繪制生命曲線圖(根據細胞因子)
- 說明
- 流程
- 代碼
- 加載包
- 讀取Excel文件
- 清理數據
- 重命名列名
- 處理IL-5中的"<"符號 - 替換為檢測下限的一半
- 首先找出所有包含"<"的值
- 檢查缺失
- 移除缺失值
- 根據IL-5中位數將患者分為高低兩組
- 創建生存對象
- 擬合生存曲線
- 繪制生存曲線
- 補充
- data$new_column 創建新列/修改現有列
- 更健壯的數據清理方法
- 類型轉換(轉換為數值型)
- 類型轉換(轉換為數值型0/1)
- 保存 / 加載 擬合后的生存曲線對象
- 保存繪制的生存曲線(如圖片或PDF)
- R語言的官方環境
R Base
官網下載:
https://www.r-project.org/
包含R的核心解釋器和基礎功能,適合純命令行操作。
RStudio
官網下載:
https://www.rstudio.com/products/rstudio/download/
說明
初學者注意
(1)代碼中所有符號不能是中文
(2)#表示后面的內容是注釋,不生效
(3)括號是成對出現的
關于NA值
在 R 語言中,NA(Not Available)是用于表示缺失值(Missing Value)的特殊值。它表示某個數據點不存在、不可用或未被記錄。
-
NA 在計算中的行為
大部分數學函數(如 sum(), mean())默認會因 NA 返回 NA
需使用 na.rm = TRUE 忽略 NA 計算 -
如何檢查NA值:
用is.na() -
如何處理NA值:
(1)刪除 NA
na.omit():刪除所有含 NA 的行
complete.cases() + 索引:篩選完整數據
(2)替換 NA
均值/中位數填充(適用于數值型數據)
眾數填充(適用于分類數據)
插值法(時間序列數據)
(3)計算時忽略 NA
使用na.rm = TRUE忽略 NA 計算
流程
(1)加載需要的依賴
(2)讀取文件
(3)預處理文件:保障所需數據的完整性、格式規范;
(4)創建對象,擬合生存曲線的數據
(5)繪制曲線
代碼
加載包
library(survival)
library(survminer)
library(dplyr)
library(readxl)
如果提示沒有包,就需要下載,例如:不存在叫‘survival’這個名稱的程序包
install.packages("survival")
讀取Excel文件
data <- read_excel("G:/術前.xlsx", sheet = "術前")
"G:/術前.xlsx"是文件名,"術前"是工作區名稱
清理數據
重命名列名
# 重命名列名
colnames(data) <- c("IL5", "Status", "OS_months")
c表示列名,這里沒有寫列序號,是按順序修改前三列,如果要指定修改某列列名,示例如下:
# 方法1:直接通過列索引修改特定列名
colnames(df)[3] <- "name"
colnames(df)[7] <- "data"
colnames(df)[11] <- "time"
# 方法2:使用向量一次性修改多個列名(更簡潔)
colnames(df)[c(3,7,11)] <- c("name", "data", "time")
處理IL-5中的"<"符號 - 替換為檢測下限的一半
首先找出所有包含"<"的值
