一,歸并排序
歸并排序(Merge sort)是建立在歸并操作上的一種有效的排序算法。該算法分治法(Divide and Conquer)的一個非常典型的應用。
作為一種典型的分而治之思想的算法應用,歸并排序的實現由兩種方法:
1.自上而下的遞歸(所有遞歸的方法都可以用迭代重寫)
2.自下而上的迭代
1.基本思想
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序算法。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為二路歸并。
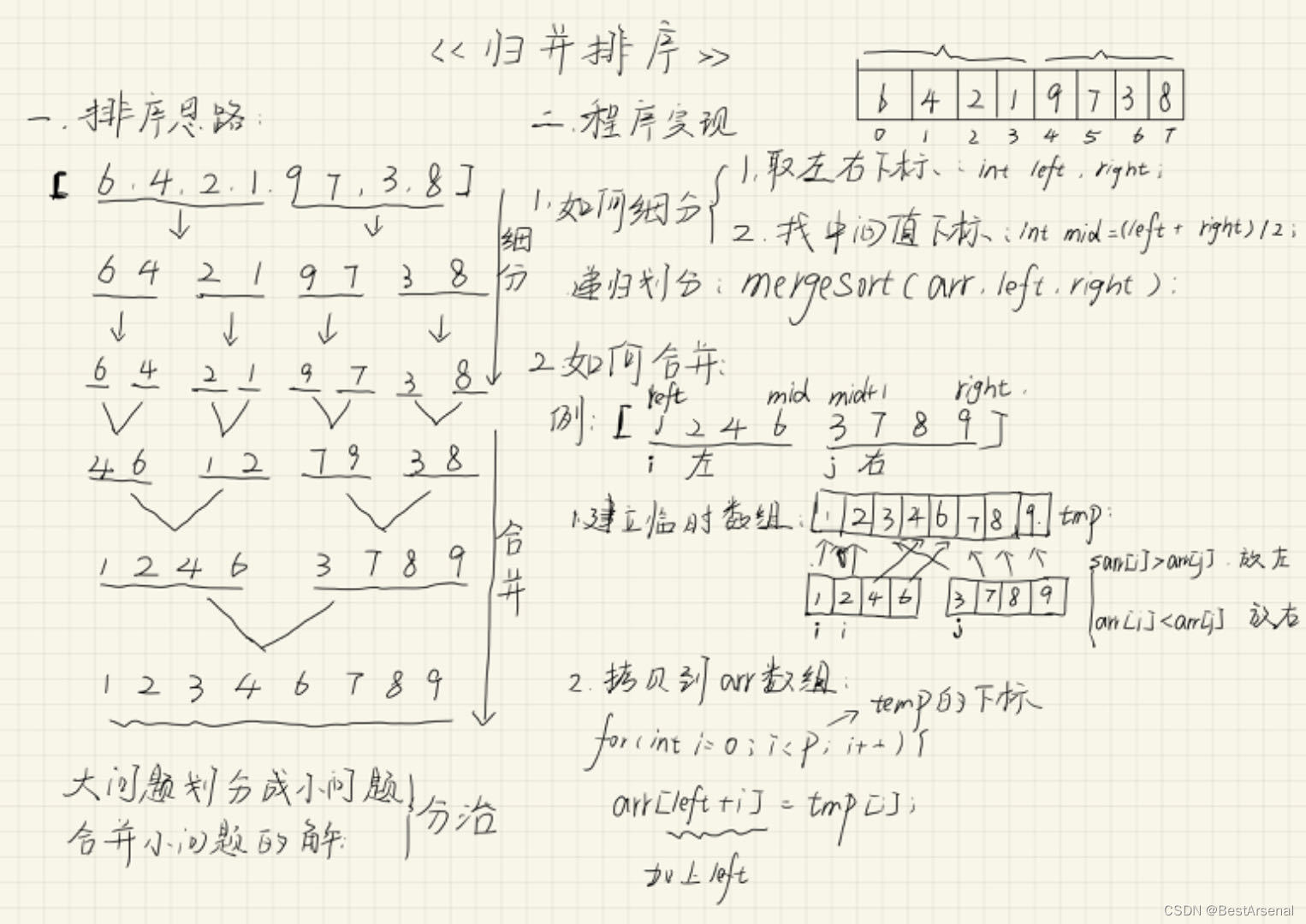
簡而言之,先通過遞歸的思想將數組分成一個一個的不可再分的子序列,接下來再對其中兩個子序列按照升序或者降序合并,重復直到合并所有子序列合并完成。(子問題其實就是兩個有序數組的合并)。
2.程序實現
#include<iostream>
using namespace std;
#define eleType int//合并兩個有序子序列
/*
參數含義: arr數組, left:序列的左邊起始點 mid:中間下標 right:右邊結束點
通過left mid right 將arr分成左右兩個區域
*/
void merge(eleType *arr,int left,int mid,int right){int i = left, j = mid + 1; // i為左邊區域的指針 j 為右邊區域的指針eleType *temp = new eleType[right + 1]; //臨時數組,用來臨時存放排序后的數字int index = 0; //臨時數組的下標while(i <= mid && j <= right){ //當左右區域都有未比完的數字temp[index++] = arr[i] < arr[j] ? arr[i++] : arr[j++]; //選擇較小的存入temp數組}while(i <= mid){ //當僅剩左邊區域temp[index++] = arr[i++]; // 按順序存入temp}while(j <= right){ //當僅剩右邊區域temp[index++] = arr[j++]; //按順序存入temp}for(int i = 0; i < index; i++){ //將temp重新放回arrarr[left + i] = temp[i];}delete [] temp; //刪除臨時temp數組
}
//歸并排序
/* 參數含義: left:最左邊下標 right : 最右邊的下標通過left 和right 計算出中間數的下標
*/
void mergesort(eleType *arr,int left,int right){if(left < right){ //遞歸條件int mid = left + (right - left) / 2; //計算中間下標mergesort(arr,left,mid); //遞歸劃分左邊區域mergesort(arr,mid + 1, right);//遞歸劃分右區域merge(arr,left,mid,right); //執行合并}
}
3.優缺點:
優點
穩定性: 穩定的排序算法,即相同元素的相對順序在排序前后保持不變。
最佳、平均和最壞時間復雜度:歸并排序在所有情況下(包括輸入數組已排序或逆序)的時間復雜度都是O(n log n),n是數組的大小。它在處理大數據集時非常高效。
空間復雜度:雖然歸并排序需要額外的空間來存儲臨時子數組,但它的空間復雜度是O(n),在實際應用中通常是可以接受的。
缺點
空間復雜度:雖然O(n)的空間復雜度可以接受的,但對于內存受限的環境或需要就地排序的場合,歸并排序不是最佳選擇。
數據移動次數:歸并排序在合并過程中可能需要大量的數據移動操作,這可能導致在某些情況下效率較低。
不適合小數據集:對于非常小的數據集,歸并排序的額外空間開銷和遞歸調用相對于其他簡單排序算法效率較低。但是在大數據集上,歸并排序的O(n log n)時間復雜度遠優于這些簡單排序算法。
遞歸深度:歸并排序是遞歸算法,對于非常大的數據集,遞歸深度可能會很大,可能導致棧溢出。
二,快速排序
1.基本思想
通過一次排序將待排序的數據分割成獨立的兩部分,其中一部分的所有數據都比另一部分的所有數據都要小,然后再按此方法對這兩部分數據分別進行快速排序,整個排序過程可以遞歸進行,以此達到整個數據變成有序序列。

