=baj1
[oracle@rac1 ~]# echo $ORACLE_SID[oracle@rac1 ~]# impdp system/oracle directory=baj_dir dumpfile=expdp_orcl_baj_01.dmp,expdp_orcl_baj_02.dmp,expdp_orcl_baj_03.dmp,expdp_orcl_baj_04.dmp logfile=impdp_baj_baj_metadata_only.log schemas=baj parallel=8 CONTENT=metadata_only table_exists_action=append cluster=n
####impdp導入之前,需要在目標數據庫上創建相應表空間對象即可;而對于imp導入時需要在目標數據庫上創建相應的用戶、權限、表空間等對象。7、舊庫遷移到新庫,舊庫編碼是GBK,新庫是UTF-8,一個漢字GBK占2個字節,UTF-8占三個字節,故對varchar2和char類型字段擴容二分之一
注意:有些業務表是定長char數據類型,但是內容只有字符,沒有漢字,如果統一進行擴容的話可能會影響程序對char數據類型的判斷,所以對于char數據類型按照要求擴長或者不擴長,哪些char必須要擴容只有在導入的時候報錯了再考慮對char進行擴容。
[oracle@rac1 ~]# sqlplus baj/123456 ###連接到baj用戶執行下面操作? ? ? ? ? ? ? ? ?
擴展char小于1300的SQL語句:
SQL> set pagesize 0; SQL> spool /home/oracle/char1.sqlSELECT 'alter table ' || t_column.table_name || ' modify ' ||t_column.column_name || ' char(' || (t_column.data_length + ceil(t_column.data_length * 0.5)) || ');' AS alter_sqlstrFROM user_tab_columns t_column, user_tables t_tablesWHERE t_column.table_name = t_tables.table_nameAND t_column.data_length <= 1300AND t_column.data_type = 'CHAR'; SQL> spool off? ? ? ? ?
擴展char大于1300且小于2000的SQL語句:
SQL> set pagesize 0; SQL> spool /home/oracle/char2.sqlSELECT 'alter table ' || t_column.table_name || ' modify ' ||t_column.column_name || ' char(2000);' AS alter_sqlstrFROM user_tab_columns t_column, user_tables t_tablesWHERE t_column.table_name = t_tables.table_nameAND t_column.data_length > 1300AND t_column.data_length < 2000AND t_column.data_type = 'CHAR'; SQL> spool off? ? ? ? ?
擴展varchar2大于2600且小于4000的SQL語句:
SQL> set pagesize 0; SQL> spool /home/oracle/char3.sqlSELECT 'alter table ' || t_column.table_name || ' modify ' ||t_column.column_name || ' varchar2(4000);' AS alter_sqlstrFROM user_tab_columns t_column, user_tables t_tablesWHERE t_column.table_name = t_tables.table_nameAND t_column.data_length > 2600AND t_column.data_length < 4000AND t_column.data_type = 'VARCHAR2'; SQL> spool off? ? ? ??
擴展varchar2小于2600的SQL語句:
SQL> set pagesize 0; SQL> spool /home/oracle/char4.sqlSELECT 'alter table ' || t_column.table_name || ' modify ' ||t_column.column_name || ' varchar2(' || (t_column.data_length + ceil(t_column.data_length * 0.5)) || ');' AS alter_sqlstrFROM user_tab_columns t_column, user_tables t_tablesWHERE t_column.table_name = t_tables.table_nameAND t_column.data_length <= 2600AND t_column.data_type = 'VARCHAR2'; SQL> spool off
8、執行需要擴容的SQL文本:
[oracle@rac1 ~]# sqlplus baj/123456
###連接到baj用戶執行下面操作SQL> /home/oracle/char1.sql
SQL> /home/oracle/char2.sql
SQL> /home/oracle/char3.sql
SQL> /home/oracle/char4.sql
###執行char1.sql、char2.sql、char3.sql、char4.sql之前,需要刪除多余的spool和spool off內容只保留alter table內容9、如果有些表擴長到varchar2(4000)也不足,所以需要修改為clob數據類型
ps:在第一次導入的時候發現導入WA_CLASSITEM表時,VFORMULASTR字段擴容到了varchar2(4000),但數據長度需要4070,varchar2最大長度為4000,所以只能通過alter table修改數據類型為clob才能解決,那么只能將生產用戶刪掉,然后再來一遍哦!

SQL> ALTER TABLE WA_CLASSITEM DROP COLUMN VFORMULASTR;
SQL> ALTER TABLE WA_CLASSITEM add VFORMULASTR CLOB;10、linux下使用impdp工具導入(導入對象的數據):
[oracle@rac1 ~]# export ORACLE_SID=baj1
[oracle@rac1 ~]# echo $ORACLE_SID[oracle@rac1 ~]# impdp system/oracle directory=baj_dir dumpfile=expdp_orcl_baj_01.dmp,expdp_orcl_baj_02.dmp,expdp_orcl_baj_03.dmp,expdp_orcl_baj_04.dmp logfile=impdp_baj_baj_data_only.log schemas=baj parallel=8 CONTENT=data_only table_exists_action=append cluster=n
####impdp導入之前,需要在目標數據庫上創建相應表空間對象即可;而對于imp導入時需要在目標數據庫上創建相應的用戶、權限、表空間等對象。? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
驗證數據部分
第一步:驗證數據大小
SQL> select sum(bytes) / 1024 / 1024 / 1024 || 'G' sumfrom dba_segmentswhere owner in ('BAJ')第二步:驗證有無失效的對象(目標數據庫上執行)
SQL> select * from dba_objects where status!='VALID' and owner in('BAJ');
SQL> @?/rdbms/admin/utlrp.sql ---有無效對象的話,進行無效對象的編譯(最大可能自動修復無效對象)。第三步:收集統計信息(目標數據庫上執行)
[oracle@rac1 ~]# vi status.sql begin
dbms_stats.gather_database_stats;
end;
/ [oracle@rac1 ~]# nohup sqlplus / as sysdba @status.sql & ---因為收集統計信息時間長,所以寫個sh后臺運行第四步:查看哪些表的統計信息被鎖定(stattype_locked字段為ALL的表示鎖定了表的統計信息,默認stattype_locked字段為空表示可以收集統計信息):
SQL> select * from dba_ind_statistics where stattype_locked='ALL' AND OWNER='BAJ';
SQL> select * from dba_tab_statistics where stattype_locked='ALL' AND OWNER='BAJ';SQL> begindbms_stats.unlock_schema_stats(ownname => 'BAJ');end;/
第五步:驗證對象(目標數據庫上執行)
SQL> select object_type t_object_type, count(*) t_countfrom dba_objectswhere owner in('BAJ')group by object_type
###注:oracle的對象類型可以分的很詳細,表、表分區、表子分區是不同的類型。
第六步:對比導入和導出日志
 ? ?
? ?
第七步:將undo時間修改回最佳值
SQL> alter system set undo_retention=10800 scope=both sid='*';? ? 兄弟們終于寫完了!!!這篇文章是我在下班后寫了3個小時奮戰到深夜23點才搞定的,之所以分享是因為大家之后肯定會用到的,所以別吝嗇你的小手, 點贊、收藏、加關注 。給我來點動力唄。那么我們下一篇文章見——expdp/impdp高效完成全部生產用戶的全庫遷移。















)

入門)