data$IL5_clean <- ifelse(grepl("<", data$IL5), as.numeric(gsub("[^0-9.]", "", data$IL5))/2,as.numeric(data$IL5))
| 函數 | 說明 | 特點 |
|---|---|---|
| ifelse(test, yes, no) | test:邏輯測試條件,yes:當test為TRUE時返回的值,no:當test為FALSE時返回的值 | 可以同時處理整個向量/列,會保持輸入數據的結構和屬性 |
| grepl(“<”, data$IL5 | 在IL5中搜索"<"符號 | 默認區分大小寫,可設置ignore.case=TRUE;多列中查找c(“12”, “<5”, “3<2”, “NA”) |
| as.numeric(data$IL5) | 將IL5整列的數據強制轉換為數值型 | 無法轉換時會生成NA并給出警告 |
| gsub(“[^0-9.]”, “”, data$IL5) | 把IL5中所有不是數字和小數點的字符串替換為空 | 應用場景:非常適合清洗實驗數據中的檢測限值(如"<0.05"),可用于提取混雜在文本中的數值(如"23.5mg/L"),常用于處理實驗室數據或醫學檢測報告中的數值 |
| data$IL5_clean | 如果IL5_clean列不存在,會創建這個新列 | 詳細說明請看補充部分:data$new_column 創建新列/修改現有列 |
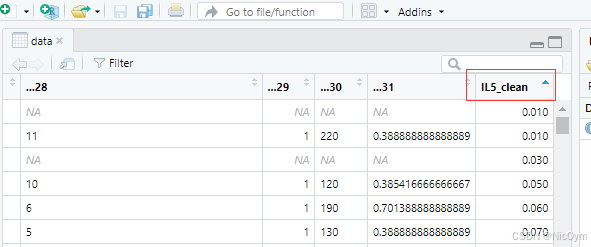
注意:
這個清理過程,可能會有 某些值無法被正確轉換為數值的情況:比如數據中存在空字符串、非數字字符或其他格式問題
解決方法請看補充部分:更健壯的數據清理方法
檢查缺失
有些行的數據不合規,通過下述代碼可以進行統計不合規的數據有多少
sum(is.na(data$IL5_clean))
sum(is.na(data$Status))
sum(is.na(data$OS_months))
sum(is.na(data$ IL5_clean)):統計IL5_clean列的缺失值數量
sum(is.na(data$ Status)):統計Status列的缺失值數量
sum(is.na(data$ OS_months)):統計OS_months列的缺失值數量
輸出示例:
[1] 5 # IL5_clean有5個缺失值
[1] 2 # Status有2個缺失值
[1] 3 # OS_months有3個缺失值
移除缺失值
簡單粗暴的方式,把不合規的數據移除(移除整行)
data_clean <- data %>% filter(!is.na(IL5_clean) & !is.na(Status) & !is.na(OS_months))
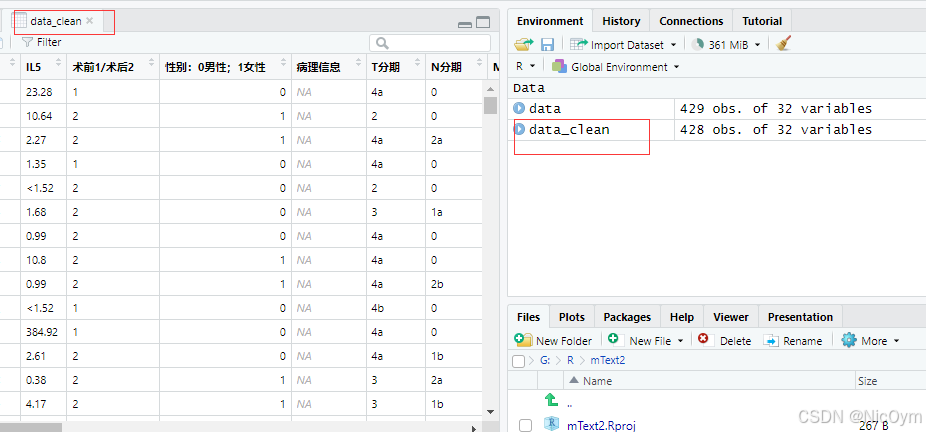
創建一個新的數據框data_clean,只保留三個關鍵列都非缺失值的完整記錄。
data_clean <- data:將數據框data復制一份到data_clean
管道操作符%>% 作用:將左側對象傳遞給右側函數的第一個參數
filter(.data, …, .preserve = FALSE).data:要篩選的數據框
…:邏輯條件表達式
.preserve:是否保留分組結構(高級用法)
意義
數據質量評估:
先統計缺失值了解數據完整度
判斷是否需要插補或可以直接刪除分析準備:
許多統計方法要求完整數據(如生存分析)
確保后續分析基于相同的一組觀測值
IL5_clean:生物標志物測量值