2.實現步驟
- 1.選擇一個基準元素(pivot):通常選擇待排序序列的第一個或最后一個元素作為基準。
- 2.分割過程:將序列中小于基準的元素放在基準的左邊,大于基準的元素放在基準的右邊。這個過程稱為分區(partition)操作,分區結束后基準元素所處的位置就是其在已排序序列中的正確位置。
- 3.遞歸排序:分別對基準左右兩邊的子序列進行快速排序。
3.代碼實現
#include<iostream>
using namespace std;
#define eleType int
/* 劃分 將比基準數大的放右邊,比基準數小的放左邊
參數含義: arr數組,left:最左邊的下標 right: 最右邊的下標
*/int getKeyPositon(eleType *arr,int left,int right){int key = arr[left]; //將第一個數作為基準數while(left < right){while(arr[right] >= key && left < right){ //右邊先移動,找比基準數小的right--;}arr[left] = arr[right]; //找到之后賦值給左邊left的位置while(arr[left] <= key && left < right){ //之后左邊移動,找比基準數大的left++;}arr[right] = arr[left];//找到之后賦值給右邊right的位置}arr[left] = key; //左右指針相遇之后,將基準數放回相遇的位置return left; //返回基準數的位置
}
/*
排序過程,不停的基準數放到正確位置
參數含義: arr數組,left:最左邊的下標 right: 最右邊的下標
*/
void quickSort(eleType *arr,int left,int right){if(left < right){ //遞歸條件int position = getKeyPositon(arr,left,right); //基準數歸位之后,數組被分成左右兩部分quickSort(arr,left,position - 1); //對左邊部分排序quickSort(arr,position + 1,right); //對右邊部分排序}
}
優缺點
優點:
速度快:在平均情況下,快速排序的時間復雜度為O(n log n),比許多排序算法都要快。
原地排序:只需要一個很小的棧空間來保存遞歸的調用,不需要額外的存儲空間。
缺點:
最壞情況:在最壞情況下(輸入數據已經有序或接近有序),快速排序的時間復雜度會退化到O(n^2)。
空間復雜度:雖然快速排序是原地排序,但在遞歸調用時可能會占用較大的棧空間。對于非常大的數據集,會導致棧溢出。
對基準元素的選擇敏感:基準元素的選擇會影響到排序的性能。如果每次選擇的基準元素都是序列中最小或最大的元素,排序的效率就會降低。










)






浮游菌檢測標準操作規程及GB/T 16292-2010測試方法解讀)