Status:患者狀態(如生死)
OS_months:總生存期
三者都是關鍵分析變量,必須完整
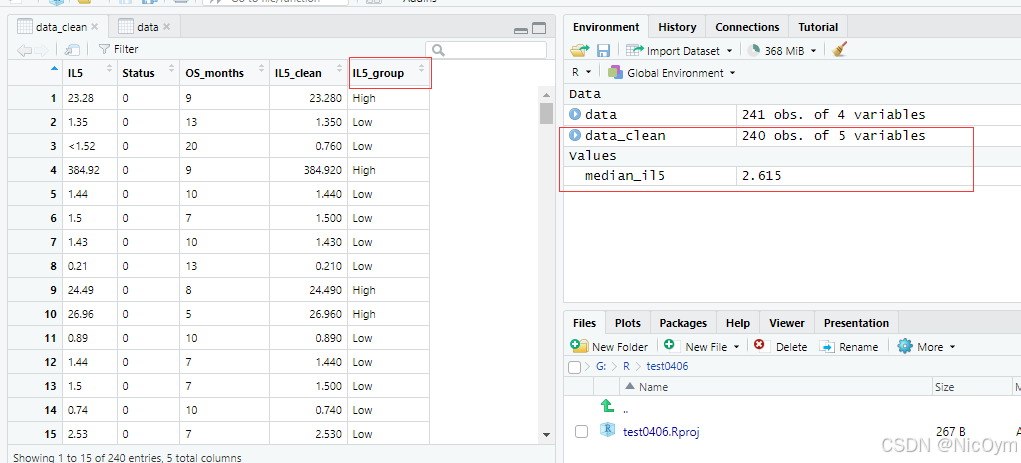
根據IL-5中位數將患者分為高低兩組
# 根據IL-5中位數將患者分為高低兩組
median_il5 <- median(data_clean$IL5_clean)
data_clean$IL5_group <- ifelse(data_clean$IL5_clean > median_il5, "High", "Low")
median() 計算中位數,默認情況下,如果向量包含NA值,函數會返回NA,除非設置na.rm = TRUE
median_il5 <- 將計算得到的中位數賦值給新變量median_il5,供后續使用。
data_clean$IL5_group <- 將ifelse的結果賦值給數據框中新創建的列IL5_group。
結果呈現:
創建生存對象
surv_obj <- Surv(time = data_clean$OS_months, event = data_clean$Status)
Surv() 創建生存數據對象,這個對象將作為后續生存分析函數的輸入。
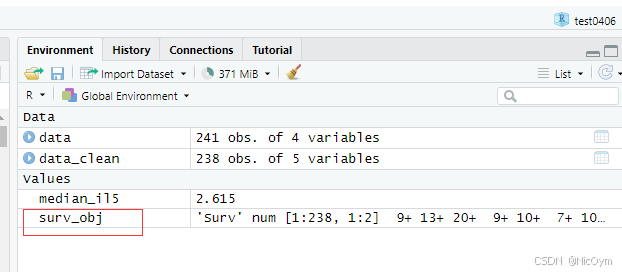
注意1:
Surv() 函數要求時間變量必須是數值型。如果檢查出變量類型不符合,會返回NA值
解決方案請看補充部分:類型轉換(轉換為數值型)
注意2:
event 參數必須是一個邏輯值(TRUE/FALSE)或數值型(0/1),其中:
0 或 FALSE 表示 刪失(censored)(患者存活或失訪)
1 或 TRUE 表示 事件發生(死亡)
解決方案請看補充部分:類型轉換(轉換為數值型0/1)
擬合生存曲線
fit <- survfit(surv_obj ~ IL5_group, data = data_clean)
survfit() 擬合生存曲線,默認使用Kaplan-Meier估計法。
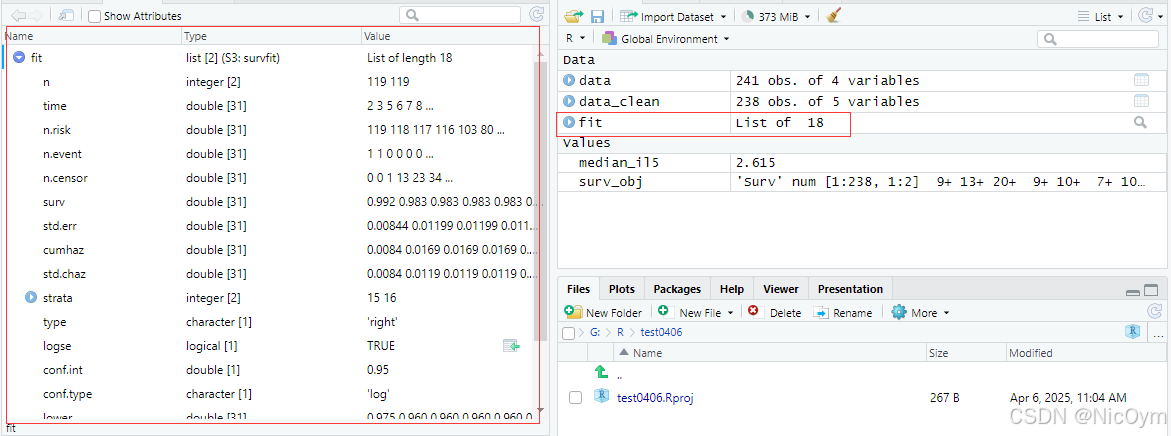
參數解釋
surv_obj ~ IL5_group:
R公式(formula),指定了生存分析的結構
左邊surv_obj是我們之前用Surv()創建的生存對象
右邊IL5_group是分組變量(基于之前IL5中位數分組的High/Low組)
data = data_clean:
指定了變量所在的數據框
這樣可以直接使用列名(IL5_group)而不需要用data_clean$IL5_group
注意:關于如何保存擬合后的生存曲線對象,請看補充部分:保存 / 加載 擬合后的生存曲線對象
繪制生存曲線
# 使用ggsurvplot函數繪制Kaplan-Meier生存曲線圖
surv_plot<-ggsurvplot(# 必需參數:生存分析結果對象,通常由survfit()函數生成fit, # 指定用于生存分析的數據集data = data_clean,# 設置y軸顯示范圍,為p值標簽留出空間#ylim = c(0.9, 1.0), # 更合理的范圍(留出標簽空間)# 邏輯值,是否在圖上顯示log-rank檢驗的p值(默認顯示在右上角)pval = TRUE, # 邏輯值,是否顯示p值的方法標簽(如"Log-rank test")pval.method = TRUE,# 設置p值標簽的位置
pval.method.coord = c(1, 1.0), # 方法標簽放在 (x=1, y=1.0)pval.coord = c(2, 1.0), # 將 P 值放在 (x=2, y=1.0)# 是否顯示生存曲線的置信區間帶conf.int = FALSE,# 設置置信區間帶的透明度(0-1,越小越透明)# conf.int.alpha = 0.2, # 20%透明度# 邏輯值,是否在圖形下方添加風險表(顯示各時間點的風險人數)risk.table = TRUE,# 設置風險表高度(占整個圖形高度的比例)risk.table.height = 0.25, # 占25%的高度# 自定義圖例標簽:# 使用paste()動態創建分組標簽,基于IL-5的中位數分組# 第一組標簽:"Low IL-5 (≤中位數值)"# 第二組標簽:"High IL-5 (>中位數值)"# round(median_il5, 2)將中位數保留兩位小數legend.labs = c(paste("Low IL-5 (≤", round(median_il5, 2)), paste("High IL-5 (>", round(median_il5, 2))),# 設置圖例的標題為"IL-5 Group"legend.title = "IL-5 Group",# 設置x軸標簽為"Time (Months)",表示時間以月為單位xlab = "Time (Months)",# 設置y軸標簽為"Survival Probability",表示生存概率ylab = "Survival Probability",# 設置圖形的主標題title = "Kaplan-Meier Survival Curve by IL-5 Level",# 設置兩條生存曲線的顏色:# 第一組顏色為十六進制碼#E7B800(紅色)# 第二組顏色為十六進制碼#2E9FDF(藍色)palette = c("#FF6A6A", "#2E9FDF"),# 設置圖形主題為ggplot2的簡約主題(去除多余背景元素)ggtheme = theme_minimal()
)
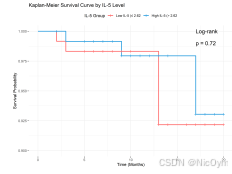
RGB顏色對照表
如何保存繪制出來的曲線,請看補充部分:保存繪制的生存曲線(如圖片或PDF)
補充
data$new_column 創建新列/修改現有列
一、列操作 (使用$和[ ])
- 單列操作
# 使用$選擇單列(返回向量)
data$column_name# 使用[ ]選擇單列(返回數據框)
data["column_name"]
data[, "column_name"] # 逗號在前表示選擇所有行
- 多列操作
# 選擇多列(返回數據框)
data[c("col1", "col2", "col3")]
data[, c("col1", "col2")]# 使用列索引
data[, 1:3] # 選擇前3列
- 整列操作
# 創建/替換整列
data$new_column <- values_vector # 長度需匹配行數# 刪除列
data$column_name <- NULL
data[, "column_name"] <- NULL
data <- subset(data, select = -column_name)
二、行操作 (使用[ , ])
- 單行操作
# 選擇單行(返回數據框)
data[1, ] # 第一行
data["row_name", ] # 如果有行名# 修改單行
data[1, ] <- c(value1, value2, ...)
- 多行操作
# 選擇多行
data[1:5, ] # 1-5行
data[c(1,3,5), ] # 第1,3,5行# 條件選擇
data[data$age > 30, ] # age大于30的行
subset(data, age > 30) # 等效方法
- 整行操作
# 添加新行
data <- rbind(data, new_row)# 刪除行
data <- data[-c(1,3), ] # 刪除第1和3行
data <- data[data$age >= 18, ] # 刪除age<18的行
三、混合操作
- 選擇特定行列
# 選擇第1-3行,第2-4列
data[1:3, 2:4]# 條件選擇特定列
data[data$age > 30, c("name", "age")]
- 修改特定區域
# 修改第2-3行的"score"列
data[2:3, "score"] <- c(90, 85)# 使用邏輯條件修改
data[data$gender == "M", "salary"] <- data[data$gender == "M", "salary"] * 1.1
更健壯的數據清理方法
data$IL5_clean <- sapply(data$IL5, function(x) {if (is.na(x) || x == "") {return(NA) # 如果是NA或空字符串,返回NA} else if (grepl("<", x)) {# 提取數值并除以2num <- as.numeric(gsub("[^0-9.]", "", x))if (is.na(num)) {return(NA) # 如果提取失敗,返回NA} else {return(num / 2)}} else {# 嘗試直接轉換為數值num <- as.numeric(x)return(ifelse(is.na(num), NA, num))}
})
額外建議
在轉換前先檢查數據的唯一值:
unique(data$IL5)
(1)如果數據中有很多不規則的值,可以考慮手動處理特殊情況
(2)對于無法自動轉換的值,可以單獨處理或考慮是否應該排除這些觀測
(3)這樣修改后,應該能更穩健地處理數據轉換問題,并清楚地知道哪些值無法被轉換。
處理完后檢查結果:
# 檢查轉換后的結果
sum(is.na(data$IL5_clean)) # 查看有多少NA值
which(is.na(data$IL5_clean)) # 查看哪些行有NA值
data[is.na(data$IL5_clean), ] # 查看這些行的原始數據
類型轉換(轉換為數值型)
> surv_obj <- Surv(time = data_clean$OS_months, event = data_clean$Status)
錯誤于Surv(time = data_clean$OS_months, event = data_clean$Status): Time variable is not numeric
data_clean$OS_months 不是數值型(numeric)變量,而 Surv() 函數要求時間變量必須是數值型。我們需要先檢查并轉換這個變量的類型。
轉換方法:
- 檢查變量類型
# 查看變量類型
str(data_clean$OS_months)
class(data_clean$OS_months)
- 轉換變量類型
如果 OS_months 是字符型(character)或因子型(factor),需要轉換為數值型:
# 轉換為數值型
data_clean$OS_months <- as.numeric(as.character(data_clean$OS_months))# 再次檢查轉換結果
sum(is.na(data_clean$OS_months)) # 查看是否有轉換失敗的NA值
which(is.na(data_clean$OS_months)) # 查看哪些行轉換失敗
- 處理轉換失敗
如果轉換產生了 NA 值,可能是因為原始數據中有非數字字符(如"/"或其他符號):
# 查看原始數據中的特殊值
unique(data$OS_months)[!is.na(unique(data$OS_months)) & is.na(as.numeric(as.character(unique(data$OS_months))))]# 清理特殊字符(例如將"/"替換為NA)
data_clean$OS_months <- ifelse(data_clean$OS_months %in% c("/", "/", " "), NA, data_clean$OS_months)
data_clean$OS_months <- as.numeric(as.character(data_clean$OS_months))# 移除NA值
data_clean <- data_clean[!is.na(data_clean$OS_months), ]
然后重新轉換
# 確保Status是數值型(0/1)
data_clean$Status <- as.numeric(as.character(data_clean$Status))# 再次檢查轉換結果
sum(is.na(data_clean$OS_months))
which(is.na(data_clean$OS_months))
完成后,查看的結果如下,可以看到已經是我們需要的整數類型

類型轉換(轉換為數值型0/1)
> surv_obj <- Surv(time = data_clean$OS_months, event = data_clean$Status)
錯誤于Surv(time = data_clean$OS_months, event = data_clean$Status): Invalid status value, must be logical or numeric
>
解決方法:
- 檢查 Status 的當前值和類型
# 查看 Status 列的唯一值和類型
unique(data_clean$Status)
class(data_clean$Status)
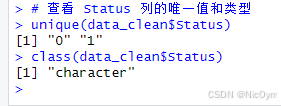
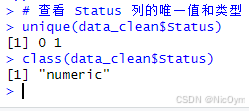
- 轉換 Status 為合法的 0/1 格式
(1) 如果 Status 是字符型(如 “0”, “1”)
data_clean$Status <- as.numeric(as.character(data_clean$Status))
(2) 如果 Status 是字符串(如 “生存”, “死亡”)
data_clean$Status <- ifelse(data_clean$Status == "死亡", 1, 0)
(3) 如果 Status 包含其他值(如 2, NA)
# 只保留 0 和 1,其余設為 NA 并移除
data_clean$Status <- ifelse(data_clean$Status %in% c(0, 1), data_clean$Status, NA)
data_clean <- data_clean[!is.na(data_clean$Status), ]
- 重新查看
# 查看 Status 列的唯一值和類型
unique(data_clean$Status)
class(data_clean$Status)
保存 / 加載 擬合后的生存曲線對象
- 說明:
通過survfit()擬合的生存曲線對象,包含以下關鍵信息:
生存概率:每個時間點的生存率(surv)。
時間點:事件發生的具體時間(time)。
風險集:每個時間點處于風險中的患者數(n.risk)。
事件數:每個時間點發生事件的數量(n.event)。
分組信息(如果存在,如本例中的IL5_group)。
在R中,保存擬合的生存曲線對象(如fit)后,可以隨時重新加載并使用它進行繪圖或分析
- 保存生存曲線對象
使用save()或saveRDS()函數將對象保存到本地文件:
方法1:使用 save()(保存為RData格式)
# 保存單個對象
save(fit, file = "survival_fit.RData")# 保存多個對象(如同時保存surv_obj和fit)
save(surv_obj, fit, file = "survival_objects.RData")
優點:可保存多個對象到一個文件。
文件格式:二進制(.RData或.rda)。
方法2:使用 saveRDS()(保存為單個對象)
saveRDS(fit, file = "survival_fit.rds")
優點:更靈活,加載時需指定新變量名(見下文)。
文件格式:二進制(.rds)
- 加載保存的對象
根據保存方式選擇對應的加載函數:
加載 save() 保存的文件
load("survival_fit.RData") # 直接恢復原對象名(如fit)
加載后,對象會以原名(如fit)自動出現在環境中。
加載 saveRDS() 保存的文件
fit_loaded <- readRDS("survival_fit.rds") # 需賦值給新變量名
可自由命名加載后的對象(如fit_loaded)。
- 使用加載的對象繪制生存曲線
加載后的對象和原始對象完全一致,可直接用于繪圖:
使用 survminer 包繪圖
library(survminer)
ggsurvplot(fit_loaded, # 加載后的對象data = data_clean, # 需確保數據存在pval = TRUE, risk.table = TRUE,conf.int = TRUE,palette = "jco") # 自定義顏色
使用基礎R繪圖
plot(fit_loaded, col = c("red", "blue"),xlab = "Time (months)", ylab = "Survival Probability")
legend("topright", legend = levels(data_clean$IL5_group), col = c("red", "blue"), lty = 1)
- 注意事項
數據一致性:
加載fit后,確保原始數據(data_clean)仍存在于環境中(繪圖時需要分組變量IL5_group)。
如果數據可能變動,建議將數據一并保存:
save(fit, data_clean, file = "survival_analysis_objects.RData")
跨平臺兼容性:
.RData和.rds文件是跨平臺的,可在Windows/macOS/Linux間共享。
版本兼容性:
如果R版本差異較大,加載時可能出現警告,建議在相同版本環境中使用。
保存繪制的生存曲線(如圖片或PDF)
- 使用 survminer (ggplot2-based) 保存圖片
如果你用ggsurvplot()繪制生存曲線(基于ggplot2),可以用ggsave()或print()保存為圖片或PDF。
方法1:直接保存為圖片/PDF
library(survminer)
library(ggplot2)# 繪制生存曲線
p <- ggsurvplot(fit, data = data_clean,pval = TRUE, risk.table = TRUE,palette = "jco")# 保存為PNG(高分辨率,600 dpi)
ggsave("survival_curve.png", plot = p$plot,width = 8, height = 6, dpi = 600)# 保存為PDF(矢量圖,適合論文)
ggsave("survival_curve.pdf", plot = p$plot,width = 8, height = 6)
補充:保存PDF時不支持中文解決方法:
install.packages("showtext")
library(showtext)
font_add("SimSun", "simsun.ttc") # Windows 系統自帶宋體
showtext_auto() # 自動啟用 showtext
ggsave("survival_curve.pdf", plot = surv_plot$plot,width = 8, height = 6, device = cairo_pdf)
方法2:保存帶風險表的完整圖形
ggsurvplot()返回的p是一個列表,包含生存曲線(p p l o t )和風險表( p plot)和風險表(p plot)和風險表(ptable)。若需保存兩者組合:
# 將圖形和風險表組合
combined_plot <- arrange_ggsurvplots(list(p), print = FALSE)# 保存組合圖
ggsave("survival_with_risk_table.png", combined_plot,width = 10, height = 8, dpi = 300)
- 使用基礎R圖形保存
如果使用基礎R的plot()函數,可以用以下方式保存:
保存為PNG/PDF
# 打開圖形設備(PNG)
png("survival_curve_baseR.png", width = 800, height = 600, res = 150)
plot(fit, col = c("red", "blue"), xlab = "Time (months)", ylab = "Survival Probability")
legend("topright", legend = levels(data_clean$IL5_group),col = c("red", "blue"), lty = 1)
dev.off() # 關閉設備并保存# 保存為PDF(矢量圖)
pdf("survival_curve_baseR.pdf", width = 8, height = 6)
plot(fit, col = c("red", "blue"), xlab = "Time (months)", ylab = "Survival Probability")
legend("topright", legend = levels(data_clean$IL5_group),col = c("red", "blue"), lty = 1)
dev.off()
- 保存為可編輯的矢量圖(如EPS/SVG)
適合進一步在Illustrator或Inkscape中編輯:
通過ggsave保存為SVG
library(svglite)
ggsave("survival_curve.svg", plot = p$plot, device = svglite,width = 8, height = 6)
通過基礎R保存為EPS
setEPS()
postscript("survival_curve.eps", width = 8, height = 6)
plot(fit, col = c("red", "blue"), xlab = "Time (months)", ylab = "Survival Probability")
legend("topright", legend = levels(data_clean$IL5_group),col = c("red", "blue"), lty = 1)
dev.off()
- 注意事項
文件路徑:
如果不指定路徑,文件會保存在當前工作目錄(通過getwd()查看)。
自定義路徑示例:
ggsave("C:/Users/Name/Desktop/survival_curve.png", plot = p$plot)
圖形分辨率:
調整dpi(每英寸點數)和width/height控制清晰度,尤其是PNG格式。
多圖形保存:
如果需要保存多個分面圖形(如不同亞組),用循環或lapply:
plots_list <- lapply(subgroups, function(group) {
ggsurvplot(subset_fit, data = subset_data, …)
})
for (i in seq_along(plots_list)) {
ggsave(paste0(“survival_group_”, i, “.png”), plot = plots_list[[i]])
)
















)

入門)